Event-Driven Serverless Architecture on AWS - Building Resilient Workflows with API Gateway, Lambda, EventBridge, Step Functions, and DynamoDB
First Published:
Last Updated:
1. Introduction
If you have built anything serverless on AWS, you already know the parts: Amazon API Gateway in front, AWS Lambda for compute, Amazon EventBridge and Amazon SNS for routing, Amazon SQS for buffering, AWS Step Functions for workflows, and Amazon DynamoDB for state. The hard part is not the parts. The hard part is assembling them into one system that behaves correctly when things go wrong — when a message is delivered twice, when a downstream dependency is slow, when one event in a batch is malformed, when a payment succeeds but inventory reservation fails halfway through a multi-step process.This article is a single, end-to-end implementation walkthrough of one named reference architecture. It is deliberately not a survey of services, and it is not a "which messaging service should I pick" comparison. Service selection — SQS vs SNS vs EventBridge, REST vs HTTP API, Standard vs Express — is a deep topic that already has a home on this site, and this article delegates those decisions to AWS Messaging and Event Routing Decision Guide and Amazon API Gateway Decision Guide. Here, the parts are already chosen; the goal is to make them work together reliably.
What you get by the end is a concrete mental model and reusable infrastructure for: the synchronous-to-asynchronous boundary, choreography with EventBridge, fan-out and buffering with SNS and SQS, idempotency and ordering that produce exactly-once effects on top of at-least-once delivery, long-running orchestration and the saga (compensation) pattern with Step Functions, the failure modes and blast radius of each component with a dead-letter and replay strategy, and end-to-end observability driven by a correlation ID that travels with every request.
Every AWS limit, default, and behavior in this article was verified against the official documentation at the time of writing. Service quotas and feature sets change; treat the AWS documentation linked in References as the source of truth, and confirm any number you depend on against AWS Service Quotas for your account and Region.
2. The Reference Architecture at a Glance
The backbone for the entire article is a single named system: an Order Processing and Fulfillment pipeline. A client submits an order over HTTPS; the system accepts it durably and immediately, then processes it asynchronously through payment, inventory, and notification steps, persisting state along the way and tolerating partial failures.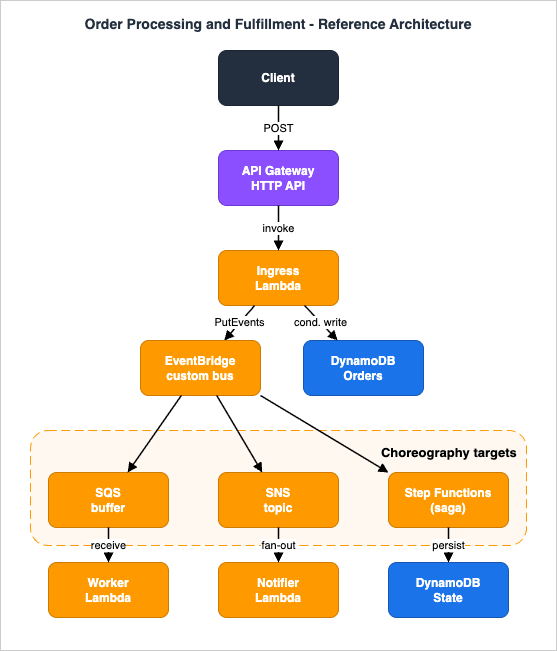
- Amazon API Gateway (HTTP API) — the synchronous front door; authenticates the caller, validates the request, and returns immediately.
- Ingress AWS Lambda — accepts the order idempotently, writes the canonical record, and publishes a domain event. (API Gateway can also integrate directly with SQS, EventBridge, or Step Functions without a Lambda — see section 3.)
- Amazon DynamoDB — the system of record for orders and for derived state (saga progress, idempotency tokens), using conditional writes for consistency.
- Amazon EventBridge (custom event bus) — choreography: it receives domain events such as
OrderPlacedand routes copies to many independent consumers by rule, with no consumer knowing about any other. - Amazon SQS — buffering and backpressure: it decouples bursty producers from rate-limited consumers and isolates poison messages.
- Amazon SNS — fan-out: a single publish reaches multiple subscribers (typically SQS queues) with per-subscription filtering.
- AWS Step Functions — orchestration: a single state machine drives the multi-step fulfillment process and, critically, runs compensating actions when a later step fails.
Choreography and orchestration are used together, on purpose. Choreography (EventBridge) is the right tool for loosely coupled, fan-out domain events where each consumer reacts independently and you want to add consumers without touching producers. Orchestration (Step Functions) is the right tool for a bounded, multi-step business transaction that needs ordered steps, timeouts, retries with backoff, and — when something fails midway — a deterministic rollback. A common mistake is to force everything into one model: pure choreography turns a saga into an untraceable web of events, while pure orchestration couples every minor side effect into one brittle state machine. This architecture uses choreography at the seams and orchestration inside the transaction.
2.1 Following one order end to end
Before implementing the pieces, it helps to watch a singleOrderPlaced request travel the whole system:- The client POSTs the order to API Gateway, which validates the caller's JWT and forwards the request to the ingress Lambda.
- The ingress writes an
ACCEPTEDorder item with a conditional write (idempotent), stamps a correlation ID, publishes anOrderPlacedevent to the custom bus, and returns202with a status URL. - EventBridge evaluates its rules and delivers a copy of the event to three independent targets: the payment SQS buffer, the notifications SNS topic, and the fulfillment Step Functions state machine.
- The payment worker polls its queue, processes each message idempotently, writes a
PAYMENTitem, and reports any failed records for partial-batch retry. - SNS fans the notification out to per-channel SQS queues, each filtered to the subscribers that want it; notifier Lambdas drain them independently.
- The state machine runs the saga — reserve inventory, charge payment, mark fulfilled — or, on failure, release inventory and cancel the order, updating the DynamoDB order status at each transition.
- Every write to the orders table emits a DynamoDB Streams record, which can publish derived events back onto the bus.
- Anything that cannot be processed lands in the relevant dead-letter queue, and the correlation ID ties every hop's logs and traces together for diagnosis.
The rest of this article implements each of these hops in turn, then examines how they fail and how the system stays diagnosable when they do.
3. Synchronous Ingress and the Sync/Async Boundary
The first design decision is where to stop being synchronous. The client deserves a fast, definitive answer that its request was accepted; it does not need to wait for payment capture and warehouse reservation. The boundary belongs right after the request is durably recorded.3.1 Accept fast, return 202
The ingress path does the minimum work required to make the request safe to process later: authenticate, validate, persist the canonical order record, publish a domain event, and return202 Accepted with the order identifier and a status URL the client can poll. Everything expensive happens after the response is sent.3.2 Idempotent acceptance
Clients retry. Networks duplicate. If the same order submission arrives twice, you must not create two orders or charge the customer twice. The ingress enforces idempotency at the boundary using a client-supplied idempotency key (commonly anIdempotency-Key HTTP header) and a DynamoDB conditional write: the first write wins, and the duplicate fails the condition and is treated as a no-op that returns the original result.# ingress/app.py - accept an order idempotently and publish a domain event
import json
import os
import boto3
from botocore.exceptions import ClientError
from aws_lambda_powertools import Logger, Tracer
logger = Logger() # structured JSON logs
tracer = Tracer() # AWS X-Ray segments
ddb = boto3.client("dynamodb")
events = boto3.client("events")
ORDERS_TABLE = os.environ["ORDERS_TABLE"]
EVENT_BUS = os.environ["EVENT_BUS_NAME"]
@tracer.capture_lambda_handler
@logger.inject_lambda_context
def handler(event, context):
body = json.loads(event["body"])
# The idempotency key is supplied by the client; fall back to API Gateway's request id.
idem_key = event["headers"].get("idempotency-key") or event["requestContext"]["requestId"]
correlation_id = event["headers"].get("x-correlation-id") or event["requestContext"]["requestId"]
logger.append_keys(correlation_id=correlation_id, order_id=idem_key)
try:
# First writer wins. A duplicate submission fails the condition and is a safe no-op.
ddb.put_item(
TableName=ORDERS_TABLE,
Item={
"pk": {"S": f"ORDER#{idem_key}"},
"sk": {"S": "META"},
"status": {"S": "ACCEPTED"},
"payload": {"S": json.dumps(body)},
"correlation_id": {"S": correlation_id},
},
ConditionExpression="attribute_not_exists(pk)",
)
except ClientError as exc:
if exc.response["Error"]["Code"] == "ConditionalCheckFailedException":
logger.info("duplicate submission ignored")
return _accepted(idem_key, correlation_id) # idempotent: return the original outcome
raise
# Publish the domain event for choreography. detail-type and source drive EventBridge rules.
events.put_events(
Entries=[{
"EventBusName": EVENT_BUS,
"Source": "orders.api",
"DetailType": "OrderPlaced",
"Detail": json.dumps({"orderId": idem_key, "correlationId": correlation_id, "order": body}),
"TraceHeader": os.environ.get("_X_AMZN_TRACE_ID", ""),
}]
)
return _accepted(idem_key, correlation_id)
def _accepted(order_id, correlation_id):
return {
"statusCode": 202,
"headers": {"x-correlation-id": correlation_id},
"body": json.dumps({"orderId": order_id, "status": "ACCEPTED"}),
}ConditionExpression="attribute_not_exists(pk)" is what makes the create idempotent — DynamoDB rejects the second writer with ConditionalCheckFailedException, and the handler converts that into the same 202 the first caller saw. And the correlation ID is established here, at the very edge, then threaded into the DynamoDB item, the EventBridge event detail, and every structured log line. Everything downstream inherits it (see section 10).3.3 Direct service integrations (no Lambda)
A Lambda in the ingress path is convenient when you need validation, enrichment, or idempotency logic. When you do not, API Gateway HTTP APIs support direct AWS service integrations that remove the function entirely. The supported subtypes include Amazon EventBridge (PutEvents), Amazon SQS (SendMessage, ReceiveMessage, DeleteMessage, PurgeQueue), Amazon Kinesis (PutRecord), AWS AppConfig (GetConfiguration), and AWS Step Functions (StartExecution, StartSyncExecution, StopExecution). For a pure "drop this onto the bus" or "enqueue this" endpoint, a direct integration is less code to run and one fewer cold start to worry about.# template.yaml (excerpt) - HTTP API + ingress Lambda + custom event bus
AWSTemplateFormatVersion: "2010-09-09"
Transform: AWS::Serverless-2016-10-31
Globals:
Function:
Runtime: python3.12
Architectures: [arm64]
MemorySize: 512
Timeout: 15
Tracing: Active # enable AWS X-Ray active tracing
LoggingConfig:
LogFormat: JSON
Resources:
OrdersBus:
Type: AWS::Events::EventBus
Properties:
Name: orders-bus
OrdersTable:
Type: AWS::DynamoDB::Table
Properties:
BillingMode: PAY_PER_REQUEST
AttributeDefinitions:
- { AttributeName: pk, AttributeType: S }
- { AttributeName: sk, AttributeType: S }
KeySchema:
- { AttributeName: pk, KeyType: HASH }
- { AttributeName: sk, KeyType: RANGE }
StreamSpecification:
StreamViewType: NEW_AND_OLD_IMAGES # power derived events (see section 8)
IngressFunction:
Type: AWS::Serverless::Function
Properties:
CodeUri: ingress/
Handler: app.handler
Environment:
Variables:
ORDERS_TABLE: !Ref OrdersTable
EVENT_BUS_NAME: !Ref OrdersBus
Policies: # least privilege: only what ingress needs
- DynamoDBWritePolicy: { TableName: !Ref OrdersTable }
- EventBridgePutEventsPolicy: { EventBusName: !Ref OrdersBus }
Events:
PostOrder:
Type: HttpApi
Properties:
Path: /orders
Method: POSTPolicies block is the first appearance of a theme that runs through the whole architecture: each component is granted only the permissions it uses. The ingress can write the orders table and put events on the bus — nothing else (see section 6.4 for least-privilege between components, and AWS Lambda Concurrency and Scaling Guide for how the ingress scales under load).3.4 Authorization, validation, and throttling at the edge
The cheapest request to process is the one you reject before it costs anything downstream. API Gateway HTTP APIs validate identity at the edge with a built-in JWT authorizer: you point it at an OpenID Connect issuer (for example an Amazon Cognito user pool) with an expected audience, and API Gateway verifies the token's signature against the issuer's public key, checks theiss, aud, and exp claims, optionally enforces per-route scopes, and passes the validated claims through to the integration — all before your Lambda runs. For authorization logic that JWT claims cannot express, a Lambda authorizer runs custom code and returns an allow/deny decision plus a context object the ingress can read. HTTP APIs also apply throttling at the route and stage level, which is the first backpressure layer in the entire system: it caps the request rate at the front door so a traffic spike is shed as 429 Too Many Requests responses instead of becoming a flood of events the back end must absorb. The deep authorization design — authorizer types, mutual TLS, and the REST-vs-HTTP trade-off — is covered in Amazon API Gateway Decision Guide; the point here is that identity, basic request shape, and rate are all enforced before the asynchronous machine even starts.4. Choreography with EventBridge
Once an order is recorded, the ingress publishes a singleOrderPlaced event to a custom event bus and forgets about it. EventBridge takes over routing. This is choreography: the producer announces a fact ("an order was placed"); independent consumers decide what to do about it.4.1 Event bus, rules, and targets
A rule on the bus matches events with an event pattern and forwards matching events to one or more targets (Lambda functions, SQS queues, SNS topics, Step Functions state machines, and many others). Because each consumer attaches its own rule, you can add a new consumer — a fraud-screening function, an analytics sink — by adding a rule, with zero changes to the producer. That decoupling is the entire point of choreography.# template.yaml (excerpt) - route OrderPlaced to a buffered worker, with a target DLQ
PaymentQueue:
Type: AWS::SQS::Queue
Properties:
VisibilityTimeout: 90 # >= 6x the worker's timeout (see section 5)
RedrivePolicy:
deadLetterTargetArn: !GetAtt PaymentDLQ.Arn
maxReceiveCount: 5
PaymentDLQ: # consumer-failure DLQ (SQS redrive target)
Type: AWS::SQS::Queue
Properties:
MessageRetentionPeriod: 1209600 # 14 days (max) to give you time to investigate
PaymentRuleDLQ: # delivery-failure DLQ (EventBridge rule target)
Type: AWS::SQS::Queue
Properties:
MessageRetentionPeriod: 1209600
OrderPlacedToPaymentRule:
Type: AWS::Events::Rule
Properties:
EventBusName: !Ref OrdersBus
EventPattern:
source: ["orders.api"]
detail-type: ["OrderPlaced"]
Targets:
- Id: PaymentQueue
Arn: !GetAtt PaymentQueue.Arn
DeadLetterConfig: # rule-level DLQ for undeliverable target invocations
Arn: !GetAtt PaymentRuleDLQ.ArnRedrivePolicy → PaymentDLQ (for messages the consumer cannot process) and the EventBridge rule's DeadLetterConfig → PaymentRuleDLQ (for events EventBridge cannot deliver to the target at all). They protect different failure modes, so keeping them apart makes triage unambiguous; section 9 maps all four dead-letter mechanisms out.4.2 The event envelope and schema evolution
Events are a contract. EventBridge wraps every event in a standard envelope (source, detail-type, time, region, id, and your detail payload); your domain data lives in detail. Treat the detail shape as a versioned public interface: add fields freely, never repurpose or remove a field that consumers read. When a breaking change is unavoidable, introduce a new detail-type (for example OrderPlaced.v2) and run both until consumers migrate. The EventBridge Schema Registry can infer and store these schemas and generate typed bindings, which makes the contract explicit and discoverable.4.3 PutEvents limits that shape your design
PutEvents accepts up to 10 entries per request, and the total entry size of the request must be less than 1 MB; nested JSON is processed up to 1,000 levels deep. These limits push two habits: keep events small (publish a reference and a few key attributes, not a whole document — fetch the rest from DynamoDB or S3 by ID), and batch related events into one PutEvents call when you are emitting many at once. If an entry fails, the response reports a non-zero FailedEntryCount with per-entry error codes; treat a partial failure as a retryable condition for the failed entries only.4.4 Pipes and Scheduler - where they fit
Two EventBridge capabilities are adjacent to the bus and worth placing precisely:- EventBridge Pipes is point-to-point: it connects one source (SQS, DynamoDB Streams, Kinesis, MSK, Amazon MQ) to one target, with optional filtering and enrichment (via Lambda, Step Functions, API Gateway, or API destinations) in between. Use the bus for one-to-many fan-out; use a pipe for a single source-to-target hop where you would otherwise write glue code. The deep treatment of Pipes patterns lives in Amazon EventBridge Pipes and Event-Driven Architecture Patterns.
- EventBridge Scheduler triggers targets on a schedule or one-time at scale — for example, "cancel this order if it is still unpaid in 30 minutes." It replaces ad-hoc scheduled rules for time-based actions.
4.5 Targeting precisely: event patterns and input transformers
Two rule features keep choreography clean. An event pattern matches not only onsource and detail-type but on the content of detail, so a rule can subscribe to a narrow slice — "orders flagged for manual review," "orders in a specific region" — without the consumer filtering anything itself. An input transformer then reshapes the matched event into exactly the payload the target expects, so you can route the same domain event to consumers with different input contracts without changing the producer.{
"EventPattern": {
"source": ["orders.api"],
"detail-type": ["OrderPlaced"],
"detail": {
"order": {
"region": ["ap-northeast-1"],
"review": [{ "exists": true }]
}
}
},
"InputTransformer": {
"InputPathsMap": { "id": "$.detail.orderId", "corr": "$.detail.correlationId" },
"InputTemplate": "{ \"orderId\": \"<id>\", \"correlationId\": \"<corr>\", \"action\": \"review\" }"
}
}OrderPlaced event safely serve a payment worker, a notifier, a fraud reviewer, and an analytics sink at once.5. Fan-Out and Buffering with SNS and SQS
EventBridge gets the order to the right consumers; SNS and SQS govern how many copies go where and at what rate. These two services do different jobs and are most powerful combined.5.1 SNS fan-out with filter policies
When one event must reach several independent subscribers, an SNS topic fans a single publish out to all of them. The durable, replayable pattern is SNS-to-SQS fan-out: the topic delivers to multiple SQS queues, each owned by one consumer, so a slow or failing consumer drains its own queue without affecting the others. Subscription filter policies let each queue receive only the subset it cares about — attribute-based filtering (the default) matches on message attributes, while payload-based filtering can match inside the message body and supports nested policies. Filter policy constraints to design within: up to 5 keys, the total combination of values not exceeding 150, and a maximum policy size of 256 KB.# template.yaml (excerpt) - SNS fan-out to a filtered SQS queue
NotificationsTopic:
Type: AWS::SNS::Topic
EmailQueue:
Type: AWS::SQS::Queue
EmailSubscription:
Type: AWS::SNS::Subscription
Properties:
TopicArn: !Ref NotificationsTopic
Protocol: sqs
Endpoint: !GetAtt EmailQueue.Arn
RawMessageDelivery: true
FilterPolicy: # this queue only wants high-value orders
channel: ["email"]
tier: ["gold", "platinum"]5.2 SQS as a shock absorber
An SQS queue between a bursty producer and a rate-limited consumer is what keeps the system standing under load. Producers write at their own pace; consumers read at theirs. Three settings tie the queue to its consumer:- Visibility timeout — when a consumer receives a message it becomes invisible to others for this window (default 30 seconds, maximum 12 hours). The rule of thumb is to set it to at least six times your function timeout so a slow-but-succeeding invocation is not redelivered while still running. If it is too short, you get duplicate processing; if it is too long, recovery from a crashed consumer is slow.
- Message retention — how long an unconsumed message survives (default 4 days, minimum 60 seconds, maximum 14 days). Set the DLQ to 14 days so failed messages wait for you.
- Maximum message size — 1 MiB (1,048,576 bytes). For larger payloads, store the body in Amazon S3 and enqueue a reference (the Amazon SQS Extended Client Library does this, supporting payloads up to 2 GB). This is one place SNS and SQS differ: an SNS message is capped at 256 KB, so if you fan out through SNS, size to the smaller limit.
5.3 Ordering and de-duplication with FIFO
Standard queues and topics deliver at-least-once with best-effort ordering, which is the right default for throughput. When per-entity ordering matters — all events for one order must be processed in sequence — use FIFO. A FIFO queue preserves order within a message group (MessageGroupId, for example the order ID) while processing different groups in parallel, and it de-duplicates sends within a 5-minute deduplication interval using either a MessageDeduplicationId you supply or content-based deduplication (a SHA-256 hash of the body). FIFO throughput is based on API request limits — 300 transactions per second per partition in non-high-throughput mode, scaling higher with high-throughput mode and batching. Reach for FIFO only where ordering or send-side de-duplication is a real requirement; it is not free throughput.5.4 Backpressure: don't let upstream flood downstream
Buffering only helps if consumers do not blow past the capacity of whatever they call next. The maximum concurrency setting on an SQS event source mapping (configurable from 2 to 1,000) caps how many concurrent Lambda invocations one queue can drive, so a deep backlog cannot consume your whole account concurrency or overwhelm a fragile downstream database. This is cleaner than the older reserved-concurrency workaround, which could push messages back to the queue or to the DLQ when the limit was hit. Pair it with a downstream that fails fast, and the queue depth becomes your pressure gauge rather than your outage. The scaling mechanics of the consumers themselves are covered in AWS Lambda Concurrency and Scaling Guide.6. Idempotency, Ordering, and Exactly-Once Effects
The single most important idea in this architecture: AWS messaging is at-least-once, so your processing must be idempotent. EventBridge, SNS, and SQS standard queues can all deliver a message more than once. Lambda retries failed invocations. You do not get exactly-once delivery; you engineer exactly-once effects by making every side effect safe to repeat.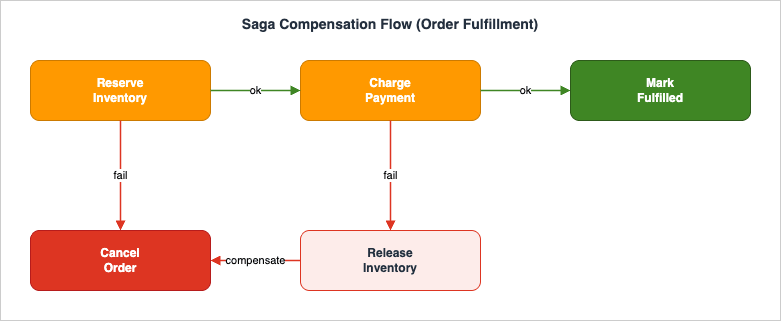
6.1 Idempotency with DynamoDB conditional writes
The lowest-level, most reliable tool is the DynamoDB conditional write you already saw in section 3.attribute_not_exists(pk) turns "create this record" into a one-time operation no matter how many times it runs. For updates, the same idea with a version attribute gives you optimistic locking: ConditionExpression="version = :expected" rejects writers working from stale data, and ReturnValuesOnConditionCheckFailure hands back the current item so a retry can re-evaluate without a separate read. For multi-item atomic effects, TransactWriteItems applies all-or-nothing across items.6.2 Idempotency with Lambda Powertools
For function-level idempotency, the Powertools for AWS Lambda idempotency utility removes the boilerplate. You annotate a handler or function with@idempotent, point it at a DynamoDB persistence layer, and it hashes the event (or a JMESPath-selected subset of it) into an idempotency key. The first invocation runs and stores its result; duplicate invocations within a configurable window return the stored result without re-running the body. It also handles an in-progress state so two concurrent duplicates do not both execute, and it uses the DynamoDB TTL attribute to expire records automatically. The persistence table is a simple one: an id partition key and an expiration TTL attribute.# worker/app.py - an idempotent worker that consumes the payment queue
import os
from aws_lambda_powertools import Logger
from aws_lambda_powertools.utilities.idempotency import (
idempotent_function,
DynamoDBPersistenceLayer,
IdempotencyConfig,
)
logger = Logger()
persistence = DynamoDBPersistenceLayer(table_name=os.environ["IDEMPOTENCY_TABLE"])
# Use the business key (orderId) as the idempotency key, not the whole SQS envelope,
# so a redelivered message and a retried invocation map to the same key.
config = IdempotencyConfig(event_key_jmespath="orderId")
@idempotent_function(data_keyword_argument="order", persistence_store=persistence, config=config)
def charge_payment(order: dict) -> dict:
# Side effects here run exactly once per orderId within the TTL window.
# ... call the payment provider, write a PAYMENT item with a conditional put ...
return {"orderId": order["orderId"], "status": "CHARGED"}
def handler(event, context):
# SQS delivers a batch; report partial failures so only failed messages return to the queue.
batch_item_failures = []
for record in event["Records"]:
try:
order = _parse(record)
logger.append_keys(correlation_id=order.get("correlationId"), order_id=order["orderId"])
charge_payment(order=order)
except Exception:
logger.exception("payment failed")
batch_item_failures.append({"itemIdentifier": record["messageId"]})
return {"batchItemFailures": batch_item_failures}6.3 Ordering where it actually matters
Most steps do not need global ordering; they need per-aggregate ordering — events for a single order in sequence, events for different orders in parallel. That maps exactly to a FIFO message group keyed on the order ID (section 5.3). Do not reach for a single global FIFO stream to get "ordering"; it serializes unrelated work and becomes a bottleneck. Identify the aggregate that actually requires order, key the group on it, and let everything else run concurrently.6.4 Least privilege between components
Idempotency and correctness depend on components not doing things they should not. Grant each function only the actions and resources it needs: the ingress canPutEvents to one bus and write one table; the payment worker can read one queue, write the idempotency table, and write payment items — it cannot touch the inventory table. Scope IAM policies to specific resource ARNs, and let EventBridge and SNS assume narrowly scoped roles to invoke their targets. This is what bounds the blast radius in section 9: a compromised or buggy component can only damage what its role allows.6.5 Idempotency windows and their pitfalls
Idempotency is not permanent; it has a window. The Powertools utility expires its records by TTL, and a FIFO queue de-duplicates only within its 5-minute deduplication interval. Two pitfalls follow. First, the window must outlast the longest realistic retry horizon for the operation it guards — if a message can be redriven from a DLQ hours later, a 5-minute FIFO interval will not catch the duplicate, so the durable defense (a conditional write keyed on the business ID) has to be the backstop. Second, the idempotency key must be the business identity, not the transport envelope: keying on the SQSmessageId treats a redelivery of the same logical event as a new request, defeating the purpose. Key on the order ID (or order ID plus operation), so a retried invocation, a redelivered message, and a replayed event all collapse to the same key. The transport-level de-duplication (FIFO) is an optimization that reduces duplicates; the conditional write is the guarantee that makes the effect exactly-once.7. Long-Running Workflows with Step Functions (Orchestration and Saga)
Some work is a transaction, not a notification. Fulfilling an order means: reserve inventory, charge payment, then mark the order fulfilled — in order, with retries, and with a rollback if a later step fails after an earlier one already changed the world. That is what Step Functions is for, and the rollback is the saga pattern.7.1 Standard vs Express
Step Functions has two workflow types, and the choice is about durability vs volume:- Standard — runs up to one year, exactly-once execution semantics, full execution history, and support for the asynchronous integration patterns below. This is the right type for the fulfillment saga: it may wait on a human or an external system, and it must reliably run compensations.
- Express — runs up to 5 minutes, at-least-once semantics, very high volume (over 100,000 executions per second). Use it for short, idempotent, high-throughput steps (for example, a fast transformation invoked per event), not for a stateful transaction that must compensate.
You can combine them: a Standard workflow for the durable, compensatable transaction, calling an Express workflow for a fast idempotent sub-step.
7.2 Service integration patterns
How a task waits determines how you model long operations:- Request Response — start the action and move on as soon as the API responds. (The only pattern Express supports.)
- Run a Job (
.sync) — start the action and wait for it to complete before the next state, without writing a polling loop. - Wait for Callback (
.waitForTaskToken) — pass a task token to an external worker or a human-approval step and pause until something callsSendTaskSuccess/SendTaskFailurewith that token. Standard workflows support all three; Express supports Request Response only.
7.3 Retry, Catch, and the saga
Inside the state machine,Retry handles transient errors with exponential backoff and jitter, and Catch routes terminal errors to a compensation branch. The saga is simply: each forward step has a matching compensating step, and a failure after a successful step triggers the compensations in reverse.{
"Comment": "Order fulfillment saga (Standard workflow)",
"StartAt": "ReserveInventory",
"States": {
"ReserveInventory": {
"Type": "Task",
"Resource": "arn:aws:states:::lambda:invoke",
"Parameters": { "FunctionName": "ReserveInventory", "Payload.$": "$" },
"Retry": [
{ "ErrorEquals": ["States.TaskFailed"], "IntervalSeconds": 2,
"MaxAttempts": 3, "BackoffRate": 2.0 }
],
"Catch": [ { "ErrorEquals": ["States.ALL"], "Next": "CancelOrder" } ],
"Next": "ChargePayment"
},
"ChargePayment": {
"Type": "Task",
"Resource": "arn:aws:states:::lambda:invoke",
"Parameters": { "FunctionName": "ChargePayment", "Payload.$": "$" },
"Retry": [
{ "ErrorEquals": ["States.TaskFailed"], "IntervalSeconds": 2,
"MaxAttempts": 3, "BackoffRate": 2.0 }
],
"Catch": [ { "ErrorEquals": ["States.ALL"], "Next": "ReleaseInventory" } ],
"Next": "MarkFulfilled"
},
"MarkFulfilled": {
"Type": "Task",
"Resource": "arn:aws:states:::dynamodb:updateItem",
"Parameters": {
"TableName": "Orders",
"Key": { "pk": { "S.$": "States.Format('ORDER#{}', $.orderId)" }, "sk": { "S": "META" } },
"UpdateExpression": "SET #s = :fulfilled",
"ExpressionAttributeNames": { "#s": "status" },
"ExpressionAttributeValues": { ":fulfilled": { "S": "FULFILLED" } }
},
"End": true
},
"ReleaseInventory": {
"Type": "Task",
"Resource": "arn:aws:states:::lambda:invoke",
"Parameters": { "FunctionName": "ReleaseInventory", "Payload.$": "$" },
"Next": "CancelOrder"
},
"CancelOrder": {
"Type": "Task",
"Resource": "arn:aws:states:::dynamodb:updateItem",
"Parameters": {
"TableName": "Orders",
"Key": { "pk": { "S.$": "States.Format('ORDER#{}', $.orderId)" }, "sk": { "S": "META" } },
"UpdateExpression": "SET #s = :cancelled",
"ExpressionAttributeNames": { "#s": "status" },
"ExpressionAttributeValues": { ":cancelled": { "S": "CANCELLED" } }
},
"End": true
}
}
}ReleaseInventory releasing an already-released reservation must be a no-op (a conditional write on the reservation record does this). And the workflow's progress is durable in Step Functions, but the business state lives in DynamoDB — the state machine drives the steps; the order's authoritative status is the DynamoDB item the steps update. For larger fan-out inside a workflow (process thousands of order lines in parallel), Step Functions Distributed Map is the tool; its mechanics and the JSONata/variables model are covered in AWS Step Functions Distributed Map Guide and AWS Step Functions JSONata and Variables Guide.7.4 The callback pattern in practice
Not every step finishes on its own. A manual approval, a partner system that calls back hours later, or an asynchronous job with no.sync integration all need the workflow to pause and wait for an external signal. The .waitForTaskToken pattern does this: the task passes a token out with its payload, the state machine suspends (without consuming compute), and an external actor resumes it by returning the token. For a fulfillment flow that requires a human sign-off above a threshold, the approval step looks like this:"AwaitApproval": {
"Type": "Task",
"Resource": "arn:aws:states:::sqs:sendMessage.waitForTaskToken",
"Parameters": {
"QueueUrl": "https://sqs.ap-northeast-1.amazonaws.com/111122223333/approvals",
"MessageBody": {
"orderId.$": "$.orderId",
"taskToken.$": "$$.Task.Token"
}
},
"TimeoutSeconds": 86400,
"Catch": [ { "ErrorEquals": ["States.Timeout"], "Next": "CancelOrder" } ],
"Next": "ChargePayment"
}TimeoutSeconds guard ensures the execution does not wait forever — on timeout it compensates and cancels.# Resume a paused workflow once the approval decision is made.
aws stepfunctions send-task-success \
--task-token "$TASK_TOKEN" \
--task-output '{"approved": true, "approver": "ops-oncall"}'
# Or reject, which routes to the Catch branch and triggers compensation.
aws stepfunctions send-task-failure \
--task-token "$TASK_TOKEN" --error "Rejected" --cause "Manual review declined"8. State and the Data Tier (DynamoDB)
State is what makes the system trustworthy across retries, restarts, and failures. DynamoDB holds three kinds of state here: the canonical order (system of record), saga progress (status transitions the workflow writes), and idempotency tokens (the Powertools persistence table).8.1 Consistency through conditional writes
Every state transition that must happen at most once, or must not regress, is a conditional write: create-once withattribute_not_exists, advance-once with a status guard (ConditionExpression="#s = :expected_prior_status"), and concurrent-safe updates with a version counter. This is what lets multiple consumers act on the same order without corrupting it. Detailed item and key modeling — single-table design, access patterns, GSIs — is its own discipline and is covered in Amazon DynamoDB Single-Table Design Guide.8.2 DynamoDB Streams as a source of derived events
A change to the orders table can itself be an event. With Streams enabled (NEW_AND_OLD_IMAGES in the SAM template above), every write produces a stream record you can consume — with a Lambda trigger, or with an EventBridge Pipe that filters and forwards changes onto the bus. This is the transactional outbox pattern done natively: you write business state and emit the corresponding event from the same committed change, so you never publish an event for a write that did not commit, or commit a write whose event was lost. Stream consumers, like queue consumers, must be idempotent and support partial-batch responses (section 9).8.3 TTL for ephemeral state
Idempotency records, short-lived locks, and saga scratch state should not live forever. DynamoDB TTL deletes expired items automatically (best-effort, typically within a few days of expiry), which keeps the idempotency table small and bounds how long a duplicate is suppressed. Set the TTL window to comfortably exceed the longest plausible retry horizon for the operation it protects.8.4 Atomic multi-item writes with transactions
Some state changes are not safe to do one item at a time. Reserving inventory and recording the reservation against the order must either both happen or neither happen; a crash between two separate writes leaves a phantom reservation or a paid-for order with no stock held.TransactWriteItems applies up to a bounded set of writes atomically, each with its own condition, so the whole group commits or none of it does.# Reserve stock and record the reservation atomically and idempotently.
ddb.transact_write_items(
TransactItems=[
{
"Update": {
"TableName": "Inventory",
"Key": {"pk": {"S": "SKU#A100"}},
"UpdateExpression": "SET available = available - :q",
"ConditionExpression": "available >= :q", # never oversell
"ExpressionAttributeValues": {":q": {"N": "1"}},
}
},
{
"Put": {
"TableName": "Orders",
"Item": {
"pk": {"S": "ORDER#o-10231"}, "sk": {"S": "RESERVATION#A100"},
"qty": {"N": "1"},
},
"ConditionExpression": "attribute_not_exists(pk)", # idempotent reserve
}
},
]
)available >= :q) prevents overselling under concurrency, and the reservation's attribute_not_exists condition makes a retried reservation a no-op. Transactions cost more than single writes and have item limits, so reserve them for the few changes that genuinely must be atomic; most transitions in this architecture are single conditional writes.9. Failure Modes, Blast Radius, and Dead-Letter Strategy
A Level 400 architecture is judged by what happens when a part fails. Here is the failure map for each hop, what it threatens, and how it is contained.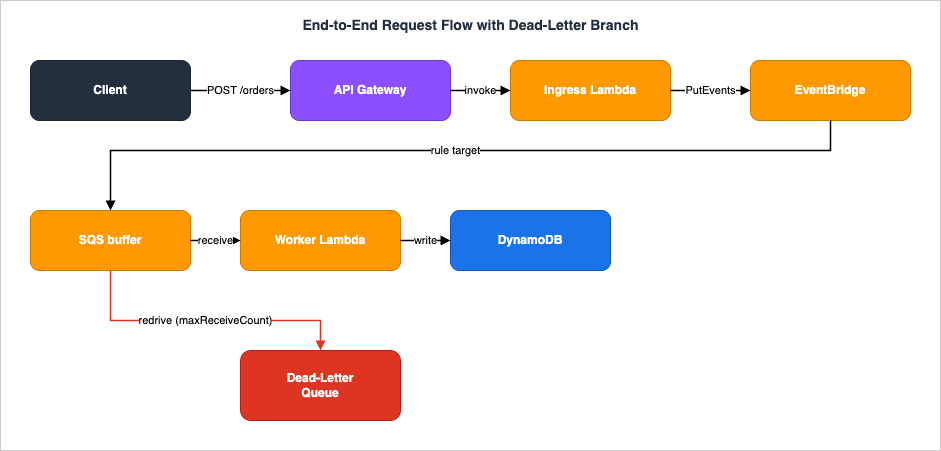
9.1 Poison messages and partial batches
A single malformed message must not block a queue. WithReportBatchItemFailures enabled on the event source mapping, the worker returns the IDs of only the records it failed to process (the batchItemFailures list in section 6.2), and only those become visible again — successful records in the same batch are not reprocessed. After maxReceiveCount receives, the redrive policy moves the message to the DLQ, taking the poison out of the hot path so the rest of the queue keeps flowing. For stream sources (Kinesis, DynamoDB Streams), the analogous controls are MaximumRetryAttempts, BisectBatchOnFunctionError (split a failing batch to isolate the bad record), and an on-failure destination for record metadata.9.2 The four dead-letter mechanisms, disambiguated
"DLQ" means four different things in this architecture; mixing them up is a common production incident:| Mechanism | Protects against | What it captures |
|---|---|---|
SQS redrive policy (RedrivePolicy) | Consumer repeatedly fails to process a message | The original message, after maxReceiveCount receives |
EventBridge rule DLQ (DeadLetterConfig) | EventBridge cannot deliver an event to a target | The undelivered event with error metadata |
Lambda async DLQ (function DeadLetterConfig) | Async invocation exhausts retries | The event content only (no response detail) |
| Lambda destinations (on-failure / on-success) | Async invocation outcome routing | A richer record: request and response/context |
For asynchronous Lambda invocations specifically, the defaults are 2 retries with the event kept in the internal queue for up to 6 hours; both are configurable. Prefer destinations over the older async DLQ when you can — destinations capture request and response, support success routing as well as failure, and can target SQS, SNS, Lambda, or EventBridge (S3 for failures). When delivery to a destination fails, Lambda emits a
DestinationDeliveryFailures metric you should alarm on.9.3 Backpressure, retry storms, and quota interaction
Failure propagates through scale. If a downstream dependency slows, naive retries multiply load and turn a slowdown into an outage (a retry storm). The defenses are already in the architecture: the SQS buffer absorbs the burst, the maximum concurrency cap (section 5.4) stops the queue from flooding the dependency, exponential backoff with jitter inRetry blocks spreads the load, and the DLQ siphons off what cannot succeed. Watch the quota interactions: a producer that can PutEvents far faster than a consumer can drain, multiplied by Lambda's per-function burst of 1,000 concurrent executions per 10 seconds, can overrun a downstream that is sized smaller — which is exactly why the consumer's concurrency, not the producer's rate, must be the governing limit.9.4 Symptom, root cause, triage, remediation
A worked example of cross-service diagnosis:- Symptom: customers report orders stuck in
ACCEPTED; the DLQ depth is climbing. - Triage: check the SQS
ApproximateAgeOfOldestMessage(backlog growing?), the worker'sErrorsandThrottles(failing or being throttled?), and a sample message in the DLQ. - Root cause (common): the worker times out calling the payment provider; because the visibility timeout was shorter than the worker timeout, messages were redelivered mid-flight, retries compounded, and
maxReceiveCountpushed them to the DLQ. - Remediation: raise the visibility timeout to at least 6x the worker timeout, add a circuit breaker around the provider call, then redrive the DLQ back to the source queue once the dependency recovers.
# Inspect the backlog and the dead-letter queue, then redrive after the fix.
aws cloudwatch get-metric-statistics \
--namespace AWS/SQS --metric-name ApproximateAgeOfOldestMessage \
--dimensions Name=QueueName,Value=PaymentQueue \
--start-time "$(date -u -d '-1 hour' +%FT%TZ)" --end-time "$(date -u +%FT%TZ)" \
--period 300 --statistics Maximum
# Start a DLQ redrive back to the source queue (after the root cause is fixed).
aws sqs start-message-move-task \
--source-arn arn:aws:sqs:ap-northeast-1:111122223333:PaymentDLQ9.5 Replay and reprocessing
Some incidents require replaying events, not just messages. EventBridge archive and replay lets you archive matched events and replay them to the bus over a chosen time window — invaluable when a consumer had a bug and you need to reprocess the events it mishandled. Because consumers are idempotent (section 6), replay is safe: events that were already handled correctly become no-ops. For queue-level recovery, SQS DLQ redrive moves messages back to the source queue. Design for replay from the start — it is the difference between a five-minute recovery and a data-loss incident.9.6 Isolating a single consumer's failure
The architecture's shape is what bounds the blast radius. Because each consumer owns its own queue behind SNS or EventBridge, a consumer that is failing or slow drains (or backs up) only its queue — the payment path is unaffected by a broken analytics sink, and vice versa. Contrast this with a single shared queue read by several consumers, where one slow reader starves the others. At the routing layer, EventBridge delivers to each rule target independently and retries each with its own policy: by default it retries a transient delivery failure with exponential backoff and jitter for up to 185 attempts over 24 hours (both configurable per target), then routes the event to the rule's DLQ if one is set — otherwise the event is dropped. Permanent failures (access denied, a deleted target) are not retried at all, which is why a misconfigured rule fails silently unless you have alarmed onFailedInvocations and the rule DLQ. The design rule is simple: give every fan-out branch its own buffer and its own dead-letter destination, so a failure is contained to one branch and is recoverable rather than lost.10. Observability: Correlation IDs and Distributed Tracing
When a request crosses seven services, "look at the logs" is meaningless unless you can find this request's logs everywhere it went. The correlation ID established at ingress (section 3.2) is what makes that possible.10.1 Propagating the correlation ID
The correlation ID travels by riding in whatever each hop carries: the HTTP header at the edge, the EventBridge eventdetail, the SQS message attributes, the Step Functions execution input, and a structured-log key on every line. With Powertools Logger.append_keys(correlation_id=...), every subsequent log statement in that invocation is automatically tagged, so a single CloudWatch Logs Insights query across log groups reconstructs the whole journey.Each component then emits structured JSON logs that carry the same key, so the records line up across services:
{"level":"INFO","message":"payment captured","correlation_id":"b3f1c2a4-...-9d","order_id":"o-10231","service":"payment-worker","cold_start":false}-- CloudWatch Logs Insights: trace one request across every component's log group
fields @timestamp, @log, level, message, order_id
| filter correlation_id = "b3f1c2a4-...-9d"
| sort @timestamp asc10.2 Distributed tracing with X-Ray
With active tracing enabled (theTracing: Active global in the SAM template) and the Powertools Tracer, AWS X-Ray stitches the API Gateway entry, the ingress function, and downstream calls into a single service map and trace timeline. Propagating the X-Ray trace header through PutEvents (TraceHeader) and onward keeps asynchronous hops linked to the originating request, so a latency spike points at the exact segment responsible.10.3 The metrics that actually catch incidents
Alarm on the signals that lead failures rather than trail them:- SQS:
ApproximateAgeOfOldestMessage(the earliest sign of a stuck consumer),ApproximateNumberOfMessagesVisible(backlog), and DLQApproximateNumberOfMessagesVisible(anything greater than 0 is an incident). - Lambda:
Errors,Throttles,Duration(approaching timeout), andDestinationDeliveryFailures. - Event source mappings / streams:
IteratorAge(consumer falling behind the stream). - EventBridge:
FailedInvocationsand the rule DLQ depth. - Step Functions:
ExecutionsFailed,ExecutionsTimedOut, andExecutionThrottled.
The full cross-service observability architecture — OpenTelemetry/ADOT, Application Signals, SLOs, and correlated dashboards — is the subject of AWS Observability Architecture Guide.
11. Variations and When to Reshape the Architecture
The reference architecture is a starting point, not a mandate. The high-value variations — and the signals that you have outgrown a choice — are below. The deep selection criteria live in AWS Messaging and Event Routing Decision Guide; this section is only about when to reshape.- Choreography vs orchestration. Stay with EventBridge choreography while consumers are independent and reactive. Move a flow into a Step Functions orchestration the moment you need ordered steps, a timeout on the whole process, or compensation — i.e., when "what happened" stops being a set of independent reactions and becomes one transaction.
- Synchronous vs asynchronous. Keep the 202-and-defer boundary unless the client genuinely needs the result in the same call (then a Step Functions Express synchronous execution behind API Gateway fits). Resist making the ingress wait for fulfillment; that recouples what you decoupled.
- SQS vs Kinesis. Use SQS for work queues with independent items and per-message delete semantics. Switch to a stream (Kinesis) when you need ordered, replayable, multi-consumer event logs with high fan-in throughput — the streaming variant is its own architecture, covered in AWS Real-Time Streaming Data Pipeline Architecture Guide.
- EventBridge vs SNS. Both fan out; EventBridge offers content-based routing across many target types, schema registry, archive/replay, and SaaS integrations, while SNS offers very high-throughput pub/sub with the simplest SQS fan-out. Use SNS when you need raw fan-out throughput to SQS; use EventBridge when routing logic, replay, or heterogeneous targets matter.
- Real-time client updates. When clients need pushed updates rather than polling the status URL, a GraphQL subscription layer fits in front — see Real-Time and GraphQL API Architecture with AWS AppSync.
12. Frequently Asked Questions
12.1 Choreography or orchestration - which should I use?
Both, for different jobs. Use choreography (EventBridge) for loosely coupled, fan-out reactions where consumers are independent and you want to add them without changing producers. Use orchestration (Step Functions) for a bounded multi-step transaction that needs ordering, timeouts, retries, and compensation. The seams between bounded contexts are choreography; the inside of a transaction is orchestration.12.2 How do I make a Lambda idempotent?
Pick a stable business idempotency key (an order ID, not the SQS message ID), then either enforce it with a DynamoDB conditional write (attribute_not_exists) for create-once effects, or use the Powertools idempotency utility with a DynamoDB persistence layer for general handler-level idempotency with an in-progress lock and TTL. Make compensating actions idempotent too, since they can also be retried.12.3 Where do failed events go?
It depends on which hop failed. A message a consumer cannot process goes to the SQS DLQ via the redrive policy aftermaxReceiveCount. An event EventBridge cannot deliver to a target goes to the rule DLQ. An asynchronous Lambda invocation that exhausts its retries goes to the function's on-failure destination (preferred — it captures request and response) or its async DLQ (event content only). See the table in section 9.2.12.4 How do I trace one request across all these services?
Generate a correlation ID at ingress and propagate it through the event detail, message attributes, workflow input, and a structured-log key on every line; query it across log groups with CloudWatch Logs Insights. Enable X-Ray active tracing and propagate the trace header so the asynchronous hops link back to the originating request.12.5 Standard or FIFO queues and topics?
Default to standard for throughput; it is at-least-once with best-effort ordering, which your idempotent consumers already tolerate. Use FIFO only where you genuinely need per-group ordering or send-side de-duplication, keyed on the aggregate that requires it (e.g., the order ID), so unrelated work still runs in parallel.12.6 Do I even need Step Functions, or can EventBridge do it all?
If your flow is a set of independent reactions with no rollback, EventBridge alone is simpler. The moment you need a step to wait for an earlier step, a deadline on the whole process, or a compensation when a later step fails, hand the transaction to Step Functions — re-implementing ordered retries and compensation by hand on top of raw events is how event-driven systems become unmaintainable.13. Summary
A reliable event-driven serverless system is not a pile of services; it is a small number of deliberate decisions applied consistently. Draw the synchronous boundary right after a durable, idempotent accept and return 202. Use EventBridge choreography at the seams and Step Functions orchestration (with saga compensation) inside transactions. Buffer with SQS, fan out with SNS, and govern rate with maximum-concurrency caps so upstream never floods downstream. Assume at-least-once delivery and engineer exactly-once effects with conditional writes and Powertools idempotency. Give every failure a defined destination — disambiguate the four DLQ mechanisms — and design replay in from day one. Thread a correlation ID through every hop so one request is traceable across all seven services.From here, the natural next steps in this series extend the same backbone: AWS Real-Time Streaming Data Pipeline Architecture Guide for ordered, replayable event logs; AWS Observability Architecture Guide for the full tracing/metrics/logs stack; and Real-Time and GraphQL API Architecture with AWS AppSync for pushing live updates to clients.
14. References
- Amazon EventBridge User Guide
- Amazon EventBridge PutEvents API Reference
- Amazon EventBridge Pipes
- How EventBridge retries delivering events (retry policy and DLQ)
- Amazon SQS message quotas
- Exactly-once processing in Amazon SQS
- Handling errors for an SQS event source in Lambda
- Capturing records of Lambda asynchronous invocations (destinations and DLQ)
- Understanding Lambda function scaling and concurrency
- Choosing workflow type in AWS Step Functions (Standard vs Express)
- AWS Step Functions service integration patterns (.sync and waitForTaskToken)
- Amazon DynamoDB condition expressions (conditional writes)
- Amazon DynamoDB transactions (TransactWriteItems)
- Amazon DynamoDB Streams
- Amazon DynamoDB Time to Live (TTL)
- Amazon SNS subscription filter policies
- API Gateway HTTP API AWS service integration subtype reference
- Powertools for AWS Lambda (Python) - Idempotency
- AWS Well-Architected Serverless Applications Lens
Related Articles on This Site
- AWS Messaging and Event Routing Decision Guide — how to choose between SQS, SNS, and EventBridge for routing.
- Amazon API Gateway Decision Guide — REST vs HTTP API vs WebSocket and authorization options.
- AWS Lambda Concurrency and Scaling Guide — reserved/provisioned concurrency and event source scaling.
- Amazon EventBridge Pipes and Event-Driven Architecture Patterns — point-to-point integration patterns.
- AWS Step Functions Distributed Map Guide — large-scale parallel fan-out inside a workflow.
- AWS Step Functions JSONata and Variables Guide — modern data flow inside state machines.
- Amazon DynamoDB Single-Table Design Guide — item and key modeling for the data tier.
References:
Tech Blog with curated related content
Written by Hidekazu Konishi