AI Agent Defense in Depth Model (AIDDM) - WAF, Guardrails, Reasoning Sandbox, and Output Filter
First Published:
Last Updated:
This article proposes and names the mental model I use when designing defenses for production AI agents: The AI Agent Defense in Depth Model, hereafter abbreviated as AIDDM. It splits AI agent defense into four cooperating layers — Edge / Network, Input / Prompt Validation, Reasoning / Runtime, and Output / Egress — each with its own responsibility, its own representative implementations across AWS / GCP / OSS stacks, and its own observable metrics. The point of the model is not to invent new controls, but to give the controls you already use a shared vocabulary so that gaps between them become visible.
The article is written for AI agent and LLM application security implementers and architects who already operate at least one production agent and need a framework that makes design reviews, threat modeling, and incident postmortems faster. It is structured as a long-form reference: a problem statement, the model itself with a whole-stack diagram, four layer-by-layer chapters, a "putting it together" chapter showing how to instantiate AIDDM on AWS, GCP, and OSS stacks, an evaluation chapter on per-layer KPIs and red-team scoring, an anti-pattern catalog, FAQs that map AIDDM to OWASP LLM Top 10 and MITRE ATLAS, and a summary.
A note on scope. This article deliberately does not include concrete jailbreak payloads, vendor pricing numbers, or any production configuration from my own sites. The intent is to provide a framework, not a recipe book of attacks, and to remain stable as vendor catalogs and prices change.
1. The Problem — How AI Agents Actually Get Broken
1.1 Six canonical attack surfaces
When I review AI agent security incidents and red-team findings, the same six attack categories keep appearing. The labels vary by source — OWASP, MITRE ATLAS, vendor research, internal postmortems — but the underlying behaviors cluster well into six. The AIDDM model maps each of these to one or more layers, and that mapping is what gives the model its working value.The first is direct prompt injection. A user supplies input intended to override the system prompt or the agent's role — for example, a request that asks the assistant to ignore previous instructions or to act as a different persona. The second is indirect prompt injection, where the malicious instruction is not in the user message but in a retrieved document, a tool result, or some other piece of context the agent reads as part of its work. The third is tool abuse, where an agent is induced to call a tool with arguments it should not call — writing to a wrong storage prefix, calling a delete endpoint, or invoking a chained tool whose composition exceeds the user's actual permission. The fourth is sensitive output, where the agent produces personally identifiable information, secrets, prohibited content, or hallucinated factual claims that an external compliance regime forbids. The fifth is denial of wallet, where an attacker exploits the unbounded relationship between input size, retrieval expansion, and downstream model spend to drive cost up faster than usage limits notice. The sixth is exfiltration through outputs, where an agent is induced — typically through a chained injection — to encode internal data into a benign-looking output (for example, a URL that the rendered page will fetch).
The table below catalogs these six surfaces, gives a concrete example of each, and names the primary AIDDM layer that addresses them.
| Attack surface | Concrete example | Primary defending layer(s) |
|---|---|---|
| Direct prompt injection | User message asks the agent to ignore its system prompt and act as a different persona | Layer 2 (Input) |
| Indirect prompt injection | Retrieved document or tool result contains text that the agent interprets as instructions | Layer 2 (Input), Layer 3 (Reasoning) |
| Tool abuse | Agent is induced to call a write or delete tool with arguments it should not have | Layer 3 (Reasoning) |
| Sensitive output | Agent emits PII, secrets, or harmful content the policy forbids | Layer 4 (Output) |
| Denial of wallet | Attacker drives token usage and downstream model spend past budget | Layer 1 (Edge), Layer 3 (Reasoning) |
| Exfiltration via output | Agent encodes internal data into a benign-looking output (links, images, code) | Layer 4 (Output) |
This is not a complete taxonomy. It is the operational subset I find useful when deciding where to put a control. Other taxonomies (OWASP LLM Top 10, MITRE ATLAS) cover more ground; this one is tuned to making the layer assignment unambiguous.
1.2 Why one-layer defenses fail
The reason a single layer is not enough is structural, not a question of how good any one layer is. Each attack class has at least one variant that bypasses any given control if that control is asked to carry the whole load.A rate-based WAF rule, no matter how well tuned, cannot tell that a well-formed prompt is asking the agent to ignore its system prompt. The bytes look legitimate at the network edge. A Guardrails-style input filter, no matter how strict, cannot tell that an over-privileged tool will write to a wrong location once the agent decides to call it — the call is structurally valid at the input stage. A tool allow-list, no matter how careful, will not catch an agent that emits a customer's email address in plain text because the output policy was missing. An output filter, no matter how aggressive, will not stop a thousand-request-per-second cost-amplification attack because by the time output filtering runs, the spend has already happened.
This is not novel — the same logic underlies defense in depth in classic enterprise security. The reason it deserves an AI-specific model is that the failure modes are different from the network era. The single-chokepoint temptation in AI agent design is to centralize everything in the model itself ("the model will refuse"), or to centralize everything in a single guardrail layer ("the guardrail will refuse"). AIDDM is a counter to that temptation: it distributes responsibility, and it makes the gaps observable instead of invisible.
2. Introducing the AI Agent Defense in Depth Model (AIDDM)
2.1 Naming and scope
The full name of the model is The AI Agent Defense in Depth Model, and the abbreviation used throughout this article and in references to it elsewhere is AIDDM. The model is a mental model and a vocabulary, not a product or a specification. It applies to any production AI agent that takes user input, performs some reasoning, possibly calls tools, and returns output — whether that agent runs on Amazon Bedrock, on a self-hosted model, on a managed agent service, or as a chained pipeline of LLM calls.The one-line definition is:
AIDDM splits production AI agent defense into four cooperating layers — Edge / Network, Input / Prompt Validation, Reasoning / Runtime, and Output / Egress — each with its own responsibility, its own representative implementations, and its own observable metrics, so that no single layer is asked to bear the entire defense and the gaps between layers become visible.
What AIDDM is not is also worth saying. It is not a replacement for OWASP LLM Top 10, MITRE ATLAS, or any vendor's threat model. Those are catalogs of attacks. AIDDM is a placement model for the controls you choose to defend against those attacks. The two are complementary — OWASP gives you the "what to defend against" list, AIDDM gives you a "where each defense lives" map. The FAQ at the end of this article makes that mapping concrete.
2.2 The five design principles
Five principles guide what fits in AIDDM and what does not. These principles are the part of the model that you should remember even if you forget the layer names.- Defense in depth, not in series. Each layer is responsible for stopping certain attack categories on its own, not for handing them off. Layers are checked in series for performance, but they are designed for independent effectiveness.
- Per-layer observability. Each layer emits metrics that can answer the question "is this layer doing its job?" without requiring data from other layers. If a layer has no metric of its own, it has no place in AIDDM.
- Cross-vendor portability. The model describes responsibilities, not products. An AIDDM implementation on AWS, on GCP, and on self-hosted infrastructure should look like the same architecture drawn in three vocabularies.
- Blast-radius scoping. Each layer assumes the other layers may fail. No layer escalates its trust based on the success of another layer's check. Layer 3, for example, does not skip its tool allow-list because Layer 2 already validated the prompt.
- Falsifiable controls. Every layer's effectiveness is provable through red-team exercises whose outcomes can be reproduced. If the only evidence that a layer works is "no incidents so far", that is not an AIDDM layer.
These principles are why AIDDM has four layers, not three and not five (see also FAQ 10.1). Each layer maps to a structurally different point in the request lifecycle — bytes at the edge, semantic content of the input, model reasoning and tool execution, bytes leaving the system — and adding a layer would either merge two of those or invent a non-falsifiable one.
2.3 Whole-stack overview diagram
The diagram below is the canonical AIDDM picture. User requests enter at the top, flow through the four layers in order, and emit safe output at the bottom. Each layer is annotated with its responsibility, its representative implementations, and its primary observable KPI.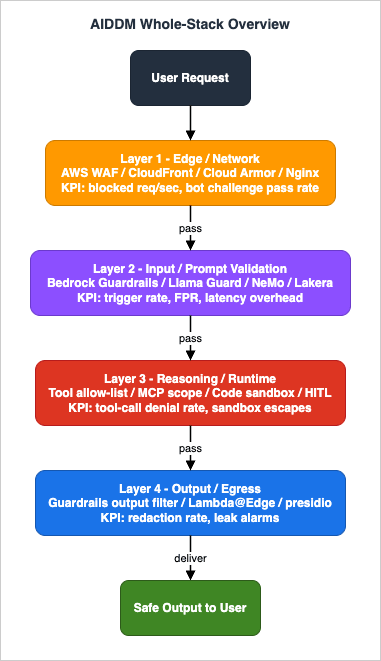
| Layer | Name | Responsibility | Representative implementations | Primary KPI |
|---|---|---|---|---|
| L1 | Edge / Network | Rate limiting, bot mitigation, request size, geo / IP reputation, cheap regex reject | AWS WAF (Rate-based, Bot Control, Size, Custom regex), CloudFront, Cloudflare | Blocked requests per second, rate-limit hit rate |
| L2 | Input / Prompt Validation | Semantic inspection of the prompt, PII detection, prompt-attack classification, context-window hygiene | Amazon Bedrock Guardrails (Prompt Attack), Llama Guard 3, NeMo Guardrails, Lakera Guard, Azure AI Content Safety, Constitutional Classifiers | Guardrail trigger rate, false positive rate, latency overhead |
| L3 | Reasoning / Runtime | Tool allow-list, argument schema validation, code sandboxing, task isolation, human-in-the-loop approval | Tool allow-list, MCP scope tokens, AgentCore Code Interpreter sandbox, Lambda pre-screening on tool args, HITL approval gate, Cedar policy | Tool-call denial rate, sandbox escape attempts, HITL trigger frequency |
| L4 | Output / Egress | Response redaction (PII, secrets, harmful content), hallucination detection, streaming cut, watermarking | Amazon Bedrock Guardrails (Output filter), Lambda@Edge response rewriter, presidio / PII regex, Constitutional AI critique-revise, structured-output enforcement | Output redaction rate, leak detection alarms, end-to-end latency |
The remainder of this article expands each layer in turn. Each layer chapter is structured identically — responsibility, representative implementations, metrics, and failure modes — so that readers can skim to the layer relevant to their current design review without losing the structure.
3. Layer 1 — Edge / Network
3.1 Responsibility
Layer 1 sits at the network edge, before any model is invoked, before any tool is considered. Its job is to reject obviously unwanted traffic at the cheapest possible cost point. Three properties define what "obviously unwanted" means here: high frequency from a single source, unmistakable bot signatures, and oversized or malformed requests that should not even reach the application code.The reason this layer is not optional, even for agents that are far better defended at higher layers, is the cost asymmetry. Every byte that reaches Layer 2 incurs the cost of input filtering. Every prompt that reaches Layer 3 incurs the cost of a model call, plus any downstream tool calls the agent decides to make. A botnet that drives a thousand benign-looking requests per second past an undefended Layer 1 can exhaust a generative-AI budget far faster than a classic web denial-of-service exhausts an EC2 fleet. The agent does not have to be tricked at all — just kept busy.
3.2 AWS WAF reference patterns
On AWS, Layer 1 is naturally implemented with AWS WAF in front of an Application Load Balancer, an API Gateway, or a CloudFront distribution that fronts the agent endpoint. The canonical WAF posture for an AI endpoint differs from a classic web posture in three places: the rate-based rule needs a much lower threshold than for typical APIs because every request can be expensive, Bot Control should be configured to challenge rather than block by default so that a misidentified legitimate user falls back to a CAPTCHA rather than a hard 403, and the body size constraint should be set tight enough that a 100 KB jailbreak payload is rejected before it ever reaches Layer 2.In addition to these three baseline rules, a known-pattern regex rule that rejects requests containing strings that are unambiguous markers of an attack tool — not the attack content itself, just the tooling signature — catches a measurable fraction of automated traffic at a fraction of the cost of doing the same rejection at Layer 2. The trade-off, as always with regex on a WAF, is false positives on uncommon legitimate inputs; the mitigation is to start in count-only mode and graduate to block only after a soak period.
I have written about these patterns in detail in a companion article, and I treat that article as the canonical deep dive for Layer 1. See AWS WAF for Generative AI - Prompt Injection Defense Implementation Patterns for the full set of patterns, the rule-graduation checklist, the worked CloudWatch Logs Insights detection examples, and the infrastructure-as-code skeleton for a complete Web ACL.
3.3 Pre-screening Lambda integration
When the four built-in WAF capabilities are not enough, the next tool at Layer 1 is a Lambda-based pre-screen. AWS WAF rule actions are limited to allow, block, count, CAPTCHA, and challenge and cannot directly invoke Lambda, so the pre-screen Lambda is wired in adjacent to WAF rather than as a WAF rule action — typically as a Lambda@Edge function on the CloudFront origin-request path that runs after the WAF Web ACL has evaluated, as an API Gateway REQUEST authorizer that denies the request before it reaches the agent, or as an application-layer middleware that runs synchronously before the model call. The function receives the request as it would have been delivered to the agent, runs a fast pre-screen (length checks, encoding checks, classification by a small local model or a cheap remote one), and returns block or allow. The latency budget is tight — on the order of a few tens of milliseconds, because every request pays the cost — and the function must fail open in a controlled way if its dependencies are unreachable, since failing closed at Layer 1 means a total outage rather than a degraded posture.The Lambda pre-screen is also where rate-shaping logic that goes beyond a flat rate-based rule lives. For example, a per-user budget that counts tokens rather than requests, or a per-tenant burst allowance, requires state that the static WAF cannot maintain. The pre-screen reads that state from a small DynamoDB table or an in-memory cache and rejects when the budget is exceeded.
3.4 Metrics and failure modes
The primary metrics at Layer 1 are blocked requests per second (broken down by rule), rate-limit hit rate per source, and Bot Control challenge pass rate. These are emitted directly by AWS WAF to CloudWatch and are the cheapest layer to instrument because the data is already there. The secondary metric is the pre-screen Lambda's denial rate, which should correlate but not perfectly overlap with the rule-based denials.The dominant failure mode at Layer 1 is over-broad rules causing legitimate users to be blocked. The mitigation is a strict count-then-block graduation: every new rule starts in count-only mode, runs for at least a soak period, and is promoted only after the false positive rate is below a chosen threshold. A second failure mode is the temptation to push Layer 2 work into Layer 1 — for example, classifying prompt content with a model in the WAF Lambda. This is technically possible but breaks the cost discipline that makes Layer 1 valuable; if you find yourself needing model inference in a WAF rule, that decision belongs in Layer 2.
3.5 Deep dive linkage
For the full Layer 1 implementation — all six patterns, the WAF rule graduation checklist, the penetration testing runbook, and the infrastructure-as-code skeleton — see the dedicated article: AWS WAF for Generative AI - Prompt Injection Defense Implementation Patterns. The companion article also covers the correlation pattern between WAF labels and Bedrock token spend, which is the primary cross-layer linkage between Layer 1 and the downstream layers in AIDDM.4. Layer 2 — Input / Prompt Validation
4.1 Responsibility
Layer 2 receives the request after it has passed Layer 1. The bytes look reasonable — they are the right size, they came from a non-blocked source, they did not match any obvious attack tool signature. Layer 2's job is to look at the semantic content of the prompt and the assembled context, and to decide whether what is about to be sent to the model is acceptable. This is the layer that catches direct prompt injection, classifies prompts into attack categories, redacts user-side PII before it touches the model, and enforces that retrieved context does not introduce instructions the user did not write.A useful way to think about Layer 2 is that it is the first layer that needs to know what an agent is. Layer 1 treats the request as bytes. Layer 2 treats the request as a structured prompt — system message, retrieved context, user message, possibly conversation history — and applies different checks to different parts of that structure.
4.2 Bedrock Guardrails Prompt Attack
On AWS, the headline implementation of Layer 2 is Amazon Bedrock Guardrails with the Prompt Attack filter enabled. This is a managed control that runs before the request reaches the model and classifies whether the prompt is a prompt injection or jailbreak attempt. It can be configured to block on detection, redact, or simply tag the request for downstream observation.Two configuration choices matter. The first is whether the Guardrail is attached as a model-level filter or as a request-level filter — the former is simpler to apply across all calls, the latter gives finer control per use case. The second is the threshold at which a detection becomes a block; lower thresholds catch more attacks but also more false positives. As with Layer 1 rate rules, the graduation pattern is to start in tag-only mode, observe the false positive rate, and promote to block when the operating point is clear.
The Guardrail's strength is that it does not require any model-side prompt engineering to work, and its detections appear in CloudTrail and CloudWatch so the rest of the observability pipeline can ingest them without extra plumbing. Its weakness is that it is a single-vendor classifier; if its training distribution misses a novel attack pattern, the only recourse is a defense-in-depth check elsewhere.
4.3 Cross-vendor implementations
Layer 2 is also where the cross-vendor portability principle of AIDDM (Section 2.2 principle 3) is most visible. The same responsibility can be filled by several products from several vendors, and a portable design uses one of them at this layer rather than coupling tightly to a specific API.Llama Guard 3 is Meta's open-weight prompt-safety classifier. It runs as a local model and produces a structured judgment per prompt. It is the natural fit when the rest of the stack is self-hosted, or when running a classifier model locally is preferred for latency or data-residency reasons. NVIDIA NeMo Guardrails is a Python-side framework that intercepts the prompt and the response and runs configurable rules — Colang scripts — between them; it is the natural fit when more programmatic control over the rule set is desired, and when integration with the existing application stack is preferable to integrating with a managed cloud control. Lakera Guard is a managed API that classifies prompts for injection and PII; it is the natural fit when a managed third-party classifier is preferable to either running a local model or coupling to a single cloud vendor. Azure AI Content Safety is the Azure-native counterpart and pairs naturally with Azure OpenAI deployments.
These options do not need to be mutually exclusive. A practical Layer 2 deployment often runs at least two of them in series — a vendor-managed classifier (such as Bedrock Guardrails or Lakera Guard) for the easy 95% of attacks, and a Colang or Llama Guard rule set for the application-specific patterns that no managed product knows about. The cost of running two classifiers is small relative to the cost of a single missed attack.
4.4 Constitutional Classifiers pattern
A pattern that has emerged in research and that is now reaching production is the Constitutional Classifiers pattern, where instead of (or in addition to) a third-party classifier, the application maintains a small set of constitutions — declarative descriptions of what is and is not allowed — and applies them via a fast classifier. The constitution is the audit artifact: it documents the application's policy in a form that humans can read and update, and the classifier enforces it at runtime.This pattern is particularly useful when an application has policy requirements that are unique to its domain (financial, medical, legal) and no general-purpose classifier covers them. The constitution lives in version control, changes go through code review, and the classifier's outputs become the metric that proves the policy is being enforced.
4.5 Metrics
The primary Layer 2 metrics are the Guardrail trigger rate (per category, where the category is direct injection / indirect injection / PII / etc.), the false positive rate measured against a labeled holdout set, and the latency overhead introduced by the layer. The trigger rate is easy to measure because every classifier emits it; the false positive rate requires investment in a labeled set that is refreshed as the threat landscape evolves; the latency overhead requires p95 and p99 measurement, not averages, because Layer 2 sits on the critical request path.A secondary metric that is harder but worth measuring is the "category drift" rate — how the distribution of detected categories changes month over month. A sudden spike in indirect injection categories, for example, is a signal that a retrieval pipeline upstream is delivering attacker-controlled content; that signal would be invisible if only the aggregate trigger rate were tracked.
4.6 Failure modes
The dominant Layer 2 failure mode is single-classifier dependence: trusting one managed classifier to catch every attack class. The mitigation is the multi-classifier approach described in Section 4.3. The second failure mode is over-tuning toward low false positive rates: a classifier set to block only on extremely high confidence leaks every borderline case, and borderline is where most real attacks live. The mitigation is to measure both rates and choose an operating point that the business can defend, not the operating point that produces the cleanest dashboard. The third failure mode is forgetting that Layer 2 is not the model itself: applying input classification but giving the model the same context with no further controls is exactly the single-chokepoint pattern that AIDDM rejects.5. Layer 3 — Reasoning / Runtime
5.1 Responsibility
Layer 3 is the first layer where the model is part of the system. The model has received the prompt, has decided what to do, and is now either generating a final response or calling a tool. Layer 3's job is to constrain what the model is allowed to do during that reasoning step — which tools it can call, with what arguments, in what sandbox, and with what level of human approval.This is the layer where most of the AI-specific work in AIDDM lives. Classic web security has decades of precedent for Layer 1 (WAF) and substantial precedent for Layer 4 (response filters). Layer 2 is a newer but increasingly standardized space with managed products from every major vendor. Layer 3 is where the design decisions are still mostly bespoke, and where the cost of getting it wrong is the highest because an over-privileged agent does damage that is harder to undo than emitting a single bad output.
5.2 Tool allow-list and MCP scope tokens
The first and most important Layer 3 control is the tool allow-list. An agent should be configured with the minimal set of tools needed for its task, and the agent runtime should refuse to invoke any tool not on that list — regardless of what the model emitted in its tool-use response. This is the "fail closed on unknown tool" pattern, and it should be the default rather than an opt-in.For agents that talk to Model Context Protocol (MCP) servers, the equivalent control is MCP scope tokens: each agent session is issued a token whose scopes describe which MCP servers it can talk to and which tools on those servers it can invoke. The MCP server, not the agent, enforces the scope. This delegates Layer 3 trust from the agent process to the MCP server, which is the right inversion because the MCP server is the thing that owns the destructive operation. For implementation patterns of MCP servers on AWS Lambda, see MCP Server on AWS Lambda Complete Guide.
5.3 Code Interpreter sandbox
When an agent has access to a code interpreter — a tool that executes arbitrary Python or shell code on behalf of the agent — the sandbox around that interpreter becomes a Layer 3 control. The minimal posture is a network-isolated container with no credentials, no outbound network access, ephemeral filesystem, and a hard wall-clock limit per execution. Amazon Bedrock AgentCore's Code Interpreter implements this pattern as a managed service. For applications that build their own, the same posture can be assembled with Firecracker microVMs or with a managed sandbox provider; the principle is the same and the test for "is this Layer 3 compliant" is whether the sandbox would survive a worst-case prompt that asks it to read every file it can reach and POST it to an attacker.The reason Code Interpreter sandboxes are a separate Layer 3 control rather than part of the tool allow-list is that the tool is "execute code" and the allow-list cannot meaningfully restrict the contents of the code being executed. The control has to live at the sandbox boundary, not at the call interface.
For the broader AgentCore security pattern that puts Code Interpreter into the same architecture as identity, gateway, and policy, see Amazon Bedrock AgentCore Implementation Guide Part 2: Multi-Layer Security with Identity, Gateway, and Policy.
5.4 Argument schema validation
Even when a tool is on the allow-list, the arguments the model proposes to call it with must be validated against a schema before the call is executed. A weather lookup tool that accepts a city name should not be invoked with a thousand-line string that happens to encode a different prompt. A file-read tool that accepts a path should not be invoked with../../../etc/passwd. The schema is the contract, and the validation step is what enforces it.In practice, this often takes the form of a small Lambda function that wraps every tool call, runs JSON Schema validation, optionally classifies the argument string with a small model for prompt-injection content, and either forwards the call to the actual tool or rejects it. The trade-off is one round-trip of added latency per tool call; the benefit is that the model's reasoning never directly touches the actual tool surface, which simplifies post-incident analysis substantially.
5.5 HITL approval gates
For tools whose effects are large enough that getting them wrong is unrecoverable — sending email, paying invoices, modifying production data — the right Layer 3 control is a human-in-the-loop (HITL) approval gate. The agent emits a proposed tool call, the runtime pauses, an operator (in-app, via a message channel, or out-of-band) approves or rejects, and only then does the call execute. This is the equivalent of the four-eyes principle in financial systems, and it is the only Layer 3 control that catches an attack class that none of the others can: the case where the agent is doing exactly what it was instructed to do, but the instruction is wrong.The design challenge is keeping the HITL trigger rate low enough that operators do not start auto-approving out of habit, and high enough that the destructive tools are reliably gated. The rate is tunable through the choice of which tools require HITL and through dynamic policies (always approve for low-impact arguments, always pause for high-impact ones).
For broader patterns on production agent reasoning and tool design, see Enterprise AI Agent Design Notes Part 2 and Enterprise AI Agent Design Notes Part 3.
5.6 Metrics and failure modes
The Layer 3 metrics are tool-call denial rate (broken down by reason: allow-list, schema, HITL), sandbox escape attempts (counted from sandbox-side telemetry, not from agent telemetry), and HITL trigger frequency. The denial rate by reason is the most diagnostic of the three — a shift from schema-rejection-dominant to allow-list-rejection-dominant, for example, is usually a sign that the model has started attempting tools it was not previously trying.The dominant Layer 3 failure mode is over-broad tool permissions granted during early development and never tightened. The mitigation is the allow-list-by-default posture and a quarterly review of every agent's tool inventory. The second failure mode is the fail-open-on-validation-error anti-pattern — a tool-call wrapper that, when the schema validator throws, lets the call through with a warning. The right behavior is the opposite: fail closed and surface the error to operators. The third failure mode is auto-approval drift on HITL gates; the mitigation is to audit approval-vs-reject ratios periodically and re-tune which tools require gates.
6. Layer 4 — Output / Egress
6.1 Responsibility
Layer 4 sits after the model has produced a response and before that response is delivered to the user. Its job is to scan the response for things that should not leave the system — PII the policy says must be redacted, secrets that an upstream tool result accidentally surfaced, harmful content the application's policy forbids, or hallucinated factual claims that an external compliance regime treats as fabricated. It also handles structural concerns like enforcing structured-output schemas and cutting a streaming response mid-flight when a violating token appears.Layer 4 is the layer most often skipped in early-stage agent designs, because the response looks fine in testing and the cost of running output filters on every response is real. The reason AIDDM gives it equal weight is that some attack classes — in particular the exfiltration-via-output class from Section 1.1 — have no other layer that can catch them. By the time the response is being generated, Layers 1 through 3 have already done their work; only Layer 4 sees the final output.
6.2 Bedrock Guardrails Output filter
On AWS, Amazon Bedrock Guardrails ships an output filter that runs as part of the same Guardrail used in Layer 2 (Section 4.2). It scans the generated text for prohibited content categories — hate, violence, sexual content, custom topic blocks — and for PII, with the same configurable threshold and block / redact / tag actions. Because it runs as part of the model invocation rather than after, it can also cut streaming output mid-flight when a violation appears, which avoids the user seeing a partial response that is then retracted.The same trade-off as Layer 2 applies: a single-vendor classifier is a single point of detection failure, and a defense-in-depth Layer 4 runs at least two output checks. The second check, often a regex-based PII redactor, catches the structurally simple cases (email addresses, phone numbers, credit-card-like patterns) that a learned classifier might miss because they are not on its training distribution.
6.3 Lambda@Edge output rewriting
For responses that leave through CloudFront, a Lambda@Edge function on the origin-response path can rewrite the response body before it is delivered. This is the same mechanism as the Layer 1 / Layer 4 connection in the AWS WAF article (Pattern 6 in that article); the Layer 4 use case is to apply egress-side redaction even on responses that bypassed Bedrock (for example, cached responses) or that came from a non-Bedrock origin.The trade-off at Lambda@Edge is the latency cost on every response and the limited execution time / memory available at the edge. For responses that exceed those limits, the same logic moves to a regional Lambda invoked synchronously between the agent and the user. The principle — egress-side rewriting before bytes leave the boundary — is the same.
6.4 PII and secret redaction
The two most common Layer 4 jobs are PII redaction and secret redaction. PII redaction uses a combination of a classifier (presidio or similar) and regex rules to identify and replace personally identifiable substrings; the replacement may be deletion, asterisk-masking, or token-substitution depending on the application. Secret redaction is structurally similar but the patterns are different — API key formats, JWT tokens, AWS access key signatures, private key headers. Both jobs are run on every response; the failure mode is to skip them for internal responses, which works until an internal response leaks externally.A subtle requirement that often gets missed is that redaction must run on the response even when the response is a tool result being passed back through the agent. If a tool returns a database row that contains a customer's email address, and the agent reflects that email in its final response, the redactor must catch it on the way out. Redacting only inputs (Layer 2) or only the model's first-pass output is insufficient because the model can re-emit redacted content from memory of the tool result.
6.5 Structured-output schema enforcement
For agent responses that are consumed by another program rather than rendered to a human — a downstream Lambda, a workflow step, an MCP client — the schema of the output is itself part of the security boundary. An agent that is supposed to return{ "decision": "approve" | "deny", "reason": "<string>" } but instead returns prose embedding an extra execute_command field is the structural prerequisite for an output-to-tool exfiltration. Layer 4 enforces the schema before the response is handed off, so the violating shape is caught at the boundary rather than at the consumer.The implementation has three complementary mechanisms. First, request the model in structured-output mode at invocation time so the provider validates against the schema before generating tokens (Amazon Bedrock Converse API supports this through tool-use as a structured response channel; OpenAI and Google expose the same capability as JSON schema-constrained sampling). Second, re-validate the returned object against the same schema in Layer 4 code — provider-side validation can be defeated by a model that emits a syntactically valid but semantically wrong shape, and the second check is the layer that catches schema drift after a model version change. Third, on validation failure either retry with the validation error appended to the prompt (one retry only, to bound cost) or hard-fail with a structured error to the consumer; never silently return the malformed object, since downstream code will execute on whatever fields it can parse.
The failure mode is treating provider-side structured output as sufficient. Production incidents in this category usually involve a model version upgrade that subtly changed how the model interprets an optional field; the provider-side check still passed because the field was present, but the field value violated an implicit invariant (for example, a list that should be non-empty came back empty). The mitigation is the second validation pass and an alert on schema-violation rate as a per-day metric — sudden jumps almost always indicate either an upstream model change or a new prompt-injection pattern targeting the schema.
6.6 Streaming partial-cut
For streaming responses, the additional Layer 4 requirement is the ability to cut the stream mid-flight when a violating token appears, and to substitute a refusal or a safe stub. This is structurally different from filtering a complete response because the violating token may appear before its full context is visible. The implementation pattern is to maintain a sliding window of recent tokens, run the filter against the window, and cut the stream the moment the window flags. The trade-off is a slight increase in per-token latency, which on streaming responses is usually invisible to users.6.7 Metrics and failure modes
Layer 4 metrics are output redaction rate (counts of redactions per category, per response), leak detection alarms (high-severity alerts for specific patterns — production secret formats, named customer identifiers in the wrong context), and end-to-end latency contribution. End-to-end latency at Layer 4 includes both the steady-state filtering overhead and the worst-case impact of mid-flight cuts on streaming responses.The dominant failure mode is, again, single-classifier dependence: trusting a managed output filter to catch every category. The mitigation is to layer a regex secret-redactor on top of the managed filter. The second failure mode is failing to apply Layer 4 to tool-call results that are reflected back into the response. The mitigation is to redact tool results as part of Layer 3's tool-wrapper Lambda (Section 5.4) rather than relying on Layer 4 to catch them after the model has re-emitted them. The third failure mode is too-aggressive redaction making responses unintelligible; the mitigation is the same operating-point discipline as Layers 1 and 2 — measure both rates, choose the point that the business can defend, and revisit quarterly.
7. Putting It Together — Three Reference Stacks
This section instantiates AIDDM as three concrete reference stacks. Each stack uses native components of its respective ecosystem and demonstrates that the same model can be applied across AWS, GCP, and self-hosted infrastructure without distortion.The table below summarizes the three stacks side by side. Each row is an AIDDM layer; each column is one of the three reference stacks.
* You can sort the table by clicking on the column name.
| Layer | AWS-native | GCP-native | Self-hosted (OSS) |
|---|---|---|---|
| Layer 1 (Edge) | AWS WAF + CloudFront + Bot Control | Cloud Armor + Cloud Load Balancing + reCAPTCHA Enterprise | Nginx + fail2ban + rate-limit module + Crowdsec / Anubis |
| Layer 2 (Input) | Bedrock Guardrails (Prompt Attack) + Lakera Guard | Model Armor (Vertex AI Safety) + custom DLP rules | Llama Guard 3 + NeMo Guardrails + local constitution |
| Layer 3 (Reason) | AgentCore Code Interpreter + Lambda tool wrapper + Cedar policy + HITL approval | Vertex AI Agent Builder tool allow-list + Cloud Functions pre-screen + HITL Pub/Sub gate | Firecracker sandbox + JSON Schema arg validation + HITL Slack approval |
| Layer 4 (Output) | Bedrock Guardrails output filter + Lambda@Edge rewriter + presidio | Model Armor output filter + DLP API + Cloud Functions response rewriter | presidio + regex egress filter + stream watcher |
7.1 AWS-native stack
The AWS-native stack uses CloudFront with AWS WAF at the edge (Layer 1), Amazon Bedrock Guardrails for prompt validation on the input side and output filtering on the response side (Layers 2 and 4), and Amazon Bedrock AgentCore with Code Interpreter, tool allow-lists, and a Lambda tool-wrapper at Layer 3. For policy enforcement on tool calls, AWS Verified Permissions with Cedar provides a structured allow-list for which agent identities can invoke which tools under which contexts.The advantage of the AWS-native stack is that observability is already wired up: WAF logs flow to CloudWatch, Bedrock Guardrails detections flow to CloudWatch and CloudTrail, AgentCore traces flow to CloudWatch Logs, and end-to-end correlation by request ID is straightforward. The disadvantage is single-vendor lock-in for the classifier layers, which Section 4.3 argues is itself a failure mode; the mitigation is to add a non-AWS classifier (Lakera Guard or a self-hosted Llama Guard) in series at Layer 2.
7.2 GCP-native stack
The GCP-native stack uses Cloud Armor on Cloud Load Balancing at the edge (Layer 1) — including its Adaptive Protection module for ML-based detection of anomalous traffic patterns — and Model Armor (the Vertex AI Safety control plane) for prompt and response filtering (Layers 2 and 4). At Layer 3, Vertex AI Agent Builder provides the tool allow-list primitive, and a Cloud Functions pre-screening wrapper or a Cloud Run service can be inserted between the agent and the tool surface for schema validation. The HITL pattern on GCP is typically wired through Pub/Sub with an operator-side console.The properties of the GCP stack mirror the AWS stack: observability is wired up through Cloud Logging and Cloud Monitoring, end-to-end correlation is straightforward, and single-vendor classifier risk applies. The mitigation, as on AWS, is to add a non-GCP classifier in series.
7.3 Self-hosted / open-source stack
The self-hosted stack assembles the same responsibilities from open-source components. At Layer 1, Nginx with rate-limit modules, Crowdsec or Anubis for bot mitigation, and fail2ban for slow brute-force defense cover the WAF responsibilities. At Layer 2, Llama Guard 3 as a local classifier and NeMo Guardrails as a Colang-script rules layer cover the input filtering responsibilities. At Layer 3, the sandbox is typically Firecracker microVMs orchestrated by a managed sandbox library, the argument validation is JSON Schema in the tool-wrapper service, and HITL is a Slack or Microsoft Teams approval bot. At Layer 4, presidio for PII / secret redaction and a small stream-watcher service for cut-on-violation cover the output side.The trade-off is operational. The self-hosted stack requires more engineering investment per layer, but it is the only stack that can be deployed in air-gapped or strict-data-residency environments. The AIDDM responsibilities and metrics are the same; only the products change.
8. Evaluation Metrics — How to Prove the Model Works
8.1 Per-layer KPI catalog
The KPI catalog below is the operational view of AIDDM. Each layer has at least one primary KPI that answers the question "is this layer doing its job", and at least one secondary KPI that surfaces shifts in attack distribution.| Layer | Primary KPI | Secondary KPI | Source system |
|---|---|---|---|
| L1 | Blocked requests per second (per rule) | Bot Control challenge pass rate | CloudWatch Metrics from WAF / Cloud Armor / Nginx |
| L2 | Guardrail trigger rate (per category) | False positive rate vs labeled holdout | CloudTrail / Cloud Logging / classifier logs |
| L3 | Tool-call denial rate (per reason) | HITL trigger frequency | Agent runtime logs / Cedar evaluation logs |
| L4 | Output redaction rate (per category) | Streaming-cut frequency | Output filter logs / Lambda@Edge logs |
These are emitted regardless of the implementation stack. The Section 7 reference stacks differ only in the system that emits them; the metric names and the dashboards that consume them should be identical. The figure below shows how the four metric streams converge into a single per-layer dashboard. For CloudWatch Logs Insights query patterns that work with these streams, see CloudWatch Logs Insights Query Collection.
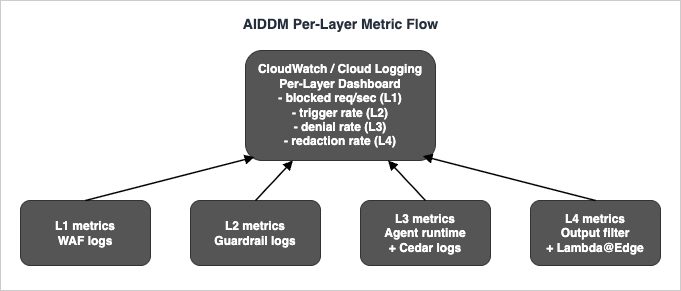
8.2 End-to-end red-team scoring
Per-layer KPIs do not, on their own, prove that the layers compose. An AIDDM stack can have all four layers individually green and still leak when an attack chain crosses layer boundaries in unexpected ways. The standard way to test composition is end-to-end red-team scoring: a curated set of attack scenarios is run against the live (or staging) agent, and the outcome is recorded per scenario — blocked at which layer, leaked through which layer, took how many turns to leak.The output of a red-team run is a scorecard where each row is a scenario, each column is a layer, and each cell is one of three values: blocked at this layer, passed through this layer, not applicable. A healthy stack has at least one "blocked" cell per row. A stack with rows where every cell is "passed through" or "not applicable" has a coverage gap, and the gap is exactly where to focus next.
The frequency of red-team runs is a judgment call, but a useful baseline is to run a small set on every release and a full set quarterly. Failures from quarterly runs feed back into Layer-specific KPI thresholds; if a quarterly run reveals a Layer 2 gap, the operating point at Layer 2 is reconsidered before the next release.
8.3 Attack-by-layer coverage matrix
The coverage matrix below maps each of the six canonical attack surfaces (Section 1.1) to each of the four layers. "Primary" means the layer has a control specifically aimed at that surface; "Assist" means the layer contributes but is not the primary defender; a dash means the layer does not address that surface.| Attack Surface | L1 (Edge) | L2 (Input) | L3 (Reasoning) | L4 (Output) |
|---|---|---|---|---|
| Direct prompt injection | Assist | Primary | Assist | — |
| Indirect prompt injection | — | Primary | Primary | Assist |
| Tool abuse | — | Assist | Primary | — |
| Sensitive output | — | Assist | Assist | Primary |
| Denial of wallet | Primary | Assist | Primary | — |
| Exfiltration via output | — | — | Assist | Primary |
9. Anti-Patterns and Common Failure Modes
The anti-patterns below recur across the agent designs I review. They are not novel — most of them are special cases of design principles violated in Section 2.2 — but they are common enough to deserve naming.The single-chokepoint collapse. A team decides that "Guardrails will handle it" or "the model will refuse" and pushes all four layers' worth of responsibility into one control. This always fails because the single control has a finite false-negative rate, and there is no second check to catch the misses. The AIDDM principle violated is defense in depth (Section 2.2 principle 1). The fix is to require at least two layers of control per attack class in the coverage matrix; rows with only Layer 4 coverage are a signal to add a Layer 2 control, and vice versa. For broader anti-pattern thinking applied to AI-augmented codebases, see Code Review Checklist and Anti-Pattern Catalog.
Fail-open on internal error. A tool-wrapper that, when its schema validator throws, allows the call through with a warning log line. This is structurally the same as having no validator. The AIDDM principle violated is blast-radius scoping (Section 2.2 principle 4). The fix is to fail closed by default everywhere in Layer 3 and to surface the error to operators rather than absorbing it.
Optimizing for the dashboard. A team tunes Layer 2 thresholds to make the false-positive metric look clean and inadvertently lifts the threshold so high that real attacks slip through. The AIDDM principle violated is falsifiable controls (Section 2.2 principle 5); the layer is no longer measuring what it claims to measure. The fix is to track both rates (true-positive and false-positive) and to choose an operating point that the business can defend, not the operating point that makes the dashboard green.
Cross-layer trust. A Layer 3 control that skips its check because Layer 2 already validated the prompt, or a Layer 4 redactor that skips a tool result because Layer 3 was supposed to redact it. This violates blast-radius scoping (Section 2.2 principle 4). The fix is to design each layer as if every other layer might fail; the small redundancy in checks is the design's primary safety margin.
Audit-trail erosion. A team adds aggressive Layer 1 / Layer 2 blocking and then turns off the corresponding logs to save storage. The defense still works in the steady state, but when an incident occurs, the team has no data with which to triage. This is not in the principle list explicitly because it sits between operations and engineering, but it is the failure mode that turns a tractable incident into an existential one. The fix is to keep the per-layer KPI source data for at least the incident-window length, even when its sampled aggregates suffice for dashboards.
Postmortem skip. When a layer blocks an attack, the response is "Guardrails worked, no incident" and the case is closed. This loses signal. Each block is data about what is being tried, against what surface, by whom. The fix is the same as in any operational discipline: short postmortems even on successful blocks, captured in a shared format. The reference here is the broader practice documented in AWS Postmortem Case Studies and Design Lessons.
Naming framework drift. A team that has settled on AIDDM as a vocabulary starts calling layers by different names in different teams — "the WAF layer" vs "L1" vs "edge" vs "the rate-limiter". This is a documentation problem, not a security one, but it makes the model less useful. The naming pattern that helps here is the same one used by Architecture Decision Records: pick one name per layer, write it down, and treat departures as docs work rather than ignoring them. The reference for naming-and-format discipline is Architecture Decision Records: Templates and Operational Patterns for Teams That Actually Maintain Them.
10. Frequently Asked Questions
10.1 Why four layers, not three or five?
Four layers correspond to four structurally different points in the request lifecycle: bytes arriving at the network boundary, semantic content of the assembled prompt, the reasoning and tool-execution loop, and bytes leaving the network boundary. A three-layer model has to merge two of these — typically Edge and Input, or Reasoning and Output — and the merge loses one of the metric streams that makes the model falsifiable (Section 2.2 principle 5). A five-layer model has to invent a layer that does not correspond to a distinct lifecycle point; the candidates I have seen (a policy layer, a monitoring layer) end up either being cross-cutting concerns rather than layers, or duplicating a responsibility that already lives in one of the four. Four is the smallest number that gives each lifecycle point a layer of its own, and the largest number where each layer remains independently observable.10.2 How does AIDDM relate to OWASP LLM Top 10 and MITRE ATLAS?
OWASP LLM Top 10 and MITRE ATLAS are attack taxonomies. They tell you what the attacks are. AIDDM is a placement model for controls. It tells you where each defense lives. The two compose — you take an OWASP / ATLAS attack, map it to an AIDDM layer, and put the appropriate control there. As a rough mapping: LLM01 (prompt injection) is primarily Layer 2 with Layer 3 backup, LLM02 (insecure output handling) is Layer 4, LLM03 (training data poisoning) is upstream of AIDDM entirely, LLM04 (model denial of service) is Layer 1 with Layer 3 backup, LLM05 (supply chain) is again upstream, LLM06 (sensitive info disclosure) is Layer 4 with Layer 2 PII redaction assisting, LLM07 (insecure plugin design) is Layer 3, LLM08 (excessive agency) is Layer 3, LLM09 (overreliance) is operational rather than AIDDM, LLM10 (model theft) is Layer 1 plus authentication outside AIDDM. The exact mapping changes with each revision of OWASP, but the structure — find the lifecycle point the attack crosses, put the control at that layer — does not.10.3 Can I skip Layer 1 if I run behind an API gateway?
API gateways — Amazon API Gateway, Apigee, Kong — provide some Layer 1 capabilities natively: rate limiting, IP allow / deny lists, basic request validation. If those capabilities cover your Layer 1 responsibilities, you do not need a separate WAF. What you cannot skip is the responsibility itself. A common mistake is to assume that an API gateway with default settings is Layer 1 and to leave it un-tuned; the agent-specific threshold work in Section 3.3 (rate limits that account for token cost, not request count) still needs to be done at whichever component is acting as Layer 1. The label moves; the work does not.10.4 Where does prompt caching fit?
Prompt caching is a performance optimization, not a security control, but it has a security touch point worth naming. Layer 2 must run before the cache lookup, not after, or a cached malicious prompt that was admitted once will keep being admitted at near-zero latency. The way to express this in AIDDM is that Layer 2 is an input-side control and runs on every request regardless of whether the downstream model call hits the cache. The same logic applies to retrieval caches: Layer 2 runs on the assembled prompt-plus-context, not on the cache key, so that a cached retrieval that has become poisoned does not slip through.10.5 What about multi-agent systems?
Multi-agent systems — a supervisor agent that orchestrates sub-agents, each of which can call tools and emit output — do not change the AIDDM structure but multiply it. Each agent in the system has its own L1 through L4 stack, and the inter-agent boundary is a Layer 4 to Layer 2 transition: agent A's output is agent B's input. The implication is that Layer 4 redaction on agent A is not optional even if agent A's output is only consumed internally; agent B treats that output as input and the prompt-injection class returns at every internal boundary. The other implication is that the per-layer KPIs are now per-agent-per-layer, which makes the dashboard wider but does not change its structure.11. Summary
This article proposed The AI Agent Defense in Depth Model, abbreviated AIDDM, as a mental model for organizing AI agent defenses. The model splits defense into four cooperating layers — Edge / Network, Input / Prompt Validation, Reasoning / Runtime, Output / Egress — each with its own responsibility, its own representative implementations across AWS / GCP / OSS stacks, and its own observable metrics. Five principles guide what fits and what does not: defense in depth not in series, per-layer observability, cross-vendor portability, blast-radius scoping, and falsifiable controls.The practical takeaways are three. First, the model is a vocabulary, not a product, so its value comes from being used consistently across design reviews, incident postmortems, and red-team scorecards. Second, the per-layer KPI catalog (Section 8.1) and the attack-by-layer coverage matrix (Section 8.3) are the two artifacts that turn the vocabulary into operational discipline; without them, the model is just labels. Third, the recommended adoption path is to instrument one layer at a time, get its KPI on the dashboard, run a red-team scenario against it, and only then move to the next layer; trying to deploy all four layers at once is a recipe for partial implementations of all of them.
For the Layer 1 deep dive that names six concrete WAF patterns, the rule-graduation checklist, and the IaC skeleton, see AWS WAF for Generative AI - Prompt Injection Defense Implementation Patterns. For the agent-side security architecture that AIDDM Layer 3 sits inside, see Amazon Bedrock AgentCore Implementation Guide Part 2: Multi-Layer Security with Identity, Gateway, and Policy.
12. References
- AWS WAF Developer Guide
- Amazon Bedrock Guardrails Documentation
- Amazon Bedrock AgentCore Documentation
- Model Context Protocol Specification
- OWASP Top 10 for LLM Applications
- MITRE ATLAS
- Llama Guard 3 (Meta, Hugging Face)
- NVIDIA NeMo Guardrails Documentation
- Lakera Guard
- Azure AI Content Safety
- Google Cloud Armor
- Microsoft Presidio
Related Articles on This Site
- AWS WAF for Generative AI - Prompt Injection Defense Implementation Patterns — the canonical Layer 1 deep dive
- Amazon Bedrock AgentCore Implementation Guide Part 2: Multi-Layer Security with Identity, Gateway, and Policy — Layer 3 identity and tool layer reference
- Architecture Decision Records: Templates and Operational Patterns for Teams That Actually Maintain Them — naming and documentation discipline
- Enterprise AI Agent Design Notes Part 1
- Enterprise AI Agent Design Notes Part 2
- Enterprise AI Agent Design Notes Part 3
- AWS Postmortem Case Studies and Design Lessons
- CloudWatch Logs Insights Query Collection
- Code Review Checklist and Anti-Pattern Catalog
- MCP Server on AWS Lambda Complete Guide
References:
Tech Blog with curated related content
Written by Hidekazu Konishi