Agentic RAG Architecture on Amazon Bedrock - Query Planning, Retrieval Grading, and Self-Correction with AgentCore, Knowledge Bases, and Reranking
First Published:
Last Updated:
1. Introduction
A static Retrieval-Augmented Generation (RAG) pipeline does one thing: it embeds the user's question, runs a single vector search, stuffs the top chunks into a prompt, and generates an answer. When the search is good, the answer is good. The problem is what happens when the search is bad — when the question is ambiguous, spans several documents, uses vocabulary the corpus does not, or needs two facts that live in different places. A static pipeline has no way to notice that its retrieval missed; it generates a confident answer from irrelevant context, and the failure surfaces only when a user complains.The hard part of production RAG is therefore not the retrieval call. It is the operational loop around the call: planning the right queries, grading what came back, deciding to search again with a different strategy, and verifying that the final answer is actually grounded in what was retrieved. That loop is what "agentic RAG" — also called corrective RAG or self-RAG — refers to. An agent treats retrieval as a tool it can invoke repeatedly, inspect the results of, and re-plan around, rather than as a one-shot function.
This article is a single, end-to-end implementation walkthrough of one named reference architecture: the Self-Correcting Retrieval Loop on Amazon Bedrock. It connects Amazon Bedrock AgentCore Runtime, Bedrock Knowledge Bases, the Bedrock Rerank API, Bedrock Guardrails, and Bedrock evaluations into a loop that plans, retrieves, reranks, grades, re-queries when needed, generates with citations, verifies grounding, and feeds quality metrics back into evaluation. The goal is a system you can reason about, instrument, and debug — not a demo.
This is the upper layer of an existing foundation. The mechanics of building a static knowledge base — ingestion, chunking, vector-store selection, and the basics of Guardrails — are covered in Amazon Bedrock RAG Architecture Guide, and this article deliberately delegates those topics there rather than repeating them. For the agent-hosting layer, see Amazon Bedrock AgentCore Implementation Guide Part 1: Foundation, and for terminology, Amazon Bedrock Glossary. What follows assumes you can already stand up a knowledge base and focuses entirely on the agent loop, retrieval-quality control, self-correction, grounding, and evaluation.
A note on currency and scope: Amazon Bedrock's AI surface area changes quickly. Every model ID, API field, and limit in this article was verified against the official AWS documentation at the time of writing, but you should re-verify the current values — model lifecycle, regional availability, and quotas in particular — before depending on them. This article contains no pricing figures by editorial policy; consult the official Amazon Bedrock pricing page for cost characteristics. It also avoids attack payloads and treats safety controls as defense-in-depth rather than guarantees.
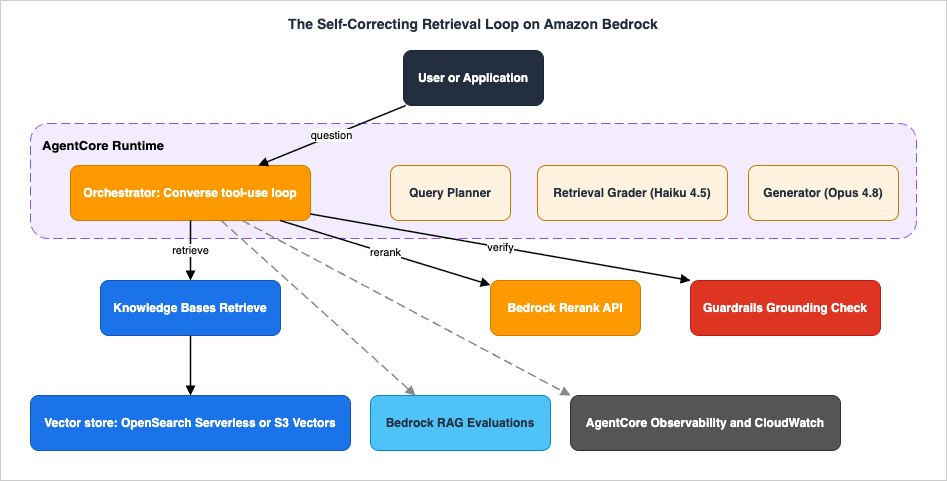
2. The Reference Architecture at a Glance
The Self-Correcting Retrieval Loop is built from nine components. Six AWS AI services collaborate so that a single question can be planned, searched, re-searched, generated, and verified before the user ever sees a token.| Component | Service / API | Role in the loop |
|---|---|---|
| Orchestrator | AgentCore Runtime + Bedrock Converse | Hosts the agent; drives the tool-use loop |
| Query planner | Converse tool use (or KB QUERY_DECOMPOSITION) | Splits a complex question into sub-queries |
| Retriever | Knowledge Bases Retrieve | Hybrid/semantic search with metadata filters |
| Reranker | Bedrock Rerank | Reorders candidates by cross-encoder relevance |
| Retrieval grader | Converse (Claude Haiku 4.5) | Scores whether the context answers the sub-query |
| Loop controller | Application code | Bounds iterations, latency, and escalation |
| Generator | Converse (Claude Opus 4.8) | Produces the cited answer |
| Grounding verifier | Guardrails ApplyGuardrail | Contextual grounding + relevance check |
| Evaluation harness | Bedrock RAG evaluations | Offline regression + online quality metrics |
The orchestrator is a Strands Agents application running on AgentCore Runtime, which provides a serverless, framework-agnostic host with per-session microVM isolation and execution windows of up to 8 hours — long enough for multi-step retrieval loops that involve several model calls. The agent itself is a Bedrock
Converse tool-use loop: the model decides when to call retrieve, when to rerank, when it has enough context, and when to stop. Knowledge Bases is the system of record for retrieval; the Rerank API sharpens the candidate ranking; Guardrails performs the independent grounding check on the way out; and Bedrock evaluations close the quality loop. The rest of this article walks one question through this architecture, component by component, then covers the cross-cutting concerns and the failure modes that span them.3. Static RAG as the Floor, and When to Go Agentic
Static RAG is the correct default. A singleRetrieveAndGenerate call against a well-built knowledge base answers the majority of factual questions accurately, cheaply, and with the lowest latency, and it is the floor this architecture builds on. The detailed mechanics of that floor — data sources, chunking strategies, embedding-model choice, and vector-store selection — live in Amazon Bedrock RAG Architecture Guide. You should reach for the agentic loop only when the question shape defeats single-shot retrieval.Three signals justify the added complexity:
- Ambiguous or under-specified queries. "How do I configure it?" has no single good embedding because "it" is unresolved. An agent can ask a clarifying sub-query against the corpus or rewrite the query before searching.
- Multi-hop reasoning. "Which of our two storage tiers has the lower durability, and what is the migration path?" requires retrieving facts about both tiers and then a third document about migration. One vector search cannot reliably surface all three.
- Multiple sources or strategies. When the answer might live in any of several knowledge bases, or when keyword precision matters as much as semantic similarity, the agent benefits from issuing several differently-shaped queries and merging the results.
Amazon Bedrock itself offers a built-in, single-call form of one of these patterns: query decomposition, where the managed orchestration layer of
RetrieveAndGenerate breaks a complex question into sub-queries automatically. That is the right tool when the only thing you need is decomposition and you want AWS to manage the orchestration. The agentic loop in this article is for the harder case: when you need to inspect retrieval quality between steps, branch on it, escalate to a different source, and enforce your own loop budget. Section 4 shows both, side by side.4. Query Planning and Decomposition
The first stage turns the user's question into one or more well-formed retrieval queries. There are two implementation paths, and a production system often uses both.4.1 KB-native query decomposition
When decomposition is all you need, enable it onRetrieveAndGenerate and let Bedrock's orchestration layer handle the sub-query generation, retrieval, and synthesis in one managed call. The orchestration configuration carries a queryTransformationConfiguration of type QUERY_DECOMPOSITION:import boto3
agent_rt = boto3.client("bedrock-agent-runtime", region_name="us-west-2")
response = agent_rt.retrieve_and_generate(
input={"text": "Who scored higher in the 2022 final, Argentina or France, and by how many goals?"},
retrieveAndGenerateConfiguration={
"type": "KNOWLEDGE_BASE",
"knowledgeBaseConfiguration": {
"knowledgeBaseId": "KB_ID",
"modelArn": "arn:aws:bedrock:us-west-2:ACCOUNT_ID:inference-profile/us.anthropic.claude-opus-4-8",
"orchestrationConfiguration": {
"queryTransformationConfiguration": {
"type": "QUERY_DECOMPOSITION"
}
},
},
},
)
print(response["output"]["text"])
for citation in response["citations"]:
for ref in citation["retrievedReferences"]:
print(ref["location"], ref.get("metadata"))
citations array ties each claim back to a retrieved chunk. This is single-call, fully managed, and has no agent loop — which is exactly its limitation: you cannot interpose your own grading or escalation logic between the sub-queries and the answer.4.2 Agent-driven planning with Converse tool use
When you need that control, make planning an explicit step in aConverse tool-use loop. You expose retrieval as a tool, and the model decides how to decompose the question and how many times to search. The planner is just a system instruction plus a tool schema; the agent emits a tool_use block, your code executes the retrieval, and the loop continues until the model stops asking for tools.import boto3
bedrock = boto3.client("bedrock-runtime", region_name="us-west-2")
TOOL_CONFIG = {
"tools": [
{
"toolSpec": {
"name": "search_knowledge_base",
"description": (
"Retrieve passages from the corpus for ONE focused sub-question. "
"Call this multiple times with different sub-questions when the user's "
"question is multi-part. Do not pass the full multi-part question."
),
"inputSchema": {
"json": {
"type": "object",
"properties": {
"sub_query": {
"type": "string",
"description": "A single, self-contained question to search for.",
},
"metadata_filter": {
"type": "object",
"description": "Optional structured filter, e.g. {'product': 'storage'}.",
},
},
"required": ["sub_query"],
}
},
}
}
],
"toolChoice": {"auto": {}},
}
SYSTEM = [{
"text": (
"You are a retrieval planner. Decompose the user's question into the minimum "
"set of self-contained sub-questions, search for each, and only answer once the "
"retrieved context is sufficient. If a search returns weak context, reformulate "
"and search again rather than guessing."
)
}]
messages = [{"role": "user", "content": [{"text": "Which storage tier has lower durability, and what is the migration path to the other?"}]}]
response = bedrock.converse(
modelId="us.anthropic.claude-opus-4-8",
system=SYSTEM,
messages=messages,
toolConfig=TOOL_CONFIG,
inferenceConfig={"maxTokens": 2048, "temperature": 0},
)
response["stopReason"] == "tool_use", the content list contains one or more toolUse blocks, each with the planned sub_query. Your loop executes the retrieval (Section 5), appends a toolResult block, and calls converse again. The model has now turned one multi-hop question into two focused searches — "durability of each storage tier" and "migration path between tiers" — and will not answer until both have returned usable context.The trade-off between the two paths is control versus simplicity. KB-native decomposition is one call and zero loop code, but opaque between sub-queries. The Converse loop is more code and more model calls, but every retrieval result passes through your hands, which is what makes grading and self-correction (Section 6) possible.
5. Retrieval and Reranking
Once the planner has a focused sub-query, retrieval runs in two stages: a recall-oriented vector search that casts a wide net, followed by a precision-oriented rerank that reorders the candidates with a cross-encoder.5.1 Retrieving candidates with the Knowledge Bases Retrieve API
TheRetrieve operation on the bedrock-agent-runtime endpoint returns ranked chunks without generating an answer, which is exactly what an agent loop needs — the agent wants the raw context so it can grade it. The key knobs live under retrievalConfiguration.vectorSearchConfiguration:import boto3
agent_rt = boto3.client("bedrock-agent-runtime", region_name="us-west-2")
resp = agent_rt.retrieve(
knowledgeBaseId="KB_ID",
retrievalQuery={"text": "durability of the standard storage tier"},
retrievalConfiguration={
"vectorSearchConfiguration": {
"numberOfResults": 20,
"overrideSearchType": "HYBRID",
"filter": {
"andAll": [
{"equals": {"key": "tenant_id", "value": "acme"}},
{"in": {"key": "doc_type", "value": ["spec", "faq"]}},
]
},
}
},
)
candidates = [
{"text": r["content"]["text"], "score": r.get("score"), "location": r["location"]}
for r in resp["retrievalResults"]
]
numberOfResultssets the maximum number of chunks returned. The default is 5; for the two-stage pattern you deliberately over-retrieve here (e.g. 20) and let the reranker cut back to a precise top-k. The maximum is governed by a Bedrock service quota — check the current value rather than hard-coding an assumption. With hierarchical chunking, this counts child chunks, and the response may return fewer items because children sharing a parent are collapsed into the parent.overrideSearchTypeselectsHYBRID(vector embeddings plus raw-text keyword search) orSEMANTIC(vector only). Hybrid is the better default when exact terms — error codes, product names, identifiers — matter. Note that hybrid search is only available on Amazon OpenSearch Serverless, Amazon RDS (Aurora PostgreSQL), and MongoDB vector stores that contain a filterable text field; on other stores the query falls back to semantic.filterapplies a metadata filter built from operators such asequals,notEquals,greaterThan,in,startsWith, and the boolean combinersandAll/orAll. This is the mechanism that enforces tenant and security boundaries (Section 9): a chunk that does not match the filter is never retrieved, so isolation is structural rather than prompt-based.
The Retrieve API can also apply reranking and metadata filtering inline (via
rerankingConfiguration and implicitFilterConfiguration inside vectorSearchConfiguration), which is convenient for the managed path. In the agentic loop we call the Rerank API explicitly so the reranked candidates and their scores are visible to the grader.5.2 Reranking with the Bedrock Rerank API
Vector similarity is a good first-pass filter but a weak final ranking: the embedding that retrieved a chunk was computed independently of the query, so the top vector hit is not necessarily the most relevant passage. A reranker is a cross-encoder that scores each candidate against the actual query, producing a far more reliable ordering. TheRerank operation, also on bedrock-agent-runtime, takes the query and the retrieved passages and returns relevance-scored indices:import boto3
agent_rt = boto3.client("bedrock-agent-runtime", region_name="us-west-2")
RERANK_MODEL_ARN = "arn:aws:bedrock:us-west-2::foundation-model/cohere.rerank-v3-5:0"
RELEVANCE_THRESHOLD = 0.5
TOP_K = 5
def rerank(query, candidates):
resp = agent_rt.rerank(
queries=[{"type": "TEXT", "textQuery": {"text": query}}],
sources=[
{
"type": "INLINE",
"inlineDocumentSource": {
"type": "TEXT",
"textDocument": {"text": c["text"]},
},
}
for c in candidates
],
rerankingConfiguration={
"type": "BEDROCK_RERANKING_MODEL",
"bedrockRerankingConfiguration": {
"modelConfiguration": {"modelArn": RERANK_MODEL_ARN},
"numberOfResults": TOP_K,
},
},
)
ranked = []
for r in resp["results"]:
if r["relevanceScore"] >= RELEVANCE_THRESHOLD:
ranked.append({**candidates[r["index"]], "relevance": r["relevanceScore"]})
return ranked
relevanceScore and the index of the candidate it refers to. Two patterns matter for self-correction. First, top-k: you asked for 20 candidates and keep the best 5. Second, the score threshold: if the best relevanceScore is below a floor you set, that is a strong, cheap signal that retrieval failed — the grader in Section 6 can treat a low top score as a trigger to re-query before you spend tokens on generation.Bedrock currently offers two reranker models: Amazon Rerank 1.0 (
amazon.rerank-v1:0) and Cohere Rerank 3.5 (cohere.rerank-v3-5:0). Regional availability differs and is the most common deployment surprise: Amazon Rerank 1.0 is not available in US East (N. Virginia), whereas Cohere Rerank 3.5 is. Confirm the model is available in your Region before wiring the ARN, and keep the ARN in configuration rather than code so a Region change is a config change.6. Retrieval Grading and the Correction Loop
This is the section that turns "RAG with a reranker" into agentic RAG. After retrieval and reranking, the agent does not generate yet. It grades the context: is this enough to answer the sub-query correctly, or not? The grade drives a decision — answer, re-query, escalate, or give up — and that decision is bounded by an explicit budget so the loop always terminates.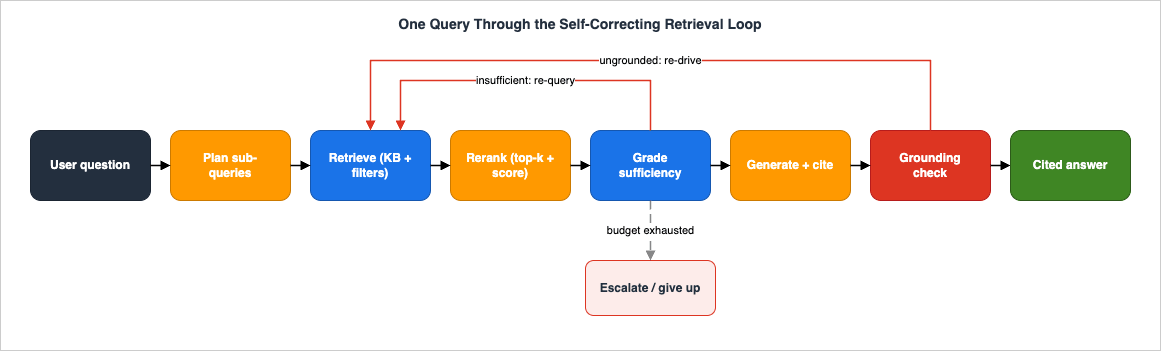
6.1 Grading retrieved context with a fast model
Grading is a small, high-volume classification task, which makes it a good fit for a fast, lower-cost model rather than the generation model. Claude Haiku 4.5 (us.anthropic.claude-haiku-4-5-20251001-v1:0) grades each candidate set against its sub-query and returns a structured verdict. Forcing the model to emit a tool call gives you a typed result instead of free text:import json
import boto3
bedrock = boto3.client("bedrock-runtime", region_name="us-west-2")
GRADER_MODEL = "us.anthropic.claude-haiku-4-5-20251001-v1:0"
GRADE_TOOL = {
"tools": [{
"toolSpec": {
"name": "record_grade",
"description": "Record the grade for the retrieved context against the sub-question.",
"inputSchema": {"json": {
"type": "object",
"properties": {
"sufficient": {"type": "boolean",
"description": "True only if the context fully answers the sub-question."},
"relevant_chunks": {"type": "integer",
"description": "How many of the provided chunks are on-topic."},
"missing": {"type": "string",
"description": "What information is still missing, or empty if sufficient."},
"reformulated_query": {"type": "string",
"description": "A better search query if not sufficient, else empty."},
},
"required": ["sufficient", "relevant_chunks", "missing"],
}},
}
}],
"toolChoice": {"tool": {"name": "record_grade"}},
}
def grade(sub_query, chunks):
context = "\n\n".join(f"[{i}] {c['text']}" for i, c in enumerate(chunks))
resp = bedrock.converse(
modelId=GRADER_MODEL,
system=[{"text": "You are a strict retrieval grader. Judge only whether the "
"provided context is sufficient to answer the sub-question. "
"Do not use outside knowledge."}],
messages=[{"role": "user", "content": [
{"text": f"Sub-question: {sub_query}\n\nRetrieved context:\n{context}"}
]}],
toolConfig=GRADE_TOOL,
inferenceConfig={"maxTokens": 512, "temperature": 0},
)
for block in resp["output"]["message"]["content"]:
if "toolUse" in block:
return block["toolUse"]["input"]
return {"sufficient": False, "relevant_chunks": 0, "missing": "no grade produced"}
reformulated_query it would try next and a description of what is missing. That feedback is what makes the correction corrective: instead of blindly retrying the same query, the loop retries a better one.6.2 The correction loop, with a budget
The loop ties planning, retrieval, reranking, and grading together — and, critically, bounds them. An ungoverned agent loop is a production hazard: it can spin indefinitely on an unanswerable question, blow the latency budget, and burn tokens. Three guards keep it safe.import time
MAX_ITERATIONS = 4
LATENCY_BUDGET_S = 12.0
MIN_TOP_RELEVANCE = 0.5
def answer_sub_query(sub_query):
deadline = time.monotonic() + LATENCY_BUDGET_S
query = sub_query
history = []
for iteration in range(MAX_ITERATIONS):
if time.monotonic() > deadline:
return {"status": "timeout", "context": best_context(history)}
candidates = retrieve(query, top_n=20) # Section 5.1
ranked = rerank(query, candidates) # Section 5.2
history.append((query, ranked))
top = ranked[0]["relevance"] if ranked else 0.0
if top < MIN_TOP_RELEVANCE:
# Cheap signal: retrieval clearly missed. Re-query before grading.
query = escalate_query(sub_query, history)
continue
verdict = grade(sub_query, ranked) # Section 6.1
if verdict["sufficient"]:
return {"status": "answered", "context": ranked}
# Corrective step: use the grader's reformulation, else escalate the source.
query = verdict.get("reformulated_query") or escalate_query(sub_query, history)
# Budget exhausted: hand back the best context we found, flagged as low-confidence.
return {"status": "exhausted", "context": best_context(history)}
- Iteration cap (
MAX_ITERATIONS). The loop runs at most a fixed number of times. This is the hard stop against infinite re-querying. - Latency budget (
LATENCY_BUDGET_S). Each iteration costs a retrieve, a rerank, and a grade. The deadline check converts an open-ended quality search into a bounded one, returning the best context found so far rather than hanging. - Escalation ladder (
escalate_query). When reformulation is not enough, the loop escalates: widen the metadata filter, switch to a different knowledge base, or — if your policy allows it and the corpus is genuinely missing the fact — fall back to a different source. The terminal rung is an honest "I could not find this," not a hallucinated answer.
The blast radius of each failure is contained at this layer. A zero-hit search returns an empty candidate list, which the
top < MIN_TOP_RELEVANCE branch catches as a re-query trigger rather than letting an empty context reach the generator. A low-relevance result is caught the same way. Loop divergence — the model reformulating into ever-worse queries — is bounded by the iteration cap and the latency budget. The state machine that governs these transitions is shown below.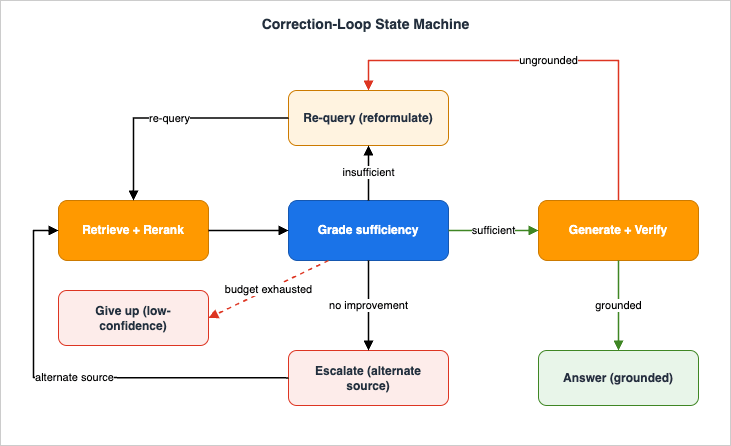
7. Generation, Grounding, and Citations
Once the loop has gathered sufficient, graded context for every sub-query, the generator composes the final answer — and then an independent check verifies that the answer is actually grounded in that context.7.1 Generation with citations
Generation is aConverse call with the assembled context and an instruction to cite. The generation model is the most capable tier — Claude Opus 4.8 (us.anthropic.claude-opus-4-8), with a 1M-token context window that comfortably holds the merged retrieved context — because answer quality is where you want to spend. A system instruction that requires the model to answer only from the provided context, and to say so when the context is insufficient, is the first (model-level) line of defense against hallucination:SYSTEM_GEN = [{
"text": (
"Answer the user's question using ONLY the provided context. Cite each claim with "
"its [chunk index]. If the context does not contain the answer, say so explicitly "
"and do not fill the gap with prior knowledge."
)
}]
resp = bedrock.converse(
modelId="us.anthropic.claude-opus-4-8",
system=SYSTEM_GEN,
messages=[{"role": "user", "content": [
{"text": f"Question: {user_question}\n\nContext:\n{numbered_context}"}
]}],
inferenceConfig={"maxTokens": 4096, "temperature": 0},
)
answer = resp["output"]["message"]["content"][0]["text"]
RetrieveAndGenerate returns a citations array that maps spans of the answer to the specific retrieved references, which is the cleanest way to render inline source links. In the agentic loop, you already hold the graded chunks, so numbering them in the prompt and asking for [index] citations keeps the source mapping under your control.7.2 Independent grounding verification with Guardrails
A system instruction reduces hallucination but does not prove grounding. The verification step is a contextual grounding check performed by Bedrock Guardrails through theApplyGuardrail API. The decisive property is that ApplyGuardrail is decoupled from model invocation: it evaluates text against a configured guardrail without calling a foundation model, so it is an independent referee rather than a self-assessment by the generator. You mark which content block is the grounding source, which is the query, and which is the response to be guarded:br = boto3.client("bedrock-runtime", region_name="us-west-2")
guard = br.apply_guardrail(
guardrailIdentifier="GUARDRAIL_ID",
guardrailVersion="DRAFT",
source="OUTPUT",
content=[
{"text": {"text": grounding_source_text, "qualifiers": ["grounding_source"]}},
{"text": {"text": user_question, "qualifiers": ["query"]}},
{"text": {"text": answer}}, # the generated response to verify
],
)
if guard["action"] == "GUARDRAIL_INTERVENED":
# Grounding or relevance below threshold: do not return the answer as-is.
# Re-query (back to Section 6), regenerate, or return a low-confidence message.
handle_ungrounded(guard["assessments"])
Guardrails does much more than grounding — denied topics, content filters, PII detection via sensitive-information policies, and word filters — and those policy types, along with the broader responsible-AI architecture, are the subject of a dedicated article in this series, Responsible-AI Guardrails Architecture on AWS. Here we use only the grounding check, as the loop's final gate.
8. Evaluation and Quality Loops
A self-correcting loop is only trustworthy if you can measure whether it is actually improving answers, and catch the prompt or model change that quietly makes them worse. Bedrock provides a managed evaluation surface, and the loop emits online signals you should treat as first-class metrics.8.1 Offline evaluation with Bedrock RAG evaluations
Amazon Bedrock evaluations can evaluate a knowledge base (or any RAG source) using a judge model — an LLM-as-a-judge that scores retrieval and generation against a dataset of prompts and ground-truth answers. You can run a retrieval-only evaluation (does the knowledge base surface the right passages?) or a retrieval-with-response-generation evaluation (are the generated answers correct and grounded?), and you can mix built-in metrics with custom ones. The built-in metrics include context relevance, correctness, completeness, faithfulness, and harmfulness; scores fall on a 0–1 scale, where higher means more of that quality is present.The evaluation is created as a job (via the console or the
bedrock control-plane API) that points at an evaluator model, the RAG source, and an S3 prompt dataset containing ground-truth retrievals and answers. Treat this as a regression gate: keep a curated, version-controlled set of representative and adversarial questions, run the evaluation on every change to the planner prompt, the reranker threshold, the grader, or the generation model, and block the change if a metric regresses. The full LLMOps treatment — wiring this into a pipeline as an automated gate — is the subject of LLMOps Observability and Evaluation Architecture on AWS, and the AgentCore-native built-in evaluators are covered in Amazon Bedrock AgentCore Evaluations Practical Guide.8.2 Online quality signals from the loop
The loop already produces the signals you need to monitor in production, for free. Emit them as metrics:- Grade outcomes — the fraction of sub-queries graded
sufficienton the first iteration versus after re-query. A falling first-pass rate means retrieval quality is drifting. - Loop iterations per question — rising iteration counts indicate the corpus is missing content or the embeddings have drifted from the query distribution.
- Top relevance score — the reranker's best score per query; a downward trend is an early warning before users notice.
- Grounding interventions — the rate at which
ApplyGuardrailrejects a generated answer. A spike points at either a retrieval regression or a generation-prompt change.
These four metrics, plotted together, are a compact health dashboard for the whole loop. Section 10 covers where they live and how to alarm on them.
9. Cross-Cutting: IAM, Data Boundaries, Memory, and Caching
The components above are only safe and operable in production if four cross-cutting concerns are handled deliberately.9.1 Least-privilege IAM per component
Each call in the loop hits a distinct Bedrock API, and the agent's execution role should grant only those actions, scoped to specific resource ARNs. A representative policy for the loop's runtime role:{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Retrieve",
"Effect": "Allow",
"Action": ["bedrock:Retrieve", "bedrock:RetrieveAndGenerate"],
"Resource": "arn:aws:bedrock:us-west-2:ACCOUNT_ID:knowledge-base/KB_ID"
},
{
"Sid": "Rerank",
"Effect": "Allow",
"Action": "bedrock:Rerank",
"Resource": "arn:aws:bedrock:us-west-2::foundation-model/cohere.rerank-v3-5:0"
},
{
"Sid": "InvokeModels",
"Effect": "Allow",
"Action": ["bedrock:InvokeModel", "bedrock:Converse"],
"Resource": [
"arn:aws:bedrock:us-west-2:ACCOUNT_ID:inference-profile/us.anthropic.claude-opus-4-8",
"arn:aws:bedrock:us-west-2:ACCOUNT_ID:inference-profile/us.anthropic.claude-haiku-4-5-20251001-v1:0",
"arn:aws:bedrock:*::foundation-model/anthropic.claude-opus-4-8",
"arn:aws:bedrock:*::foundation-model/anthropic.claude-haiku-4-5-20251001-v1:0"
]
},
{
"Sid": "Guardrail",
"Effect": "Allow",
"Action": "bedrock:ApplyGuardrail",
"Resource": "arn:aws:bedrock:us-west-2:ACCOUNT_ID:guardrail/GUARDRAIL_ID"
}
]
}
Resource: "*" — so a compromised loop cannot reach knowledge bases, models, or guardrails it was never meant to touch.9.2 Data boundaries through metadata filters
In a multi-tenant or security-tiered corpus, isolation must be structural, not a polite request in a prompt. The mechanism is metadata filtering (Section 5.1): each ingested chunk carries a.metadata.json sidecar with attributes such as tenant_id or classification, and every Retrieve call includes a filter that constrains results to the caller's allowed values. Because the filter is applied inside the vector search, a chunk the caller is not entitled to is never retrieved and therefore can never reach the model — the boundary holds even under prompt injection, because there is nothing in context to leak. Derive the filter from the caller's authenticated identity, never from anything the model produced.9.3 Memory, caching, and idempotency
Conversational memory — remembering what "it" referred to two turns ago — belongs to AgentCore Memory, not to the retrieval loop; its design is covered in AI Agent Memory Design Guide. For the loop itself, three operational habits matter. Cache at the boundaries: identical sub-queries within a session can reuse retrieval and rerank results, and repeated agent system prompts benefit from prompt caching. Idempotency: key each retrieval and generation on the sub-query (and tenant) so a retried loop iteration after a transient error does not double-count toward the budget or produce divergent context. And latency budgeting (Section 6.2) is itself a cross-cutting concern — the per-iteration cost compounds, so the budget must be set against the end-to-end user-facing deadline, not per call.10. Observability and Failure Modes
You cannot operate what you cannot see, and a multi-service loop fails in ways a single metric cannot explain. The AWS Well-Architected Agentic AI Lens (best practice AGENTREL08-BP02) makes the point precisely: a single latency number at the request boundary cannot tell you whether slowness came from retrieval, inference, the reranker, or grounding — you need stage-level telemetry.10.1 Instrumenting the loop
Three layers of signal cover the architecture:- AgentCore Observability. Agents hosted on AgentCore Runtime automatically emit OpenTelemetry-compatible traces, spans, and metrics to Amazon CloudWatch, viewable in the CloudWatch GenAI Observability console (Agents, Sessions, and Traces views). Built-in metrics include session count, latency, duration, token usage, and error rates; agent runtime logs land in log groups under
/aws/bedrock-agentcore/runtimes/, and the metrics namespace isbedrock-agentcore. Viewing traces requires a one-time enablement of CloudWatch Transaction Search. You can also instrument your own spans for the retrieve / rerank / grade / generate stages so each shows up as a timed segment in the trace. - Bedrock model invocation logging. Enable it to capture full request and response data for every model call — token counts, latency, and finish reason — to CloudWatch Logs and/or Amazon S3. A shift in the finish-reason distribution or a spike in output tokens often precedes a visible quality regression, and without the logs that early signal is invisible.
aws bedrock put-model-invocation-logging-configuration \
--logging-config '{
"cloudWatchConfig": {
"logGroupName": "/aws/bedrock/modelinvocations",
"roleArn": "arn:aws:iam::ACCOUNT_ID:role/BedrockLoggingRole"
},
"textDataDeliveryEnabled": true
}'
- The loop's own metrics. The four online signals from Section 8.2 — first-pass grade rate, iterations per question, top relevance, and grounding-intervention rate — published to CloudWatch with CloudWatch Anomaly Detection on each, and composite alarms that fire when several degrade together, give operators a baseline that adapts without hand-tuned thresholds.
10.2 Failure modes and how to isolate them
* You can sort the table by clicking on the column name.| Symptom | Likely root cause | How to isolate | Containment / remediation |
|---|---|---|---|
| Empty answers / "not found" spike | Zero-hit retrieval | Top relevance near 0 in metrics; empty retrievalResults | Re-query branch already catches it; check data-source sync and the metadata filter |
| Confidently wrong answers | Low-relevance context reaching generation | Grade rate falling, grounding interventions rising | Raise the rerank RELEVANCE_THRESHOLD; tighten the grader prompt |
| Hallucinated claims | Generation outran its context | ApplyGuardrail grounding score below threshold | Loop back on intervention; do not ship a caveat |
| Slow responses | Loop divergence / too many iterations | Iterations-per-question trending up | Lower MAX_ITERATIONS; verify the latency-budget deadline fires |
| Legitimate answers blocked | Guardrail over-blocking | High intervention rate with high grade rate | Re-tune grounding/relevance thresholds; review denied topics |
| Stale or missing facts | Knowledge base sync failure | Ingestion job status; document counts | Re-run the data-source sync; alarm on ingestion-job failures |
| Region/ARN errors at call time | Reranker or model not in the call Region | ValidationException / AccessDenied on rerank or converse | Move the ARN to config; confirm model availability in the Region |
The pattern across every row is the same: because each stage is independently instrumented and independently graded, a failure surfaces at the stage that caused it, not as an undifferentiated "the agent gave a bad answer." That is the operational payoff of the loop architecture.
11. Variations: Hybrid Search, GraphRAG, and Multimodal
The loop above is the vector-RAG backbone, but the same control structure adapts to three common variations, each of which has its own dedicated treatment in this series.- Hybrid and tiered retrieval. Hybrid search (vector plus keyword) is a per-call setting (
overrideSearchType: HYBRID, Section 5.1) on the stores that support it. At the storage layer, Amazon S3 Vectors — generally available since 2025 and natively integrated with Knowledge Bases — gives a durable, large-scale, cost-optimized vector store for infrequently queried corpora, and pairs well with Amazon OpenSearch Serverless for hot queries in a tiered design. The choice is about query latency and access pattern, expressed qualitatively here; see the official pricing pages for the economics. - GraphRAG. When the answer depends on relationships between entities rather than passage similarity, a knowledge graph beats pure vector search. Bedrock Knowledge Bases supports GraphRAG with Amazon Neptune Analytics, and multi-hop retrieval over a graph is the focus of GraphRAG Architecture on AWS. The correction loop is unchanged; only the retriever component swaps.
- Multimodal corpora. When the source documents are PDFs with tables, images, audio, or video, the ingestion side — parsing and structuring non-text content before it becomes retrievable — is the hard part, and it is covered in this series' multimodal document intelligence pipeline article. Once the content is in the knowledge base, the loop in this article applies as-is.
12. Frequently Asked Questions
Is agentic RAG always better than static RAG?No. Static RAG is cheaper, faster, and simpler, and it is the right default for well-formed factual questions. Add the loop only when the question shape (ambiguous, multi-hop, multi-source) or a measured quality gap justifies it. Over-engineering RAG into an agent loop for questions a single
RetrieveAndGenerate would answer adds latency and cost for no benefit.Do I need AgentCore Runtime, or can I run the loop in Lambda?
The loop logic is just code and runs anywhere. AgentCore Runtime is valuable when you want serverless per-session isolation, execution windows longer than Lambda's 15-minute limit, built-in OpenTelemetry observability, and identity-aware tool access without building that scaffolding yourself. For a short, single-turn loop, Lambda is fine; for long-running or multi-agent retrieval, AgentCore Runtime earns its place.
Should I use the Rerank API or the Knowledge Bases inline reranking configuration?
Both call the same reranker models. Inline reranking (inside the
Retrieve request) is simpler when you do not need to inspect the scores. The standalone Rerank API is preferable in the agentic loop because the per-candidate relevanceScore becomes a first-class signal the grader and loop controller can branch on.How is the contextual grounding check different from prompting the model to "only use the context"?
The prompt is a model-level instruction the generator can still violate. The grounding check runs through
ApplyGuardrail, which is decoupled from the generator and evaluates the answer against the source independently, producing grounding and relevance scores. It is a referee, not a self-report, which is why it can serve as the loop's final gate.Which model should grade, and which should generate?
Use a fast, lower-cost model for grading (a high-volume, narrow classification task) — Claude Haiku 4.5 fits — and the most capable model for the final answer, where quality matters most (Claude Opus 4.8). Splitting the roles keeps the loop affordable without compromising the user-facing answer. Verify current model availability and IDs before deploying.
How do I keep tenants from seeing each other's documents?
Enforce isolation with metadata filters on every
Retrieve call, derived from the caller's authenticated identity, so disallowed chunks are never retrieved (Section 9.2). Do not rely on the prompt to keep data separated — a chunk that reaches the model can leak.13. Summary
Static RAG answers the easy questions; the value of an agentic architecture is in handling the questions where a single retrieval fails. The Self-Correcting Retrieval Loop on Amazon Bedrock makes that handling explicit and operable: aConverse tool-use loop on AgentCore Runtime plans focused sub-queries, Knowledge Bases Retrieve casts a wide net with metadata filters that double as tenant boundaries, the Rerank API sharpens the ranking and exposes a relevance score, a fast model grades sufficiency, a bounded loop controller decides to answer or re-query within a strict iteration and latency budget, Opus 4.8 generates with citations, and Guardrails' contextual grounding check independently verifies the answer before it ships. Bedrock evaluations and stage-level observability close the loop so quality is measured, not assumed.The architectural through-line is that every stage is independently invoked, independently graded, and independently instrumented. That is what lets the system self-correct instead of failing silently, and what lets an operator pinpoint which stage failed instead of guessing. Build the static floor first, add the loop only where the question shape demands it, bound every loop with a budget, and verify grounding with an independent referee — and you have a RAG system you can trust in production. The companion articles in this series — GraphRAG for relationship-heavy retrieval, multimodal ingestion for non-text corpora, responsible-AI Guardrails, and the LLMOps evaluation pipeline — extend each of these stages in depth.
14. References
- Amazon Bedrock Knowledge Bases - Configure and customize queries and response generation
- Amazon Bedrock - Use a reranker model
- Amazon Bedrock - Supported Regions and models for reranking
- Amazon Bedrock Guardrails - Use the ApplyGuardrail API
- Amazon Bedrock Guardrails - Use contextual grounding check to filter hallucinations
- Host agent or tools with Amazon Bedrock AgentCore Runtime
- Observe your agent applications on Amazon Bedrock AgentCore Observability
- Evaluate the performance of Amazon Bedrock resources
- Review metrics for RAG evaluations that use LLMs
- AWS Well-Architected Agentic AI Lens - AGENTREL08-BP02 (agent tracing for telemetry)
- Supported models and Regions for Amazon Bedrock knowledge bases
- Using Amazon S3 Vectors with Amazon Bedrock Knowledge Bases
- Amazon Bedrock Converse API reference
- Service Authorization Reference - Actions for Amazon Bedrock
- Amazon Bedrock pricing
Related Articles in This Series
- Amazon Bedrock RAG Architecture Guide
The static-RAG floor this article builds on (ingestion, chunking, vector stores). - Amazon Bedrock AgentCore Implementation Guide Part 1: Foundation
The agent-hosting layer: Runtime, Memory, and Code Interpreter patterns. - Amazon Bedrock AgentCore Evaluations Practical Guide
Built-in evaluators for agents. - AI Agent Memory Design Guide
Conversational memory for agents. - Amazon Bedrock Glossary
Terminology reference.
References:
Tech Blog with curated related content
Written by Hidekazu Konishi