Production RAG Architecture on Amazon Bedrock - Knowledge Bases, Vector Stores, Retrieval, Guardrails, and Evaluation
First Published:
Last Updated:
RetrieveAndGenerate call and a screenshot of a grounded answer. Production RAG is a different problem. The hard part is not invoking a model; it is operating the loop that surrounds the model: ingesting documents reliably, chunking and embedding them so retrieval actually finds the right passage, generating answers that cite their sources, blocking ungrounded or unsafe output, and measuring retrieval and answer quality so you can tell whether a change made things better or worse.This guide builds one named reference architecture end to end on Amazon Bedrock and follows a single user question all the way through it. It is deliberately an implementation walkthrough, not a service tour. Where a decision is really a "which option do I pick" question — which vector store, how to defend against prompt injection — it is compressed into one section and delegated to an existing decision guide, so this article can stay focused on wiring the pieces together, the failure modes that cut across them, and how you observe and evaluate the whole system.
Throughout, AWS service facts (Knowledge Bases, vector stores, Guardrails, evaluation) were checked against the AWS documentation, and the generative-model details were checked against the Anthropic documentation. There are no prices in this article by design — cost characteristics are discussed qualitatively and every pricing question is a link to the official pricing pages.
1. Introduction
A useful way to frame production RAG is to separate the build-time path from the request-time path. At build time you take raw documents from a source, split them into chunks, turn each chunk into a vector with an embedding model, and write those vectors plus the original text and metadata into a vector store. At request time a user question is embedded with the same model, the vector store returns the nearest chunks, those chunks are stitched into a prompt, a foundation model generates an answer with citations, and a guardrail inspects the input and the output before the answer reaches the user. Wrapped around both paths is an evaluation loop that scores retrieval and generation quality and tells you when to re-chunk, swap an embedding model, or tighten a guardrail.Amazon Bedrock Knowledge Bases is the managed building block that handles most of the build-time path and a large part of the request-time path for you. It connects a foundation model to your private data, runs the ingestion workflow (parsing, chunking, embedding, and writing to a vector store), and exposes the
Retrieve and RetrieveAndGenerate operations for querying. You still own the surrounding architecture: where the source data lives, the application tier that calls the APIs, the guardrail policy, the IAM boundaries, the observability, and the evaluation cadence. That surrounding architecture is what this article implements.This is intentionally not a duplicate of the official RAG quickstart or of a vector-database comparison. The differentiators here are a single concrete walkthrough with an architecture diagram and a query-flow diagram, the cross-component failure modes and how to contain them, the cross-cutting concerns (least-privilege IAM, tenant and data boundaries, idempotent sync, caching), and the evaluation loop that keeps the system honest over time. Deep selection of a vector store is delegated to Amazon S3 Vectors Design Decision Guide, prompt-injection defense to AWS WAF Generative AI Prompt Injection Patterns, and the Bedrock fundamentals to Amazon Bedrock Basic Information and API Examples.
2. The Reference Architecture at a Glance
The architecture this article implements is a single named system: a knowledge assistant that answers questions over a corporate document corpus. Documents land in Amazon S3 (the same lake you might build in a data lakehouse). A Bedrock Knowledge Base ingests them — parsing, chunking, embedding — and writes vectors to a vector store. An application tier (Amazon API Gateway in front of AWS Lambda) accepts user questions, calls the Knowledge Base, applies a Bedrock Guardrail, and returns a cited answer. A separate evaluation pipeline periodically scores retrieval and generation quality.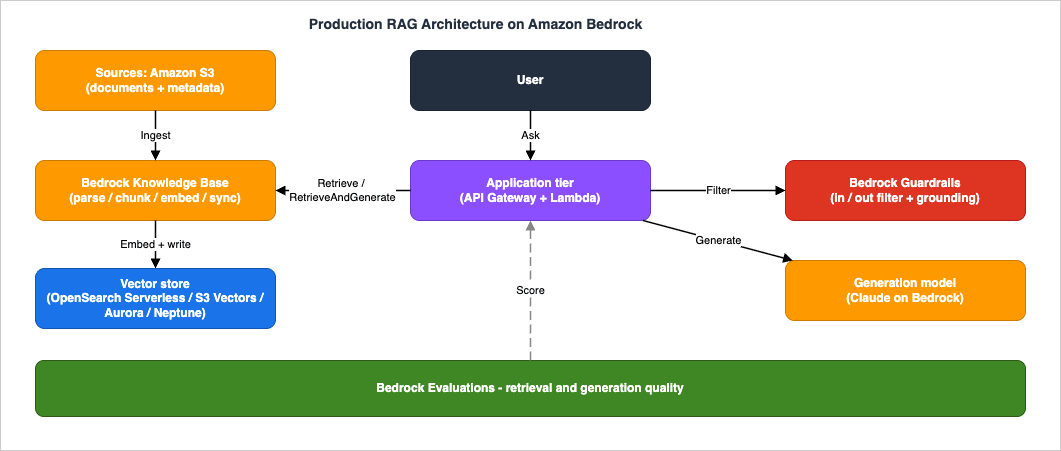
- Amazon S3 (source) holds the raw documents and their sidecar metadata files. If you have a governed lakehouse, this is where it connects to RAG; see the upcoming AWS Data Lakehouse Architecture Guide for the source side.
- Bedrock Knowledge Base owns ingestion: it parses each document, splits it into chunks, embeds the chunks with your chosen embedding model, and writes the vectors and text to the vector store. It also serves
RetrieveandRetrieveAndGenerate. - Vector store holds the embeddings and supports nearest-neighbor search. Knowledge Bases supports several stores; the choice is a decision guide topic in its own right (Section 4).
- Application tier (API Gateway + Lambda) is your code. It authenticates the caller, attaches tenant/metadata filters, calls the Knowledge Base, enforces a guardrail, and shapes the cited response. The serverless plumbing patterns here are the subject of the Event-Driven Serverless Architecture on AWS guide.
- Bedrock Guardrails inspect the user input and the generated output and can block denied topics, redact PII, and filter ungrounded responses.
- Bedrock Evaluations scores the system on a schedule so quality changes are visible.
Two orchestration choices matter up front. First, you can let
RetrieveAndGenerate perform the whole RAG flow in one call, or you can call Retrieve yourself and keep full control of prompt construction and generation. Production systems usually start with RetrieveAndGenerate and move specific paths to Retrieve when they need custom prompting, custom post-processing, or to route different questions to different models. Second, ingestion is asynchronous and idempotent: you trigger a sync, Bedrock reconciles the data source against the vector store, and only changed documents are re-processed. Keeping these two facts in mind — decoupled retrieval and asynchronous sync — explains most of the design decisions below.3. The Ingestion Pipeline: Chunking and Embeddings
Retrieval quality is decided at ingestion time. If a chunk is too large, the embedding blurs several ideas together and the nearest-neighbor search returns something vaguely related; if it is too small, the answer to a question gets split across chunks and no single passage scores high enough. The ingestion pipeline is where you make these trade-offs concrete.3.1 Data sources and parsing
A Knowledge Base data source points at unstructured content — most commonly an S3 prefix — and Bedrock walks it on each sync. For documents that are mostly clean text, the default parser is sufficient. For documents with nested tables, images, and graphs, Knowledge Bases supports advanced parsing that uses a foundation model to extract structure that a naive text extraction would lose. The current parser options include the Amazon Bedrock Data Automation parser and foundation-model parsers from the Claude, Nova, and Llama vision families; check the supported-models page for current Region and model availability before you commit, because this list moves quickly.Parsing choice has downstream consequences: FM-based parsing produces cleaner, more faithful chunks for complex layouts but adds model invocations to every ingestion run. Treat it as a quality lever you turn on for the document types that need it, not a global default.
3.2 Chunking strategy
Bedrock Knowledge Bases supports four chunking strategies, configured on the data source:- Fixed-size splits text into approximately fixed token counts with a configurable overlap. It is predictable and a good baseline.
- Hierarchical creates layered chunks — larger parent chunks and smaller child chunks — so retrieval can match on a precise child while returning the broader parent for context.
- Semantic splits on natural-language boundaries so that semantically related sentences stay together rather than being cut at an arbitrary token count.
- None treats each file as a single chunk; you use it when you have already pre-processed documents into one-chunk-per-file units.
The following table summarizes how to think about the choice.
| Strategy | What it does | When it fits |
|---|---|---|
| Fixed-size | Approx. fixed tokens with overlap | Baseline; uniform prose; predictable cost |
| Hierarchical | Parent/child layered chunks | Long structured docs where you want precise match plus surrounding context |
| Semantic | Splits on content similarity | Mixed content where token-boundary cuts hurt meaning |
| None | One chunk per file | Pre-chunked content; you control splitting upstream |
A data source declares its chunking strategy in infrastructure as code. The CloudFormation fragment below defines an S3 data source on an existing Knowledge Base using hierarchical chunking. The
ChunkingStrategy property is required; the per-strategy configuration object is optional and supplies the level sizes and overlap.Resources:
KbDataSource:
Type: AWS::Bedrock::DataSource
Properties:
KnowledgeBaseId: !Ref KnowledgeBaseId
Name: corp-docs
DataSourceConfiguration:
Type: S3
S3Configuration:
BucketArn: !Sub arn:aws:s3:::${SourceBucket}
InclusionPrefixes:
- documents/
VectorIngestionConfiguration:
ChunkingConfiguration:
ChunkingStrategy: HIERARCHICAL
HierarchicalChunkingConfiguration:
LevelConfigurations:
- MaxTokens: 1500 # parent
- MaxTokens: 300 # child
OverlapTokens: 60
3.3 Choosing an embedding model
The embedding model converts each chunk into a vector. Knowledge Bases supports several embedding models, and the choice constrains your vector dimensions and, in turn, your vector store options. The current text-embedding lineup is:| Model | Model ID | Vector type | Dimensions |
|---|---|---|---|
| Amazon Titan Embeddings G1 - Text | amazon.titan-embed-text-v1 | Floating-point | 1536 |
| Amazon Titan Text Embeddings V2 | amazon.titan-embed-text-v2:0 | Floating-point, binary | 256, 512, 1024 |
| Cohere Embed English | cohere.embed-english-v3 | Floating-point, binary | 1024 |
| Cohere Embed Multilingual | cohere.embed-multilingual-v3 | Floating-point, binary | 1024 |
Amazon Titan Text Embeddings V2 is the common default for new text RAG systems: it supports configurable output dimensions (256, 512, or 1024) and both floating-point and binary vector types, which gives you a storage/accuracy dial. Smaller dimensions cut index size and query cost at a modest accuracy cost; binary vectors cut storage further but are only supported on some vector stores (see Section 4). For multilingual corpora, Cohere Embed Multilingual or Titan V2 (trained on 100+ languages) are the natural picks. Multimodal embedding models exist as well for image-bearing corpora.
Two rules keep you out of trouble. First, the embedding model is part of your index: changing it means re-embedding and re-indexing the entire corpus, so choose deliberately. Second, embedding the query at request time must use the same model that embedded the chunks — Knowledge Bases handles this for you, which is one more reason to let it own the embedding step rather than rolling your own.
3.4 Synchronization and incremental updates
Ingestion runs as a job. You start it withStartIngestionJob; Bedrock parses, chunks, embeds, and writes to the vector store, and reports per-document statistics. The important production property is that sync is incremental and idempotent: Bedrock reconciles the data source against what is already indexed, so a re-run only processes new, changed, and deleted documents. That makes it safe to trigger a sync on a schedule or from an S3 event without worrying about duplicating content.import boto3
agent = boto3.client("bedrock-agent")
resp = agent.start_ingestion_job(
knowledgeBaseId="KB123456",
dataSourceId="DS123456",
description="nightly sync",
)
job = resp["ingestionJob"]
print(job["status"]) # STARTING -> IN_PROGRESS -> COMPLETE | FAILED
# Poll for terminal state, then inspect statistics
stats = agent.get_ingestion_job(
knowledgeBaseId="KB123456",
dataSourceId="DS123456",
ingestionJobId=job["ingestionJobId"],
)["ingestionJob"]["statistics"]
print(stats) # documentsScanned / Indexed / Failed / Deleted ...
StartIngestionJob accepts a client token for idempotency so a retried trigger does not start a duplicate job, and Bedrock enforces a service quota on concurrent ingestion jobs, so coalesce bursts of events into a single sync rather than launching overlapping jobs for the same data source.3.5 Metadata for filtering
Retrieval gets dramatically more precise when you attach metadata to documents and filter on it at query time. In a Knowledge Base, you attach a sidecar metadata file (JSON) alongside each source document, with attributes typed as string, number, or Boolean — for exampletenant_id, department, effective_date, or classification. At query time you pass a filter so the nearest-neighbor search only considers chunks whose metadata matches. This is the mechanism behind multi-tenant isolation (Section 8) and behind "only search the current product version" style narrowing. Plan your metadata schema during ingestion design, not after — adding a filterable attribute later means re-syncing so the attribute is indexed on every chunk.4. Vector Stores and Retrieval
With chunks embedded and stored, retrieval is the act of finding the nearest vectors to the query vector and returning their source text. This section covers the store choice (briefly, then delegated) and the retrieval APIs (in depth).4.1 Choosing a vector store (compressed, then delegated)
Bedrock Knowledge Bases can write to several vector stores. TheStorageConfiguration object currently supports eight types: Amazon OpenSearch Serverless, Amazon OpenSearch Managed Cluster, Amazon Aurora (RDS PostgreSQL with pgvector), Amazon Neptune Analytics (for GraphRAG), Amazon S3 Vectors, Pinecone, Redis Enterprise Cloud, and MongoDB Atlas. Knowledge Bases can create and manage the vector index for you on the supported AWS stores, or you can pre-create one yourself.A one-line orientation rather than a full comparison:
| Store | Orientation |
|---|---|
| OpenSearch Serverless | Default managed AWS vector store; supports binary vectors; broad feature set |
| OpenSearch Managed Cluster | When you need cluster-level tuning and cost/performance control |
| Aurora PostgreSQL (pgvector) | When you already run Postgres and want vectors next to relational data |
| Neptune Analytics | GraphRAG — combine a knowledge graph with vector search |
| Amazon S3 Vectors | Cost-optimized, large-scale vector storage for AI workloads |
The deep selection — latency profiles, scale ceilings, binary-vector support, operational model, and when S3 Vectors versus OpenSearch Serverless is right — is its own decision and is covered in Amazon S3 Vectors Design Decision Guide. The rest of this section treats the store as a black box behind the retrieval APIs. Note one cross-constraint from Section 3: only OpenSearch Serverless and OpenSearch Managed clusters support binary vector embeddings, so a binary-vector storage decision and an embedding-dimension decision are linked.
The storage choice is declared when you create the Knowledge Base. The CLI call below creates a Knowledge Base backed by OpenSearch Serverless, with Titan Text Embeddings V2 as the embedding model. The field-mapping object tells Bedrock which index fields hold the vector, the chunk text, and the metadata.
aws bedrock-agent create-knowledge-base \
--name corp-knowledge-assistant \
--role-arn "arn:aws:iam::111122223333:role/BedrockKBRole" \
--knowledge-base-configuration '{
"type": "VECTOR",
"vectorKnowledgeBaseConfiguration": {
"embeddingModelArn": "arn:aws:bedrock:us-east-1::foundation-model/amazon.titan-embed-text-v2:0"
}
}' \
--storage-configuration '{
"type": "OPENSEARCH_SERVERLESS",
"opensearchServerlessConfiguration": {
"collectionArn": "arn:aws:aoss:us-east-1:111122223333:collection/abcd1234",
"vectorIndexName": "corp-docs-index",
"fieldMapping": {
"vectorField": "bedrock-knowledge-base-default-vector",
"textField": "AMAZON_BEDROCK_TEXT_CHUNK",
"metadataField": "AMAZON_BEDROCK_METADATA"
}
}
}'
4.2 Retrieve vs RetrieveAndGenerate
Knowledge Bases exposes three query operations, and choosing among them is the central request-time design decision:Retrievereturns the source chunks (and images, if present) most relevant to the query, as an array. It performs retrieval only — no generation. You own the prompt and the model call afterward.RetrieveAndGeneratejoinsRetrievewith model invocation: it retrieves the relevant chunks and generates a natural-language answer with citations to the specific source chunks. It is the whole RAG flow in one call.GenerateQueryconverts a natural-language question into a query suitable for a structured data store (natural language to SQL). It is used under the hood byRetrieveAndGeneratewhen the Knowledge Base is connected to a structured store, and you can call it directly.
Because
Retrieve is exposed separately, you can decouple the RAG steps and customize them. The decision rule:- Use
RetrieveAndGeneratewhen the managed prompt and citation handling fit your use case. It is less code, and citations come back structured. - Use
Retrievewhen you need custom prompt construction, want to inject the chunks into a multi-step agent, need to post-process or re-rank with your own logic, or want to route different question types to different models.
A minimal
RetrieveAndGenerate call, with a metadata filter that restricts retrieval to one tenant and one department:import boto3
rt = boto3.client("bedrock-agent-runtime")
resp = rt.retrieve_and_generate(
input={"text": "What is our data retention period for audit logs?"},
retrieveAndGenerateConfiguration={
"type": "KNOWLEDGE_BASE",
"knowledgeBaseConfiguration": {
"knowledgeBaseId": "KB123456",
"modelArn": (
"arn:aws:bedrock:us-east-1:111122223333:"
"inference-profile/us.anthropic.claude-opus-4-8"
),
"retrievalConfiguration": {
"vectorSearchConfiguration": {
"numberOfResults": 8,
"filter": {
"andAll": [
{"equals": {"key": "tenant_id", "value": "acme"}},
{"equals": {"key": "department", "value": "security"}}
]
}
}
}
}
}
)
print(resp["output"]["text"])
for c in resp.get("citations", []):
for ref in c.get("retrievedReferences", []):
print(ref["location"], ref["metadata"].get("source_uri"))
Retrieve call that hands you the chunks so you can build the prompt yourself:hits = rt.retrieve(
knowledgeBaseId="KB123456",
retrievalQuery={"text": "data retention period for audit logs"},
retrievalConfiguration={
"vectorSearchConfiguration": {
"numberOfResults": 8,
"filter": {"equals": {"key": "tenant_id", "value": "acme"}}
}
}
)
chunks = [h["content"]["text"] for h in hits["retrievalResults"]]
# ... build your own prompt from `chunks`, then call the model directly.
4.3 Hybrid search and reranking
Pure vector (semantic) search can miss exact-keyword matches — product codes, error strings, acronyms. Knowledge Bases supports hybrid search that combines semantic and keyword matching where the vector store supports it; you select the search type in thevectorSearchConfiguration. On top of either search type, you can attach an optional reranking model to Retrieve or RetrieveAndGenerate to reorder the retrieved documents by relevance before they reach the generation step. Reranking trades a little extra latency and cost for better ordering, which matters most when you retrieve a wide set and want the best few at the top; consult the Bedrock reranking documentation for the current model and Region list. The practical pattern is: retrieve a generous numberOfResults, rerank, then let generation see only the top-ranked chunks.5. Generation, Prompting, and Citations
Generation turns retrieved chunks into an answer. WithRetrieveAndGenerate, Bedrock builds the prompt, calls the model, and returns the answer with citations; you control the model, the prompt template, and the inference settings.5.1 Model selection
On Amazon Bedrock, Anthropic Claude models are addressed with ananthropic. provider prefix, and newer models are typically invoked through a cross-Region inference profile (for example us.anthropic.claude-opus-4-8) rather than a bare foundation-model ID. The current Claude lineup, verified against the Anthropic documentation, is Claude Opus 4.8 (most capable; anthropic.claude-opus-4-8), Claude Sonnet 4.6 (anthropic.claude-sonnet-4-6), and Claude Haiku 4.5 (anthropic.claude-haiku-4-5). Bedrock also offers Amazon Nova, Meta Llama, and Mistral families as generation models.Pick the generation model per path, not globally. A high-stakes, low-volume answer path benefits from the most capable model; a high-volume, latency-sensitive path can use a faster model and lean harder on retrieval quality and reranking. Because
RetrieveAndGenerate takes the model ARN as a parameter, routing different question classes to different models is a configuration choice, not a re-architecture. This article does not quote model prices; see the official Amazon Bedrock pricing page for current rates and the Anthropic model documentation for capability details.5.2 Prompt construction and grounding
The generation prompt has one job: instruct the model to answer only from the retrieved context and to say so when the context does not contain the answer.RetrieveAndGenerate exposes a prompt template you can override; the template includes a placeholder for the retrieved passages and the user query. A grounding-first template looks like this in spirit:You are a knowledge assistant. Answer the user's question using ONLY the
search results provided below. If the search results do not contain the
answer, say you don't have enough information - do not use prior knowledge
and do not guess. Cite the sources you used.
Search results:
$search_results$
User question: $query$
5.3 Citations
RetrieveAndGenerate returns citations that map spans of the generated answer back to the specific retrieved chunks, including the source location and the chunk metadata. Surface these in your application — a knowledge assistant that links each claim to its source document is both more trustworthy and far easier to debug, because when an answer is wrong you can immediately see which chunk misled the model. If you use the decoupled Retrieve path, you are responsible for constructing citations from the returned location and metadata fields yourself; preserve a stable source_uri in your metadata so citations resolve to something a user can open.6. Guardrails and Safety
Amazon Bedrock Guardrails provide configurable filters on the input and the output of a generative AI application. In a RAG system they do two distinct jobs: keep unsafe or out-of-scope content out, and catch ungrounded answers that prompting alone did not prevent.6.1 The guardrail filters
A guardrail is composed of filters, and it must contain at least one. The current filter set is:- Content filters — detect and filter harmful text or image content across categories (Hate, Insults, Sexual, Violence, Misconduct) with configurable strength per category.
- Prompt attacks — a category within content filters that detects jailbreaks, prompt injections, and prompt leakage (in the Standard tier). This is one layer of prompt-injection defense; the broader pattern is delegated below.
- Denied topics — topics you define in natural language that the application should refuse to engage.
- Word filters — exact-match custom words and phrases (and a ready-made profanity list).
- Sensitive information filters — detect and block or mask PII (and custom regex entities) in inputs and responses.
- Contextual grounding checks — detect and filter hallucinations by checking whether the response is grounded in the source and relevant to the query.
- Automated reasoning checks — validate that responses comply with logical rules and policies you define in natural language.
6.2 Contextual grounding for RAG
The contextual grounding check is the filter that earns its keep in RAG. It scores a response on two dimensions — grounding (is the answer factually supported by the source passages?) and relevance (does the answer address the user's question?) — and blocks responses that fall below a confidence threshold you set (the threshold range is 0 to 0.99). Raising the threshold filters more aggressively (fewer ungrounded answers, more false blocks); lowering it is more permissive. Tune it against your evaluation set (Section 7) rather than guessing, and re-tune when you change chunking, the embedding model, or the generation model, because all three shift the grounding distribution.A guardrail with a contextual grounding policy, created from the CLI:
aws bedrock create-guardrail \
--name corp-rag-guardrail \
--blocked-input-messaging "I can't help with that request." \
--blocked-outputs-messaging "I don't have enough grounded information to answer that." \
--contextual-grounding-policy-config '{
"filtersConfig": [
{"type": "GROUNDING", "threshold": 0.75},
{"type": "RELEVANCE", "threshold": 0.5}
]
}' \
--sensitive-information-policy-config '{
"piiEntitiesConfig": [
{"type": "EMAIL", "action": "ANONYMIZE"},
{"type": "CREDIT_DEBIT_CARD_NUMBER", "action": "BLOCK"}
]
}'
RetrieveAndGenerate through the generation configuration, so the same call that retrieves and answers also enforces the policy:resp = rt.retrieve_and_generate(
input={"text": user_question},
retrieveAndGenerateConfiguration={
"type": "KNOWLEDGE_BASE",
"knowledgeBaseConfiguration": {
"knowledgeBaseId": "KB123456",
"modelArn": MODEL_ARN,
"generationConfiguration": {
"guardrailConfiguration": {
"guardrailId": "gr-abc123",
"guardrailVersion": "1"
}
}
}
}
)
6.3 An important boundary, and what guardrails do not guarantee
There is a boundary to understand: a guardrail applied throughRetrieveAndGenerate evaluates the user input and the model-generated response — it does not filter the retrieved reference passages themselves. If sensitive content lives in your source corpus, the guardrail will not scrub it out of retrieval; you manage that at the data and metadata layer (classification, tenant filters, and not ingesting what should not be retrievable). For applying a guardrail to arbitrary text outside the managed flow — including retrieved context before it reaches a model on a decoupled Retrieve path — Bedrock provides the ApplyGuardrail API, which evaluates content against a guardrail for any model, including custom or third-party ones.Finally, a guardrail being configured and passing is not the same as the system being safe. Filters are probabilistic and tier-dependent; a passing grounding check raises confidence but does not prove an answer is correct, and a content filter reduces but does not eliminate harmful output. Treat guardrails as one layer of defense in depth, combined with grounding-first prompting, least-privilege data access, evaluation, and human review for high-stakes paths. One operational note: if you enable model invocation logging, blocked content appears as plain text in those logs — account for that in your log handling. The dedicated treatment of prompt-injection attack and defense patterns is delegated to AWS WAF Generative AI Prompt Injection Patterns; this article does not include attack procedures.
7. Evaluation and Quality Loops
A RAG system that you cannot measure is one you cannot improve safely, because every change to chunking, embeddings, retrieval depth, prompt, or model trades one kind of error for another. Amazon Bedrock Evaluations provides a managed way to score retrieval and generation quality so those trades are visible.7.1 What you can measure
Bedrock supports RAG evaluation jobs in two shapes:- Retrieve only — scores the retrieval step alone: how relevant and how complete are the retrieved passages for each query. The metrics here are context relevance and context coverage.
- Retrieve and generate — scores the end-to-end flow: retrieval plus the generated answer, on dimensions such as correctness, completeness, faithfulness (hallucination), and helpfulness.
Evaluations can be run with LLM-as-a-judge (a second model scores the responses), with programmatic metrics, or with human reviewers. The LLM-as-a-judge approach gives you human-like nuance at automation speed and, for retrieval-only jobs, does not require ground-truth answers. Supported evaluator models span the Amazon Nova, Anthropic Claude, Meta Llama, and Mistral families.

7.2 Wiring evaluation into the loop
The point of evaluation is regression detection, not a one-time score. Keep a fixed evaluation dataset of representative questions (and ground-truth answers where you have them), run an evaluation job on every meaningful change, and compare report cards before and after. A retrieve-and-generate evaluation job, started with boto3:bedrock = boto3.client("bedrock")
bedrock.create_evaluation_job(
jobName="rag-eval-retrieve-generate-2026-06-20",
roleArn="arn:aws:iam::111122223333:role/BedrockEvalRole",
evaluationConfig={
"automated": {
"datasetMetricConfigs": [{
"taskType": "QuestionAndAnswer",
"dataset": {
"name": "corp-rag-eval-set",
"datasetLocation": {
"s3Uri": "s3://my-eval-bucket/datasets/rag_qa.jsonl"
}
},
"metricNames": [
"Builtin.Correctness",
"Builtin.Completeness",
"Builtin.Faithfulness"
]
}],
"evaluatorModelConfig": {
"bedrockEvaluatorModels": [
{"modelIdentifier": "anthropic.claude-opus-4-8"}
]
}
}
},
inferenceConfig={
"ragConfigs": [{
"knowledgeBaseConfig": {
"retrieveAndGenerateConfig": {
"type": "KNOWLEDGE_BASE",
"knowledgeBaseConfiguration": {
"knowledgeBaseId": "KB123456",
"modelArn": MODEL_ARN
}
}
}
}]
},
outputDataConfig={"s3Uri": "s3://my-eval-bucket/results/"}
)
8. Cross-Cutting: IAM, Data Boundaries, and Caching
The components above only become a production system when the cross-cutting concerns are right: who can call what, how tenants and sensitive data are kept apart, and how you avoid paying twice for the same work.8.1 Least-privilege IAM
There are two principals to scope. The Knowledge Base service role is what Bedrock assumes to do ingestion and retrieval: it needs read access to the source S3 prefix, permission to invoke the embedding model, and access to the vector store. The application role (the Lambda execution role) needs only permission to call the Knowledge Base query operations and the guardrail — not the underlying store, not the source bucket. Keeping these separate means a compromised application cannot read raw source documents or rewrite the index.A focused application-role policy:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "QueryKnowledgeBase",
"Effect": "Allow",
"Action": [
"bedrock:Retrieve",
"bedrock:RetrieveAndGenerate"
],
"Resource": "arn:aws:bedrock:us-east-1:111122223333:knowledge-base/KB123456"
},
{
"Sid": "InvokeGenerationModelViaRAG",
"Effect": "Allow",
"Action": ["bedrock:InvokeModel"],
"Resource": "arn:aws:bedrock:*::foundation-model/anthropic.*"
},
{
"Sid": "ApplyGuardrail",
"Effect": "Allow",
"Action": ["bedrock:ApplyGuardrail"],
"Resource": "arn:aws:bedrock:us-east-1:111122223333:guardrail/gr-abc123"
}
]
}
kms:Decrypt on the specific key rather than account-wide.8.2 Tenant and data boundaries
For a multi-tenant assistant, the cheapest robust isolation is metadata filtering: tag every chunk with atenant_id at ingestion, and make the application always inject a tenant_id filter on every Retrieve/RetrieveAndGenerate call, derived from the authenticated caller — never from client input. A single shared Knowledge Base with strict metadata filtering avoids the operational sprawl of one Knowledge Base per tenant while keeping tenant data segregated at query time. For stronger isolation requirements you can combine this with separate vector indexes or data sources; the trade-off is operational cost versus blast-radius reduction. Sensitive-but-same-tenant data (for example, documents only some roles may see) is handled the same way, with a classification attribute and a filter the application enforces server-side.The critical rule: the filter must be applied on the server side, from the caller's verified identity. If the filter is something the client can set, it is not an isolation boundary.
8.3 Caching and idempotency
Two caching opportunities reduce cost and latency without touching correctness. First, cache full answers for identical (or normalized) questions within a tenant — many knowledge-assistant questions repeat — with a short time-to-live so changes to the corpus eventually surface. Second, the model layer itself supports prompt caching for repeated context; if you use the decoupledRetrieve path and build prompts directly, a stable system-prompt prefix is a natural cache point. On the ingestion side, idempotency is already handled by the incremental sync (Section 3.4): because re-running a sync only processes changed documents, an at-least-once trigger (a retried S3 event, a duplicated schedule) does not corrupt the index. Make your own sync trigger idempotent too — coalesce events and avoid launching a second ingestion job while one is running.9. Observability and Failure Modes
When a RAG answer is wrong, the cause is almost always in one of four places. Good observability lets you tell which, fast.
9.1 The four failure modes
Retrieval is off-target. The answer is fluent but draws on the wrong passages. Symptom: citations point at irrelevant chunks. Root causes: chunking too coarse or too fine, an embedding-model mismatch for the content (for example an English-only model on multilingual text), or a missing/over-broad metadata filter. Diagnose by callingRetrieve directly with the failing query and inspecting the returned chunks and scores — if the right passage is not in the top results, it is a retrieval problem, not a generation problem. Fixes: adjust chunking and re-sync, switch embedding model, add hybrid search or reranking, tighten the metadata filter.Hallucination / weak grounding. Retrieval returned good chunks but the answer adds unsupported claims. Symptom: the contextual grounding score is low, or a reviewer finds claims absent from the cited chunks. Root causes: a prompt that does not insist on grounding, too few retrieved chunks, or a generation model reaching beyond the context. Fixes: strengthen the grounding instruction, raise
numberOfResults, raise the contextual grounding threshold, and re-evaluate.Guardrail over- or under-blocking. Either legitimate answers are blocked (threshold too strict, denied topics too broad) or unsafe/ungrounded answers slip through (threshold too loose). Diagnose with the guardrail trace and your evaluation set: measure block rate against a labeled set of good and bad answers. Fixes: tune the contextual grounding threshold and content-filter strengths against evaluation data, not anecdotally.
Sync failure. The corpus changed but the index did not. Symptom: answers cite stale content or miss new documents. Diagnose from the ingestion job statistics (
documentsFailed, documentsScanned) and the job status. Root causes: source permission errors, malformed documents, or a sync that never ran. Fixes: alarm on failed ingestion jobs, surface per-document failures, and re-trigger sync.9.2 What to watch
Use CloudWatch for the operational metrics of the surrounding services (API Gateway latency and errors, Lambda errors, throttles, and duration) and propagate a correlation ID from the API request through the Lambda log lines so you can reconstruct one user interaction across components. For the model and RAG layer, enable Amazon Bedrock model invocation logging to capture inputs, outputs, and metadata for invocations (remembering the plain-text-blocked-content caveat from Section 6), and watch for Bedrock throttling exceptions on the generation and embedding models. Together these let you separate an infrastructure problem (Lambda timeout, API Gateway 5xx) from a quality problem (low grounding score, off-target retrieval) within one trace. Deeper end-to-end tracing across services — correlation IDs, X-Ray, structured logs — is the subject of a dedicated observability architecture guide; here the goal is simply to know which of the four failure modes you are in.10. Variations: When Fine-Tuning or Agents Fit Better
RAG is the right default when answers must reflect private, frequently changing data with source attribution. Two variations are worth one paragraph each.Fine-tuning changes the model's weights to internalize style, format, or narrow domain behavior. It does not keep up with changing facts — you would re-tune on every corpus change — and it does not provide citations. Use it alongside RAG when you need a particular tone or output structure, not as a replacement for retrieval. This article does not go deeper into fine-tuning; treat it as a complementary lever.
Agents add planning and tool use on top of retrieval: when answering a question requires multiple retrieval steps, calling other systems, or taking actions, an agent that uses the Knowledge Base as one tool is the better shape. The multi-agent and agent-runtime patterns are covered in the existing AgentCore guides and are out of scope here; the RAG architecture in this article is exactly the retrieval tool such an agent would call. The decision is about question complexity: single-hop factual questions over documents are pure RAG; multi-step, multi-source, action-taking workflows are agents.
11. Frequently Asked Questions
Should I useRetrieve or RetrieveAndGenerate?Start with
RetrieveAndGenerate — it is the whole RAG flow with managed prompting and structured citations. Move a path to Retrieve when you need custom prompt construction, custom post-processing or reranking logic, multi-step orchestration, or per-question-class model routing.How do I stop the model from making things up?
Combine three things: a grounding-first prompt that forbids answering outside the retrieved context, the contextual grounding guardrail tuned against your evaluation set, and enough retrieved chunks that the answer is actually present. Then measure faithfulness with a retrieve-and-generate evaluation job and watch it over time.
Which vector store should I choose?
It depends on scale, latency, binary-vector needs, and whether you want vectors next to relational or graph data. Knowledge Bases supports eight stores; the selection is its own topic in Amazon S3 Vectors Design Decision Guide. For a managed AWS default, OpenSearch Serverless is the common starting point.
How do I isolate tenants in one Knowledge Base?
Tag every chunk with a
tenant_id at ingestion and have the application inject a tenant_id filter on every query, derived from the authenticated caller — never from client input. A single Knowledge Base with strict server-side metadata filtering avoids per-tenant sprawl while keeping data segregated.Do guardrails make my RAG application safe?
They are one layer, not a guarantee. A guardrail applied through
RetrieveAndGenerate checks the input and the generated answer, not the retrieved passages; filters are probabilistic; and a passing grounding check raises confidence without proving correctness. Combine guardrails with grounding-first prompting, least-privilege data access, evaluation, and human review for high-stakes answers.My answers cite the wrong documents — where do I start?
That is a retrieval problem, not a generation problem. Call
Retrieve directly with the failing query and inspect the chunks and scores. If the right passage is not in the top results, fix chunking (re-sync), the embedding model, the metadata filter, or add hybrid search and reranking before touching the prompt or model.How do I keep the index fresh?
Drive
StartIngestionJob from change (an S3 event or schedule). Sync is incremental and idempotent, so it only reprocesses changed documents; coalesce bursts so you do not launch overlapping jobs, and alarm on failed ingestion jobs.12. Summary
Production RAG on Amazon Bedrock is an architecture, not an API call. The reference system in this guide ties together S3 sources, a Bedrock Knowledge Base that owns parsing, chunking, embedding, and incremental sync, a vector store chosen for your scale and latency, an API Gateway and Lambda application tier that retrieves and generates with citations, Bedrock Guardrails that filter input and output and check grounding, and Bedrock Evaluations that score retrieval and generation so you can change the system safely. The recurring lessons: retrieval quality is decided at ingestion time; the embedding model is part of your index; grounding needs both a prompt and a guardrail; isolation must be enforced server-side from verified identity; and you cannot improve what you do not measure. Deep selection of the vector store, the prompt-injection defenses, and the agent patterns are delegated to focused guides so this one can stay an implementation walkthrough.For the building blocks and adjacent topics, see Amazon Bedrock Basic Information and API Examples, the vector-store decision in Amazon S3 Vectors Design Decision Guide, prompt-injection defense in AWS WAF Generative AI Prompt Injection Patterns, the evaluation mindset in Amazon Bedrock AgentCore Evaluations Practical Guide, and the terminology in Amazon Bedrock Glossary.
13. References
- Amazon Bedrock Knowledge Bases
- Retrieving information from data sources using Amazon Bedrock Knowledge Bases
- StorageConfiguration (supported vector stores)
- Prerequisites for using a vector store for a knowledge base
- Supported models and Regions for Amazon Bedrock knowledge bases
- AWS::Bedrock::DataSource ChunkingConfiguration
- Create your guardrail (Amazon Bedrock Guardrails components)
- Use contextual grounding check to filter hallucinations in responses
- Evaluate the performance of Amazon Bedrock resources
- Evaluate the performance of RAG sources using Amazon Bedrock evaluations
- Amazon S3 Vectors
- Amazon Bedrock model invocation logging
- Amazon Bedrock pricing
- Supported foundation models in Amazon Bedrock
References:
Tech Blog with curated related content
Written by Hidekazu Konishi