Responsible-AI Guardrails Architecture on AWS - Independent Content Safety with Bedrock Guardrails, Comprehend, and WAF
First Published:
Last Updated:
This article builds the opposite: an independent content-safety pipeline on AWS, where the safety controls are a separate layer that sits in front of and behind the model and never depends on which model is running. The backbone is Amazon Bedrock Guardrails applied through the
ApplyGuardrail API (decoupled from model invocation), with Amazon Comprehend completing PII handling, AWS WAF providing the coarse edge filter, and AWS CloudTrail, Bedrock model invocation logging, and Amazon CloudWatch recording every decision for audit.This is a Level 400 implementation walkthrough: one named reference architecture, an end-to-end request flow with block branches, reproducible API calls and infrastructure snippets for each component, the cross-component failure modes, and the cross-cutting concerns (least-privilege IAM, data boundaries, governance). It deliberately delegates the network-edge rule details to a dedicated article, the conceptual framing to a dedicated model, and the per-tenant policy isolation to a dedicated multi-tenant article, so it can stay focused on the safety control plane itself.
A word on framing before we start: a request passing every configured check does not mean the content is safe. Content safety controls are probabilistic detectors with thresholds; they reduce risk, they do not prove its absence. Everything below is written as defense in depth, where each layer narrows the gap the others leave, and the audit trail exists precisely because no single control is sufficient.
1. Introduction: Safety as an Independent Control Layer
The instinct to delegate safety to the model is understandable. Frontier models are trained with safety alignment, and a well-written system prompt can shape behavior a long way. But three properties of production systems break the "let the model handle it" approach:- Models change. You will upgrade model versions, and you may route different requests to different models for cost, latency, or capability. Safety behavior that is implicit in one model's weights does not transfer to the next, and you have no contract that says it should.
- Not every model is yours. The moment you add a self-hosted open-weight model, a third-party API model, or a fine-tuned variant, "the model's built-in safety" stops being a single, known quantity.
- Implicit safety is unauditable. If the only thing standing between a user and a harmful output is the model's training, there is no log that says "this input was checked against these policies and the decision was X." Governance, incident response, and regulatory review all need that record.
The architectural answer is to move content safety out of the model and into a separate control layer that you own, version, observe, and apply consistently regardless of the model behind it. On AWS, the keystone that makes this possible is the
ApplyGuardrail API, which lets you evaluate any text against a configured Amazon Bedrock guardrail without invoking a foundation model at all. Because the check is decoupled from inference, you can place it anywhere in your flow — before retrieval, before the model call, after the model call — and you can apply the same policy to outputs from a model that does not even run on Bedrock.This article's scope is that independent pipeline and how its parts fit together. It is intentionally narrow on a few things that other articles already own:
- WAF rule specifics and prompt-injection patterns are delegated to AWS WAF for Generative AI - Prompt Injection Defense Implementation Patterns. Here, WAF appears only as the coarse edge layer in the larger pipeline.
- The conceptual layering vocabulary is delegated to AI Agent Defense in Depth Model (AIDDM). This pipeline is, in AIDDM terms, the concrete implementation of the Input and Output layers.
- The client-side tool trust boundary for agents is delegated to MCP Tool Poisoning Defense Guide.
What stays here is the safety control plane: independent guardrail application, the content/topic/PII policies, contextual grounding for hallucination control, the WAF-to-Guardrails-to-Comprehend division of responsibility, the audit trail, and the tuning and failure modes that decide whether the whole thing is usable in production.
2. The Reference Architecture at a Glance
The pipeline is a single named architecture: The Independent Content-Safety Pipeline. A request flows through a coarse edge filter, an independent pre-generation guard, the model, an independent post-generation guard plus a grounding check, and a PII-completion pass, and every decision is written to an audit trail. The defining property is that the two guard stages are applied throughApplyGuardrail, so they are not bound to the model in the middle.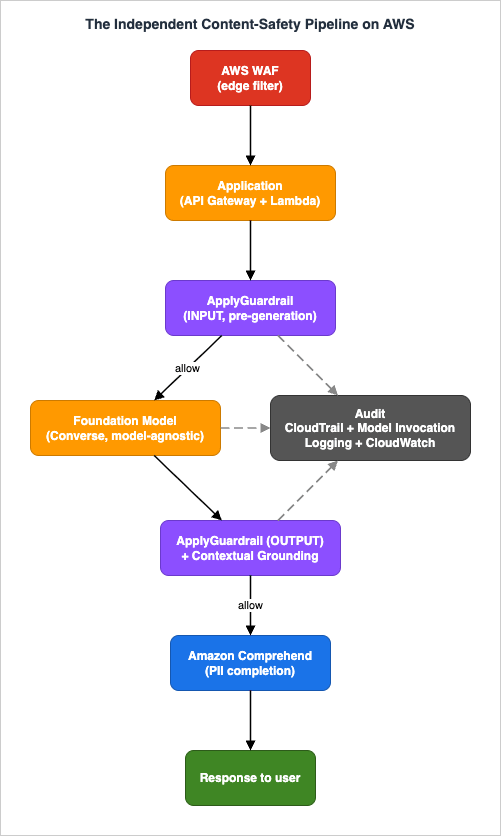
- AWS WAF (edge, coarse). A byte-level filter on the public entry point (Amazon CloudFront, Application Load Balancer, or Amazon API Gateway). It stops automated abuse, enforces rate and size limits, and matches known-bad patterns before any model is invoked. It cannot understand meaning. Rule details are delegated to the WAF article.
- Application tier. Your service (for example AWS Lambda behind API Gateway) that orchestrates the pipeline: it calls the pre-guard, the model, the post-guard, and the PII pass, and it decides what to return on a block.
- Pre-generation guard —
ApplyGuardrailwithsource = INPUT. Evaluates the user input against denied topics, content filters, prompt-attack detection, word filters, and sensitive-information rules before the model runs and, in a RAG flow, before retrieval. - Foundation model — Converse API (model-agnostic). The model call itself. Because the guards are independent, the model can be any Bedrock model, and the same policy can guard outputs from a model that runs elsewhere.
- Post-generation guard —
ApplyGuardrailwithsource = OUTPUTplus a contextual grounding check. Evaluates the model output against the same content/topic/PII policies and, for RAG and summarization, checks that the answer is grounded in and relevant to the retrieved source. - Amazon Comprehend (PII completion). A complementary PII pass with a richer entity taxonomy and custom downstream redaction, covering both the model path and non-model data paths (logs, tickets, stored transcripts).
- Audit (CloudTrail + model invocation logging + CloudWatch). CloudTrail records control-plane changes, model invocation logging captures inputs and outputs, the guardrail trace records every assessment, and CloudWatch turns it into metrics, alarms, and dashboards.
Why both a pre-guard and a post-guard? They catch different failures. The pre-guard stops disallowed requests (a denied topic, a prompt-injection attempt, PII the user should not be sending) and, importantly, can stop a RAG retrieval from running against a bad query at all. The post-guard stops disallowed responses (harmful content the model produced, PII leaking from the context, an answer that is not grounded in the source). A single check on one side leaves the other side open.
Why independent rather than the model's built-in safety? Three reasons, all of which the
ApplyGuardrail documentation states directly: content validation works on any text input or output; the API can be integrated anywhere in the flow; and it is decoupled from foundation models so you can apply policy without invoking one. That decoupling is the whole point — it is what makes the safety layer portable across models and frameworks.3. Independent Guardrails with ApplyGuardrail
This is the core of the architecture, so it gets the most detail. The end-to-end flow below shows where the two independent guard stages sit relative to the model, and what happens on a block.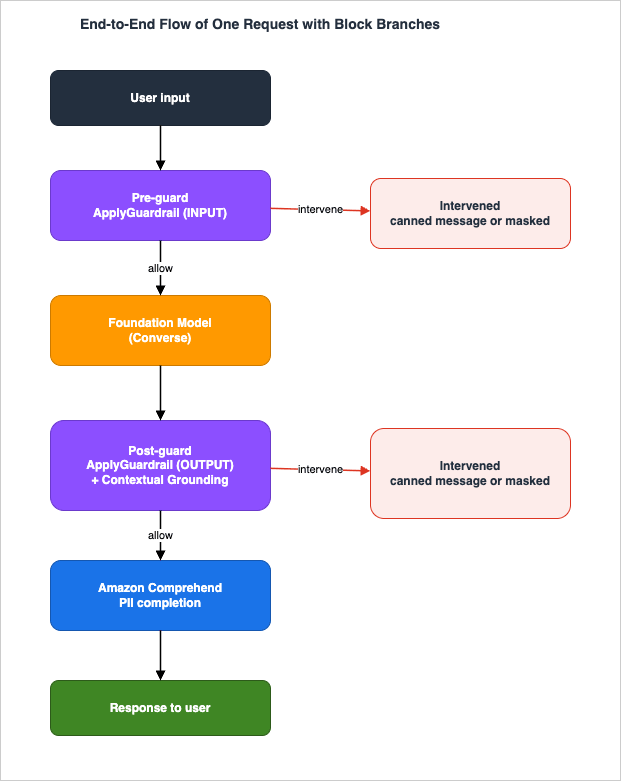
3.1 Why decoupling matters
ApplyGuardrail assesses text against a pre-configured guardrail without calling a model. The practical consequences:- You can guard before spending a model call — block a disallowed input and never pay for inference on it.
- You can guard outputs from any model, including one outside Bedrock, by passing the generated text as
OUTPUT. - You can place the check at any point — for a RAG application, you can evaluate the user input before retrieval rather than waiting for final generation.
The request shape is small. You specify the guardrail by
guardrailIdentifier and guardrailVersion, set source to INPUT or OUTPUT, and pass the content to evaluate:import boto3
bedrock_runtime = boto3.client("bedrock-runtime", region_name="us-east-1")
def pre_guard(user_text: str, guardrail_id: str, guardrail_version: str) -> dict:
"""Evaluate a user input before any retrieval or model call."""
response = bedrock_runtime.apply_guardrail(
guardrailIdentifier=guardrail_id,
guardrailVersion=guardrail_version, # "DRAFT" while testing, a numbered version in production
source="INPUT",
content=[{"text": {"text": user_text}}],
)
return response
action is either GUARDRAIL_INTERVENED or NONE. When the guardrail intervened, output carries either the masked content (for anonymization) or a single canned message (for a block); when it did not intervene, output is empty. The assessments array carries the per-policy detail — topicPolicy, contentPolicy, wordPolicy, sensitiveInformationPolicy, and contextualGroundingPolicy — which is exactly what you record for audit.def decide(response: dict) -> tuple[str, str]:
"""Map an ApplyGuardrail response onto an application decision."""
if response["action"] != "GUARDRAIL_INTERVENED":
return ("ALLOW", "")
outputs = response.get("outputs") or response.get("output") or []
if outputs:
# Either a canned block message or masked/anonymized text, depending on policy.
return ("INTERVENED", outputs[0]["text"])
return ("INTERVENED", "")
outputs vs output) can differ between the documentation snapshot and the SDK you use; read the assessment object and the action field, and treat the canned/masked text as the user-facing result rather than assuming a fixed key.3.2 Applying both stages around the model
The application tier wires the two stages around a model-agnostic Converse call. The post-guard runs on the generated text; only output that the guardrail did not block is returned.def guarded_generate(user_text, model_id, guardrail_id, guardrail_version, messages):
# Stage 1: pre-generation guard on the input.
pre = pre_guard(user_text, guardrail_id, guardrail_version)
pre_decision, pre_message = decide(pre)
log_assessment("INPUT", pre) # see section 7
if pre_decision == "INTERVENED" and not pre.get("outputs"):
return blocked_response(pre_message) # blocked input: skip retrieval and the model entirely
# Stage 2: model call (any Bedrock model; the guard does not depend on which one).
model_out = bedrock_runtime.converse(modelId=model_id, messages=messages)
answer = model_out["output"]["message"]["content"][0]["text"]
# Stage 3: post-generation guard on the output.
post = bedrock_runtime.apply_guardrail(
guardrailIdentifier=guardrail_id,
guardrailVersion=guardrail_version,
source="OUTPUT",
content=[{"text": {"text": answer}}],
)
log_assessment("OUTPUT", post) # see section 7
post_decision, post_message = decide(post)
if post_decision == "INTERVENED":
return post_message # canned block message or masked answer
return answer
outputScope. Set it to FULL to return the entire assessment, including non-detected entries, which is what you want when you are tuning thresholds and need to see scores for content that passed as well as content that was blocked.3.3 Designing the policy, and versioning it
A guardrail is a configured resource, created once and then versioned. The recommended lifecycle is to iterate against the unversionedDRAFT, then publish a numbered version and pin production to it. Pinning matters: it means a policy change you make while tuning does not silently alter the behavior of every production request mid-flight. You create the guardrail with CreateGuardrail and evolve it with UpdateGuardrail; each publish produces an immutable numbered version.Define the guardrail as infrastructure so the policy is reviewable and the change history lives in version control. A CloudFormation excerpt (trimmed to the policy shape):
Resources:
ContentSafetyGuardrail:
Type: AWS::Bedrock::Guardrail
Properties:
Name: independent-content-safety
BlockedInputMessaging: "This request can't be processed."
BlockedOutputsMessaging: "This response can't be provided."
ContentPolicyConfig:
FiltersConfig:
- Type: HATE
InputStrength: HIGH
OutputStrength: HIGH
- Type: PROMPT_ATTACK
InputStrength: HIGH
OutputStrength: NONE # prompt-attack applies to input, not model output
TopicPolicyConfig:
TopicsConfig:
- Name: Investment_Advice
Type: DENY
Definition: "Specific buy/sell/hold recommendations for individual securities."
SensitiveInformationPolicyConfig:
PiiEntitiesConfig:
- Type: EMAIL
Action: ANONYMIZE
- Type: CREDIT_DEBIT_CARD_NUMBER
Action: BLOCK
ContextualGroundingPolicyConfig:
FiltersConfig:
- Type: GROUNDING
Threshold: 0.7
- Type: RELEVANCE
Threshold: 0.7
3.4 Safeguard tiers and language coverage
Content filters and denied topics each support two tiers, and you can choose the tier per policy. The Standard tier provides more robust performance and broader language support, and it requires cross-Region inference; the Classic tier provides the established functionality with support for English, French, and Spanish. You enable a tier through the tier configuration on the policy, together with the cross-Region configuration when using Standard. The practical rule: if your users write in languages beyond English/French/Spanish, you almost certainly want the Standard tier, and you must budget for cross-Region inference being part of the path.3.5 Throughput and chunking
ApplyGuardrail has a default limit of 25 text units (approximately 25,000 characters) per second. If a single input exceeds that, you chunk it and process sequentially to avoid throttling — a common starting point is to break content into pieces of about half the limit and reassemble, keeping as much context intact per request as possible. The caveat that matters for correctness: when the guardrail intervenes by masking rather than blocking, the returned content is the processed text, so when you chunk you must recompile the response from the per-chunk processed outputs, not from the original.3.6 Standalone checks for agents
For agentic applications that need lightweight, resource-less checks rather than a full configured guardrail, Bedrock Guardrails exposesInvokeGuardrailChecks, which supports content filters, prompt-attack detection, and sensitive-information filters as standalone checks. It has its own throughput limit (a default of 1,500 requests per minute per account per Region at the time of writing), so smooth traffic over time and use exponential backoff with jitter on retries. Use it where you want a quick per-step check inside an agent loop without provisioning a guardrail resource; use the full ApplyGuardrail path where you want the complete policy set, including contextual grounding and denied topics.Across all of these, the IAM principle is least privilege: the role that calls the guards needs
bedrock:ApplyGuardrail (and bedrock:InvokeGuardrailChecks if used) and nothing more on the safety plane; the ability to CreateGuardrail/UpdateGuardrail belongs to a separate, tightly scoped change-management role (see section 7).4. Content Filters, Denied Topics, and PII
A single guardrail bundles several policy types. Knowing what each one is for — and where Amazon Comprehend complements them — is what keeps you from either over-relying on one control or duplicating work.4.1 The guardrail policy types
- Content filters (multimodal). Detect and filter harmful content across categories — hate, insults, sexual, violence, misconduct, and prompt attacks — for both text and image content. Each category has an adjustable strength of
NONE,LOW,MEDIUM, orHIGH, set independently for input and output. Prompt-attack detection is meaningful on the input side; setting it on output has no useful effect because the model output is not a prompt. - Denied topics. Define topics that are undesirable for your application; they are blocked if detected in user queries or model responses, and you can configure separate actions for input and output. Topics can be custom (a name, a definition, and example phrasings) or drawn from managed topics such as financial advice.
- Word filters. Block specific words and phrases by exact match — a custom list (competitor names, internal code names) plus a managed profanity list.
- Sensitive information filters. Block or mask PII and custom regular-expression matches in inputs and responses. The action per entity is either
BLOCK(refuse) orANONYMIZE(mask in place); detection is probabilistic over standard formats such as account numbers and dates of birth, and the regex option lets you add organization-specific identifiers.
4.2 Where Amazon Comprehend completes the picture
The guardrail's sensitive-information filter is inline and managed, which is exactly what you want in the model path. Amazon Comprehend's PII detection is complementary, and the division of responsibility is worth being explicit about because it is easy to either skip Comprehend (and miss coverage) or run both blindly (and double-handle).Comprehend brings a richer, named entity taxonomy. Its real-time PII detection covers five categories: financial (bank account number, routing number, card number, CVV, expiry, PIN), personal (name, address, phone, email, age), technical security (username, password, URL, AWS access key, AWS secret key, IP address, MAC address), national (SSN, passport number, driver ID), and other (date-time). For each detected entity you get the type, a confidence score, and the begin/end offsets.
The operational nuance that drives your design: with Comprehend you can locate PII with real-time analysis or an asynchronous batch job, but the built-in redaction of PII requires an asynchronous batch job. In a real-time request path you therefore use the offsets to mask the text yourself; for bulk redaction of stored documents you use a batch job.
import boto3
comprehend = boto3.client("comprehend", region_name="us-east-1")
def redact_pii(text: str, language_code: str = "en") -> str:
"""Real-time PII completion: cheap gate, then locate, then self-mask using offsets."""
# Cheap boolean gate first: ContainsPiiEntities returns labels only.
labels = comprehend.contains_pii_entities(Text=text, LanguageCode=language_code)
if not labels.get("Labels"):
return text
# Locate exact spans, then mask in place using begin/end offsets.
found = comprehend.detect_pii_entities(Text=text, LanguageCode=language_code)
redacted = text
for entity in sorted(found["Entities"], key=lambda e: e["BeginOffset"], reverse=True):
begin, end = entity["BeginOffset"], entity["EndOffset"]
redacted = redacted[:begin] + f"[{entity['Type']}]" + redacted[end:]
return redacted
ContainsPiiEntities is a cheap boolean gate — call it before the more detailed DetectPiiEntities so you only pay for offset-level detection when PII is actually present. Second, masking is applied from the end of the string backwards so that each replacement does not shift the offsets of the entities still to be processed.Use Comprehend for what the inline guardrail filter is not positioned to do: a broader entity taxonomy, custom downstream masking logic, and non-model data paths — redacting PII from logs, support tickets, and stored transcripts before they are indexed or archived. Real-time analysis covers English and Spanish; confirm current language support before relying on it for other languages.
A point on honesty: PII detection — by Guardrails or Comprehend — is probabilistic. It will miss some entities and flag some non-entities. The pipeline treats it as defense in depth (inline guardrail filter, plus Comprehend, plus your own regex for known-format identifiers), not as a guarantee that no sensitive data ever passes.
5. Contextual Grounding and Hallucination Control
For RAG and summarization workloads, the most damaging failure is not harmful content — it is a confident, well-formed answer that is not supported by the source. The contextual grounding check is the control for that, and it is the second core of this architecture because it is what connects the safety layer to a retrieval pipeline.5.1 What the check measures
The contextual grounding check evaluates two paradigms, each with its own threshold:- Grounding — is the response factually supported by the source? Any new information introduced in the response that is not in the source counts as ungrounded.
- Relevance — is the response relevant to the user's query?
The documentation's example makes the distinction crisp. With a source of "London is the capital of UK. Tokyo is the capital of Japan" and a query "What is the capital of Japan?": the answer "The capital of Japan is London" is relevant but ungrounded (it contradicts the source), while "The capital of UK is London" is grounded but irrelevant (it does not answer the query). You catch each with the corresponding threshold.
Thresholds are confidence scores you configure between 0 and 0.99 (a threshold of 1 would block effectively everything). A response scoring below the grounding or relevance threshold is treated as a hallucination and blocked. Raising the threshold blocks more ungrounded/irrelevant content at the cost of more false positives — the right value is a function of your tolerance for inaccuracy, and a high-stakes domain warrants a higher threshold. Officially, contextual grounding checks filter over 75% of hallucinated responses for RAG and summarization workloads; that is a meaningful reduction, not elimination, which is why the answer is still subject to the rest of the pipeline.
5.2 The three inputs, and how to pass them
A grounding check needs three components: the grounding source (the contextual information, for example the retrieved chunks), the query (the user's question), and the content to guard (the model response). The character limits are part of the design budget: the grounding source supports up to 100,000 characters, the query up to 1,000, and the response up to 5,000.When you call
ApplyGuardrail directly — the model is not invoked by the guard, so you supply all three — you mark the source and query with the qualifiers field and pass the model response as the content to guard:def grounding_check(source, query, answer, guardrail_id, guardrail_version):
return bedrock_runtime.apply_guardrail(
guardrailIdentifier=guardrail_id,
guardrailVersion=guardrail_version,
source="OUTPUT", # grounding runs on output; a response is required
content=[
{"text": {"text": source, "qualifiers": ["grounding_source"]}},
{"text": {"text": query, "qualifiers": ["query"]}},
{"text": {"text": answer}}, # the content to guard (optionally qualified guard_content)
],
)
type (GROUNDING or RELEVANCE), the configured threshold, the actual score, and the action. Logging the score (not just the action) is what lets you tune thresholds against real traffic.5.3 Connecting to RAG, and the boundaries
This is the join point with an agentic or static RAG pipeline: the retrieved chunks become thegrounding_source, the user's question becomes the query, and the model's drafted answer becomes the content to guard. For the agent-style retrieval, grading, and self-correction loop that produces those chunks, see Agentic RAG Architecture on Amazon Bedrock.Three boundaries to respect, all from the official behavior:
- Supported use cases are summarization, paraphrasing, and question answering. Conversational QA / chatbot use cases are not supported by the grounding check, so do not rely on it for free-form multi-turn chat.
- Relevance is decided per chunk, optimistically. If any one processed chunk is deemed relevant, the whole response is considered relevant. With streaming output this can mean an irrelevant response reaches the user and is only marked irrelevant after the full response is streamed — design your UX around that if you stream.
- The character limits are hard. Oversized grounding sources or responses must be handled deliberately (truncate, summarize, or split), or the check will not see what you think it sees.
5.4 Automated Reasoning checks as a complement
For domains where you can express the rules of correctness formally, Amazon Bedrock Guardrails also offers Automated Reasoning checks, which verify generated content against a structured, mathematical representation of knowledge (an Automated Reasoning Policy) and can explain why a response is or is not accurate. It is a complement to contextual grounding rather than a replacement: grounding asks "is this supported by the retrieved text," Automated Reasoning asks "is this consistent with these formal rules." Treat it as an advanced add-on for high-assurance, rule-bound domains; the rest of this pipeline does not depend on it.6. Edge Defense and Defense in Depth
With the guard stages, PII completion, and grounding in place, the question is how they divide responsibility with the network edge — and where each one is blind.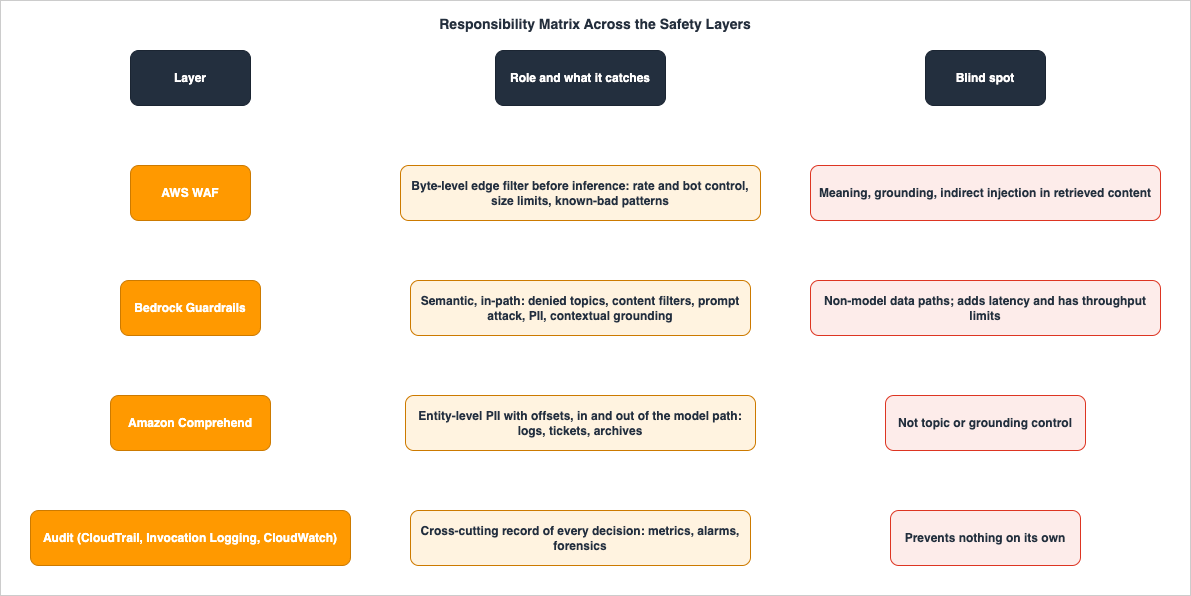
- AWS WAF — byte-level, at the edge, before inference. Rate-based rules, bot control, size and content-type limits, and pattern matching against known-bad strings. It is the cheapest place to stop automated abuse and resource-exhaustion attacks, and it runs before you spend anything on a model. It cannot reason about meaning, indirect injection in retrieved content, or whether an answer is grounded. The rule patterns themselves — including prompt-injection signatures and denial-of-wallet defenses — are delegated to AWS WAF for Generative AI - Prompt Injection Defense Implementation Patterns.
- Bedrock Guardrails — semantic, in the inference path. Denied topics, content categories, prompt-attack classification, sensitive information, and contextual grounding. It understands content in a way WAF cannot, but it runs per request inside the path and so adds latency and is subject to its own throughput limits.
- Amazon Comprehend — entity-level PII, in and out of the model path. A richer PII taxonomy with offsets, usable for both the model path and non-model data (logs, tickets, archives) where Guardrails is not in the loop.
- Audit — across all layers. Records what each layer decided; it prevents nothing on its own but is what makes detection, tuning, and incident response possible.
In the vocabulary of the AI Agent Defense in Depth Model (AIDDM), WAF is the Edge layer, the pre-generation guard is the Input layer, and the post-generation guard plus grounding and PII completion are the Output layer. This article is the concrete AWS implementation of those layers; AIDDM is where the layering is argued in the abstract and mapped to OWASP and MITRE catalogs.
The reason this is defense in depth and not a checklist is that each layer's blind spot is another layer's job. WAF cannot see semantics; Guardrails does. Guardrails sees the model path but not your log pipeline; Comprehend covers that. None of them prove safety; the audit trail is how you find what slipped through. Passing all configured layers is a strong signal, not a safety proof — the layers are arranged so that the gaps are small and visible, not so that any one of them can be trusted alone.
7. Auditing and Policy Governance
An independent safety layer is only as good as your ability to prove what it did and to change it safely. Three AWS facilities cover the recording, and IAM plus versioning cover the governance.7.1 Recording every decision
- Guardrail assessments. Every
ApplyGuardrailresponse carries the per-policy assessment; with tracing enabled andoutputScope = FULL, you capture scores for both detected and non-detected content. Persist these — they are the per-request safety record. - Model invocation logging. Bedrock can collect the full request, response, and metadata for
Converse,ConverseStream,InvokeModel, andInvokeModelWithResponseStream. It is disabled by default and is configured per Region with destinations of Amazon CloudWatch Logs, Amazon S3, or both; payloads over 100KB or in binary form are delivered to S3. You control encryption with AWS KMS and the retention period. Note that logging is only captured for calls made through thebedrock-runtimeendpoint. - AWS CloudTrail. Records the control-plane API activity — who created or updated a guardrail, who changed the logging configuration — which is the change history you need for governance and for answering "when did this policy change."
- Amazon CloudWatch. Turns the logs and metrics into operational signal: custom metric filters over the log group, alarms on block-rate spikes or anomalous patterns, and dashboards that show the safety layer's behavior over time.
The S3 destination requires a bucket policy that lets the Bedrock service principal write the logs, scoped by source account and source ARN:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AmazonBedrockLogsWrite",
"Effect": "Allow",
"Principal": { "Service": "bedrock.amazonaws.com" },
"Action": ["s3:PutObject"],
"Resource": ["arn:aws:s3:::<bucket>/<prefix>/AWSLogs/<account-id>/BedrockModelInvocationLogs/*"],
"Condition": {
"StringEquals": { "aws:SourceAccount": "<account-id>" },
"ArnLike": { "aws:SourceArn": "arn:aws:bedrock:<region>:<account-id>:*" }
}
}
]
}
kms:GenerateDataKey under the same source-account and source-ARN conditions.7.2 Least-privilege IAM and the data boundary
Separate the roles by job. The request-path role that runs the pipeline getsbedrock:ApplyGuardrail, bedrock:Converse, the relevant Comprehend detect actions, and write access to the log path — and nothing on guardrail management. A distinct, tightly held change-management role gets bedrock:CreateGuardrail / bedrock:UpdateGuardrail / bedrock:CreateGuardrailVersion and the logging-configuration permissions. A third, read-only role reads the logs for audit. This separation is what stops the service that runs the safety check from also being able to weaken it.The data boundary deserves attention because the audit trail itself contains exactly the sensitive content you are trying to control. Model inputs and outputs in the logs may include PII or regulated data, so the log destinations are KMS-encrypted, access-controlled to the read-only audit role, and given a retention period that matches your policy. This is also where per-tenant isolation enters: in a multi-tenant system, each tenant's policy, logs, and data boundary must be separated. That isolation — per-tenant guardrails, ABAC with IAM session tags, and tenant-scoped logging — is delegated to Multi-Tenant Generative AI SaaS Architecture on AWS.
7.3 Change management through versioning
Treat the guardrail like code. Iterate onDRAFT, validate against a labeled evaluation set with ApplyGuardrail (cheaper than testing through the model because no inference runs), then publish a numbered version and pin production to it. When you need to change a policy, you publish a new version and roll it out deliberately — running sessions stay on the pinned version, and you can roll back by re-pinning if the new version regresses. CloudTrail records each publish, closing the governance loop: every change to what "safe" means is attributable and reversible.8. Tuning and Failure Modes
A safety pipeline that blocks everything is as useless as one that blocks nothing. This section is the core operational content: the failure modes that show up in production, how to tell them apart, and how to tune. The throughline is that you tune against an evaluation set, not against intuition — a labeled dataset of safe examples (should pass), harmful examples (should block), edge cases (boundary tests), and, if you use the Standard tier, examples in multiple languages. Run it throughApplyGuardrail and measure.8.1 Over-blocking (false positives)
- Symptom. Legitimate requests or answers are blocked; users report the assistant "refusing for no reason."
- Likely causes. Content-filter strength set too high for the domain; a denied topic defined too broadly so it catches adjacent legitimate content; a grounding or relevance threshold set so high that correct answers fall below it.
- Triage. Re-run the request with
outputScope = FULLand read the assessment: which policy fired, with what confidence, and — for grounding — what score. Compare the score distribution of known-good content against the threshold. - Remediation. Lower the specific filter strength, narrow the denied-topic definition and examples, or lower the threshold — one change at a time, re-measured against the evaluation set so you do not trade a false-positive problem for a false-negative one.
8.2 Under-blocking (false negatives)
- Symptom. Content that should have been caught reaches the user.
- Likely causes. Filter strength too low; a language mismatch where Classic-tier coverage (English, French, Spanish) misses content in another language; a PII format the managed entity set does not cover; a denied topic whose definition does not match how the content is actually phrased.
- Remediation. Raise the relevant strength; move content filters and denied topics to the Standard tier for broader language coverage (and accept cross-Region inference in the path); add Amazon Comprehend and custom regex for PII the inline filter misses; expand the topic definition with more example phrasings.
8.3 Grounding misjudgments
The grounding check has specific behaviors that look like bugs if you do not expect them. A relevant-but-ungrounded answer and a grounded-but-irrelevant answer are caught by different thresholds, so tune them separately. Because relevance is decided optimistically per chunk, a large multi-chunk source can mark a response relevant on the strength of one chunk; if that surprises you, reduce the source to the chunks actually retrieved for the query. Remember the unsupported case — conversational QA / chatbot — and do not deploy grounding there expecting it to work. And watch the character limits (100,000 / 1,000 / 5,000): silently exceeding them means the check evaluated truncated input.8.4 PII leakage
Treat PII as a layered problem precisely because any single detector misses. The inline sensitive-information filter is the first pass; Amazon Comprehend is the backstop with a broader taxonomy; organization-specific identifiers get a regex. The same applies on the way out to storage: redact before logs and transcripts are indexed or archived, using a batch redaction job for bulk stored data and offset-based masking in the real-time path. If a leak is found, the fix is usually to add the missed entity type or pattern to the layer best positioned to catch it, then add a case to the evaluation set so it cannot regress.8.5 Throttling and latency
Two throughput limits shape the design.ApplyGuardrail defaults to about 25 text units (~25,000 characters) per second, so long inputs must be chunked and processed sequentially, recompiling masked output from the per-chunk results. InvokeGuardrailChecks defaults to about 1,500 requests per minute per account per Region, and even below the per-minute limit a sudden burst can be throttled — smooth traffic and use exponential backoff with jitter on retries. On latency: running a pre-guard and a post-guard adds two synchronous checks to the path. Keep them where they are correctness-critical, run independent checks concurrently where the logic allows, and for non-blocking concerns (for example PII redaction of content destined only for storage) move the work off the request path. Confirm the current numeric limits in the official quotas pages before sizing, since they are adjustable and change over time.8.6 Tier and language mismatch
A subtle, recurring failure is a guardrail configured on the Classic tier serving a multilingual audience: content in unsupported languages is simply not evaluated the way you expect. If your traffic is multilingual, use the Standard tier for content filters and denied topics, and verify that cross-Region inference is permitted in your environment, since the Standard tier requires it.The honest summary of this section: tuning is continuous, not a one-time setup. An evaluation set that passes today tells you the pipeline handles known cases; it does not certify safety against the cases you have not thought of. Keep the set growing from real incidents, keep the thresholds under review, and keep the audit trail so the next surprise is at least visible.
9. Frequently Asked Questions
Is ApplyGuardrail a separate service from the model, and does it cost a model call?It is part of Amazon Bedrock Guardrails and runs without invoking a foundation model. That decoupling is the point — you can evaluate input before deciding to call a model, and you can evaluate output from a model that does not run on Bedrock. For pricing, see the official Amazon Bedrock pricing page; this article does not quote figures.
Do I still need Amazon Comprehend if the guardrail already has a PII filter?
They overlap but are not redundant. The guardrail filter is inline and managed in the model path; Comprehend brings a richer entity taxonomy, offset-level detection for custom masking, and coverage of non-model data paths such as logs and tickets. Use the guardrail filter in the path and Comprehend as the backstop and for bulk or stored data.
Does the contextual grounding check work for a chatbot?
The supported use cases are summarization, paraphrasing, and question answering. Conversational QA / chatbot use cases are explicitly not supported, so do not rely on the grounding check for free-form multi-turn chat.
Where does AWS WAF fit, and why is it not enough on its own?
WAF is the coarse, byte-level edge filter that stops automated abuse and known-bad patterns before any inference. It cannot reason about meaning, indirect injection in retrieved content, or grounding. It is the first layer of a defense-in-depth stack, not the whole thing; the rule patterns are covered in the dedicated WAF article.
How do I keep a policy change from breaking production?
Iterate on the
DRAFT guardrail, validate against a labeled evaluation set with ApplyGuardrail, publish a numbered version, and pin production to that version. Roll changes out by publishing a new version and re-pinning, with CloudTrail recording each change.What is the single most useful setting when tuning?
outputScope = FULL. It returns the complete assessment, including scores for content that passed, which is what you need to see where your thresholds actually sit relative to real traffic.Does passing all the guardrail checks mean the content is safe?
No. The checks are probabilistic detectors with thresholds; they reduce risk and they are arranged so the gaps between layers are small and visible. Safety comes from defense in depth plus an audit trail, not from any single check returning "allowed."
How do I handle inputs longer than the guardrail can process at once?
Chunk them to stay under the per-second text-unit limit and process sequentially. When the guardrail masks rather than blocks, recompile the final text from the per-chunk processed outputs rather than the originals.
10. Summary
Content safety is most robust when it is an independent control layer rather than a property you hope the model retains across upgrades. On AWS, theApplyGuardrail API makes that independence concrete: it evaluates any input or output against a configured Amazon Bedrock guardrail without invoking a model, so you can apply the same denied-topic, content-filter, prompt-attack, sensitive-information, and contextual-grounding policies before and after generation, regardless of which model runs in between.Around that core, the pipeline assigns clear responsibilities: AWS WAF stops automated abuse at the edge, the pre- and post-generation guards enforce semantic policy in the path, the contextual grounding check controls hallucination for RAG and summarization, Amazon Comprehend completes PII handling across model and non-model paths, and CloudTrail, model invocation logging, and CloudWatch record every decision. Least-privilege IAM separates running the checks from changing them, and guardrail versioning turns policy change into reviewable, reversible change management.
The discipline that makes it usable is tuning against a labeled evaluation set and treating over-blocking, under-blocking, grounding misjudgments, PII leakage, and throttling as expected failure modes with known triage paths — while never reading a passing check as proof of safety. Built this way, the safety layer is portable across models, observable in production, and auditable after the fact, which is exactly what responsible AI in production requires.
11. References
- Amazon Bedrock Guardrails - Developer Guide
- Use the ApplyGuardrail API in your application
- Use contextual grounding check to filter hallucinations in responses
- GuardrailContextualGroundingFilter - Amazon Bedrock API Reference
- Block harmful images with content filters
- Monitor model invocation using CloudWatch Logs and Amazon S3
- Personally identifiable information (PII) - Amazon Comprehend Developer Guide
- Trust and safety - Amazon Comprehend
- AWS Generative AI Security Reference Architecture - Securing AI applications (AWS WAF)
- Amazon Bedrock Security and Compliance
- Tailor responsible AI with new safeguard tiers in Amazon Bedrock Guardrails
- Use the ApplyGuardrail API with long-context inputs and streaming outputs in Amazon Bedrock
- Amazon Bedrock Pricing
- AWS WAF for Generative AI - Prompt Injection Defense Implementation Patterns
- AI Agent Defense in Depth Model (AIDDM) - WAF, Guardrails, Reasoning Sandbox, and Output Filter
- MCP Tool Poisoning Defense Guide - Client-Side Defense in Depth for AI Agents
- Agentic RAG Architecture on Amazon Bedrock
- Multi-Tenant Generative AI SaaS Architecture on AWS
References:
Tech Blog with curated related content
Written by Hidekazu Konishi