AI Agent Engineering Glossary - Memory, Tools, Orchestration, and Protocols Explained
First Published:
Last Updated:
The list is curated to map cleanly to today's agent stacks (Amazon Bedrock AgentCore, LangGraph, CrewAI, AutoGen, Strands Agents, Mastra) and to the protocols and patterns that are quickly becoming the lingua franca of agent engineering. Each term gets a one-paragraph definition, a list of closely related terms, and a primary external source for further reading.
This article is a companion to my earlier AI and Machine Learning Glossary for AWS, which covers foundation models, Amazon SageMaker, and Amazon Bedrock service terms. Where that glossary stops at the model-and-platform layer, this one starts at the agent layer above it.
How to Use This Glossary
Use the A-Z Term Index below to jump directly to a term. Each entry follows the same shape: a 2-4 sentence definition, a Related line cross-linking to other terms in this page, and a Source line linking to the canonical specification, paper, or vendor documentation.
Categories group terms by the layer of the agent stack they belong to. If you are debugging an agent, start in Foundation and Memory. If you are extending an agent, look at Tools, Protocols, and Retrieval. If you are scaling one, Orchestration, Evaluation, Security, and Lifecycle are where you spend time. Where terms are vendor-specific (Bedrock AgentCore, LangGraph, etc.), the descriptions stay at the product-name level rather than its current API surface, to keep this page from rotting as the products evolve.
A-Z Term Index
A2A Protocol · Agent · Agent Graph · Agent Observability · Agentic Loop · Amazon Bedrock AgentCore Runtime · AutoGen · Autonomous Agent · Browser Use · Capability Negotiation · Chain of Thought (CoT) · Chunking · Code Interpreter · Compaction · Computer Use · Constitutional AI · Context Compression · Context Window · Conversation Buffer · Conversation Summary · CrewAI · DeepEval · Dense Retrieval · Embedding · Episodic Memory · Evaluation Set · Faithfulness · Function Calling · Golden Dataset · Grounding · Guardrail · Hallucination · Handoff · Hierarchical Agents · Hybrid Search · HyDE (Hypothetical Document Embeddings) · Indirect Prompt Injection · Jailbreak · JSON-RPC · Knowledge Graph · LangGraph · Latency Budget · Lexical Search (BM25) · LLM-as-a-Judge · Long-Term Memory · Mastra · MCP Client · MCP Prompt · MCP Resource · MCP Roots · MCP Sampling · MCP Server · Memory Hierarchy · Memory Retrieval · Model Context Protocol (MCP) · Multi-Agent · Output Filter · Pairwise Comparison · Parallel Tool Calls · PII Redaction · Pipeline · Plan-and-Execute · Prompt Injection · Promptfoo · Query Rewriting · Ragas · ReAct · Red Teaming · Reflection · Regression Test · Reranker · Retrieval-Augmented Generation (RAG) · Sandbox · Self-Critique · Semantic Memory · Session Replay · Short-Term Memory · Single-Agent · Span · Stdio Transport · Strands Agents · Streamable HTTP Transport · Supervisor Pattern · Swarm Pattern · Token Usage Tracking · Tool Choice · Tool Definition · Tool Error · Tool Poisoning · Tool Result · Tool Schema · Tool Use · Tool-Using Agent · Trace · Trajectory Evaluation · Tree of Thoughts (ToT) · Vector Memory · Vector Store · WebSocket Transport · Working Memory
Architecture Overview
The five layers below frame why the terms in this glossary exist. Perception ingests inputs and tool results; Reasoning decides; Memory persists what cannot fit in the prompt; Tools act on the world; Action surfaces side effects and handoffs. Observability and Guardrails cross-cut every layer.
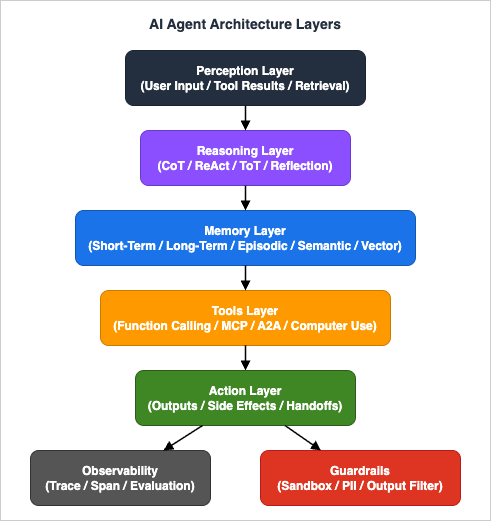
A. Foundation - Agent Concepts and Reasoning
Agent
An agent is a software system that uses a language model to decide what action to take next, executes that action against tools or environments, observes the result, and loops until a goal is satisfied. The defining property is that the control flow is decided by the model at runtime, not by a fixed program. Agents differ from plain LLM calls in that they are stateful, tool-using, and goal-directed.
Related: Agentic Loop, Autonomous Agent, Tool-Using Agent, ReAct
Source: Anthropic - Building Effective Agents
Agentic Loop
The agentic loop (sometimes called the agent loop or reason-act loop) is the repeating cycle of "model proposes action, action executes, result returns to model, model proposes next action". Most agent frameworks differ only in how they implement this loop: as a graph (LangGraph), as a chat thread with tool calls, or as a managed runtime (Amazon Bedrock AgentCore Runtime).
Related: Agent, ReAct, Tool Use, Plan-and-Execute
Source: Anthropic - Building Effective Agents
Autonomous Agent
An autonomous agent is one that can choose its own subgoals and continue executing without per-step human approval, typically over multiple turns or hours. Autonomy is a spectrum rather than a binary: most production agents pause for human approval at high-impact actions (writes, payments, irreversible operations) while remaining autonomous for everything else.
Related: Agent, Plan-and-Execute, Guardrail, Agentic Loop
Source: Anthropic - Building Effective Agents
Tool-Using Agent
A tool-using agent invokes external functions or services as part of its reasoning, rather than answering purely from the model's parametric knowledge. The model emits a structured tool call, the runtime executes it, and the result is fed back into the next turn. Tool use is what allows agents to act on the world rather than just describe it.
Related: Tool Use, Function Calling, Tool Definition, MCP
Source: Anthropic - Tool use
ReAct
ReAct (Reason + Act) is a prompting and execution pattern in which the model alternates between an explicit "thought" step (reasoning) and an "action" step (tool call) at each turn. It was introduced by Yao et al. in 2022 and remains the canonical baseline for tool-using agents because it gives both the model and human reviewers a legible trace of why an action was taken.
Related: CoT, Agentic Loop, Tool Use, Trajectory Evaluation
Source: Yao et al., 2022 - ReAct
Tree of Thoughts (ToT)
Tree of Thoughts generalises Chain of Thought by exploring multiple reasoning branches in parallel, scoring partial solutions, and pruning unpromising paths. It is more expensive than CoT but yields better results on tasks where the model benefits from backtracking, such as planning, search, and constraint satisfaction.
Related: CoT, Reflection, Plan-and-Execute, Self-Critique
Source: Yao et al., 2023 - Tree of Thoughts
Chain of Thought (CoT)
Chain of Thought prompting asks the model to produce intermediate reasoning steps before its final answer. Empirically, CoT improves performance on multi-step problems because the intermediate tokens act as a scratchpad. In modern reasoning models the CoT may be produced internally and hidden from the user, while still influencing the final output.
Related: ReAct, ToT, Reflection
Source: Wei et al., 2022 - Chain of Thought
Reflection
Reflection is a self-improvement pattern in which the agent re-reads its own prior output (a draft answer, a plan, or a trajectory) and writes a critique, then revises. It is cheap to implement (one extra model call) and often closes a meaningful quality gap on tasks that have a verifiable form, such as code or structured data.
Related: Self-Critique, ToT, LLM-as-a-Judge
Source: Shinn et al., 2023 - Reflexion
Self-Critique
Self-critique is a narrower form of reflection where the model is prompted specifically to identify mistakes in its own output against an explicit rubric, before revising. It is the workhorse of "verifier-style" agents and of evaluation pipelines that use LLM-as-a-Judge.
Related: Reflection, LLM-as-a-Judge, Constitutional AI
Source: Shinn et al., 2023 - Reflexion
Plan-and-Execute
Plan-and-Execute is an agent pattern that separates a planner step (decompose a goal into a sequence of subtasks) from an executor step (run each subtask, possibly with its own agent or tool). It trades latency and structure for reliability - the plan is a contract the agent commits to before acting, making the trajectory easier to inspect.
Related: ReAct, Supervisor Pattern, Pipeline
Source: LangChain - Plan-and-Execute Agents
B. Memory
Short-Term Memory
Short-term memory is the working state available to the agent within a single session, typically held in the active context window. It includes the user's request, the running scratchpad, recent tool calls and results, and any in-flight plan. When the session ends, short-term memory is discarded unless an explicit step persists it to long-term memory.
Related: Working Memory, Context Window, Conversation Buffer, Compaction
Source: Amazon Bedrock AgentCore - Memory
Long-Term Memory
Long-term memory is state that survives across sessions and is fetched on demand. Implementations vary from a key/value store of user preferences, to a vector index of past conversations, to a graph database of entities and relationships. Long-term memory is what lets an agent feel coherent across days rather than merely within one session.
Related: Short-Term Memory, Episodic Memory, Semantic Memory, Vector Memory
Source: Amazon Bedrock AgentCore - Memory
Episodic Memory
Episodic memory stores specific past interactions as discrete "episodes" - what happened, when, with whom - so the agent can later recall events. It is contrasted with semantic memory, which stores generalised facts. Episodic memory is the right substrate for "remember what we decided yesterday" style features.
Related: Long-Term Memory, Semantic Memory, Memory Retrieval, Vector Memory
Source: Amazon Bedrock AgentCore - Memory
Semantic Memory
Semantic memory stores generalised facts and preferences extracted from many episodes - e.g. "the user prefers Python type hints" - rather than the verbatim text of any one conversation. It is typically populated by a background summariser that distils episodes into facts and overwrites older entries.
Related: Episodic Memory, Long-Term Memory, Compaction, Knowledge Graph
Source: Amazon Bedrock AgentCore - Memory
Working Memory
Working memory is the agent's scratchpad for the current task: the running plan, partial results, and notes the model wants to keep visible while it works. In framework terms it is often the same buffer as the chat history; in cognitive terms it is closer to a deliberate, structured planning surface.
Related: Short-Term Memory, Plan-and-Execute, Conversation Buffer, Context Window
Source: Anthropic - Building Effective Agents
Memory Hierarchy
Memory hierarchy refers to layering memories by access speed and persistence: the active context window at the top (fast, ephemeral), a session cache below it, and persistent stores (vector, key/value, graph) further down. Designing the hierarchy explicitly is what separates a chatbot from an agent that scales.
Related: Short-Term Memory, Long-Term Memory, Compaction, Context Window
Source: Packer et al., 2023 - MemGPT
Conversation Buffer
A conversation buffer is the simplest memory primitive: a verbatim list of past messages in the order they happened. It is cheap and faithful, but it grows linearly with the dialogue and eventually exceeds the context window, at which point you must summarise, truncate, or page out.
Related: Conversation Summary, Compaction, Context Window, Short-Term Memory
Source: LangChain - Memory concepts
Conversation Summary
A conversation summary is a compressed representation of past dialogue produced by a smaller LLM call. It replaces or supplements the raw buffer when history grows long. The trade-off is faithfulness: a summary keeps the gist but discards detail that may matter later.
Related: Conversation Buffer, Compaction, Long-Term Memory, Working Memory
Source: LangChain - Memory concepts
Vector Memory
Vector memory stores past content as embedding vectors in a vector database and retrieves the top-k most similar entries on demand. It scales to large histories and supports semantic recall ("what did we say about X?") rather than recency-only recall. Vector memory is the default substrate for long-term memory in most modern stacks.
Related: Embedding, Vector Store, Long-Term Memory, Memory Retrieval
Source: Amazon Bedrock AgentCore - Memory
Memory Retrieval
Memory retrieval is the operation of fetching relevant entries from memory at the start of (or during) a turn, and injecting them into the prompt. The retrieval policy - how many, by what similarity threshold, with what recency weighting - is a major lever on both quality and cost.
Related: Vector Memory, RAG, Reranker, Context Compression
Source: Amazon Bedrock AgentCore - Memory
Context Window
The context window is the maximum number of tokens the model can attend to in a single call. It bounds how much memory, retrieval, and tool output can be in front of the model at once. Modern flagship models have very large windows, but cost and recall both degrade well before the hard limit, which makes deliberate window management mandatory at scale.
Related: Compaction, Conversation Summary, Memory Hierarchy, Token Usage Tracking
Source: Anthropic - Context windows
Compaction
Compaction (sometimes called context compression or pruning) is the process of shrinking the active context window by summarising, deduplicating, or evicting older content while preserving information the agent still needs. It is the operational answer to "the chat is too long" and is run continuously in long-running agents.
Related: Conversation Summary, Context Window, Memory Hierarchy, Context Compression
Source: Anthropic - Context management
C. Tool Use and Function Calling
Tool Definition
A tool definition is the contract the agent uses to know a tool exists: its name, a natural-language description of what it does and when to use it, and a schema for its parameters. The quality of the description is a direct predictor of whether the model will choose the tool at the right moments.
Related: Tool Schema, Tool Choice, Function Calling, MCP
Source: Anthropic - Tool use
Tool Schema
A tool schema specifies the input shape of a tool, almost always as JSON Schema. The model emits arguments that conform to the schema, and the runtime validates them before invoking the underlying function. Tight schemas (with enums, required fields, and constraints) materially reduce malformed tool calls.
Related: Tool Definition, Function Calling, JSON-RPC, Tool Error
Source: JSON Schema
Tool Use
Tool use is the act of the model emitting a tool call as part of its output, the runtime executing the call, and the result being fed back into the next turn. It is the mechanism by which agents read databases, write files, call APIs, and operate the world.
Related: Function Calling, Agentic Loop, Tool Result, ReAct
Source: Anthropic - Tool use
Function Calling
Function calling is the API-level feature of LLM providers that lets a caller register tools and receive structured tool-call objects in the model's response. The terms tool use and function calling are used near-interchangeably; "function calling" is more common in OpenAI-flavoured APIs, "tool use" in Anthropic-flavoured APIs.
Related: Tool Use, Tool Definition, Parallel Tool Calls, Tool Choice
Source: OpenAI - Function calling
Tool Choice
Tool choice is the API parameter that lets the caller bias whether the model must use a tool, must use a specific tool, or is free to choose (including "no tool"). It is the most reliable way to force structured output through a tool when free-form generation is too unconstrained.
Related: Function Calling, Tool Definition, Tool Use, Parallel Tool Calls
Source: Anthropic - Tool use
Parallel Tool Calls
Parallel tool calls let the model request multiple independent tool invocations in a single turn, which the runtime can dispatch concurrently. Used carefully, parallel tool calls collapse multi-turn fetches into one round trip; used carelessly, they amplify race conditions and rate-limit pressure.
Related: Tool Use, Function Calling, Agentic Loop, Latency Budget
Source: OpenAI - Function calling
Tool Result
A tool result is the structured value returned to the model after a tool executes. It is what closes the loop in tool use: the model sees the result on the next turn and decides what to do next. Tool results should carry enough context for the model to recover from partial failure without re-fetching.
Related: Tool Use, Tool Error, Agentic Loop, Function Calling
Source: Anthropic - Tool use
Tool Error
A tool error is a structured failure result from a tool - a non-2xx status, a thrown exception, a validation failure. Returning errors back to the model (instead of crashing) lets the model self-correct: retry with different arguments, fall back to another tool, or report the failure to the user.
Related: Tool Result, Tool Use, Sandbox, Trajectory Evaluation
Source: Anthropic - Tool use
Computer Use
Computer use refers to the agent operating a computer the way a human would - by reading screenshots and emitting mouse, keyboard, and shell commands rather than calling structured APIs. It generalises tool use to environments that lack APIs and is the basis for browser, desktop, and OS automation agents.
Related: Browser Use, Tool Use, Sandbox, Code Interpreter
Source: Anthropic - Computer use
Browser Use
Browser use is the specialisation of computer use to a headless browser: the agent reads a DOM or a rendered screenshot and emits browser actions (click, type, navigate). It is the most common way agents interact with sites that have no API.
Related: Computer Use, Tool Use, Sandbox
Source: Playwright
Code Interpreter
A code interpreter is a sandboxed environment (typically Python) the agent can use to run arbitrary code, inspect results, and iterate. It is one of the highest-leverage tools because it turns open-ended numeric, data, and parsing problems into ordinary programs.
Related: Sandbox, Tool Use, Computer Use, AgentCore Runtime
Source: Amazon Bedrock AgentCore - Code Interpreter
D. Protocols - MCP and A2A
Model Context Protocol (MCP)
The Model Context Protocol is an open protocol, introduced by Anthropic in late 2024, that standardises how LLM applications connect to external tools, data sources, and prompts. MCP defines a client/server model with a small set of primitives - tools, resources, prompts, sampling, roots - carried over JSON-RPC. Its goal is to make integrations interchangeable across hosts and providers, much as LSP did for editors and language servers.
Related: A2A Protocol, MCP Server, MCP Client, JSON-RPC
Source: Model Context Protocol Specification
A2A Protocol
Agent-to-Agent (A2A) Protocol is an open protocol for direct communication between independent agents, allowing one agent to delegate tasks to another regardless of vendor or framework. It was introduced by Google in 2025 and is now stewarded by the Linux Foundation, with adopters across multiple agent platforms including Amazon Bedrock AgentCore. A2A complements MCP: where MCP standardises the agent-to-tool boundary, A2A standardises the agent-to-agent boundary.
Related: MCP, Multi-Agent, Handoff, Supervisor Pattern
Source: Agent2Agent (A2A) Protocol Specification
Streamable HTTP Transport
Streamable HTTP is the recommended transport for remote MCP servers: a regular HTTP request/response endpoint augmented with Server-Sent Events for server-to-client streaming. It replaces the earlier separate "SSE transport" with a single endpoint that can do both directions over standard HTTP infrastructure.
Related: MCP, Stdio Transport, WebSocket Transport, JSON-RPC
Source: Model Context Protocol Specification
Stdio Transport
Stdio transport runs an MCP server as a local subprocess, exchanging JSON-RPC messages over its standard input and output streams. It is the simplest transport and the right default when the server and client run on the same machine (typical for editor integrations).
Related: MCP, Streamable HTTP, MCP Server, JSON-RPC
Source: Model Context Protocol Specification
WebSocket Transport
A WebSocket transport carries JSON-RPC traffic over a single persistent bidirectional connection. WebSockets are not part of the current MCP specification (stdio and Streamable HTTP are the official transports), but the protocol is transport-agnostic and some implementations layer it over WebSockets when both endpoints already speak that protocol and need low-latency, bidirectional message flow.
Related: MCP, Streamable HTTP, Stdio Transport, JSON-RPC
Source: RFC 6455 - The WebSocket Protocol
MCP Resource
An MCP resource is a piece of data the server exposes to the client, identified by a URI - for example, a file, a database row, a configuration entry. Resources are read-only from the client's perspective; the server is responsible for resolving them. They are how MCP gives a model controlled read access to a system without inventing per-system APIs.
Related: MCP, MCP Server, MCP Roots, MCP Prompt
Source: Model Context Protocol Specification
MCP Prompt
An MCP prompt is a named, parameterised prompt template the server exposes to the client. The client can list available prompts, fetch them, and render them with arguments. Prompts make repeatable interaction patterns shareable as protocol entities rather than as code.
Related: MCP, MCP Resource, MCP Server, Tool Definition
Source: Model Context Protocol Specification
MCP Sampling
Sampling is the MCP primitive that lets an MCP server ask the client (host) to call an LLM on its behalf, with user approval. It inverts the usual direction of tool use: the server is asking for a language model completion, so the host can apply policy, attribution, and consent uniformly.
Related: MCP, MCP Server, Sandbox
Source: Model Context Protocol Specification
MCP Roots
Roots are the set of filesystem or URI scopes the client tells the server it is allowed to operate on. They are the principal mechanism by which an MCP host limits the blast radius of a third-party server - "you may read this project directory and nothing else".
Related: MCP, Sandbox, Capability Negotiation, Guardrail
Source: Model Context Protocol Specification
JSON-RPC
JSON-RPC is a small, transport-agnostic remote procedure call protocol that encodes requests and responses as JSON objects with method, params, id, result, and error fields. MCP carries every message as JSON-RPC, which is why it is straightforward to implement on top of stdio, HTTP, or WebSockets.
Related: MCP, Tool Schema, Streamable HTTP, Stdio Transport
Source: JSON-RPC 2.0 Specification
Capability Negotiation
Capability negotiation is the handshake at the start of an MCP session in which client and server tell each other which optional features they support (resources, prompts, sampling, roots, tool list change notifications). It is how the protocol stays small at its core while allowing optional extensions.
Related: MCP, MCP Roots, Streamable HTTP, JSON-RPC
Source: Model Context Protocol Specification
MCP Server
An MCP server is the process that exposes tools, resources, and prompts to a host (the AI application). It can run locally (stdio) or remotely (Streamable HTTP). Production-grade servers wrap APIs, databases, file systems, or proprietary back ends behind the standard MCP surface. See also MCP Server on AWS Lambda - Complete Guide.
Related: MCP, MCP Client, Stdio Transport, Streamable HTTP
Source: Model Context Protocol Specification
MCP Client
An MCP client lives inside the host application and maintains the connection to one MCP server. A host (like an IDE, a chat app, or an agent runtime) typically spawns many clients, one per server, and arbitrates which tools/resources the model sees.
Related: MCP, MCP Server, Capability Negotiation, Sandbox
Source: Model Context Protocol Specification
E. Orchestration and Frameworks
Single-Agent
A single-agent design uses one LLM-backed agent with one set of tools to handle a task end-to-end. It is the right default: simpler to reason about, easier to evaluate, and frequently better than a multi-agent design until you can articulate why you need more than one agent.
Related: Multi-Agent, Agentic Loop, Tool Use, Plan-and-Execute
Source: Anthropic - Building Effective Agents
Multi-Agent
A multi-agent design composes several agents that communicate to solve a task - typically because each agent has a distinct role, toolset, or model. Multi-agent designs trade simplicity for specialisation and parallelism; they are most justified when the subproblems differ enough that a single prompt becomes unwieldy.
Related: Supervisor Pattern, Handoff, A2A Protocol, Swarm Pattern
Source: Anthropic - Building Effective Agents
Supervisor Pattern
In the supervisor pattern, a top-level agent owns the conversation and delegates subtasks to specialised worker agents, collecting their results. It is the workhorse of multi-agent designs because the supervisor is a single, debuggable place where routing and state are managed.
Related: Multi-Agent, Hierarchical Agents, Plan-and-Execute, Handoff
Source: Anthropic - Building Effective Agents
Hierarchical Agents
Hierarchical agents extend the supervisor pattern to multiple levels: a top supervisor delegates to mid-level supervisors, which delegate to leaf workers. Hierarchies help when the task graph is genuinely deep, but each level adds latency and a place where state can be miscommunicated.
Related: Supervisor Pattern, Multi-Agent, Agent Graph
Source: LangGraph - Multi-agent concepts
Swarm Pattern
In a swarm, peer agents collaborate without a central supervisor - passing work between themselves via handoffs or a shared blackboard. Swarms can be more resilient than hierarchies but harder to debug because no single agent owns the trajectory.
Related: Multi-Agent, Handoff, A2A Protocol, Agent Graph
Source: LangGraph - Multi-agent concepts
Pipeline
A pipeline (sometimes called a chain) is a fixed sequence of steps where each step consumes the previous step's output. Pipelines are not strictly "agents" - the control flow is hard-coded - but they are an essential building block inside agents, especially for retrieval, formatting, and post-processing.
Related: Agent Graph, RAG, Plan-and-Execute, LangGraph
Source: LangChain Expression Language
Agent Graph
An agent graph models agent behaviour as nodes (computations, agents, or tools) and edges (transitions). Graph-based frameworks (LangGraph, Amazon Bedrock AgentCore-style state machines) make control flow explicit and make resume/retry semantics straightforward.
Related: LangGraph, Plan-and-Execute, Trace
Source: LangGraph
LangGraph
LangGraph is an open-source framework from the LangChain team for building agents as explicit state graphs over nodes and edges, with first-class support for persistence, streaming, and human-in-the-loop. It is the agent runtime most often paired with LangChain components but can be used independently.
Related: Agent Graph, Multi-Agent, CrewAI, Agentic Loop
Source: LangGraph
CrewAI
CrewAI is an open-source framework that models multi-agent systems as a crew of agents with declared roles, goals, and tasks. Its idiom is more declarative than LangGraph's - you describe who does what - and it ships with patterns for sequential and hierarchical execution.
Related: Multi-Agent, Supervisor Pattern, Hierarchical Agents, Handoff
Source: CrewAI Documentation
AutoGen
AutoGen is an open-source multi-agent framework from Microsoft Research that emphasises conversational agents - agents that interact through structured dialogue, including with humans and with code-execution sandboxes. It pioneered patterns like "two-agent chat" for solver/critic loops.
Related: Multi-Agent, Self-Critique, Code Interpreter, Reflection
Source: AutoGen
Strands Agents
Strands Agents is an open-source agent framework originated and maintained by AWS that aims to be lightweight and model-driven: a small Python core with built-in MCP support and tight integration with Amazon Bedrock and AgentCore. It is the framework AWS uses in its own AgentCore samples.
Related: AgentCore Runtime, MCP, Tool Use, Agentic Loop
Source: Strands Agents SDK (strands-agents/sdk-python)
Mastra
Mastra is an open-source TypeScript framework for building agents and workflows, with first-class support for tools, memory, retrieval-augmented generation, and evals. It targets JavaScript/TypeScript stacks the way LangGraph and CrewAI target Python.
Related: LangGraph, CrewAI, Strands Agents, Tool Use
Source: Mastra
Amazon Bedrock AgentCore Runtime
Amazon Bedrock AgentCore Runtime is AWS's managed runtime for hosting agents as containerised, isolated microVMs. It provides session isolation, identity-aware tool invocation, integrated memory, observability, and built-in support for protocols including MCP and A2A. See also Amazon Bedrock AgentCore - Beginner's Guide and Production Guide.
Related: Strands Agents, MCP, A2A Protocol, Agent Observability
Source: Amazon Bedrock AgentCore Developer Guide
Handoff
A handoff is the act of one agent transferring control (and relevant context) to another agent. Handoffs are the primitive that turns isolated single-agents into a multi-agent system. The handoff API is what determines how lossy the transfer is - what survives, what gets summarised, what is dropped.
Related: Multi-Agent, Supervisor Pattern, Swarm Pattern, A2A Protocol
Source: LangGraph - Multi-agent concepts
F. Retrieval and RAG
Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation fetches relevant passages from an external corpus at query time and inserts them into the prompt so the model can ground its answer in current, specific information. RAG is the dominant pattern for grounding LLMs in proprietary or rapidly changing data because retraining the model is impractical.
Related: Vector Store, Embedding, Reranker, Grounding
Source: Lewis et al., 2020 - RAG
Vector Store
A vector store (vector database) indexes high-dimensional embedding vectors and supports approximate nearest neighbour search over them. It is the storage substrate for both RAG and vector memory. Implementations range from libraries (FAISS) to managed services (OpenSearch with k-NN, Pinecone, pgvector).
Related: Embedding, Vector Memory, RAG, Hybrid Search
Source: OpenSearch - k-NN
Embedding
An embedding is a numerical vector representation of a piece of text (or image, audio, etc.) such that semantically similar inputs land near each other in the vector space. Embeddings are produced by dedicated embedding models and are the currency of semantic search and vector memory.
Related: Vector Store, RAG, Dense Retrieval, Reranker
Source: Amazon Bedrock - Titan Embeddings
Chunking
Chunking is the act of splitting a document into smaller passages before embedding and indexing. Chunk size, overlap, and boundary policy (sentence, paragraph, semantic) are all knobs that materially affect retrieval quality. There is no universal best choice; the right chunking is downstream of the queries you serve.
Related: Embedding, RAG, Vector Store, Context Window
Source: Amazon Bedrock Knowledge Bases - Chunking
Reranker
A reranker is a second-stage model that re-scores the top-k results from a fast retriever and reorders them by relevance. Rerankers are usually small cross-encoders that read query and passage together. Adding a reranker is one of the highest-ROI moves in production RAG.
Related: RAG, Hybrid Search, Dense Retrieval
Source: SBERT - Retrieve and Re-rank
Hybrid Search
Hybrid search combines lexical (keyword/BM25) and dense (vector) retrieval, fusing their scores. It is more robust than either alone because each catches what the other misses - vectors generalise across paraphrases, lexical search nails exact terms and rare names.
Related: Lexical Search, Dense Retrieval, Reranker, RAG
Source: OpenSearch - Hybrid search
Lexical Search (BM25)
Lexical search, classically powered by BM25, ranks documents by overlap of query terms weighted by their inverse document frequency and document length. It is the bedrock retrieval algorithm in search engines and remains a strong baseline; modern RAG systems almost always include it alongside vector search.
Related: Hybrid Search, Dense Retrieval, RAG, Reranker
Source: Okapi BM25 (Wikipedia)
Dense Retrieval
Dense retrieval uses embedding-based similarity over learned vector representations rather than discrete term overlap. It captures paraphrase and concept similarity that lexical search misses, at the cost of more compute and more sensitivity to embedding model choice.
Related: Embedding, Vector Store, Hybrid Search, Reranker
Source: Karpukhin et al., 2020 - Dense Passage Retrieval
Knowledge Graph
A knowledge graph models information as a graph of entities and typed relationships, often queried in a structured query language (SPARQL, Cypher). Knowledge graphs complement RAG when the answer requires traversing relationships - "who reports to whom", "what depends on what" - rather than looking up text passages.
Related: RAG, Semantic Memory, Grounding, Dense Retrieval
Source: Knowledge Graph (Wikipedia)
Query Rewriting
Query rewriting transforms a user's raw question into a form better suited to retrieval - expanding acronyms, splitting compound questions, adding synonyms, removing meta-instructions. It is typically a cheap LLM call ahead of retrieval and is one of the easiest ways to lift recall.
Source: Ma et al., 2023 - Query Rewriting for RAG
HyDE (Hypothetical Document Embeddings)
HyDE is a retrieval technique that first asks an LLM to write a hypothetical answer to the query, then embeds that hypothetical answer and retrieves real documents similar to it. It often beats embedding the query directly because the hypothetical answer looks more like the target documents.
Related: Query Rewriting, RAG, Dense Retrieval, Embedding
Source: Gao et al., 2022 - HyDE
Context Compression
Context compression shrinks retrieved passages before they reach the model - by summarising, by selecting the most relevant sentences, or by dropping low-utility content. It is the bridge between aggressive retrieval (high recall) and the model's finite context window.
Related: Compaction, RAG, Context Window, Reranker
Source: LangChain - Contextual compression
G. Evaluation
LLM-as-a-Judge
LLM-as-a-Judge uses one LLM to score the outputs of another against a rubric or a reference answer. It is the dominant practical method for evaluating open-ended agent outputs because human grading does not scale and exact-match metrics do not capture quality. The trade-offs - judge bias, judge inconsistency, judge cost - are now an active research area.
Related: Self-Critique, Pairwise Comparison, Ragas, DeepEval
Source: Zheng et al., 2023 - Judging LLM-as-a-Judge
Ragas
Ragas is an open-source evaluation framework focused on RAG pipelines, with metrics such as faithfulness, answer relevancy, and context precision/recall. It standardises a small set of LLM-judged metrics that have become the lingua franca for RAG eval.
Related: LLM-as-a-Judge, Faithfulness, Grounding, RAG
Source: Ragas Documentation
DeepEval
DeepEval is an open-source Python framework for evaluating LLM and agent outputs in a pytest-like style, bundling metrics for hallucination, faithfulness, bias, toxicity, and task-specific correctness. It targets the "unit tests for LLMs" niche.
Related: LLM-as-a-Judge, Promptfoo, Regression Test, Evaluation Set
Source: DeepEval Documentation
Promptfoo
Promptfoo is an open-source tool for declarative prompt and model evaluation, with a YAML-driven matrix of prompts × models × test cases and built-in assertions. It is widely used for regression testing prompts across providers.
Related: Regression Test, Evaluation Set, LLM-as-a-Judge, Pairwise Comparison
Source: Promptfoo
Hallucination
A hallucination is a model output that is fluent and confident but factually wrong or unsupported by the provided context. Reducing hallucination is the central concern of grounding, faithfulness evaluation, and RAG.
Related: Faithfulness, Grounding, RAG, Guardrail
Source: Huang et al., 2023 - Hallucination survey
Faithfulness
Faithfulness measures whether the model's output is supported by the source material it was given (a retrieved passage, a tool result, a user-supplied document). A faithful answer may still be wrong if the source is wrong, but it does not invent. Faithfulness is the most useful single metric in RAG eval.
Related: Grounding, Hallucination, Ragas, LLM-as-a-Judge
Source: Ragas Documentation
Grounding
Grounding is the practice of constraining a model's output to information actually present in some authoritative source - a retrieved document, a database row, a tool result. Where faithfulness is a measurement, grounding is the design pattern that aims for high faithfulness.
Related: Faithfulness, RAG, Hallucination, Knowledge Graph
Source: Amazon Bedrock - Knowledge Bases
Trajectory Evaluation
Trajectory evaluation scores the full sequence of an agent's thoughts, tool calls, and intermediate results - not just the final answer. It is what catches an agent that "got the right answer for the wrong reasons" or that wasted many tool calls. It is essential for production agent eval.
Related: Trace, Span, Agent Observability, ReAct
Source: LangSmith - Evaluation concepts
Golden Dataset
A golden dataset is a curated, version-controlled set of inputs with known-good outputs used as the ground truth for evaluation and regression testing. It is one of the highest-leverage artefacts in an agent team: without it, every change is a gamble.
Related: Evaluation Set, Regression Test, DeepEval, Promptfoo
Source: LangSmith - Evaluation concepts
Pairwise Comparison
Pairwise comparison asks a judge (LLM or human) to pick the better of two outputs for the same input, rather than to score each absolutely. Pairwise judgements are easier to elicit consistently than absolute scores and are the basis of preference-based evaluation and RLHF-style training data.
Related: LLM-as-a-Judge, Regression Test, Golden Dataset
Source: Zheng et al., 2023 - Judging LLM-as-a-Judge
H. Security and Safety
Prompt Injection
Prompt injection is an attack where adversarial instructions in user input or retrieved content cause the model to ignore its original system prompt and follow the attacker's instructions instead. It is the most prevalent class of LLM attack and the principal reason agents need strict tool-permission policies rather than trusting model output. See also AWS WAF - Generative AI Prompt Injection Patterns.
Related: Indirect Prompt Injection, Jailbreak, Guardrail, Tool Poisoning
Source: OWASP Top 10 for LLM Applications
Indirect Prompt Injection
Indirect prompt injection is prompt injection delivered through content the model retrieves (a web page, a document, an email) rather than typed by the user. It is dangerous because the attacker does not need direct access to the agent: any data source the agent reads becomes an attack surface.
Related: Prompt Injection, RAG, Sandbox, Tool Poisoning
Source: Greshake et al., 2023 - Indirect Prompt Injection
Jailbreak
A jailbreak is a prompt or sequence of prompts that bypasses a model's safety policies - for example, by reframing the request, claiming a different role, or encoding the request to evade keyword filters. Jailbreaks and prompt injections overlap but are not identical: a jailbreak targets safety policy, an injection targets task instructions.
Related: Prompt Injection, Guardrail, Red Teaming, Constitutional AI
Source: OWASP Top 10 for LLM Applications
Sandbox
A sandbox is an isolated execution environment that limits what code, tool calls, or filesystem access an agent can perform. Sandboxing is the principal defence-in-depth control against both bugs and prompt injection - the agent might try to do anything, but the sandbox bounds what can happen.
Related: Code Interpreter, Computer Use, Guardrail
Source: Amazon Bedrock AgentCore - Code Interpreter
Guardrail
A guardrail is a policy enforcement layer that sits between the model and the world - filtering harmful content, masking PII, blocking off-topic responses, or rejecting prompts that violate policy. Guardrails are typically implemented as separate models or rule engines, not as additions to the system prompt, so that they cannot be jailbroken away.
Related: Output Filter, PII Redaction, Constitutional AI, Prompt Injection
Source: Amazon Bedrock - Guardrails
Output Filter
An output filter inspects model outputs after generation and blocks, redacts, or rewrites content that violates policy (toxic content, regulated topics, secrets). It is the post-hoc complement to input-side guardrails.
Related: Guardrail, PII Redaction, Constitutional AI, Red Teaming
Source: Amazon Bedrock - Guardrails
Constitutional AI
Constitutional AI is an Anthropic-introduced training and inference technique in which a model critiques and revises its own outputs against an explicit written set of principles (a "constitution"). At inference time the constitutional pattern can also be applied prompt-side as a self-critique loop.
Related: Self-Critique, Guardrail, Reflection, Red Teaming
Source: Anthropic - Constitutional AI
Red Teaming
Red teaming is the practice of deliberately attacking an agent - with jailbreaks, prompt injections, edge-case inputs - to find policy and safety failures before users do. It is a continuous activity, not a one-off audit, and is increasingly automated with adversarial agents.
Related: Jailbreak, Prompt Injection, Indirect Prompt Injection, Guardrail
Source: OWASP Top 10 for LLM Applications
Tool Poisoning
Tool poisoning is an attack in which the description or schema of a tool (often an MCP tool from a third-party server) is crafted to manipulate the model into mis-using it. Because the model reads tool descriptions as part of its prompt, an attacker who controls a tool description controls a slice of the system prompt.
Related: Prompt Injection, MCP, Sandbox
Source: OWASP Top 10 for LLM Applications
PII Redaction
PII redaction detects and removes (or masks) personally identifiable information from model inputs, retrieved content, or outputs. It is a baseline control for any agent that touches user data and is typically implemented as a separate detector model or rule engine.
Related: Guardrail, Output Filter, Prompt Injection, Red Teaming
Source: Amazon Bedrock - Sensitive information filters
I. Lifecycle and Observability
Trace
A trace is the end-to-end record of a single agent invocation - the chain of LLM calls, tool calls, retrievals, and decisions that led to the final response. Traces are the unit of debugging for agents the way HTTP traces are for distributed systems.
Related: Span, Agent Observability, Trajectory Evaluation, Session Replay
Source: OpenTelemetry - Traces
Span
A span is a single named operation inside a trace - one LLM call, one tool invocation, one retrieval - with start time, duration, attributes, and parent reference. Spans nest to form the tree of work that a trace records.
Related: Trace, Agent Observability, Latency Budget, Token Usage Tracking
Source: OpenTelemetry - Traces
Agent Observability
Agent observability is the practice of instrumenting agents so that every decision, tool call, retrieval, and model output is recorded as structured telemetry. It generalises classical observability (metrics, logs, traces) to include token usage, prompts, and judge scores.
Related: Trace, Span, Trajectory Evaluation, Session Replay
Source: Amazon Bedrock AgentCore - Observability
Session Replay
Session replay is the ability to re-run a recorded agent session deterministically - feeding back the same inputs, the same tool responses, and the same model outputs - to debug or to re-evaluate. It depends on traces that capture every input the agent saw, including non-deterministic ones.
Related: Trace, Agent Observability, Regression Test, Evaluation Set
Source: LangSmith - Observability
Evaluation Set
An evaluation set is a curated collection of inputs (and often reference outputs) used to score agent performance. Evaluation sets differ from golden datasets in scope: a golden set is the ground-truth subset; an evaluation set may include adversarial, exploratory, or long-tail cases without known answers.
Related: Golden Dataset, Regression Test, DeepEval, Promptfoo
Source: LangSmith - Evaluation concepts
Regression Test
A regression test runs the agent on a fixed evaluation set on every change and flags drops in score. Without regression tests every prompt edit, model upgrade, or tool change is a gamble. Modern agent platforms run regression tests as part of CI.
Related: Evaluation Set, Golden Dataset, Promptfoo, DeepEval
Source: Promptfoo - Introduction
Token Usage Tracking
Token usage tracking records, per call, the number of input and output tokens consumed (and increasingly, cached tokens, reasoning tokens, and tool-result tokens). It is the basis for cost accounting, budget enforcement, and quality/cost trade-off analysis.
Related: Latency Budget, Span, Agent Observability, Context Window
Source: Anthropic - Messages API
Latency Budget
A latency budget is the maximum end-to-end time a user-facing agent invocation is allowed to consume, with sub-budgets allocated to retrieval, model calls, tool calls, and post-processing. Budgets turn "agents are slow" from a vague complaint into a measurable constraint that drives architecture decisions (caching, parallel tool calls, smaller models for routing).
Related: Parallel Tool Calls, Span, Trace, Token Usage Tracking
Source: OpenTelemetry - Traces
Related hidekazu-konishi.com Articles
- Amazon Bedrock AgentCore - Beginner's Guide
- Amazon Bedrock AgentCore - Production Guide
- Amazon Bedrock AgentCore Implementation Guide - Part 1: Foundation
- Amazon Bedrock AgentCore Implementation Guide - Part 2: Security
- Amazon Bedrock AgentCore Implementation Guide - Part 3: Infrastructure
- Amazon Bedrock AgentCore Implementation Guide - Part 4: Multi-Agent
- MCP Server on AWS Lambda - Complete Guide
- Claude Code - Getting Started Guide
- Claude Code - Harness and Environment Engineering Guide
- Enterprise AI Agent Design Notes - Part 1
- Enterprise AI Agent Design Notes - Part 2
- Enterprise AI Agent Design Notes - Part 3
- AI and Machine Learning Glossary for AWS
References
- Model Context Protocol Specification
- Agent2Agent (A2A) Protocol Specification
- Amazon Bedrock AgentCore Developer Guide
- Anthropic - Building Effective Agents
- Anthropic - Tool Use Documentation
- OpenAI - Function Calling
- LangGraph
- CrewAI
- AutoGen (Microsoft Research)
- Strands Agents SDK (strands-agents/sdk-python)
- Mastra
- OWASP Top 10 for LLM Applications
- OpenTelemetry - Traces
- Ragas
- DeepEval
- Promptfoo
- Yao et al., 2022 - ReAct
- Yao et al., 2023 - Tree of Thoughts
- Wei et al., 2022 - Chain of Thought
- Shinn et al., 2023 - Reflexion
- Bai et al., 2022 - Constitutional AI
Summary
This glossary collects the essential terms that engineers building, scaling, or evaluating AI agents repeatedly encounter - across reasoning patterns (CoT, ReAct, ToT, Reflection), memory architectures, tool use and function calling, the MCP and A2A protocols, orchestration frameworks (LangGraph, CrewAI, AutoGen, Strands Agents, Mastra, Amazon Bedrock AgentCore Runtime), retrieval and RAG, evaluation, security, and observability.
The page is intended as a stable reference: each definition is short enough to read in one breath, each Related line maps the term to its neighbours, and each Source link goes to the canonical specification, paper, or vendor documentation. I will continue to update this glossary as new protocols, frameworks, and patterns become part of the working vocabulary of agent engineering.
References:
Tech Blog with curated related content