Multi-Tenant Generative AI SaaS Architecture on AWS - Tenant Isolation, Per-Tenant Knowledge Bases, and Guardrails with ABAC
First Published:
Last Updated:
This article is a Level 400 implementation walkthrough of one named reference architecture — a Tenant-Isolated Generative AI SaaS on AWS — that makes cross-tenant access structurally hard rather than merely configured away. The backbone is Amazon Cognito for tenant identity, Amazon API Gateway and AWS Lambda for the request path, AWS Security Token Service (AWS STS) session tags with attribute-based access control (ABAC) for scoped runtime credentials, Amazon Bedrock with per-tenant Amazon Bedrock Knowledge Bases and per-tenant Amazon Bedrock Guardrails for the AI tier, Amazon DynamoDB and AWS KMS for the data tier, and Amazon CloudWatch embedded metric format (EMF) for per-tenant usage metering. The generic SaaS isolation mechanics — the pool/silo/bridge models, Cognito tenant context, and DynamoDB fine-grained access control — are covered in depth in my existing AWS SaaS Multi-Tenant Architecture Guide, so here I keep them compact and concentrate on what is specific to the AI tier: isolating knowledge bases and guardrails, and binding the whole pipeline to one tenant-scoped session.
A note on scope and honesty: this is a security-adjacent topic, so I am deliberate about what each control actually guarantees. Passing a configuration check is not the same as being isolated. Throughout, I separate hard boundaries that IAM, KMS, and per-resource policies enforce on the AWS side from application-enforced boundaries that depend on your code setting the right value on every call. I do not include attack payloads, prompt-injection strings, or real secrets. The deep treatment of guardrail policy itself is delegated to my Responsible-AI Guardrails Architecture on AWS article (No.06 in this series). For pricing, always consult the official AWS pricing pages; this article never quotes cost figures and frames metering purely as a usage signal.
1. Introduction: Cross-Tenant Isolation Is the Architecture
In a single-tenant deployment, isolation is trivial: there is only one tenant, so any data the application can reach belongs to that tenant. The moment you serve many tenants from shared infrastructure, isolation stops being implicit and becomes the central design problem. Every shared component — a vector index, a model invocation role, a DynamoDB table, a KMS key, a log group — is now a place where tenant boundaries can blur.Generative AI raises the stakes in three ways. First, the system actively retrieves and synthesizes data: a retrieval-augmented generation (RAG) pipeline pulls documents into the model's context and the model writes them into the answer, so a retrieval that crosses a tenant boundary surfaces directly to the user as text. Second, the boundary is semantic, not just structural: even if rows are isolated, a shared vector store can return a neighbor's chunk if the query filter is wrong. Third, the controls are new and fast-moving — knowledge bases, guardrails, reranking, and agent runtimes each have their own isolation knobs, and they must be wired together correctly for the boundary to hold end to end.
The thesis of this article is that tenant isolation should be structural: derived from a verified identity, carried as a tagged session, and enforced by AWS authorization at each tier — not reconstructed by hand in every handler. Where a hard boundary is not available (most notably a shared "pool" knowledge base, where the per-tenant filter is set by your code), you should know it, treat it as a logical boundary, and compensate with defense in depth and continuous verification. The rest of the article builds that architecture component by component, traces a single tenant request end to end, and then examines how isolation fails and how you detect it.
For readers who want the externalized, fine-grained application-level authorization layer (which user within a tenant may invoke which feature), that concern is complementary and is covered in my AWS Verified Permissions and Cedar Complete Guide; this article focuses on the tenant boundary rather than the user-within-tenant boundary. For Amazon Bedrock terminology used throughout, see my Amazon Bedrock Glossary.
2. The Reference Architecture at a Glance
The reference architecture has two planes, following the vocabulary of the AWS Well-Architected SaaS Lens and the SaaS Architecture Fundamentals whitepaper: a control plane and an application plane.The control plane is global and is not itself multi-tenant. It onboards tenants, provisions their isolated resources, and operates the fleet. When a tenant is onboarded, the control plane creates (or assigns) that tenant's knowledge-base namespace or dedicated knowledge base, its guardrail, its KMS key material, its Cognito attributes, and a record in a tenant configuration table that maps a tenant to its concrete resource identifiers and tier.
The application plane is where multi-tenant request handling lives. A single tenant request flows along this path:
Amazon Cognito (authentication, tenant claim)
-> Amazon API Gateway (Cognito authorizer validates JWT)
-> AWS Lambda (reads tenant_id from verified claims)
-> AWS STS AssumeRole + session tags (tenant-scoped credentials, ABAC)
-> Amazon Bedrock InvokeModel / Converse (tenant guardrail)
-> Amazon Bedrock Knowledge Bases Retrieve (silo KB ARN | pool metadata filter)
-> Amazon DynamoDB (LeadingKeys scoped to ${aws:PrincipalTag/tenant})
-> AWS KMS (per-tenant CMK / encryption context)
-> Amazon CloudWatch EMF (per-tenant usage metrics)aws:PrincipalTag/tenant rather than reconstructed by the application.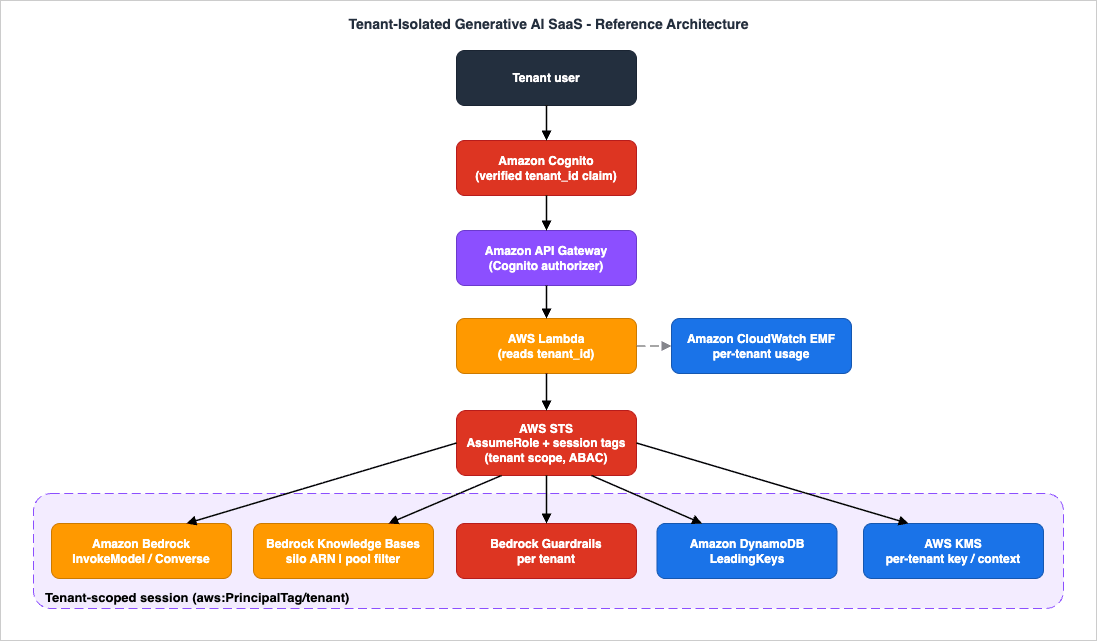
* You can sort the table by clicking on the column name.
| Tier | Service | Isolation job | Enforcement |
|---|---|---|---|
| Identity | Amazon Cognito | Authenticate the user; carry a non-mutable tenant_id claim | Token signature + claim source (control plane) |
| Edge | Amazon API Gateway | Reject unauthenticated calls; per-tenant throttling | Cognito authorizer; usage plans |
| Compute | AWS Lambda | Read tenant_id; assume a tenant-scoped session | Application logic (fail-closed if untagged) |
| Runtime identity | AWS STS session tags / ABAC | Stamp the session with tenant; gate downstream by tag | IAM (hard boundary) |
| AI generation | Amazon Bedrock (InvokeModel / Converse) | Invoke a model with the tenant's guardrail | IAM on guardrail/model ARNs + app selects guardrail |
| AI retrieval | Amazon Bedrock Knowledge Bases | Return only the tenant's chunks | Silo: IAM on KB ARN (hard) / Pool: metadata filter (app-enforced) |
| Data | Amazon DynamoDB | Read/write only the tenant's items | IAM dynamodb:LeadingKeys (hard boundary) |
| Encryption | AWS KMS | Decrypt only with the tenant's key/context | Key policy + grants (hard boundary) |
| Telemetry | Amazon CloudWatch EMF | Attribute usage to the tenant without leaking PII | Application logging (dimension hygiene) |
3. Pool, Silo, and Bridge Models for the AI Tier
The pool/silo/bridge taxonomy is the standard SaaS isolation vocabulary, and the generic mechanics are fully covered in my AWS SaaS Multi-Tenant Architecture Guide. Here I apply it specifically to the AI tier, where the trade-offs differ from a plain web/database stack.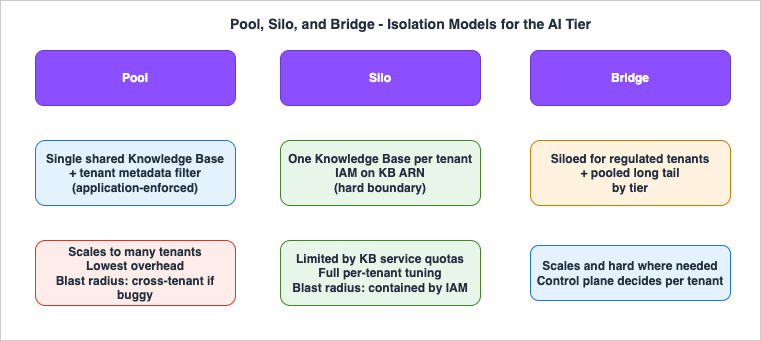
- Pool — A single, shared Amazon Bedrock knowledge base holds every tenant's documents, separated by a
tenantmetadata attribute on each chunk, and everyRetrievecall passes a filter on that attribute. One vector index, one set of resources, lowest operational overhead, scales to many tenants. The isolation is logical and application-enforced: AWS does not know that a missing filter is a bug. As AWS Prescriptive Guidance notes in its Security Reference Architecture for generative AI, "It's up to the application or agent to add the correct metadata to each API call." - Silo — Each tenant gets a dedicated knowledge base (and typically its own data-source bucket prefix and vector index). Isolation is a hard boundary: you scope
bedrock:Retrieveto that tenant's knowledge-base ARN, so a wrong tenant cannot retrieve even if application code is buggy. The cost is operational: more resources to provision and operate, and you must stay within account-level service quotas for the number of knowledge bases (check the Service Quotas console — these are adjustable but finite, which is exactly why pure-silo does not scale to very large tenant counts). - Bridge — A pragmatic hybrid. Large or regulated tenants are siloed (dedicated knowledge base, dedicated key); the long tail of small tenants share a pooled knowledge base with metadata filtering. The control plane decides, per tenant, which model applies, based on the
tierrecorded in tenant configuration.
* You can sort the table by clicking on the column name.
| Dimension | Pool | Silo | Bridge |
|---|---|---|---|
| Knowledge base | One shared KB | One KB per tenant | Mixed by tier |
| AI-tier isolation | Metadata filter (app-enforced) | KB ARN in IAM (hard) | Per tenant |
| Scales to many tenants | Strong | Limited by quotas | Strong |
| Blast radius of a code bug | Cross-tenant retrieval possible | Contained by IAM | Contained for siloed tenants |
| Per-tenant tuning (chunking, model) | Limited | Full | Full for siloed |
| Operational overhead | Lowest | Highest | Moderate |
There is no universally correct choice. The decision rule I use: start pooled for speed and scale, silo the tenants whose data classification or contractual terms demand a hard boundary, and — regardless of model — treat the data tier (DynamoDB, S3, KMS) as ABAC-enforced so the non-AI boundary is always hard. The next three sections build exactly that.
4. Tenant Identity and Scoped Sessions
This is the keystone. Everything downstream depends on a session that reliably carries the tenant identity in a way AWS can authorize against.4.1 Establishing tenant context in Amazon Cognito
The tenant identity must originate from a source the user cannot tamper with. With an Amazon Cognito user pool, the common pattern is a custom attribute such ascustom:tenant_id, populated at onboarding by the control plane (via AdminCreateUser / AdminUpdateUserAttributes) and surfaced in the ID token. Cognito custom attributes must be declared at user-pool creation time (there is a fixed maximum number of custom attributes per pool), and tenant attributes should be relatively static identity data, not a general-purpose store.The critical rule, stated plainly in the Cognito documentation on attributes for access control, is that a user-mutable attribute must not be a security boundary: "An attribute that a user can change through
UpdateUserAttributes should not serve as a security boundary in your IAM policies." To make tenant_id trustworthy, do one or more of the following:- Declare the attribute as
Mutable: falsein the user-pool schema. - Remove the attribute from the app client's
WriteAttributesso the client cannot change it. - Normalize or override the claim in a pre token generation Lambda trigger from a trusted source, rather than trusting whatever the client supplies.
A pre token generation trigger is also the clean place to map external identity-provider groups onto your internal tenant model and to keep the token compact:
# Cognito pre token generation Lambda: stamp a trusted tenant_id claim.
# tenant_id is resolved from a control-plane source, never from user input.
def handler(event, context):
user_name = event["userName"]
tenant_id = resolve_tenant_from_directory(user_name) # control-plane lookup
event["response"]["claimsOverrideDetails"] = {
"claimsToAddOrOverride": {
"tenant_id": tenant_id,
"tier": resolve_tier(tenant_id),
}
}
return event
tenant_id from the verified claims in the request context — never from a request body or header that a client can forge.4.2 From claim to session tag: two paths
There are two well-supported ways to convert the verified tenant claim into a tenant-tagged set of temporary credentials.Path A — Application-tier AssumeRole with session tags (used as the primary path here). The Lambda function calls
sts:AssumeRole and passes the tenant as a session tag. The returned credentials are a tagged IAM principal, and the tag is readable in IAM policies as aws:PrincipalTag/tenant.import boto3
sts = boto3.client("sts")
def tenant_scoped_session(tenant_id: str, tier: str) -> boto3.Session:
resp = sts.assume_role(
RoleArn=TENANT_RUNTIME_ROLE_ARN,
RoleSessionName=f"tenant-{tenant_id}",
Tags=[
{"Key": "tenant", "Value": tenant_id},
{"Key": "tier", "Value": tier},
],
TransitiveTagKeys=["tenant"], # tag survives any further role chaining
DurationSeconds=900,
)
c = resp["Credentials"]
return boto3.Session(
aws_access_key_id=c["AccessKeyId"],
aws_secret_access_key=c["SecretAccessKey"],
aws_session_token=c["SessionToken"],
)
sts:TagSession. The trust policy of the runtime role must allow the application's execution role both to assume the role and to tag the session:{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": { "AWS": "arn:aws:iam::ACCOUNT:role/app-execution-role" },
"Action": ["sts:AssumeRole", "sts:TagSession"],
"Condition": {
"StringLike": { "aws:RequestTag/tenant": "*" },
"ForAllValues:StringEquals": { "aws:TagKeys": ["tenant", "tier"] }
}
}
]
}
sts:AssumeRoleWithWebIdentity and sts:TagSession to the cognito-identity.amazonaws.com principal. This path moves the tagging into the identity layer and is convenient when the client talks to AWS services directly; Path A keeps the exchange inside your backend, which is the better fit for an API-Gateway-fronted Lambda design and is what the rest of this article assumes.4.3 ABAC: one policy, every tenant
The point of session tags is that a single permission policy on the runtime role serves all tenants, because the policy compares resource attributes against the caller's tag instead of naming each tenant explicitly. This is attribute-based access control. The downstream sections show concrete ABAC statements for DynamoDB and KMS. The two ABAC properties to keep in mind:- Fail-closed on a missing tag. If the session is somehow not tagged (a code path that forgot
TagSession),${aws:PrincipalTag/tenant}resolves to nothing and tag-conditioned statements simply do not match — access is denied rather than silently granted. Design for this: never give the runtime role a broad fallback statement that grants access without the tag condition. - The tag is only as trustworthy as its source. ABAC is exactly as strong as the guarantee that the
tenanttag reflects the authenticated tenant. That is why §4.1 insists the claim be non-mutable and stamped from a trusted source. ABAC does not rescue a forgeable tenant claim.
5. Isolating the AI Tier: Per-Tenant Knowledge Bases and Guardrails
This is the section that distinguishes a generative AI SaaS from a generic one. Two AI-tier resources carry tenant data and tenant policy: the knowledge base (retrieval) and the guardrail (safety). Each needs a tenant-isolation strategy.5.1 Per-tenant knowledge bases — silo vs pool
Silo: a dedicated knowledge base per tenant (hard boundary). Amazon Bedrock supports resource-level IAM permissions on knowledge bases. You scopebedrock:Retrieve (and bedrock:GetKnowledgeBase) to a specific knowledge-base ARN:{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "RetrieveTenantKB",
"Effect": "Allow",
"Action": ["bedrock:Retrieve", "bedrock:GetKnowledgeBase"],
"Resource": "arn:aws:bedrock:REGION:ACCOUNT:knowledge-base/TENANT_KB_ID"
}
]
}
- Per-tenant runtime role (strongest, simplest to reason about). The control plane provisions one role per tenant, each granting
bedrock:Retrieveonly on that tenant's knowledge-base ARN. The application selects the role from tenant configuration and constrains who may assume it with a trust-policy condition onaws:PrincipalTag/tenant. A buggy retrieve call cannot reach another tenant's knowledge base because the credentials lack the permission. - Resource-tag ABAC on the knowledge base. Tag each knowledge base with its
tenantand conditionbedrock:Retrieveonaws:ResourceTag/tenantequaling${aws:PrincipalTag/tenant}, so one shared role serves all siloed tenants. Confirmaws:ResourceTagcondition-key support forbedrock:Retrievein the Amazon Bedrock entry of the Service Authorization Reference before relying on this pattern; if it is not supported for the action, fall back to pattern 1.
Pool: one knowledge base, metadata filtering (logical boundary). Ingest every tenant's documents into a single knowledge base, attach a
tenant metadata attribute to each chunk (a metadata file accompanies each document, up to a fixed small size limit, and a clean S3 prefix-per-tenant layout keeps it organized), and pass a RetrievalFilter on every call:agent_rt = session.client("bedrock-agent-runtime") # tenant-scoped session
resp = agent_rt.retrieve(
knowledgeBaseId=POOL_KB_ID,
retrievalQuery={"text": user_question},
retrievalConfiguration={
"vectorSearchConfiguration": {
"numberOfResults": 5,
"filter": {"equals": {"key": "tenant", "value": tenant_id}},
}
},
)
RetrievalFilter is a union type — exactly one operator per node (equals, in, andAll, orAll, and the comparison operators) — and it is honored by both Retrieve and RetrieveAndGenerate. You can compose tenant scoping with data classification, for example andAll of equals tenant and in classification ["public","internal"].The pool pattern is powerful and scalable, but be precise about what it guarantees. The filter value is supplied by your code on every call. AWS enforces that the filter is applied; it does not enforce that the value is correct for the caller. If a handler omits the filter, hardcodes the wrong tenant, or builds it from an untrusted input, the shared index can return another tenant's chunks. So a pool knowledge base is a logical boundary that must be backed by:
- Derive the filter from the session, never the request. Build
tenant_idfrom the verified claim that produced the session tag, so the retrieval filter and the IAM session agree by construction. - Post-retrieval assertion. After
Retrieve, assert that every returned source'stenantmetadata equals the session's tenant; emit a metric and fail the request if not (see §9). - Defense in depth. Keep the data tier (DynamoDB, S3, KMS) ABAC-enforced so a retrieval bug cannot also become a write or decrypt across tenants.
If your retrieval pipeline also reranks results, the service role needs
bedrock:Rerank and bedrock:InvokeModel for the rerank model; the per-tenant scoping still happens at the Retrieve filter or the knowledge-base ARN, upstream of the rerank.5.2 Per-tenant guardrails
Amazon Bedrock Guardrails let you screen prompts and responses for denied topics, sensitive information, contextual grounding, and prompt attacks. The deep treatment of what to put in a guardrail is in my Responsible-AI Guardrails Architecture on AWS (No.06). Here the concern is narrow: how a guardrail is assigned per tenant.A guardrail is a versioned resource identified by
guardrailIdentifier + guardrailVersion. There are two ways to apply it:- Inline on the model call.
InvokeModelandConverseaccept aguardrailIdentifier(and version). If you do not provide one, no guardrail is applied. The application looks up the tenant's guardrail from tenant configuration and passes it on every invocation:
bedrock_rt = session.client("bedrock-runtime") # tenant-scoped session
resp = bedrock_rt.converse(
modelId=tenant_cfg["model_id"], # tenant-/tier-specific
messages=[{"role": "user", "content": [{"text": user_question}]}],
guardrailConfig={
"guardrailIdentifier": tenant_cfg["guardrail_id"],
"guardrailVersion": tenant_cfg["guardrail_version"],
},
)
- Independently with
ApplyGuardrail. You can evaluate content against a guardrail without invoking a model, which is useful for screening retrieved context before it enters the prompt, or for screening tool outputs in an agent loop.ApplyGuardrailtakes theguardrailIdentifier/guardrailVersionin the request path and returns a pass/fail outcome.
You can also add an IAM hard boundary on top of the application's selection: scope
bedrock:ApplyGuardrail (and the guardrail used by InvokeModel) to the tenant's guardrail ARN under the same per-tenant-role or resource-tag pattern as the knowledge base, so a misconfigured request cannot apply another tenant's guardrail.Two honesty notes that this series treats as non-negotiable for safety topics. First, assigning a guardrail is a control-plane and application concern; if your code forgets to pass
guardrailConfig, no guardrail runs — there is no implicit default. Second, a request that passes a guardrail is not proven safe; a guardrail reduces risk for the categories it is configured to detect, and "the guardrail intervened" is a useful signal, not a safety guarantee. Treat guardrail outcomes as inputs to monitoring (§9), and keep the detailed policy design in No.06.5.3 Conversation memory and per-tenant prompt context
Conversation history is tenant data too. If you persist turns to feed the next request, that store must be tenant-isolated exactly like any other data — which in this architecture means DynamoDB withLeadingKeys ABAC (§6). The same applies to any per-tenant system prompt, few-shot examples, or retrieved context cached between turns: cache keys must include the tenant, and a cache lookup must be scoped by the session tenant so one tenant never reads another's cached context. The point is that "memory" is not a special exception to isolation; it is data, and it rides the same boundaries.6. Data-Tier Isolation with ABAC
The AI tier sits on top of a data tier — conversation state, tenant configuration, document metadata, and the encryption keys protecting them. Unlike the pooled knowledge base, the data tier can be a hard boundary in the pool model, because DynamoDB and KMS both support fine-grained, attribute-conditioned IAM. This is where the tenant session tag pays off most cleanly.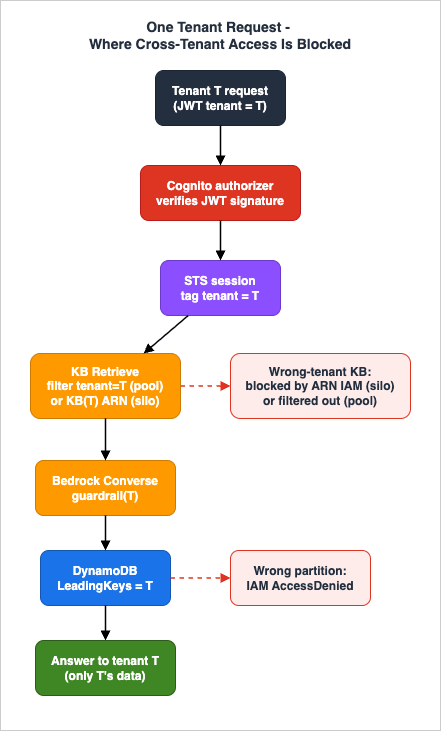
6.1 DynamoDB fine-grained access control with LeadingKeys
DynamoDB'sdynamodb:LeadingKeys condition key restricts a principal to items whose partition key matches a value — the canonical pooled-table SaaS pattern. Model the table so the partition key is (or is prefixed by) the tenant identifier, then condition the runtime role's policy on the session tag:{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "TenantScopedItems",
"Effect": "Allow",
"Action": [
"dynamodb:GetItem", "dynamodb:Query",
"dynamodb:PutItem", "dynamodb:UpdateItem", "dynamodb:DeleteItem",
"dynamodb:BatchGetItem", "dynamodb:BatchWriteItem"
],
"Resource": "arn:aws:dynamodb:REGION:ACCOUNT:table/ConversationStore",
"Condition": {
"ForAllValues:StringEquals": {
"dynamodb:LeadingKeys": ["${aws:PrincipalTag/tenant}"]
}
}
}
]
}
dynamodb:LeadingKeys represents the partition key (the name is plural and requires the ForAllValues set-operator modifier), so a Query or GetItem for a partition that does not equal the session's tenant is denied by IAM — not by application code. The application does not have to remember to add a tenant predicate; even if it issues a query for the wrong partition, the request fails. That is the difference between a hard boundary and a logical one. You can extend this with dynamodb:Attributes and dynamodb:Select to restrict which item attributes a principal may read or write, hiding sensitive columns within an otherwise readable item. The full generic treatment, including key design and global secondary index considerations, is in the AWS SaaS Multi-Tenant Architecture Guide.6.2 Encryption boundaries with AWS KMS
Encryption gives you a second, independent hard boundary. Two patterns, often combined:- Per-tenant customer managed key (CMK). Siloed or higher-tier tenants get a dedicated KMS key. The key policy (and grants) restrict decryption to principals carrying the matching tenant tag, so even a principal that somehow reached the ciphertext cannot decrypt it without the right session. Scope KMS use to Bedrock with a
kms:ViaServicecondition (for examplebedrock.REGION.amazonaws.com) so the key is usable only through the intended service path. - Shared key with per-tenant encryption context. Pooled tenants can share a key while binding each object's ciphertext to its tenant through the KMS encryption context (an additional authenticated data set, e.g.
{"tenant": tenant_id}). A decrypt request must present the same context, and you can condition grants onkms:EncryptionContext:tenantmatching the session tag, so a decrypt for the wrong tenant context fails.
The encryption boundary is valuable precisely because it is independent of the application: it holds even if an IAM statement is mis-scoped, as long as the key policy is correct. Defense in depth means a single mistake should not collapse every boundary at once.
7. Usage Metering (Not Cost)
A multi-tenant AI service has to attribute usage to tenants — to enforce per-tenant limits, to spot a runaway tenant, and to feed downstream billing systems. This section is about producing the usage signal. It is explicitly not about cost: I do not translate usage into money here, and I quote no prices. Cost modeling belongs in your billing system and the official AWS pricing pages; conflating metering with pricing in an architecture article ages badly and is out of scope by site policy.The clean, low-overhead way to emit per-tenant usage from Lambda is the CloudWatch embedded metric format (EMF). You write a single structured log line; CloudWatch extracts the embedded values as custom metrics asynchronously, and the same line remains queryable in CloudWatch Logs Insights for root-cause analysis. No separate
PutMetricData call is needed — generating metrics from EMF requires only the logs:PutLogEvents permission.{
"_aws": {
"Timestamp": 1700000000000,
"CloudWatchMetrics": [
{
"Namespace": "GenAISaaS/Usage",
"Dimensions": [["TenantId", "Operation"]],
"Metrics": [
{ "Name": "InputTokens", "Unit": "Count" },
{ "Name": "OutputTokens", "Unit": "Count" },
{ "Name": "Retrievals", "Unit": "Count" },
{ "Name": "Invocations", "Unit": "Count" }
]
}
]
},
"TenantId": "tenant-7f3a",
"Operation": "RetrieveAndGenerate",
"InputTokens": 1842,
"OutputTokens": 503,
"Retrievals": 5,
"Invocations": 1,
"request_id": "a1b2c3d4-...."
}
TenantId is a bounded dimension — its cardinality is your tenant count — so it is appropriate. Keep unbounded identifiers (request_id, message IDs) as ordinary log properties, not dimensions, so they remain searchable in Logs Insights without minting a metric per value. This keeps per-tenant dashboards and alarms cheap to operate while preserving full-fidelity logs.The token counts themselves come from the Amazon Bedrock response usage fields, so you are metering what the model actually consumed rather than estimating. Aggregate these metrics into per-tenant dashboards and feed the same signal into the noisy-neighbor controls in the next section.
8. Cross-Cutting: Noisy Neighbor, Least Privilege, and Policy
Three cross-cutting concerns determine whether the architecture is operable, not just isolated.Noisy neighbor. Tenant isolation of data does not automatically isolate capacity. One tenant can saturate shared throughput and degrade everyone. The AI tier has its own scarce resources — Amazon Bedrock model throughput (tokens per minute / requests per minute, optionally raised with provisioned throughput), the knowledge base's vector store capacity, and Lambda concurrency. Controls to keep one tenant from starving the rest:
- Edge throttling per tenant. API Gateway usage plans and API keys (or a per-tenant token-bucket in the authorizer/Lambda) cap request rates per tenant before work begins.
- Concurrency partitioning. Reserved or provisioned concurrency for the AI Lambda functions, and per-tenant in-flight limits, prevent one tenant from consuming the whole pool.
- Application-level token budgets. Enforce a per-tenant ceiling on tokens or retrievals per window, using the very EMF metrics from §7 as the live counter.
- Tier-aware routing. The
tiersession tag lets premium tenants route to higher throughput (or provisioned capacity) while the shared tier rides on-demand.
Least privilege. The runtime role should grant only the actions the request path needs, every privileged action should carry the tenant tag condition, and there should be no statement that grants data access without the tag condition (so the architecture is fail-closed). Use IAM Access Analyzer and policy unit tests to catch a statement that is broader than intended — an over-broad role is the most common way a "configured" isolation quietly becomes no isolation.
Per-tenant policy. Different tenants may need different guardrails, different model tiers, different data-retention rules. Drive these from the tenant configuration record rather than from code branches, so onboarding a tenant with a stricter policy is data, not a deploy. The guardrail policy specifics are delegated to No.06; the binding of a policy to a tenant is the control-plane job described in §10's onboarding flow.
9. Observability and Failure Modes
Because several boundaries here are configuration-shaped, you must be able to see a boundary failing. This section catalogs the failure modes specific to a multi-tenant AI SaaS and how to diagnose them. The overarching principle: do not assume that because a configuration check passed, isolation holds — verify the boundary continuously with signals.Cross-tenant retrieval (pool model). Symptom: an answer cites a document the tenant does not own. Root cause: a missing or wrong
RetrievalFilter, or a filter built from untrusted input. Diagnosis and guard: tag every retrieved source with its tenant metadata, and after each Retrieve assert that all sources match the session tenant; emit a CrossTenantRetrievalBlocked metric and fail closed on mismatch. Alarm on any nonzero value — it should always be zero, so a single occurrence is a real defect, not noise.Isolation misconfiguration (session not tagged / role too broad). Two sub-cases with opposite signatures. If the session is not tagged, ABAC denies everything and the tenant sees broad
AccessDenied errors — loud and fail-closed, easy to catch in canaries. If the role is too broad (a fallback statement without the tag condition), access succeeds where it should not — silent and fail-open, the dangerous case. Diagnosis: IAM Access Analyzer findings, policy unit tests that assert a cross-tenant call is denied, and a synthetic canary per tenant that attempts a deliberately wrong-tenant read and expects a denial.Noisy neighbor. Symptom: elevated latency or throttling for many tenants at once. Diagnosis: per-tenant EMF usage metrics (§7) plus Bedrock and Lambda throttling metrics; correlate a spike in one tenant's
Invocations/InputTokens with rising ThrottledRequests for others. Mitigation: the §8 controls.Guardrail over- or under-intervention. Symptom: legitimate tenant requests blocked (over-block) or unwanted content passing (under-block). This is a per-tenant policy and tuning concern; the detail is in No.06. At the architecture level, record guardrail outcomes per tenant as a metric so you can see a tenant whose block rate suddenly changes — and remember that an intervention is a signal, not proof of safety, and a non-intervention is not proof of harmlessness.
Knowledge base sync / ingestion failures. Symptom: a tenant's new documents are not retrievable, or (worse, in a pool model) a document is ingested without its
tenant metadata and becomes filter-invisible-but-present. Diagnosis: monitor data-source ingestion job status per tenant; validate at ingestion time that every document carries a non-empty tenant metadata value, and reject ingestion otherwise so a chunk can never enter the index untagged.For tracing across these tiers, propagate a correlation ID and the tenant through structured logs (as a property, per §7's cardinality rule) so you can reconstruct a single request's path from API Gateway through the scoped session to Bedrock and DynamoDB. If your pipeline is agentic, the broader observability and evaluation concerns — step tracing, LLM-as-judge evaluation, regression — are the subject of the agentic RAG and LLMOps articles in this series; here the focus is the isolation signals.
10. Tenant Onboarding in the Control Plane
Everything above describes the application plane — the per-request path. The control plane is what makes a tenant exist. It is global, operated by you, and is not itself multi-tenant. Onboarding a tenant is a provisioning workflow that creates the tenant's isolated footprint and records how to reach it:- Register the tenant in the tenant configuration table (tenant ID, tier, status).
- Provision the AI tier. For a siloed tenant, create a dedicated knowledge base (and its data-source bucket/prefix and vector index) and a per-tenant runtime role scoped to that knowledge-base ARN; for a pooled tenant, allocate the metadata namespace (S3 prefix +
tenantmetadata convention). Create or assign the tenant's guardrail and record its identifier and version. - Provision encryption. Create a per-tenant CMK (silo/high tier) or register the tenant's encryption context (pool), with key policies/grants conditioned on the tenant tag.
- Seed identity. Ensure the Cognito attribute schema carries
tenant_id(non-mutable), and provision users with the correct tenant value. - Record the binding. Write the concrete resource identifiers (knowledge-base ID, guardrail ID/version, key ID, model/tier) into tenant configuration so the application plane can resolve, per request, exactly which resources this tenant's scoped session may use.
Treat onboarding as infrastructure-as-code so a tenant's isolated resources and their bindings are reproducible and auditable. Offboarding is the mirror image and matters for data-retention obligations: revoke the role, delete or disable the knowledge base/namespace, schedule key deletion, and remove the configuration record.
11. Frequently Asked Questions
Should I start with the pool or the silo model?Start pooled for speed and scale, then silo the tenants whose data classification or contractual terms demand a hard boundary — that hybrid is the bridge model. Regardless of which you pick for the AI tier, keep the data tier (DynamoDB, KMS) ABAC-enforced so the non-AI boundary is always hard.
Is metadata filtering on a shared knowledge base enough to isolate tenants?
It is a logical, application-enforced boundary. AWS enforces that the filter is applied, not that its value is correct for the caller, so a code bug can still cross tenants. Back it with session-derived filters, post-retrieval assertions, and a hard data-tier boundary. A siloed knowledge base scoped by ARN is the hard-boundary alternative.
Can a single IAM role serve every tenant?
Yes for the data tier and pooled retrieval: ABAC with a tenant session tag (
dynamodb:LeadingKeys, KMS encryption context) lets one policy serve all tenants. For a siloed knowledge base bound by ARN, use a per-tenant role or resource-tag ABAC (after confirming condition-key support) because the knowledge-base ID is not the tenant tag.How do I keep the
tenant_id claim trustworthy?Make it non-mutable (declare
Mutable: false or remove it from the app client's WriteAttributes), or override it in a pre token generation Lambda from a trusted source. Never read the tenant from a request header or body the client controls. ABAC is only as strong as the claim behind the tag.Does this article cover guardrail policy design?
No — only how a guardrail is assigned per tenant (selected by tenant configuration and passed on each call, optionally constrained by IAM to the tenant's guardrail ARN). The policy design itself — denied topics, sensitive-information filters, contextual grounding — is in Responsible-AI Guardrails Architecture on AWS. A passed guardrail is a signal, not a safety guarantee.
How do I meter usage without leaking PII or exploding metric counts?
Emit CloudWatch EMF with
TenantId as a bounded dimension and keep high-cardinality identifiers (request IDs, user IDs) as log properties, not dimensions. Take token counts from the Bedrock response usage fields, and keep the signal as usage only — translate to cost in your billing system, never in the application.12. Summary
A multi-tenant generative AI SaaS is, at its core, a tenant-isolation problem with new surfaces. The reference architecture in this article makes the boundary structural by carrying a verified tenant identity from Amazon Cognito into a tenant-tagged AWS STS session, and then letting AWS authorization enforce that tag at every tier:dynamodb:LeadingKeys and KMS at the data tier, knowledge-base ARNs (silo) at the AI tier, and guardrail/model ARNs at the generation step. The result is one ABAC policy that serves every tenant and fails closed when a session is untagged.The single most important distinction to carry away is hard boundary vs application-enforced boundary. The data tier (DynamoDB, KMS) and a siloed knowledge base are hard boundaries that hold even if application code is wrong. A pooled knowledge base's metadata filter is an application-enforced boundary that is powerful and scalable but depends on your code setting the right value on every call — so it must be backed by session-derived filters, post-retrieval assertions, and defense in depth. Usage metering is a bounded-cardinality EMF signal, kept strictly as usage and never conflated with cost. And because several controls are configuration-shaped, isolation must be verified continuously with cross-tenant canaries, post-retrieval assertions, and per-tenant usage and guardrail metrics — never assumed from a passing configuration. Build the boundary into identity and authorization, keep the AI-tier filter honest about what it guarantees, and watch it the whole way down.
13. References
- Amazon Bedrock API Reference - RetrievalFilter (Retrieve / RetrieveAndGenerate)
- Amazon Bedrock API Reference - ApplyGuardrail
- Amazon Bedrock User Guide - How Amazon Bedrock works with IAM
- Amazon Bedrock User Guide - Permissions for Retrieve and RetrieveAndGenerate (knowledge base ARN scoping)
- Amazon Bedrock User Guide - Permissions for reranking
- AWS IAM User Guide - Passing session tags in AWS STS
- AWS IAM User Guide - What is ABAC for AWS?
- Amazon DynamoDB Developer Guide - Using IAM policy conditions for fine-grained access control (dynamodb:LeadingKeys)
- Amazon Cognito Developer Guide - Using attributes for access control
- Amazon Cognito Developer Guide - Pre token generation Lambda trigger
- AWS KMS Developer Guide - Encryption context and key concepts
- Amazon CloudWatch User Guide - Embedding metrics within logs (embedded metric format)
- AWS Whitepaper - SaaS Architecture Fundamentals: Control plane vs. application plane
- AWS Machine Learning Blog - Multi-tenancy in RAG applications in a single Amazon Bedrock knowledge base with metadata filtering
- AWS Prescriptive Guidance - Security Reference Architecture for generative AI (secure data access)
Related Articles on This Site
- AWS SaaS Multi-Tenant Architecture Guide - Tenant Isolation, Pool and Silo Models, Onboarding, and Metering
The generic pool/silo/bridge models, Cognito tenant context, and DynamoDB/KMS isolation mechanics this article delegates to. - AWS Verified Permissions and Cedar Complete Guide
Externalized, fine-grained application-level authorization for which user within a tenant may do what. - Amazon Bedrock Glossary
A reference for the Amazon Bedrock terms used throughout this article. - Responsible-AI Guardrails Architecture on AWS
The detailed guardrail policy design delegated from the AI-tier section. - Agentic RAG Architecture on Amazon Bedrock
The agentic retrieval pipeline this isolation pattern wraps.
References:
Tech Blog with curated related content
Written by Hidekazu Konishi