AWS Postmortem Case Studies and Design Lessons
First Published:
Last Updated:
aws.amazon.com/message/<id>/ a few days or weeks after the incident. These summaries are short, deliberately written, and deeply technical. Each one tells you something about how AWS thinks about distributed systems that you will not find in the marketing pages.In this article I read four of those public RCAs end-to-end and translate each one into design lessons I can apply to my own architectures. The cases I picked — the 2017 S3 outage, the 2020 Kinesis event, the 2021 us-east-1 network event, and the 2023 Lambda event — span six years and touch every layer of the AWS stack: storage, streaming, internal networking, and serverless compute. I also tie them together with a short chapter on the cross-cutting design patterns AWS keeps reaching for (blast radius, cell-based architecture, static stability, multi-region) and finish with a copy-pastable postmortem template I use for my own incidents.
This is not a list of failures. It is a list of design decisions, written by AWS, about systems running at a scale most of us will never operate. Reading them carefully is one of the highest-leverage things an architect can do.
1. Why Study AWS Postmortems
Most engineers read a public RCA once, on the day it comes out, looking for the answer to "was my workload affected and is it back yet." That is the wrong frame for long-term value. The right frame is: this is a free design review of a system that handles trillions of requests per day, written by the team that built it, with the timing and the trade-offs explained.Three reasons I keep coming back to these documents:
They expose internal architecture you could not infer otherwise. AWS rarely publishes how a service is structured internally. RCAs reveal things like "the Kinesis front-end fleet keeps a per-server cache that requires a thread to every other server in the fleet" or "Lambda is internally cellular, and each cell has a Frontend and an Invocation Manager." These are not implementation details. They are design choices that tell you what the team optimized for and what the failure modes look like.
They show what AWS treats as the canonical fix. Every RCA ends with a section like "what we are doing to prevent this in the future." When the same words keep appearing across years of RCAs — cellularization, blast radius, back-off, static stability — that is AWS revealing its architectural vocabulary. If your own systems do not have a clear answer to those words, the RCAs are giving you a free list of things to fix.
They calibrate expectations honestly. A multi-hour event in a single region happens, on average, once or twice a year somewhere in AWS. Reading the RCAs makes the difference between "us-east-1 broke, AWS is unreliable" and "this specific class of failure happens, here is what designs survive it" concrete.
I also think of the RCAs as the senior side of a conversation. The history of AWS service launches is the public side; the RCAs are the side that explains what those services had to learn.
AWS History and Timeline - Almost All AWS Services List, Announcements, General Availability(GA)
I refer to that history throughout this article when I talk about how a service has evolved between an RCA and today.
A fourth reason worth naming, because it surfaces only after you have read several RCAs in a row: they teach a vocabulary for talking about your own system without inflating the language. AWS RCAs avoid the heroic narrative that internal postmortems often slide into ("the on-call team responded with exemplary speed"). The tone is flat, technical, and oriented at the architecture rather than the responders. After you have read four or five of them, your own postmortem prose changes shape: you write about the system, not the people, and the document becomes something a stranger could read in three years and still learn from. That tonal shift is one of the more durable benefits of the practice, and it propagates through your team faster than any style guide.
A small caveat is also worth raising. Public RCAs are edited documents. They go through legal review, communications review, and a check that no proprietary detail leaks. What you read is the architecturally and operationally accurate story, but it is not necessarily the most colourful one. The teams involved had hours that were vastly more frantic than the prose suggests; the runbooks they followed had typos; the decisions they made were closer to the wire than the timeline lets on. None of that diminishes the architectural value of the document, but it is worth remembering when comparing a public RCA to your own internal one. Your team's incident wrote in the heat of the moment will read messier, and that is fine; the goal is the architectural lesson, not a polished publication.
2. Anatomy of an AWS Public RCA
Before walking through specific cases, it helps to know the shape of an AWS RCA. Once you know it, you can read any new one in fifteen minutes and know exactly where the design lessons are.A standard AWS Summary of the Service Event has six implicit sections, in this order:
- The opening line — one sentence stating which service in which region and which window of time. The window is always in PDT/PST and almost always in us-east-1. Note the window: durations under one hour are rarely written up at all, so anything published is at least a multi-hour event.
- A short architecture primer — two or three paragraphs describing the parts of the service that matter for the rest of the document. This is usually the only place AWS explains internal design publicly. Read this section twice.
- The trigger — what change was being made when the event began. Almost always either an operational action (a deploy, a capacity change, a config push) or an external load shift the system did not handle gracefully. AWS is consistent about naming the action without naming the operator.
- The propagation path — how the local trigger became a regional event. This is the part with the most engineering content. It usually includes a discussion of saturation (threads, file descriptors, network capacity), of caching invariants that broke, and of which downstream services depended on the failed subsystem.
- The recovery — what the team did, why some steps were slow, and what made the recovery longer than the failure. Watch for sentences like "this had not been done at this scale before" or "the dashboard tooling itself was impacted." These are the cultural lessons, not just the technical ones.
- The remediations — a numbered or bulleted list of changes, ranging from immediate (rolled back the deploy, paused the automation) to architectural (cellularize the front end, add network capacity, redesign the dashboard). The architectural items are the design lessons for everyone else.
I treat the architecture primer (step 2) and the remediations (step 6) as the highest-density paragraphs. If I only have time to read two parts of an RCA, those are the two.
A couple of patterns worth knowing:
- The word "latent" appears in almost every RCA. AWS uses it to describe a bug or behavior that existed in the system for a long time and was first triggered under specific conditions. When you see "latent issue" in an RCA, the lesson is rarely "AWS missed a bug." It is "this is what hidden coupling looks like at scale, and here is how it was made visible."
- The phrase "back-off" is a tell. If an RCA mentions back-off behavior, the propagation almost always involves a thundering herd — clients retrying faster than a recovering subsystem can absorb. The remediation is usually a change to client back-off, server-side admission control, or both.
- The phrase "blast radius" and "cell" are the two words most worth highlighting. They appear in different RCAs, but they describe the same goal: making sure a failure in one slice of the system cannot take out the others.
2.1 How I Read a New RCA in Fifteen Minutes
When a new AWS RCA gets published, I follow the same five-pass routine. It takes about fifteen minutes and produces a one-page note I can use later.- Pass 1 (1 min) — opening line. Underline the service, the region, and the time window. If the window is under one hour I usually skip the rest unless it touches a workload I run.
- Pass 2 (3 min) — architecture primer. Read it twice. The second read is for vocabulary: what does AWS call this subsystem, what does it own, what does it depend on. I copy this paragraph into my note verbatim because the words AWS uses here are the words future RCAs will reuse.
- Pass 3 (3 min) — trigger and propagation. Read the propagation paragraph and write down, on a single line: trigger → first saturation → first cascade → first customer-visible symptom. Four arrows is the goal. If I cannot make it fit on one line, I have not understood the propagation yet and I re-read.
- Pass 4 (3 min) — recovery. I look for the slowest step and write down why it was slow. The two recurring answers are "this had not been done at this scale before" and "the tooling itself was impacted." Both are general lessons, not service-specific ones.
- Pass 5 (5 min) — remediations. I read the bulleted list and tag each item: immediate, short-term, architectural. The architectural ones are the only items I copy into my own backlog as candidate audit questions for my own systems.
The output of those fifteen minutes is a five-line note. Multiplied across years, those notes become the most useful AWS documentation I own.
With that template in hand, the four case studies below become much faster to read.
3. Case Study 1: 2017-02-28 Amazon S3 us-east-1 — Blast Radius and Multi-Region Design
The S3 outage on February 28, 2017 is the most influential AWS incident I know of for design education. It is short, well-documented, and the remediation list reads like a textbook chapter on cell-based architecture.3.1 What Happened — Timeline from the Public RCA
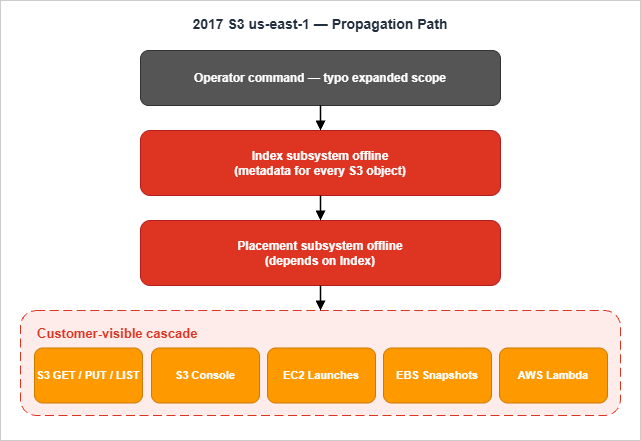
According to AWS's Summary of the Amazon S3 Service Disruption in the Northern Virginia (US-EAST-1) Region, the event started at 9:37 AM PST on February 28, 2017. An authorized S3 team member ran a command intended to remove a small number of servers from one of the S3 subsystems used by the billing process. One input was entered incorrectly, and the command removed a much larger set of servers than intended.The larger set crossed the boundary into two other subsystems that should not have been touched. Both went offline. S3 was fully operational again at 1:54 PM PST — about four hours and seventeen minutes after the start.
3.2 Root Cause as Stated by AWS
AWS is unusually direct about the trigger:S3 subsystems are designed to support the removal or failure of significant capacity with little or no customer impact. While removal of capacity is a key operational practice, in this instance, the tool used allowed too much capacity to be removed too quickly.
Two subsystems went offline. The index subsystem holds the metadata and location information for every object in the S3 region — every GET, LIST, PUT, and DELETE request goes through it. The placement subsystem allocates new storage and depends on the index subsystem to operate, so it cannot make progress while the index is down. With both offline, S3 in us-east-1 effectively could not serve traffic.
Recovery was slowed by a second-order effect: the subsystems had grown so much over the years that a complete restart at the current scale had not been performed in a long time, and the integrity-checking step took longer than expected.
3.3 What This Tells Us About AWS's Internal Design
Three internal-design facts surface in this RCA that are worth holding on to:- S3 has internal subsystems with strong coupling. The index subsystem and the placement subsystem are separate, but the placement subsystem requires the index subsystem. That coupling is a design choice — it keeps placement decisions consistent — but it also means that taking down the index always takes down placement.
- us-east-1 was a single failure domain for S3 metadata at the time. S3 already replicated data across Availability Zones, but the index and placement subsystems for the region were a single fate-shared unit. A regional event was, for that subsystem, a region-wide event.
- Operational tools can have higher blast radius than operators expect. The same command that was meant to act on a small slice could expand to a much larger one because the tool did not enforce a minimum-capacity floor. This is a tooling issue dressed up as a typo.
3.4 Lessons for Your Own Architecture
I take five lessons from the 2017 S3 RCA, in order from most to least universal:- Add a minimum-capacity floor to every operational tool that removes capacity. If a script can take down "a small set of servers", it can also take down "almost all of them" if the input is wrong. Encode the floor in the tool, not in the operator's head.
- Treat the smallest indivisible unit of your service as your real blast radius. S3 was multi-AZ for objects but single-region for metadata. If you store metadata anywhere — in DynamoDB, in a cache, in an authoritative service — your blast radius is whatever the smallest unit of that store is.
- Multi-region is the only mitigation that survives a regional event. AZ-level redundancy is necessary but not sufficient. The 2017 outage convinced many teams (including, eventually, S3 itself with replication features) that for tier-0 workloads, a regional fail-over plan must exist and must be exercised.
- Recovery time grows with scale faster than throughput does. The S3 subsystems took longer to restart than expected because they had grown without being restarted. Apply this to your own systems: if you have a stateful service that has not been cold-started in a year, you are accumulating recovery debt.
- Status pages and dashboards must work when the service does not. The S3 console and the AWS Service Health Dashboard were affected because they depended on S3. Customers learned about the outage through the Personal Health Dashboard (rebranded to AWS Health Dashboard in 2022) and external channels. Your own status page must run on a separate failure domain from the service it reports on.
3.5 Concrete Mitigations You Can Apply Now
For S3 specifically, AWS has continued to partition its internal subsystems and has added features that customers can use directly: S3 Cross-Region Replication, S3 Multi-Region Access Points, and most importantly the explicit shift to AWS History and Timeline of Amazon S3 shows multi-region as a first-class deployment story.For your own services, the immediate work is:
- Inventory every operational tool that can remove or disable capacity. Add a
--max-percentargument that defaults to a small value and refuses to run without an explicit override. - Identify the smallest fate-shared unit in your data plane. If you discover it is a single region, draft a multi-region runbook even if you do not deploy it yet. Knowing how you would do it is more than half the work.
- Move your status page to a separate AWS account, a separate region, and a separate domain. This is cheap. Doing it before the next event is much cheaper than doing it during one.
A minimum-viable safeguard for action 1 looks like this in shell — twenty lines that would have prevented the original incident:
#!/bin/bash
# Refuse to remove more than MAX_PERCENT of a fleet at once.
SET="$1" # e.g. "billing-index-fleet"
COUNT="$2" # number of servers to remove
MAX_PERCENT=10
TOTAL=$(fleet-tool list --set "$SET" | wc -l)
LIMIT=$(( TOTAL * MAX_PERCENT / 100 ))
if [ "$COUNT" -gt "$LIMIT" ]; then
echo "ABORT: $COUNT > $LIMIT (10% of $TOTAL in $SET)" >&2
echo "Re-run with --i-know-what-i-am-doing to override." >&2
[ "$3" != "--i-know-what-i-am-doing" ] && exit 1
fi
fleet-tool remove --set "$SET" --count "$COUNT"
The override exists because there are real cases where you need to act fast. Making the override explicit ensures it gets logged, reviewed, and questioned.
4. Case Study 2: 2020-11-25 Amazon Kinesis us-east-1 — Front-End Cell Failure and Thread Limits
The Kinesis event on November 25, 2020 is my favorite RCA to teach with, because it shows what happens when a single hidden constraint inside a service interacts badly with the very thing AWS does well: capacity management.4.1 What Happened — Timeline from the Public RCA
The Summary of the Amazon Kinesis Event in the Northern Virginia (US-EAST-1) Region reports that the first alarms fired at 5:15 AM PST on November 25, 2020. The triggering activity was a routine capacity addition to the Kinesis front-end fleet, which had begun at 2:44 AM PST and completed at 3:47 AM PST. Kinesis was fully back to normal at 10:23 PM PST — a window of roughly seventeen hours.That ratio — a one-hour change leading to a seventeen-hour event — is what makes this RCA important.
4.2 Root Cause as Stated by AWS
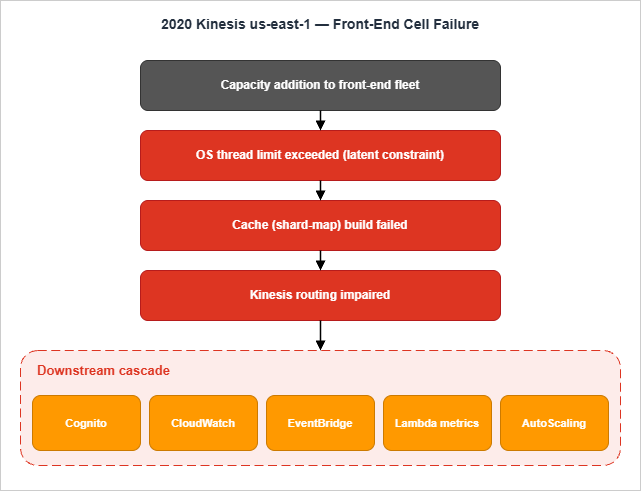
AWS identifies the root cause at 9:39 AM PST as an OS-level thread limit exceeded by the larger fleet:The new capacity had caused all of the servers in the fleet to exceed the maximum number of threads allowed by an operating system configuration.
The architectural reason this matters is in the primer:
Each server in the front-end fleet maintains a cache of information, including membership details and shard ownership.
Maintaining that cache requires each front-end server to communicate with every other front-end server, and each pairwise communication uses operating-system threads. Adding capacity therefore raised the thread count on every existing server, not just the new ones. When the limit was exceeded, cache construction failed, and the front-end servers ended up with non-functional shard maps, unable to route traffic.
Cache construction was failing to complete and front-end servers were ending up with useless shard-maps.
4.3 What This Tells Us About AWS's Internal Design
This RCA is unusually rich on internal architecture:- The Kinesis data plane is split into a front-end fleet and back-end cell-clusters. Back-end cell-clusters process streams; the front-end handles authentication, throttling, and request-routing. The back-end was already cellularized; the front-end was not yet.
- Shard ownership is distributed and cache-resolved. Each front-end server discovers and maintains a shard-map by talking to other front-ends and pulling configuration from DynamoDB. There is no single oracle for shard placement — it is gossip with a backing store.
- Capacity scaling has a quadratic coupling. Because each server keeps state about every other, doubling the fleet does not double the per-server thread count linearly with traffic; it scales with the fleet size. This is the kind of constraint that does not show up in load tests because load tests rarely test fleet expansion under traffic.
- Service boundaries are deeper than they look. Cognito, CloudWatch, EventBridge, and AutoScaling were all in the blast radius — not because they "use Kinesis" in the obvious sense, but because their internal pipelines write to Kinesis for buffering. CloudWatch metrics, in particular, became unreliable, which then cascaded into AutoScaling behavior.
4.4 Lessons for Your Own Architecture
Five lessons I draw from this case:- Audit the per-instance resource cost of being part of a fleet. If your fleet members talk to each other to maintain a cache, the per-instance cost grows with the fleet. Find out what that cost is before scaling.
- OS-level limits are architectural choices, not knobs. The thread limit — whatever your specific OS and configuration sets it to — is invisible until you cross it, and crossing it will not produce a graceful degradation. Treat ulimits the same way you treat database connection limits: monitor them, alarm on them, and document them.
- Cellularize the entry point, not just the work. Kinesis had cellularized its back-end. The front-end was a single fleet, and that became the limiting factor. The lesson generalizes: if your data plane has a router or front-end layer, that layer is part of the cell boundary.
- Indirect dependencies are real dependencies. The fact that Cognito web tiers were blocked on Kinesis writes is the kind of dependency you cannot find by reading service documentation. Find these by tracing outbound traffic, not by reading APIs.
- Health-dashboard tooling itself can be a victim. AWS's Service Health Dashboard update tool used Cognito, which was impacted. Updates were posted late. The lesson is the same as for S3 in 2017, but because it happened again three years later, the lesson is worth re-stating: status systems must run on a separate fault domain than the fault they are reporting on.
4.5 Concrete Mitigations You Can Apply Now
For Kinesis specifically, AWS announced cellularization of the front-end fleet, dedicated cache-building infrastructure, and explicit thread-consumption alarms. Many of those changes are now visible in how Kinesis On-Demand and the redesigned front-end behave under load.For your own services, three actions to take this week:
- For every service that has a fleet of homogeneous workers, write down the per-server thread / file-descriptor / connection cost as a function of fleet size. If it grows superlinearly, that is your next-event candidate.
- Pick the most critical async producer-consumer hop in your architecture (the equivalent of "Cognito writes to Kinesis"). Decide what happens if the consumer becomes slow: do producers block, drop, queue locally, or fail open? Make that decision explicit in code, not implicit in defaults.
- For an event-driven path that depends on an internal AWS streaming primitive, plan a fall-back you can switch to. The right reference for this is EventBridge Pipes — Event-Driven Architecture Patterns, which I wrote because the same questions kept coming up after Kinesis-style events.
For action 2, an explicit producer policy is just a few lines and removes the ambiguity:
# Producer-side policy for an async write to a streaming primitive.
# The point is not the algorithm; it is that the decision is in code,
# not in defaults inherited from an SDK.
def emit_event(event: dict, *, deadline_ms: int = 200) -> None:
try:
kinesis.put_record(
StreamName=STREAM,
Data=json.dumps(event).encode(),
PartitionKey=event["tenant_id"],
)
except (Throttled, Timeout) as exc:
# Decision: never block the user request on the streaming write.
# Drop with a metric and a sampled log line.
metrics.increment("emit_event.dropped", tags=[type(exc).__name__])
if random.random() < 0.01:
log.warning("dropped event", extra={"event": event})
The two-line comment is the most important part of the snippet. The shape of the failure mode is now in code review, not in someone's head.
5. Case Study 3: 2021-12-07 us-east-1 — Network Device Capacity and Internal Network Congestion
The December 7, 2021 us-east-1 event is the one most people remember, partly because of how broad the impact was and partly because the trigger was a piece of internal infrastructure most customers did not know existed.5.1 What Happened — Timeline from the Public RCA
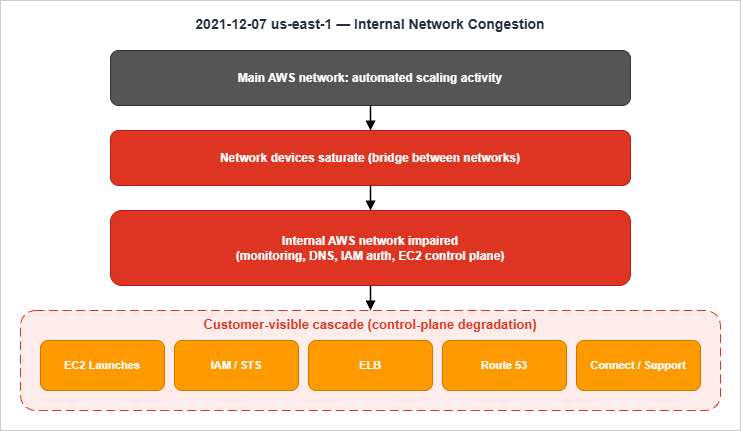
The Summary of the AWS Service Event in the Northern Virginia (US-EAST-1) Region places the start at 7:30 AM PST (3:30 PM UTC) on December 7, 2021. Most customer-visible impact was over by 2:22 PM PST (10:22 PM UTC) on the same day, although several services — STS, API Gateway, EventBridge, Fargate — saw extended recovery into the early evening (around 6:40 PM PST).The trigger was an automated activity to scale capacity in one of the services hosted on the main AWS network. That activity caused unexpected client behavior on the internal AWS network, saturating the network devices that connect the internal network to the main AWS network.
5.2 Root Cause as Stated by AWS
The RCA describes the trigger and the propagation in unusually plain language:An automated activity to scale capacity of one of the AWS services hosted in the main AWS network triggered an unexpected behavior from a large number of clients inside the internal network.
The internal network is a separate network on which AWS hosts its foundational services — monitoring, DNS, authorization, the EC2 control plane. It is connected to the main AWS network through networking devices. The surge from the automated activity overwhelmed those devices, and AWS describes the latent issue this way:
Our networking clients have well tested request back-off behaviors … but, a latent issue prevented these clients from adequately backing off during this event.
Once the network devices were congested, the foundational services lost the ability to communicate freely. Customer-visible impact included EC2 control-plane operations (new instance launches), IAM/STS, ELB control plane, Route 53, Connect, and Support.
5.3 What This Tells Us About AWS's Internal Design
The architecture primer in this RCA is short but important:- AWS runs two networks: the main one and an internal one. Customer traffic uses the main network. Foundational AWS services use the internal one. The two are bridged by network devices, and the bridge is itself a bottleneck under pathological conditions.
- Control-plane services depend on the internal network even when the data plane does not. The most striking example is EC2: existing EC2 instances were fine; new launches were not, because launches go through the EC2 control plane, which lives on the internal network.
- Back-off is an algorithm, not an aspiration. AWS calls out a "latent issue" that prevented clients from backing off. Back-off is supposed to be in every client; the question is whether it engages under the specific shape of this event. In 2021, on the internal network, it did not.
- Monitoring lives on the same network. AWS notes that the monitoring of the internal network was itself impacted: "the impairment to our monitoring systems delayed our understanding of this event." When you cannot see, you cannot act.
5.4 Lessons for Your Own Architecture
The internal-network split is a specific AWS design, but the design lessons generalize:- Find the difference between control plane and data plane in your own systems. If your control plane depends on a service that itself goes through a control plane, you have a chain. The 2021 event made many customers realize that "EC2 is up" and "I can launch new EC2 instances" are not the same statement.
- Treat back-off as a tested feature, not a default. Every retrying client in your system has back-off behavior in theory. Test it under saturation: simulate slow downstreams, dropped responses, half-closed connections. The latent issue in the AWS RCA is exactly the kind of thing only saturation testing finds.
- Separate the monitoring path from the data path. If you cannot watch your service from a place that does not depend on the service, you will be partially blind during the event you most need to see.
- Multi-region is not optional for control-plane-sensitive workloads. If your workload cannot tolerate a slow IAM, a slow EC2 control plane, or a slow STS, you must have a region you can fail to. The 2021 event was the moment this became hard to argue against.
- Some of your "regional" AWS services are actually us-east-1 services with regional veneer. Several services route their control plane through us-east-1 historically. An event in us-east-1 can therefore impact "regional" services elsewhere. AWS has been rebalancing this since 2021, but the principle applies to any global-vs-regional split in your own architecture.
5.5 Concrete Mitigations You Can Apply Now
The remediations AWS announced are instructive: they disabled the triggering scaling activity, deployed additional network configuration to protect the devices from similar congestion, redesigned the Service Health Dashboard with multi-region support, and committed to fixing the latent client back-off issue.For your own services, the highest-leverage actions are:
- Draw the dependency graph of your control plane separately from your data plane. Note any service that appears in the control plane but not in the data plane: it is likely an unmonitored single point of failure.
- Schedule a saturation game-day. Run a load that exceeds your normal throughput by 5×–10× against a dependency and verify that your retries do not amplify the problem. Add CloudFront, WAF, Lambda@Edge, and ACM to a custom origin like AWS Amplify Hosting describes one way to put a circuit breaker in front of an origin so that retries do not cascade.
- Pick one service that currently lives only in us-east-1 and write the migration plan to make it multi-region. The plan does not have to be executed; it has to exist.
A saturation game-day plan does not need to be elaborate. The minimum viable runbook is six lines:
game_day:
target: payments-api
dependency_under_test: payments-api -> stripe-webhook-relay
load_profile: 8x peak rps for 10 minutes
hypothesis: relay becomes slow at 4x peak; producer back-off engages
abort_signal: relay error rate > 50% for 60s OR p99 > 5s for 60s
observation_targets: producer retry count, relay queue depth, downstream latencies
The point is to have written the hypothesis and the abort signal before the test. The 2021 RCA's "latent issue prevented these clients from adequately backing off" is exactly the kind of thing a saturation game-day finds.
6. Case Study 4: 2023-06-13 AWS Lambda / API Errors us-east-1 — Subsystem Capacity and Trigger Path
The Lambda event on June 13, 2023 is the most recent of the four cases I cover, and the one that gives the cleanest picture of how AWS thinks about cellular architecture today.6.1 What Happened — Timeline from the Public RCA
The Summary of the AWS Lambda Service Event in the Northern Virginia (US-EAST-1) Region records that elevated error rates and latencies for Lambda function invocations began at 11:49 AM PDT on June 13, 2023. Lambda invocations began returning to normal at 1:45 PM PDT, and all affected services had fully recovered by 3:37 PM PDT — a window just under four hours.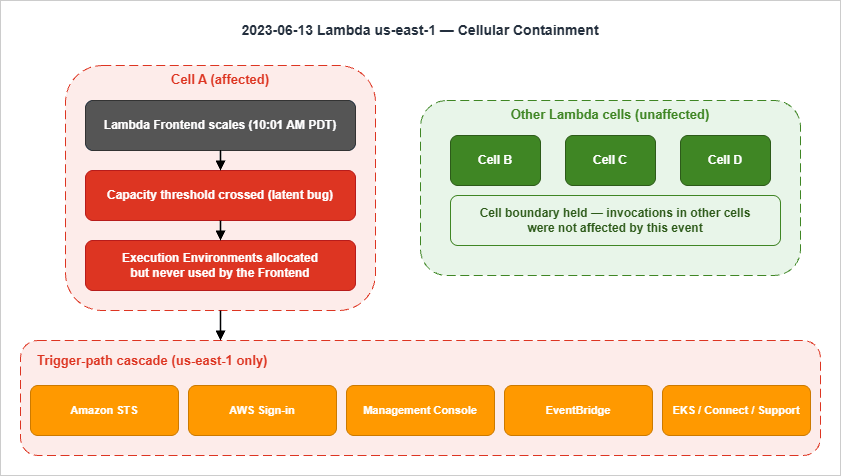
6.2 Root Cause as Stated by AWS
The architecture primer is the most explicit AWS has been publicly about Lambda's internals:AWS Lambda makes use of a cellular architecture, where each cell consists of multiple subsystems to serve function invocations for customer code.
Two subsystems matter for this event: the Lambda Frontend, which receives and routes invocations, and the Lambda Invocation Manager, which manages the underlying compute capacity (Execution Environments) per function and account.
The Lambda Frontend in one cell began scaling at 10:01 AM PDT in response to normal daily traffic increases. At 11:49 AM PDT, while adding compute capacity, it crossed a capacity threshold that had previously never been reached within a single cell. A latent bug then caused Execution Environments to be allocated for incoming requests but never fully used by the Frontend — so new invocations could not find environments and saw errors and latency.
Crucially:
Lambda function invocations within other Lambda cells were not affected by this event.
That single sentence is the pay-off line of cellular architecture, and it is the clearest contrast with the 2017 S3 event, where the failure was effectively region-wide.
6.3 What This Tells Us About AWS's Internal Design
This RCA is the most "modern" of the four because it shows the cellular pattern actually working:- Lambda is cellularized within a region. A region contains many cells; each cell has its own Frontend and Invocation Manager and serves a subset of function invocations. The cell boundary held during this event.
- Cells have well-tested operating ranges. AWS specifically calls out that the Frontend "crossed a capacity threshold that had previously never been reached within a single cell." The remediation includes bounding cells to well-tested sizes — i.e., a cell that has been load-tested to N is not allowed to scale beyond N before a new cell takes the next slice of load.
- STS and Sign-in are heavily Lambda-dependent. Some of the most visible customer impact came from STS error rates and SAML federation failures — a reminder that "AWS auth" depends on Lambda paths internally.
- The Console is regionally degraded, not globally degraded. The Management Console was unavailable for us-east-1 specifically. The lesson for customers is that "AWS Console is down" is rarely literally true; it is "AWS Console for region X is down."
This event also uncovered a gap in our Lambda cellular architecture for the scaling of the Lambda Frontend.
That sentence is the design lesson that travels: cellularizing the work is not enough; the scaling of each cell must itself be bounded.
6.4 Lessons for Your Own Architecture
Five lessons I take from this case:- Cells must have explicit upper bounds, not just lower bounds. It is common to size cells with a target capacity. It is less common to enforce a maximum that, if exceeded, triggers cell creation rather than within-cell scaling. The 2023 event is the textbook reason to do the latter.
- Latent bugs surface at thresholds you did not test. "Never reached within a single cell" is the most expensive sentence in the RCA. The mitigation is not to test every conceivable scale — it is to keep cells small enough that each cell stays within scales you have tested.
- Auth services often hide compute dependencies. STS, Sign-in, and Console all sit downstream of Lambda paths internally. If your application can tolerate Lambda being slow but cannot tolerate STS being slow, you have an indirect dependency on Lambda.
- A short event with bounded scope is the desired outcome, not a flawless service. Four hours is still painful, but compared to the seventeen-hour Kinesis event of 2020 — which propagated across services — the Lambda 2023 event was a containment success. Architecture wins when failures stay small.
- Read remediation lists for the next lesson. AWS announced "a larger architectural effort to bound all cells to well-tested sizes." That is the work that will eventually produce a future RCA where this class of failure does not recur. Watch for that pattern in your own remediations: which item is the real fix versus the immediate one.
6.5 Concrete Mitigations You Can Apply Now
For Lambda specifically, the practical advice today is:- Use Provisioned Concurrency for any Lambda whose invocation latency directly affects a user-facing path. Provisioned Concurrency removes the dependency on Frontend-side allocation under stress.
- Deploy each tier-1 Lambda function in two regions and route via a regional health check. The 2023 event was bounded to us-east-1; your workload should be bounded to "the regions I have not deployed in."
- For platform-style workloads where you operate many similar tenants, design tenant-to-cell affinity explicitly. The pattern AWS uses inside Lambda is the same one you can use for B2B SaaS isolation.
A minimal multi-region Lambda fragment in CloudFormation looks like this — note that the same code is deployed to two regions and a Route 53 health-check decides who serves traffic:
# Deployed to us-east-1 and us-west-2 with the same template.
Resources:
PaymentsFunction:
Type: AWS::Lambda::Function
Properties:
FunctionName: payments-api
Runtime: python3.12
Handler: app.handler
Code: { S3Bucket: !Ref CodeBucket, S3Key: payments.zip }
ReservedConcurrentExecutions: 200
PaymentsAlias:
Type: AWS::Lambda::Alias
Properties:
FunctionName: !Ref PaymentsFunction
Name: live
ProvisionedConcurrencyConfig:
ProvisionedConcurrentExecutions: 50
Pair this with a Route 53 health-check on a regional CloudFront distribution and you have an active-passive deployment that survives a single-region Lambda event with seconds of RTO.
7. Cross-Cutting Design Lessons
Looking at the four cases together, four design patterns keep appearing in the remediations. They are the vocabulary AWS reaches for when the same class of problem recurs.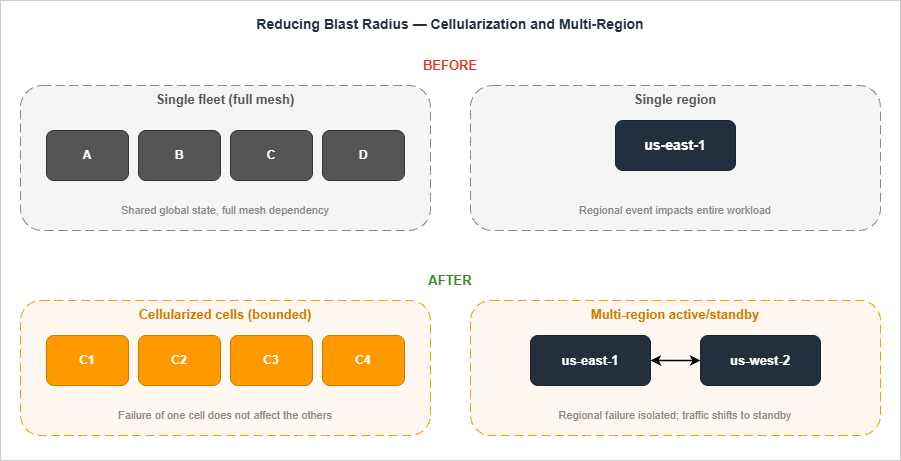
7.1 Blast Radius
Blast radius is the maximum surface a single failure can affect. Every RCA in this article is, ultimately, a story about blast radius being larger than expected:- 2017 S3: blast radius = the entire region (because metadata was a single fate-shared unit).
- 2020 Kinesis: blast radius = front-end fleet × every service that wrote to Kinesis.
- 2021 us-east-1: blast radius = every service that needed the internal network.
- 2023 Lambda: blast radius = one cell (this is the one that worked).
The discipline is to ask, for every component in your design, "what is the blast radius of this component failing entirely?" and to make that radius explicit. If the answer is "I don't know," the answer is almost always "larger than you would like."
7.2 Cell-Based Architecture
A cell is a self-contained, complete copy of a service that handles a defined subset of traffic. Cells are independent: a failure in one does not affect the others. AWS uses cells extensively — Kinesis back-end, Lambda, S3 partitions, AWS Identity and many more — and the 2023 Lambda event is the public proof that cells, when bounded, contain failures.Three properties make a cell:
- Complete: a cell can serve traffic on its own, without coordinating with other cells for the request path.
- Bounded: a cell has a maximum size that has been load-tested. Beyond that size, you create a new cell rather than scaling the existing one.
- Routable: there is a deterministic way to map a request (by tenant, by hash, by region) to a cell so that the same request always goes to the same cell.
The reason cells are hard is that they push complexity into the routing layer. The lesson from Kinesis 2020 is that the routing layer itself must be cellularized, or it becomes the new global thing. The lesson from Lambda 2023 is that cells must be bounded at the top, not just provisioned.
7.3 Static Stability
Static stability is the property that a system continues to operate, possibly in a degraded mode, when its dependencies are unavailable. The clearest example is data-plane operations that do not require control-plane calls: existing EC2 instances kept running during the 2021 event because EC2 data-plane operations do not consult the EC2 control plane.Three rules of thumb I use:
- Cache the answer the control plane gave you, and keep using it when the control plane is unreachable. This is how an EC2 instance keeps running.
- Pre-provision capacity so that you do not need to scale during an event. Auto-scaling depends on monitoring depending on a streaming pipeline depending on a network. Pre-provisioned capacity depends on none of those.
- Make the failure mode of "I cannot reach the control plane" be "keep doing what I was doing," not "stop."
A nice side effect: pre-provisioning is also what gives DynamoDB its smooth latency profile under partition pressure, which is the design point I expand on in Amazon DynamoDB Single-Table Design Guide.
7.4 Multi-Region Patterns and Their Costs
Multi-region is the only mitigation that survives a regional event. It is also the most expensive and operationally heavy pattern, and the four cases above tell you why each variant exists:- Active-passive with manual failover. Cheapest. Works for control-plane-sensitive workloads where minutes of RTO are acceptable. The 2017 S3 event is the case that makes this pattern the floor.
- Active-active behind a regional load balancer with health checks. Adds replication cost; removes manual failover. The 2021 event is the case that makes this pattern attractive for tier-0 workloads.
- Active-active with regional cells (cell per region per tenant). Maximum isolation; maximum operational cost. The 2023 Lambda event is the case that justifies this for platform services.
The pattern I use most often, for tier-1 (not tier-0) workloads, is active-passive with the passive region pre-warmed and a documented (and exercised) runbook. The runbook itself is the artifact: it forces you to discover the dependencies that block fail-over before the day you need to fail over.
7.5 Shuffle Sharding
Shuffle sharding is a refinement of cell-based architecture that AWS uses to give every customer a unique combination of cells, so that a single noisy or malicious customer cannot take down the cells of all the other customers. The Builders' Library article on shuffle sharding makes the intuition concrete: if you have eight workers and you assign each customer two of them at random, the probability that any two customers share both workers drops sharply, and the probability of a region-wide bad day drops with it.Shuffle sharding is most useful when:
- The work is tenant-scoped (a customer ID, an API key, a domain).
- A misbehaving tenant can degrade the cell it lands on (e.g. a hot key, a recursive query, a cache-bust).
- You can afford the duplication of having each tenant present on more than one cell.
The lesson from the four cases above is that shuffle sharding alone does not save you when the trigger is shared infrastructure (the network devices in 2021, the OS thread limit in 2020). Shuffle sharding is a tool for tenant-induced failures, not for infrastructure-induced ones. The two patterns compose: cellularize first to bound infrastructure failures, then shuffle-shard within cells to bound tenant failures.
For my own platform-style services, the rule of thumb I use is: assign each tenant to k cells out of n total, where k is the smallest number that lets the tenant survive losing one cell, and n is the largest number you can route across without the routing layer becoming a bottleneck of its own. Two-out-of-eight is a common starting point; in practice, the right values are dictated by request rate per tenant and by how aggressive your routing layer can be about retries.
7.6 Mapping Lessons to AWS Services
The four design patterns map to specific AWS features that did not all exist when the earlier events happened:* You can sort the table by clicking on the column name.
| Design pattern | AWS service or feature | Notes |
|---|---|---|
| Blast-radius reduction at the data layer | S3 Multi-Region Access Points, DynamoDB Global Tables, Aurora Global Database | Replication-based; tolerate region loss |
| Cell-based architecture (customer side) | AWS Organizations + per-tenant accounts, regional partitions | Forces request routing to a cell |
| Static stability for compute | EC2 instances continue running; Provisioned Concurrency for Lambda; warm pools for ASGs | Pre-provisioned capacity is the trick |
| Multi-region active-active routing | Route 53 ARC (Application Recovery Controller), Global Accelerator, regional health checks | The dial that triggers failover |
| Multi-region observability | CloudWatch cross-region dashboards, AWS Health API in another region | The status page rule from 2017 and 2020 |
A reasonable architectural ambition for a tier-1 workload today is: data layer replicated globally, compute pre-provisioned at small scale in a second region, observability that does not depend on the primary region, and a routing layer that can be flipped in minutes. None of those required a custom platform; all of them are buyable AWS features.
7.7 Failure Modes That Repeated Across All Four Cases
Reading the four RCAs side by side surfaces a small number of failure modes that AWS itself ran into more than once and that almost every customer organisation also encounters. Naming them helps you spot the same shape in your own systems before they break.The single global subsystem. S3's regional index in 2017, Kinesis's front-end fleet in 2020, the network device pool in 2021, the Lambda subsystem in 2023 — in each case there was one component that, although nominally scoped to a region, behaved as a single global dependency for the services downstream. The lesson is not that AWS made a mistake; the lesson is that every system has hidden choke points and that finding them is an explicit exercise. Run a "single point of failure" audit on your top-five workloads twice a year. The dependency you cannot remove is the dependency you must protect with extra capacity, extra alerting, and a rehearsed failover.
Capacity planning that assumed steady-state, then met saturation under recovery load. The 2017 S3 incident extended because the index subsystem had to be restarted on a fleet larger than it had been designed for. The 2020 Kinesis incident extended because the new front-end nodes hit the per-process thread limit. The 2021 network event extended because the monitoring that should have revealed the congestion ran on the same impaired internal network, delaying diagnosis, and rolling out additional network capacity took time once the cause was identified. The pattern is consistent: recovery is the worst-case load. If you only test capacity under ordinary peak, you will hit the saturation cliff during the bad day, when stakes are highest. Run capacity tests against the recovery scenario, not just the steady state.
Observability that failed at the same time as the system being observed. The 2017 service health dashboard could not update because the dashboard itself depended on S3. The 2020 console could not respond because the console depended on Cognito which depended on Kinesis. Internal observability built on the same regional substrate as the workload will fail with that substrate. The architectural rule is: the system that tells you the workload is broken must not share critical dependencies with the workload. CloudWatch in another region, AWS Health in another region, a status page on a different cloud — pick one and treat it as a load-bearing part of your incident response.
7.8 Building a Postmortem Reading Practice
The lessons in this article only become useful if your team rehearses them; otherwise they remain trivia for next time. The cheapest practice that actually changes architecture decisions is a quarterly thirty-minute reading group on one public postmortem. Pick an RCA, distribute it on Monday, schedule the discussion for Thursday, and answer four questions live in the meeting:- What was the trigger? Walk through the timeline until everyone can state it in one sentence.
- Why did the trigger propagate as far as it did? This is the architectural question, and it is where most insight is hiding.
- Which of our systems share the same shape? Be specific. Name a service, an account, a workload.
- What is the smallest change we can make this quarter that would shrink our blast radius if the same shape failed in our environment? Capture it as a ticket before the meeting ends.
The output of this practice is not a binder of postmortems; it is a backlog of small architectural improvements, each tied to a real incident in another organisation. After four quarters you will have shipped a dozen blast-radius reductions that no one would have noticed without the prompt. The compounding effect is what matters: each individual change is small, but the cumulative shift in architecture posture is dramatic, and it costs only one meeting per quarter and a single owner to drive it.
A complement worth considering is a yearly internal "game day" against one of these scenarios. Pick the 2017 S3 outage, simulate a regional dependency loss in a non-production account, and run the on-call rotation through the response. The rehearsal almost always uncovers a runbook that does not exist, an alarm that does not fire, or a credential that does not work from a backup region. Those gaps are exactly what the bad day will surface anyway; finding them on a Wednesday afternoon with coffee is better than finding them at 03:00 with a lit-up incident channel.
8. A Personal Postmortem Template
The most underrated effect of reading AWS RCAs is what they do to your own postmortem writing. Below is the Markdown template I keep in~/.notes/postmortem-template.md and copy whenever I run an internal incident review. It is shaped explicitly by the structure of an AWS public RCA — opening, architecture primer, trigger, propagation, recovery, remediations.The intent is to keep the document boring on purpose. The interesting parts are the trigger, the propagation, and the architectural item in the remediations. Everything else exists to make those three sections legible to people who were not in the room.
# Postmortem: <Service> <Region> — <Headline>
## Window
- Start: <YYYY-MM-DD HH:MM TZ>
- End: <YYYY-MM-DD HH:MM TZ>
- Customer-impact window: <separate line if it differs from the technical window>
## Summary
<Two to four sentences. What was affected, who noticed, what was the
customer-visible behavior. No causes, no remediations.>
## Architecture Primer
<Three paragraphs that someone unfamiliar with the service can read.
Describe the components that matter for this incident only. Not the
whole architecture — just the parts that appear in the propagation.>
## Trigger
<One paragraph. What change was being made or what external event
occurred when the incident began. Name the action; do not name the
operator.>
## Propagation
<The longest section. Walk through how the local trigger became the
incident. Include saturation events, retries, cache invariants that
broke, dependent services that stopped working. This is where the
engineering content lives.>
## Recovery
<What did the team do, in what order, and why was the slowest step
slow? Include timing. If a tool or dashboard was itself impacted,
say so.>
## Remediations
- Immediate: <what was disabled or rolled back, by when>
- Short-term (≤ 30 days): <bug fix, alarm, runbook>
- Architectural: <the one or two items that change the shape of the
system so this class of failure does not recur>
## Appendix: Timeline
<Bullet list, one line per timestamp. UTC. Include what was observed,
not what was concluded. Conclusions go in the Propagation section.>
## Appendix: Customer Communications
<Links to status updates, support cases opened, summaries posted.>
A few opinions about how to use it:
- Write the architecture primer before the propagation. If you cannot write the primer, the propagation will not be readable. If the primer is more than three paragraphs, the incident is too big and should be split.
- The remediations section has three buckets on purpose. The architectural item is the only one that prevents recurrence. The immediate item is the only one that closes the incident. Both are required; do not let one substitute for the other.
- The timeline is an appendix, not the document. Engineers love timelines and write them first. Readers want the summary first.
9. Summary
Across the four AWS public RCAs covered in this article, four design ideas keep returning. They are the architectural vocabulary AWS reaches for whenever the same shape of failure appears, and they are the items most worth carrying back into your own systems:- Blast radius — the maximum surface a single failure can affect. The 2017 S3 event made this concept concrete by showing that a regional metadata subsystem behaved as a single fate-shared unit. Make your blast radius explicit for every component, and then shrink it.
- Cell-based architecture — cellularize the entry point and bound each cell to a load-tested size. The 2020 Kinesis event showed what happens when the routing layer is left as a single fleet; the 2023 Lambda event showed what containment looks like when the cell boundary holds.
- Static stability — pre-provision capacity and let the data plane keep running when the control plane is unreachable. The 2021 us-east-1 event made this property visible: existing EC2 instances continued serving traffic while new launches stalled.
- Multi-region patterns — multi-region is the only mitigation that survives a regional event, and the right variant (active-passive, active-active, regional cells) depends on the workload tier. Even an unexecuted runbook is worth more than a diagram.
Three actions that compound well if you apply them in order: (1) add a minimum-capacity floor to every operational tool that can remove capacity, (2) map your control plane and data plane separately and find the indirect dependencies, and (3) run a thirty-minute postmortem reading group every quarter on one public AWS RCA. Each is small, but together they shift architecture posture in a way no single project can.
The deeper benefit of reading AWS RCAs is tonal. After enough of them, your own postmortems start describing the system rather than the responders, and the document becomes something a stranger can read in three years and still learn from. That, more than any single technical lesson, is what the practice of postmortem reading produces over time.
10. References
Primary AWS public RCAs (in the order discussed):- Summary of the Amazon S3 Service Disruption in the Northern Virginia (US-EAST-1) Region — 2017-02-28
- Summary of the Amazon Kinesis Event in the Northern Virginia (US-EAST-1) Region — 2020-11-25
- Summary of the AWS Service Event in the Northern Virginia (US-EAST-1) Region — 2021-12-07
- Summary of the AWS Lambda Service Event in the Northern Virginia (US-EAST-1) Region — 2023-06-13
AWS Architecture Blog and Builders' Library:
- Static stability using Availability Zones — Amazon Builders' Library
- Workload isolation using shuffle sharding — Amazon Builders' Library
- Avoiding fallback in distributed systems — Amazon Builders' Library
Related articles on this site:
- AWS History and Timeline — Almost All AWS Services List, Announcements, General Availability(GA)
- AWS History and Timeline of Amazon S3
- Add CloudFront, WAF, Lambda@Edge, and ACM to a custom origin like AWS Amplify Hosting
- EventBridge Pipes — Event-Driven Architecture Patterns
- Amazon DynamoDB Single-Table Design Guide
References:
Tech Blog with curated related content
Written by Hidekazu Konishi