Code Review Checklist and Anti-Pattern Catalog: A Reviewer's Reference for Modern and AI-Augmented Codebases
First Published:
Last Updated:
This article is a working reference I assemble from those fundamentals: the goals of review, the mental model a reviewer holds while reading a diff, five observation-axis checklists (bug risk, readability, performance, security, tests), a catalog of twelve recurring anti-patterns with concrete detection and repair guidance, and a focused section on what changes when the author of the diff is an AI agent. Each checklist is written so that it can be lifted and dropped into a GitHub PR template or an internal wiki without modification. Each anti-pattern is written in a "symptom → how to detect → suggested fix" form so it can be cited in line-level review comments.
The article assumes you are a working engineer who reviews and is reviewed. It does not assume any specific language, IDE, or review platform. Where I point to a primary source — Google's Engineering Practices, OWASP's Code Review Guide, Microsoft's Engineering Fundamentals Playbook, and NIST SP 800-218 — I link to it directly so the reader can follow up. The point of this catalog is not to replace those sources; it is to provide a single condensed sheet you can keep open during a real review session.
Table of Contents:
- What Code Review Is For (and What It Isn't)
- The Reviewer Mental Model — Speed vs Depth Trade-Off
- Checklist 1: Bug Risk Indicators
- Checklist 2: Readability and Naming
- Checklist 3: Performance and Resource Usage
- Checklist 4: Security
- Checklist 5: Test Coverage and Quality
- Anti-Pattern Catalog
- Reviewing AI-Generated Code
- Review Workflow Tips
- Summary
- References
1. What Code Review Is For (and What It Isn't)
Before I get into the checklists, it is worth being precise about what a review is supposed to produce. A surprising amount of friction on real teams comes from reviewers and authors disagreeing, implicitly, about the goal of the review itself. The four goals below are the ones I have found durable across every team I have worked with, regardless of language or scale.1.1 The Four Real Goals
Verify correctness with respect to a defined intent. The author claims that the change accomplishes some goal — fixing a bug, adding a feature, refactoring a module. The reviewer's first job is to read the diff and confirm that the code in front of them actually achieves that claim. This is not the same as confirming the code compiles or that the tests pass; CI does that. It is confirming that the behavior matches the stated intent, including the cases the author may not have explicitly considered.Apply design pressure before the change becomes load-bearing. Once code is merged and in use, the cost of redesigning it goes up. Review is the cheapest moment to push back on a design choice that will hurt later: a bad interface, a leaky abstraction, a missing seam for testing. Google's Engineering Practices guide states this directly: a reviewer's job is to make sure that "the overall code health of their codebase is not decreasing as time goes on" while still letting the author make progress. The trade-off is real. You are paid both to prevent decay and to not be a bottleneck.
Spread knowledge across the team. Every diff a senior engineer reviews is an opportunity for the author to learn something. Every diff a junior engineer reviews is an opportunity for the senior author to be challenged on assumptions they have stopped questioning. The Microsoft Engineering Fundamentals Playbook frames this as a core function of review: reviewers "learn and grow by having others review the code, getting exposed to unfamiliar design patterns." When a team stops doing reviews, knowledge silos almost always grow. When a team does reviews well, the senior/junior gap stays small enough that anyone can step in for anyone.
Establish shared ownership. Once two people have read and approved a piece of code, it is jointly owned. The author cannot point at the reviewer and say "they should have caught this." The reviewer cannot point at the author and say "their bug." Shared ownership is the cultural output of review, and it matters far more than any individual catch.
1.2 What Review Is Not
It is just as important to name what review is not for, because misuse of review is a major source of team friction.- It is not a style police function. If a piece of formatting is in the team's style guide, a linter or formatter should enforce it automatically. Reviewers should not be re-litigating brace placement.
- It is not a personal expression of the reviewer. "I would have written it differently" is not a valid comment. "This will break under condition X" is.
- It is not a substitute for static analysis or tests. If a class of bug can be caught by a linter, a type checker, or a test, that tooling should catch it. Reviewers should focus on the cases where human judgment is required.
- It is not a gating ritual that exists to slow work down. A team that uses review only to "show that we reviewed it" gets the cost of review without the benefit. If your review process consistently catches nothing, the process — not the reviewers — is broken.
1.3 The Mental Posture That Follows
If you accept the four goals above and the four non-goals, the reviewer's posture follows naturally. You read every line. You hold the author's stated intent in your head while doing so. You raise concerns where the code does not match the intent, where the design will hurt later, or where you genuinely do not understand — because if you do not understand, the next reader will not either. You leave style nits to tooling. You prefix purely educational comments with "Nit:" so the author knows they can be deferred. You ask questions before making demands. You remember that the author is your colleague, not your opponent.That posture, more than any checklist, is what makes review work. The checklists in §3–§7 exist to make sure that, while you are holding that posture, you are looking at the right things.
2. The Reviewer Mental Model — Speed vs Depth Trade-Off
The single most common reviewer failure mode I see is a kind of rigid uniformity: every PR gets the same depth of scrutiny regardless of size, risk, or stage of the project. That uniformity is wrong in both directions. Trivial PRs sit waiting for a deep review they did not need; load-bearing PRs get a fast skim because the reviewer was tired by the time they reached them.A useful reviewer separates two passes explicitly.
2.1 First-Pass Triage (about five minutes)
The first pass is about understanding what the change is, not whether it is right. The questions to answer in this pass are:- What is the stated purpose of this change? (PR title and description)
- What is the blast radius? (Number of files, sensitivity of the touched modules, runtime path being modified)
- What is the test surface? (Are there new tests? Do existing tests cover the changed behavior?)
- What kind of review does this need? (Mechanical refactor, behavior change, new abstraction, security-sensitive code path, AI-drafted code with limited author oversight)
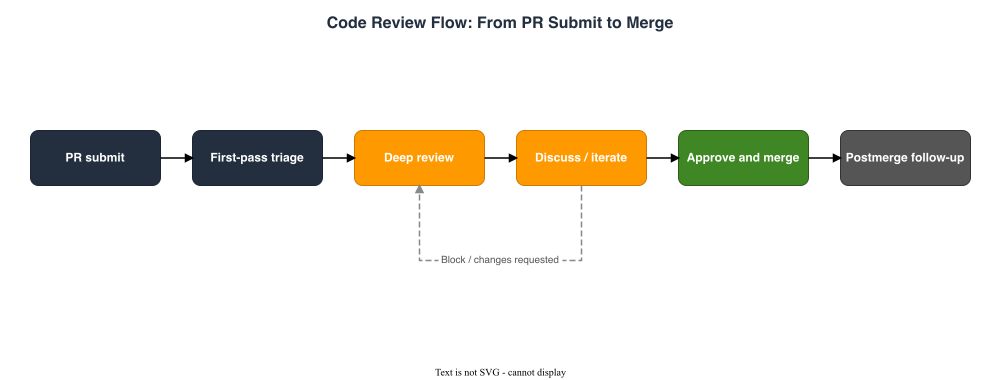
2.2 Deep Review (one axis at a time)
The deep pass should not try to look at every checklist axis at once. It is more reliable, and easier on your attention, to read the diff multiple times, each time looking for a different category of issue. My default ordering is:1. Bug risk — will this code do the wrong thing under realistic inputs? (§3)
2. Readability and naming — will the next person understand it? (§4)
3. Performance and resources — what does this look like at production load? (§5)
4. Security — what does this look like under adversarial input? (§6)
5. Tests — do the tests actually prove the claim? (§7)
You will not always do all five passes. A small refactor with no behavior change might only warrant the first two. A change to an authorization handler warrants every one. Pick deliberately, based on the first-pass plan.
2.3 The "Approve / Approve with Comments / Request Changes" Decision
On most platforms you have three options at the end of review. The decision rule I use is:- Approve — you have nothing to say that the author should act on. Style nits should not block approval; if you have only nits, write them as comments and approve.
- Approve with comments — the change is correct as-is, but you have suggestions that would improve it. The author can decide whether to act before merge or follow up later. Use this when you trust the author and the change is not safety-critical.
- Request changes — there is at least one issue that, in your judgment, must be resolved before merge. Be explicit in the comment about which issue is the blocker, so the author can address it without guessing.
Microsoft's Engineering Fundamentals Playbook puts this well: "If you have concerns about the related, adjacent code that isn't in the scope of the PR, address those as separate tasks. Don't block the current PR due to issues that are out of scope."
3. Checklist 1: Bug Risk Indicators
This is the deepest pass and the one I do first. It is also the pass where domain knowledge matters most: a reviewer who knows the system can spot a likely bug from a one-line diff that looks innocent to an outsider. The checklist below is the language-independent core; it is meant to be combined with whatever language-specific knowledge you bring.3.1 Null, Undefined, and Default-Value Paths
- Every input that can be
null/undefined/None/nil/Optional.emptyis handled or rejected before it reaches code that assumes presence. - Default values for arguments do not change observable behavior in ways the caller would not expect.
- "Not present" and "present but zero/empty" are distinguished where it matters (for example, an empty list vs. a missing list).
- Functions that return optional values document and test both branches.
3.2 Off-by-One and Boundary Conditions
- Every loop has a deliberate inclusive/exclusive choice on both ends, and the reviewer can state it without re-reading the code.
- Pagination respects the convention the rest of the codebase uses (zero-based vs. one-based, half-open vs. closed).
- Empty input (
[],"",0) does not silently produce a different code path than non-empty input. - Unicode-aware code does not assume one byte equals one character (or one codepoint equals one user-perceived character).
3.3 Time, Timezone, and Daylight Savings
- Times stored or transmitted are in UTC unless there is a documented reason otherwise.
- Times displayed to users are converted to the user's locale, not the server's.
- Date arithmetic uses calendar-aware libraries (
Temporal,java.time,dateutil), not raw second math. - Tests that involve "now" use an injectable clock so they do not break around midnight or DST transitions.
3.4 State Transitions and Invariants
- A state machine has a single source of truth (a state field, not three booleans that can disagree).
- Every state transition is enumerated; the code does not silently allow undefined transitions.
- Invariants the code depends on are either enforced at construction or asserted at the function boundary.
- Code that checks an invariant and then acts on it does so atomically (see TOCTOU in §3.6).
3.5 Resource Lifecycle
- Files, sockets, database connections, transactions, locks, and goroutines all have an owner that is responsible for closing them.
- Cleanup happens in a
finally,defer,try-with-resources, orusingblock, so it runs even if the body throws. - Loops that allocate inside the body release before the next iteration, or document why they do not.
- Background workers and watchers stop when the process they belong to stops.
3.6 Concurrency and Time-of-Check / Time-of-Use
- Shared mutable state is either synchronized, owned by one goroutine/task, or made immutable.
- Time-of-check and time-of-use are not separated by other I/O. (You check the file, then act on it; another process can change it in between.)
- Read-modify-write sequences on shared resources use compare-and-swap, transactions, or a lock that wraps both halves.
- Cancellation tokens / contexts are propagated everywhere they need to be observed.
3.7 Error Handling
- Errors are returned, not swallowed silently. (See §8.5: Silent Exception Swallow.)
- Errors at trust boundaries (network, disk, external API) are translated into domain errors before reaching business logic.
- Retries have backoff and a finite cap.
- Logged errors include enough context (request ID, user ID, input shape) to be diagnosable from logs alone.
3.8 Data Integrity Across Layers
- Database constraints (
NOT NULL, foreign keys, unique indexes) match the application's assumptions. - Migrations are reversible when possible, and irreversible ones are documented.
- Inputs from external systems are validated at the boundary, not in the middle of business logic.
- Serialization and deserialization round-trip without information loss.
4. Checklist 2: Readability and Naming
Readability is not a luxury. If the reviewer cannot understand the code on a careful read, the next person who has to debug it at 2 AM will not understand it either. The checklist here is short on purpose; readability comes from many small choices, not from a few rigid rules.4.1 Naming
- Names answer "what does this represent?" not "what type is it?".
userIdsis better thanidsList,accountIdis better thanidin a function that also takes anorderId. - Boolean names start with
is,has,can, orshould, and read as a true/false question. - Function names start with a verb that describes the side effect:
fetch,compute,apply,enqueue,commit. Pure-query functions can use a noun phrase. - Names are at the right level of abstraction: a function called
processUserthat mostly hashes a password is misnamed.
4.2 Function Size and Cohesion
- A function has a single reason to exist; if you cannot describe it in one sentence, split it.
- Microsoft's playbook offers a useful threshold: more than three arguments is a hint the function is doing too much.
- Long functions (more than ~50 lines) are usually a sign that helper functions are missing, not that the problem is intrinsically long.
- Local helpers that are only used once and only used here are still worth extracting if they have a name that explains intent.
4.3 Comments and Their Role
- Comments explain why, not what. The code already says what it does.
- A comment that restates the code in English is noise; delete it.
- Comments that document a hidden constraint, a workaround for a specific bug, or an invariant a reader cannot easily reconstruct are valuable; keep them.
TODO/FIXMEcomments include an owner and a tracking link. (See §8.7: Comment-Documented Workaround.)
4.4 Cohesion and Coupling
- Code that changes for the same reason lives in the same module; code that changes for different reasons does not.
- A module exposes the smallest interface that gets the job done. Public surface area is a long-term liability.
- Cross-module calls go through interfaces, not concrete types, when the modules represent different layers (UI, application, domain, infrastructure).
- Circular dependencies are absent or have a documented reason.
4.5 The "Will Six-Months-Future-Me Understand This?" Test
A short test for a reviewer is to imagine reading the code six months from now without context, and ask whether they would understand:- Why this branch exists.
- Why this constant has this value.
- Why this error is being caught here, and not somewhere else.
- Why this dependency is required.
5. Checklist 3: Performance and Resource Usage
Performance review is not about premature optimization. It is about catching the few patterns that turn into incidents at production load even though they look fine in tests. The checklist below is the small set of high-yield things to look for.5.1 Database Access Patterns
- No N+1 query: a loop over N items does not perform one query per item. If it does, batch with
IN (...)or a join. - Queries on large tables use indexed columns. The reviewer can name which index serves which query.
- Pagination uses keyset (cursor) pagination, not
OFFSET N, when N can grow. - Transactions are short and do not span network calls to other services.
5.2 Memory and Allocation
- Hot paths do not allocate per call when a per-instance buffer would do.
- Large reads stream rather than loading the whole payload into memory.
- Caches have eviction (TTL, LRU, size cap), so they cannot grow without bound.
- Slices/lists are pre-sized when the size is known; this avoids repeated reallocations.
5.3 Synchronous vs. Asynchronous Work
- Blocking I/O (HTTP, disk, DB) does not run on a thread that is supposed to stay responsive (UI, event loop).
- Long-running work has a timeout and a cancellation path.
- Parallelism uses an appropriate concurrency primitive (worker pool, async runtime), not unbounded
go/Thread.start/Promise.allover the entire input. - Backpressure exists somewhere: the producer cannot outrun the consumer indefinitely.
5.4 Network Calls
- Calls to external services have retries with backoff and a finite cap.
- Calls have a timeout; no call can block the caller forever.
- Idempotent retries use an idempotency key so retries do not double-charge / double-write.
- Circuit-breaking exists for calls that, when they fail, fail in droves.
5.5 The "What Does This Do at 100x Load?" Test
A useful check is to imagine the change running at 100x the current input size or 100x the current request rate:- Does any function go from O(N) to O(N²)?
- Does any allocation become a memory pressure problem?
- Does any external call become a rate-limit problem?
- Does any log line become a log volume problem?
6. Checklist 4: Security
Security review is the axis where the cost of a missed issue is highest, and the cost of a false alarm is lowest. When in doubt, raise it. The checklist here cross-references OWASP's Code Review Guide v2.0 and the Produce Well-Secured Software (PW) practice group of NIST SP 800-218; both are linked in the References section.If your codebase already uses LLM-driven features, this checklist needs a companion: my earlier post on AWS WAF prompt injection patterns covers the input-validation patterns specific to prompt-injection at the network edge.
6.1 Input Validation at Trust Boundaries
- Every input from outside the trust boundary (user, network, file system, environment, external API) is validated before being used.
- Validation is allowlist-based when possible (accept what matches a pattern) rather than denylist-based (reject what looks bad).
- Length and size limits exist on strings, lists, and uploaded files.
- Parsing happens with a well-known library; the code does not hand-roll a parser for security-sensitive formats (JWT, X.509, SQL, HTML).
6.2 Output Encoding
- Data passed into HTML, JavaScript, SQL, shell, LDAP, or another grammar is encoded for that grammar at the boundary, not concatenated raw.
- Templating engines have auto-escaping enabled.
- Logged data is not blindly trusted; secrets, tokens, and PII are redacted before they hit logs.
- File downloads set
Content-Dispositionand a content type the user cannot change.
6.3 Authentication and Authorization
- Authentication and authorization are separate concerns. Authentication asks "who are you?"; authorization asks "are you allowed to do this?".
- Authorization is enforced server-side. Client-side checks are UX hints, not gates.
- Object-level authorization is checked in the handler, not assumed from URL routing.
- Privileged actions are gated by an explicit check, not by absence of a check.
6.4 Secrets, Keys, and Credentials
- No secret is committed to the repository. (Lockfiles, fixtures, screenshots, and example configs are common offenders.)
- Secrets are read from a secret store at runtime, not from config files.
- Pre-commit hooks scan for accidental secret leaks.
- Rotation is supported: the code can read a new value without a redeploy.
6.5 Dependency Risk
- Lockfile changes are reviewed as carefully as code changes. A new transitive dependency is a new line of trust.
- New dependencies are checked against the team's allowlist or, if there is none, sanity-checked: who maintains it, when did the latest release land, does the package name match what the documentation calls it?
- Slopsquatted package names are a real attack vector. (See §9.1 for the AI-specific failure mode that produces them.)
npm audit,pip-audit,cargo audit, or equivalent runs in CI and the team has a policy for what to do when it finds a high-severity advisory.
6.6 Logging and Auditing
- Authentication and authorization decisions (success and failure) are logged with enough context to investigate.
- Logs do not include passwords, full tokens, or other secrets.
- Logs include a request ID that lets a single request be traced across services.
- Sensitive operations (account changes, money movement, permission grants) leave an audit trail.
6.7 The "What Would an Attacker Do?" Test
OWASP's Code Review Guide repeatedly frames this as "code crawling": you are not just reading the code, you are reading it through an attacker's eyes. Useful prompts to keep in your head:- What if this input is a hundred times longer than expected?
- What if this input contains the delimiter the parser uses?
- What if the user submitting this request is logged in but as someone else?
- What if this happens a thousand times a second?
- What if the network call this code depends on returns success but with garbage in the body?
7. Checklist 5: Test Coverage and Quality
Coverage percentage is a vanity metric. A test suite at 95% line coverage that does not actually verify behavior is worse than a smaller suite that does, because it produces false confidence. The checklist below is about whether the tests prove what the author claims, not how many lines they touch.7.1 Tests Verify Behavior, Not Implementation
- Each test has a clear "given/when/then" structure or equivalent. A reader can name the property the test is enforcing.
- Tests fail when the behavior is wrong, not just when the implementation changes. Refactors should not break passing tests if the public behavior is preserved.
- Tests assert specific outcomes (
assert result.status == "completed"), not "no exception was raised." - Tests use real values, not mocks-of-mocks. (See §8.10: Test Theater.)
7.2 The Right Mix
- Unit tests are fast and do not touch the network or the file system.
- Integration tests cover the seams between subsystems (handler ↔ service ↔ repo ↔ database).
- End-to-end tests cover at least one happy path through the user-visible surface.
- Property-based tests cover invariants that are hard to enumerate by hand.
7.3 Test Hygiene
- A failing test fails with a clear message that does not require reading the test source to understand.
- Tests are independent. Test #2 does not depend on test #1 having run.
- No
Thread.sleep(1000)for synchronization; use a deterministic wait condition or a virtual clock. - Flaky tests are quarantined or fixed, not retried until they pass.
7.4 Coverage at the Boundary
- Every branch in error handling has at least one test, or has a documented reason for not.
- Every input validator has a test for at least one rejected input.
- Public APIs have tests for the documented contract (success, expected failure, edge cases).
- Newly added regression tests reference the bug ID or commit they were added for.
7.5 Contract Tests for External (and AI-Drafted) Code
When code calls an external API, the test that "proves" it works against a mock proves only that the mock matches the production API. If the production API has changed, the mock has not, and the test passes anyway. A contract test — one that runs against a real or recorded version of the API — is the only way to detect that drift.This applies with extra force to AI-drafted code that claims to call an external API. The model may have invented the method or the parameter shape. (See §9.1.) A contract test against the real API is the surest detection.
8. Anti-Pattern Catalog
The patterns below are the ones I find myself flagging week after week, on every team I have worked with, in every language. For each one I give the symptom (how it shows up in a diff), how to detect it (what to grep for, what to look at), and a suggested fix.
8.1 #1: God Function
- Symptom: A single function spans 100+ lines, takes more than three or four arguments, and reads like a small program.
- How to detect: Function length, parameter count, cyclomatic complexity (
radon,eslint complexity,gocyclo). Subjectively: if the reviewer cannot describe the function in one sentence. - Suggested fix: Extract internal stages into named helper functions. Each helper should have a name that explains intent, not implementation. Resist pure mechanical extraction that just moves lines without making the code easier to read.
8.2 #2: Boolean Parameter Trap
- Symptom:
process(user, true, false, true). The reader has no idea what those booleans mean. - How to detect: Function calls with two or more positional boolean arguments.
- Suggested fix: Replace booleans with named enums, options objects, or split into separate functions:
processStrict(user)vs.processLenient(user). Most "boolean parameters" turn out to encode two different operations that share code.
8.3 #3: Premature Abstraction
- Symptom: An interface with one implementation and "we'll have more later." A factory that creates a single concrete class.
- How to detect: Grep for interfaces and abstract classes; check how many implementations actually exist. The Google Engineering Practices guide names this directly: "Encourage developers to solve the problem they know needs to be solved now, not the problem that the developer speculates might need to be solved in the future."
- Suggested fix: Inline the abstraction back into the single implementation. Add it again when a second implementation actually appears, with full information about what they have in common.
8.4 #4: Defensive Programming Overkill
- Symptom: Every internal function checks every argument for null, type, range, before doing anything. The "real" logic is buried under guard clauses.
- How to detect: Internal helpers that re-validate inputs that the caller has already validated.
if not isinstance(...)checks on values the type system already guarantees. - Suggested fix: Validate at trust boundaries (user input, network input, deserialized data). Trust internal callers. Document and enforce the contract once, at the boundary, instead of redundantly at every step.
8.5 #5: Silent Exception Swallow
- Symptom:
try { ... } catch (Exception e) { }ortry: ... except: pass. The error disappears without trace. - How to detect: Grep for empty catch blocks,
except: pass,catch ... { }, and barerescue. Static analyzers (SonarQube,pylint W0702) will flag many of them. - Suggested fix: Either handle the error specifically (translate it, retry it, surface it to the caller), or let it propagate. If you must suppress, log enough context that the suppression is visible later, and narrow the exception type to what you actually expect.
8.6 #6: Magic Numbers Without Named Constants
- Symptom:
if (retries > 3) ...,Thread.sleep(86400000),if (status == 7) .... The reader has to guess what 3, 86400000, and 7 mean. - How to detect: Grep for numeric literals in conditionals. A handful of small numbers like
0,1,-1are normal; everything else deserves a name. - Suggested fix: Lift the magic number into a named constant:
MAX_RETRIES = 3,ONE_DAY_MS = 86_400_000,STATUS_PENDING = 7. The constant becomes searchable, gets documentation, and can be changed in one place.
8.7 #7: Comment-Documented Workaround
- Symptom:
// HACK: don't ask,# FIXME: this is broken,// TODO: refactor this someday. No owner, no ticket, no plan. - How to detect: Grep for
TODO,FIXME,HACK,XXXwithout an owner or a tracking link. - Suggested fix: Either fix it now (if it is in scope), or write a real ticket and reference it:
// TODO(@alex, ENG-1234): replace with structured logging. Unowned TODOs accumulate forever; owned ones can be tracked and closed.
8.8 #8: Tight Coupling via Concrete Types
- Symptom: A high-level service imports
PostgresUserRepositorydirectly, instead of aUserRepositoryinterface. Tests cannot run without a real Postgres. - How to detect: Imports of concrete infrastructure types from non-infrastructure layers; tests that require a real database to instantiate the system under test.
- Suggested fix: Introduce a narrow interface where the layers cross. The high-level service depends on the interface; the concrete type is wired in at composition time. Tests can substitute an in-memory implementation.
8.9 #9: Time-of-Check / Time-of-Use (TOCTOU)
- Symptom:
if (file.exists()) { file.open(); }. Betweenexists()andopen(), another process can delete the file. - How to detect: Pairs of operations on the same resource where the second operation does not handle the case that the resource changed between calls. Race conditions on file system, database, and shared memory state.
- Suggested fix: Collapse check and use into a single atomic operation: open with
O_CREAT | O_EXCL, do the database update inside a transaction, hold a lock that wraps both halves. If you cannot collapse them, handle the race explicitly: catch the failure, decide whether to retry, and document the chosen behavior.
8.10 #10: Test Theater
- Symptom: A test sets up an elaborate mock, calls the system under test, and asserts that the mock was called with the expected arguments. It does not assert anything about the system's actual output.
- How to detect: Tests whose only assertions are
verify(mock).method(...)or equivalent. Tests where 90% of the lines are mock setup. Tests that pass when the implementation is replaced with a stub that does nothing. - Suggested fix: Assert against the public, observable behavior of the system — the return value, the database state, the message published — not the internal call graph. Mocks should be used only at trust boundaries (network, time, randomness), not at every internal seam.
8.11 #11: Hidden State Mutation
- Symptom: A function called
getX()quietly mutates state as a side effect. A "pure-looking" computation modifies its inputs. - How to detect: Getters and pure-named functions that have side effects (
get,compute,is,find). Functions that take a value and return a value but also modify a passed-in collection or object. - Suggested fix: Either rename the function to admit the side effect (
getOrCreateX,computeAndCache,popX), or remove the side effect. Make it impossible for a reader to be surprised.
8.12 #12: Copy-Paste with Subtle Difference
- Symptom: Two functions that look 95% identical but with one or two lines changed. A reader has to diff them line by line to see the difference.
- How to detect: Files where two adjacent functions share long runs of identical code. Editors and tools (
jscpd,pmd-cpd,simian) detect this automatically. AI-drafted code is especially prone to this pattern; see §9.5. - Suggested fix: Extract the shared portion into a helper, parameterized by the difference. If the difference is meaningful (the two cases really are different domain operations), use names that make it clear. The danger of copy-paste is not the duplication itself; it is that one copy will be fixed and the other will not.
9. Reviewing AI-Generated Code
Most of this article applies to AI-generated diffs without modification: a bug is a bug regardless of who wrote it. But AI-generated code has a small number of failure modes that are unique to its origin, and they deserve their own section. The context for this section is that AI is now writing a substantial fraction of new code — Sundar Pichai is reported to have said on Alphabet's Q3 2024 earnings call that more than a quarter of new code at Google was being generated by AI (then reviewed and accepted by engineers), and Anthropic CEO Dario Amodei has been widely quoted as predicting in early 2025 that AI would write the majority of new code across the industry within months. Whether or not those exact figures generalize, the direction is clear: reviewer attention has not scaled with that volume, and the patterns below are where attention should land.If you are still ramping on this style of review, my earlier essay Beyond Self-Disruption: The Paradigm Shift Software Engineers Need in the AI Era covers the underlying shift in engineer's role from "writer" to "reviewer of AI output". The companion piece Claude Code Getting Started covers the local-agent setup that is generating most of these diffs in practice.
9.1 Hallucinated APIs and Slopsquatted Packages
This is the single highest-yield AI-specific check. AI models confidently emit method names that do not exist on the type they are calling, parameter shapes that the library does not accept, and import names that are not in any registry.The scale is not small. The Spracklen et al. study "We Have a Package for You! A Comprehensive Analysis of Package Hallucinations by Code Generating LLMs" (USENIX Security 2025) ran 576,000 code samples through 16 major LLMs and found that, on average, 19.7% of recommended packages did not exist on npm or PyPI, with open-source models hallucinating at 21.7% and even GPT-4 Turbo doing so 3.59% of the time. More worryingly, the same study found that 43% of hallucinated package names recurred across multiple queries, which makes them a stable target for an attacker to register pre-emptively. This attack pattern was named "slopsquatting" by Seth Larson of the Python Software Foundation in 2025: register the package name an LLM keeps inventing, then wait for someone's
pip install to land on it.What to look for in a review:
- Imports of packages whose names you do not recognize. Look them up. Confirm they exist, are maintained, and match the documentation.
- Method calls on a type, where you cannot point to the documentation for that method. Check the official docs, not just the model's claim.
- Parameter shapes that look "almost right" — the right keys with one extra one, or a tuple of the wrong length.
- Configuration values that look like real configuration but are not in any version's documentation.
9.2 Plausible-but-Wrong Patterns
The model has read enough code to know what idiomatic code in your language looks like. It can produce a function that is structured exactly the way an expert would structure it, with all the right helpers and all the right comments — and that does the wrong thing.The classic failure modes:
- The model has implemented "what most callers want" instead of what your specific caller wants.
- The model has chosen the API style of an older version of the library you actually use.
- The model has converted a domain-specific business rule into a generic one because the generic one is more common in its training data.
- The model has applied a security pattern (e.g., HMAC) correctly but with the wrong key derivation, because that variant is more common in examples.
9.3 Over-Abstraction and Speculative Generality
AI-generated code tends to be more generic than it needs to be. The model has been trained on a corpus that values "extensibility" and "flexibility" as virtues; it will, given a chance, produce a strategy pattern when a single function would do, and an interface with one implementation when no interface was needed.This is the AI-specific version of §8.3, and the most common form of "future-proofing that will never be used" in AI-generated diffs. Google's Engineering Practices guide warns about this directly — "Reviewers should be especially vigilant about over-engineering." The AI does not know that your team's policy is "write the simple version first."
What to look for:
- Interfaces with exactly one implementation in the same change set.
- Configurable parameters with only one value passed.
- Abstract base classes whose only subclass is in the same file.
- Function signatures that accept "any options object" when the real callers pass two specific options.
9.4 Missing Design Rationale
When a human writes code, the choice is usually conscious: "I picked a hash map here because the lookup pattern is by key." When AI writes code, the choice is statistical: "this kind of code usually uses a hash map." The result is functionally similar code but with no documented reason behind any choice.This becomes a problem when the code needs to change. The next engineer cannot tell whether a particular choice was deliberate (and should be preserved) or coincidental (and is fine to change). Over time, code without rationale becomes load-bearing in ways no one understands, and changes get more dangerous than they need to be.
What to look for:
- Non-obvious choices (data structure, algorithm, library, error-handling strategy) without a comment, commit message, or PR description that explains them.
- Configuration values without a comment explaining what determined the value.
- A workaround for a specific bug, without a reference to that bug.
9.5 Mass-Produced Boilerplate
This is the failure mode that most easily slips through review: the diff is large, mostly uniform, and looks fine paragraph by paragraph. It might be 20 nearly-identical handlers, or 30 nearly-identical tests, or a hundred lines of validation code that all look the same. Each one passes individual scrutiny. The aggregate is a mountain of code that does not need to exist.The failure mode here is reviewer fatigue: by the tenth nearly-identical block, the reviewer is not really reading any more.
What to look for:
- Diffs where deletion of any one block would not change the system's behavior.
- "Test suites" of dozens of tests that all assert the same property under different names.
- Validation code that re-implements what a single library call would do.
- Generated code that is checked in but could be regenerated.
9.6 The AI-Specific Reviewer Checklist
Pulling the above into a single checklist:- Every imported package exists. Every called method exists. (Not "looks like it should exist".)
- The diff matches the PR description's stated intent, not just "looks like correct code."
- No interface with one implementation, no factory with one product.
- Non-obvious design choices have a documented rationale.
- Repeated near-duplicate blocks have been collapsed before merge.
- Contract tests cover any external API the AI claims to call.
- Security-sensitive code (auth, crypto, input validation) has been reviewed by a human who can vouch for its correctness, not just by the agent that wrote it.
10. Review Workflow Tips
The checklists above are about what to review. This section is about how to make review work as a sustained team practice rather than a heroic individual one.10.1 The Block / Suggest / Nit Decision
Not every comment carries the same weight. Reviewers and authors save themselves a lot of friction by being explicit about which weight a comment has.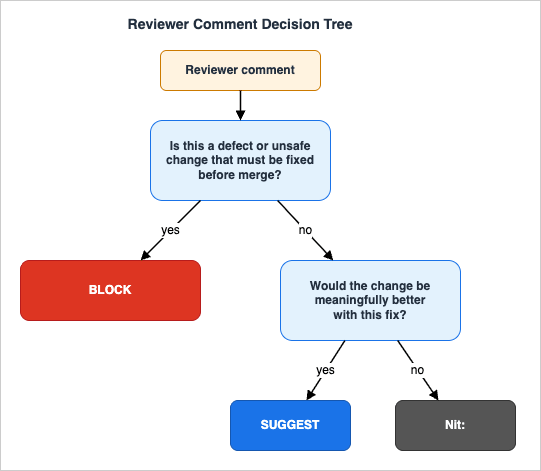
Nit: prefix tells the author: "you can ignore this if you disagree." A Suggest tells the author: "I would prefer this, but you decide." A Block tells the author: "I will not approve until this is resolved." Mixing these signals — demanding nits, soft-pedaling defects — is one of the most common sources of review friction.10.2 PR Size
The Microsoft Engineering Fundamentals Playbook puts it bluntly: the more code there is in a PR, the lower the chance of finding any individual bug. The threshold is not a number of lines — it is whether a reviewer can actually hold the change in their head. Practical heuristics:- Aim for a PR that can be reviewed in 30 minutes or less.
- If the diff is over 400 changed lines, ask whether it can be split.
- Refactors and behavior changes go in separate PRs. A reviewer reading a "rename plus refactor plus new feature" diff has lost the ability to spot the bug.
- Generated code, lockfile updates, and trivial mechanical changes can be split into their own PR so the reviewer's attention is reserved for the substantive change.
10.3 Asynchronous Review Etiquette
Most teams are distributed, and reviews happen asynchronously. A few habits help:- Reviewers commit to a turnaround time (e.g., "first response within one business day"). Stale PRs cost more than slow reviews.
- Authors leave a self-review note describing what changed and why; this gets the reviewer through the first-pass triage faster.
- Threads should converge: after two or three rounds, escalate to a synchronous conversation rather than continuing to type past each other.
- Mark resolved threads as resolved; leave only the open ones visible. Future readers will thank you.
10.4 Dividing Labor with Automated Review
Automated review tools (linters, type checkers, security scanners, AI-assisted reviewers like CodeRabbit, GitHub Copilot, and bots that summarize a diff) are now part of the toolchain. The right division of labor is:- Tools first: anything mechanical (style, simple bugs, dead code, dependency vulnerabilities) goes through automated tools before a human looks at the diff.
- Human second, on the things tools cannot judge: design choices, architectural fit, the AI-specific patterns in §9, the security-sensitive judgment calls.
- Tools never: approval. A human signs off on the change. Tools generate signal; humans make decisions.
10.5 Reviewing Your Own Diff
A surprising amount of value comes from re-reading your own diff before you ask anyone else to. The questions to ask:- Would I, reading this cold tomorrow, understand it?
- Did I name everything well, or did I leave a
tmpand adataand aresult? - Did I add a comment for every non-obvious choice?
- Did I add tests for the case I had to think about hardest while writing this?
- Did I leave debug prints, commented-out code, or
// TODOmarkers without owners?
11. Summary
The four-line summary of this article: review for behavior, not for taste; spend depth on the changes that warrant it; treat AI-generated code as the work of a fast junior who has never met your codebase; and write the comments you wish someone had written for you.The five checklists are:
1. Bug risk — nulls, off-by-ones, time, state, resources, concurrency, errors.
2. Readability and naming — names, function size, comments, cohesion, the six-month-future-you test.
3. Performance and resources — database access, allocation, sync vs. async, network, the 100x test.
4. Security — input validation, output encoding, authn/z, secrets, dependencies, logging, the attacker test.
5. Tests — behavior over implementation, the right mix, hygiene, boundary coverage, contract tests for external (and AI-drafted) calls.
The twelve anti-patterns are a working list. They are not exhaustive; they are the ones I find myself flagging most often. Add to them as your team finds new ones.
The five AI-specific risks — hallucinated APIs, plausible-but-wrong patterns, over-abstraction, missing rationale, mass-produced boilerplate — are not a separate review process. They are where to land your existing reviewer attention now that AI is writing the diff.
If this catalog is useful to you, the highest-leverage thing you can do with it is paste the section that fits your team's biggest current pain into your PR template, your CONTRIBUTING.md, or your team wiki. The cost of doing that is a few minutes. The benefit is a checklist that gets read every time someone opens a pull request, instead of a checklist that gets bookmarked once and never re-opened.
12. References
- Google Engineering Practices Documentation — Code Review Developer Guide
- Google Engineering Practices Documentation — The Standard of Code Review
- OWASP Code Review Guide v2.0 (Project Page)
- OWASP Code Review Guide v2.0 (PDF)
- Microsoft Engineering Fundamentals Playbook — Code Reviews
- Microsoft Engineering Fundamentals Playbook — Reviewer Guidance
- NIST Special Publication 800-218 — Secure Software Development Framework (SSDF) Version 1.1
- NIST SP 800-218 (PDF)
- Spracklen et al. — We Have a Package for You! A Comprehensive Analysis of Package Hallucinations by Code Generating LLMs (USENIX Security 2025)
- Beyond Self-Disruption: The Paradigm Shift Software Engineers Need in the AI Era
- Claude Code Getting Started — Why Knowing About Local AI Agents Changes Everything
- AWS WAF for Generative AI — Prompt Injection Defense Implementation Patterns
References:
Tech Blog with curated related content
Written by Hidekazu Konishi