AI Agent Memory Design Guide - Working, Long-Term, and Procedural Memory with Forgetting and Staleness Management
First Published:
Last Updated:
1. Introduction
When an AI agent behaves unreliably in production, the symptom is usually described in behavioral terms: the agent "forgot" an instruction given ten turns ago, repeated a mistake it had already been corrected on, confidently acted on a fact that stopped being true three months ago, or ran up an enormous context bill re-reading the same documents on every task. Trace these symptoms back far enough and they rarely turn out to be model problems. They are memory design problems — or more precisely, the consequence of having no deliberate memory design at all.Large language models are stateless. Every invocation starts from zero, knows only what is placed in its context window, and forgets everything when the call returns. Everything an agent "remembers" — the current plan, the user's preferences, the lessons of past sessions, the procedures that worked last time — exists only because someone decided to store it somewhere, load it at the right moment, and eventually get rid of it. Each of those three decisions (what to store, when to load, when to forget) is a design decision, and each has failure modes that look like "the agent is unreliable" when they are really "nobody designed the memory."
This guide is the design reference I wished existed when I started building long-running agents. It is a sequel to my Enterprise AI Agent Design Notes series, which covered platform selection and architecture at the cloud-provider level; this article goes one layer deeper into a single cross-cutting concern that every platform shares. It answers three questions:
- What kinds of memory does an agent need, and where should each kind live? — a taxonomy grounded in published research and framework documentation, mapped to concrete storage substrates
- How should forgetting and staleness be designed in from the start? — TTLs, decay, freshness metadata, and staleness detection, treating forgetting as a feature, not a defect
- Where is the boundary between managed memory services and what you must still build yourself? — using Amazon Bedrock AgentCore Memory and the Claude memory tool as concrete reference points
The vocabulary in this article is consistent with my earlier AI Agent Engineering Glossary; where this guide introduces terms the glossary does not yet define (procedural memory, staleness, forgetting policies), it grounds them in the published sources cited in each section rather than inventing new jargon.
Note: This article is a design guide based on the author's synthesis of publicly available research papers, official framework documentation, and official AWS and Anthropic documentation as of June 2026. Service specifications change quickly in this space — always confirm details against the official documentation linked in the References section before building.
2. A Taxonomy of Agent Memory
2.1 Four Memory Types, Grounded in Research
The agent-engineering community has largely converged on a taxonomy borrowed from cognitive science, and it is worth being precise about where it comes from, because the same words are used loosely in vendor marketing. The canonical academic source is the CoALA paper (Cognitive Architectures for Language Agents, by Sumers, Yao, Narasimhan, and Griffiths), which maps the memory modules of classic cognitive architectures onto language agents. CoALA distinguishes one short-lived memory and three long-lived ones:- Working memory — the active information available for the current decision cycle: the task at hand, the running plan, recent observations, intermediate results. In an LLM agent, this is effectively the context window plus any structured scratchpad the agent keeps in front of itself.
- Episodic memory — records of specific past experiences: what happened, when, in which session, with what outcome. The implementation form is session logs, conversation transcripts, and structured "episodes."
- Semantic memory — general facts and knowledge distilled from experience or ingested from outside: "the user prefers Python type hints", "service X deprecated API Y", "our staging environment lives in account Z." The implementation form is extracted fact records, knowledge bases, and retrieval indexes.
- Procedural memory — knowledge of how to do things. CoALA splits this into implicit procedural memory (the skills baked into the LLM's weights) and explicit procedural memory (the agent's own code, prompts, and learned rules). The implementation form for the explicit half is system prompts, playbooks, skills, and validated runbooks.
The cognitive-science lineage behind these distinctions is genuinely standard: the working-memory model is associated with Baddeley, the episodic/semantic split within declarative memory with Tulving, and the declarative/procedural distinction with Squire. The reason this matters for an engineering article is simple: these are not vendor-invented categories. LangChain's LangGraph documentation adopts the same semantic/episodic/procedural classification for long-term memory and explicitly cites CoALA as the source of the mapping. Letta (formerly MemGPT) structures agents around a memory hierarchy of in-context and out-of-context tiers. mem0's State of AI Agent Memory 2026 report organizes the field around episodic, semantic, and procedural memory. A broader academic treatment is the survey by Zhang et al., A Survey on the Memory Mechanism of Large Language Model based Agents. When you design your agent's memory around this taxonomy, you are aligning with the shared vocabulary of the field, which makes your design reviewable and your documentation legible to people who did not build the system.
One honest caveat: not every platform uses these words. Amazon Bedrock AgentCore Memory, for example, speaks of short-term memory (raw event history within a session) and long-term memory (records extracted by strategies) rather than "working memory," and it has no feature it labels "procedural memory" at all. The taxonomy is a design lens, not a product catalog; section 8 maps it onto what managed platforms actually ship.
2.2 Mapping the Taxonomy to Implementation
The table below is the practical core of this section: each memory type, what it corresponds to in a running agent, where it typically lives, and how long it should survive.| Memory type | Cognitive analog | Concrete artifact in an agent | Typical storage substrate | Typical lifetime |
|---|---|---|---|---|
| Working memory | Attention / current focus (Baddeley) | Context window contents: task, plan, recent tool results, scratchpad | The model's context window; optionally a structured state object in the framework | One task or one session; discarded unless explicitly persisted |
| Episodic memory | "What happened" (Tulving) | Conversation transcripts, event logs, structured episodes with outcomes | Append-only event store, session log database, object storage | Days to months; subject to TTL and summarization |
| Semantic memory | "What is known" (Tulving) | Extracted facts, preferences, entity knowledge, document indexes | Vector store, key-value store, knowledge graph, relational tables | Long-lived but individually revisable; subject to staleness checks |
| Procedural memory | "How to do it" (Squire) | System prompt rules, playbooks, skills, validated runbooks, agent code | Version-controlled files, prompt registries, skill repositories | Long-lived and versioned; changed through review, not automatic overwrite |
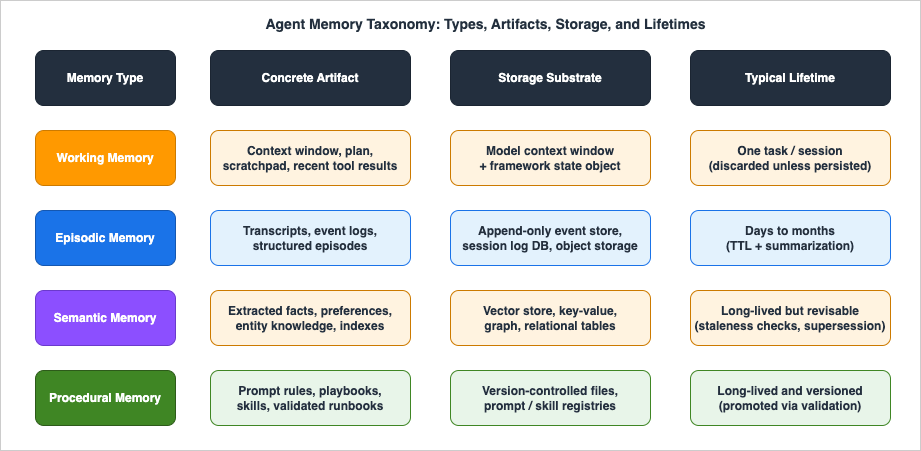
First, the four types have different write paths. Working memory is written implicitly by the act of running. Episodic memory is written automatically by logging. Semantic memory is written by an extraction step (a background process that distills episodes into facts). Procedural memory should be written by a deliberate promotion step with validation — the one write path that should never be fully automatic, for reasons covered in section 5.
Second, they have different forgetting requirements. Working memory must be aggressively pruned within a session. Episodic memory should expire on a TTL. Semantic memory needs staleness management because facts change. Procedural memory needs versioning and deprecation rather than deletion.
Third, conflating adjacent types is the most common design error. Treating the session transcript (episodic) as if it were the agent's knowledge (semantic) produces agents that retrieve noisy, redundant, contradictory context. Treating session state (working) as if it deserved permanence produces memory stores full of half-finished plans. The taxonomy earns its place by forcing each artifact into exactly one row with one lifecycle.
2.3 A Note on "Short-Term" versus "Working" Memory
In framework documentation, "short-term memory" usually means the thread-scoped conversation history — the message list that gets replayed into the context window each turn. "Working memory" in the cognitive sense is slightly narrower: the deliberately maintained planning surface (current goal, running notes, intermediate conclusions). In most implementations they share the same physical buffer, which is why the terms blur. The distinction still pays rent in design: conversation history is something you truncate or summarize, while the planning surface is something you curate — an agent that summarizes away its own current plan fails differently (and more confusingly) than one that summarizes away turn 3 of small talk. When this article says "working memory," it means everything competing for space in the active context window, with the planning surface as its most precious tenant.3. Working Memory: The Context Window as a Scarce Resource
3.1 Why the Largest Context Window Is Still Scarce
Modern frontier models advertise context windows of a million tokens or more, which tempts teams into treating working memory as effectively unlimited. Three forces push back. Attention quality degrades as the window fills — models attend less reliably to information buried in the middle of very long contexts, so retrieval-by-stuffing gets worse precisely when you rely on it most. Cost and latency scale with input size, so an agent that habitually carries hundreds of thousands of tokens of "maybe relevant" context pays for them on every single call. And in long agentic loops, stale intermediate results actively mislead: a tool output from forty turns ago describing the old state of a file is worse than no information once the file has changed.Anthropic's engineering guidance on context engineering for AI agents frames this as treating context as a finite resource with diminishing marginal returns — the practical upshot being that working-memory design is a budgeting problem, not a capacity problem. The budget has roughly four claimants: the instructions and procedural rules (system prompt, tool definitions), the task statement, the live working set (recent turns, recent tool results, the current plan), and just-in-time retrievals from long-term memory. A useful design exercise is to write the budget down explicitly — even a crude allocation like "instructions 10%, working set 50%, retrievals 30%, headroom 10%" — because it converts vague "context bloat" complaints into a measurable engineering target.
3.2 The Three Mechanisms: Summarize, Prune, Retrieve On Demand
Every working-memory scheme in production reduces to three composable mechanisms.Summarization (compaction) replaces older history with a condensed representation. The trade-off is faithfulness: a summary preserves the gist and discards detail that may matter later, so what the summarizer is told to preserve is a design decision, not an implementation detail. Good compaction prompts enumerate what must survive (decisions made, constraints discovered, file paths touched, unresolved questions); bad ones just say "summarize." On the Claude Developer Platform this exists as a server-side compaction feature that automatically summarizes earlier context when a conversation approaches a threshold; Amazon Bedrock AgentCore applies context compaction inside its runtime sessions as well. If you build your own, run compaction before hitting the hard limit, and keep the raw history in episodic storage so the summary is a view, not the only copy.
A compaction instruction worth stealing as a starting point — note that it is a preservation contract, not a length target:
Condense the conversation so far. You MUST preserve, verbatim where short:
- decisions made and their stated reasons
- constraints and requirements discovered (including ones that ruled options out)
- file paths, identifiers, and configuration values that were read or changed
- unresolved questions and known risks
- the current plan and the next intended step
You MAY drop: greetings, retried/failed tool noise, superseded drafts,
and tool outputs whose conclusions are already captured above.Pruning (context editing) removes content wholesale rather than condensing it — typically old tool results, which are bulky, rarely referenced again, and easy to re-fetch. Anthropic ships this as context editing, which clears specified older tool results from the request; the same idea appears in agent frameworks as tool-output truncation. Pruning is cheaper than summarization (no extra model call) and lossless with respect to the conversation's logical structure, which makes it the first lever to pull. Anthropic's published evaluations report that context editing alone produced a meaningful performance lift on long-horizon agent tasks, with memory-tool usage on top improving results further — directionally, "prune the junk, persist the essence" beats both "keep everything" and "summarize everything."
Just-in-time retrieval keeps the working set small by loading long-term memory only when the task needs it, instead of front-loading everything that might be relevant. Identifiers stay in context (file paths, memory keys, record IDs); contents are fetched on demand through tools. This is the same pattern as an OS page table: working memory holds references, and dereferencing is explicit and observable. The agent-visible interface can be as simple as a search tool over the memory store — AgentCore's
RetrieveMemoryRecords semantic search, a vector-store query tool, or a file read against a memory directory.A useful composition rule: prune what can be re-fetched, summarize what cannot, and retrieve rather than carry. An agent that follows all three rarely needs heroic context-window sizes; an agent that follows none will exhaust any window you give it.
3.3 The Scratchpad: Notes the Agent Keeps for Itself
There is a fourth mechanism that deserves separate billing because it crosses the boundary from working memory into persistence: structured note-taking. The agent maintains a small, curated state file — current objective, decisions so far, next steps, open questions — and updates it as it works. Within a session it anchors the plan against compaction (the notes file is always reloaded even when history is summarized). Across sessions it becomes the bootstrap: the next session starts by reading the notes instead of replaying the transcript. Anthropic's guidance on effective harnesses for long-running agents describes exactly this pattern, and its client-side memory tool (tool typememory_20250818) packages it as a tool the model can call to create, read, update, and delete files in a /memories directory that you store on your side. The scratchpad is the simplest possible memory system — files plus discipline — and for a large class of agents it is also sufficient. It is worth exhausting before reaching for infrastructure.4. Long-Term Memory: Choosing a Storage Substrate
4.1 The Decision Is About Retrieval, Not Storage
Long-term memory is state that survives across sessions and is fetched on demand. The storage decision is dominated not by how you write (everything can write JSON somewhere) but by how you need to retrieve: by meaning, by key, by relationship, or by predicate. Each retrieval mode has a natural substrate, and most real agents end up with two or three of them rather than one universal store.| Substrate | Retrieval mode | Strengths | Weaknesses | Natural memory contents |
|---|---|---|---|---|
| Vector store | Semantic similarity ("what do I know about X?") | Fuzzy recall, scales to large corpora, no schema needed | No exact lookups, duplicates accumulate, similarity is not truth | Extracted facts, episode summaries, document chunks |
| Key-value store | Exact key ("preferences for user 123") | Fast, cheap, trivially consistent, easy TTLs | You must know the key; no discovery | User preferences, settings, session state, counters |
| Graph / relational with relationships | Traversal ("what services depend on X?") | Multi-hop questions, explicit relationships, consistency | Higher modeling and maintenance cost | Entity relationships, org structures, dependency maps |
| Relational tables | Structured predicates ("episodes in the last 7 days with outcome=failed") | Filtering, aggregation, auditing, transactional updates | Schema rigidity; poor at fuzzy recall | Episode metadata, audit logs, memory bookkeeping (timestamps, confidence, TTLs) |
| Plain files (versioned) | Path / name ("the deployment playbook") | Human-reviewable, diffable, version-controlled | No query capability beyond naming discipline | Procedural memory: playbooks, skills, prompt rules, agent notes |
Vector storage has become the default substrate for the semantic layer — my glossary entry for vector memory calls it the default substrate for long-term memory in most modern stacks, and that remains accurate — but "default" does not mean "only." The most common substrate mistake is forcing everything through the vector store: preferences that should be key-value lookups get embedded and approximately retrieved (sometimes returning another user's preference as the nearest neighbor), and bookkeeping that should be a relational query ("which memories are older than 90 days?") becomes impossible because similarity search cannot express it. A clean pattern is to store the record once in a system of record (key-value or relational, carrying the metadata from section 6) and index its text in the vector store, so semantic search finds candidates and the system of record answers everything else about them.
On AWS specifically, the substrate menu includes Amazon S3 Vectors for vector indexes at object-storage scale and economics, Amazon OpenSearch Service for richer hybrid search, Amazon DynamoDB for the key-value layer, and Amazon Neptune or relational engines for relationship-heavy memory. Choosing between S3 Vectors and OpenSearch for agent memory workloads is a large enough decision to deserve its own article — see Amazon S3 Vectors Design Decision Guide - When to Use It, When Not to, and Tiered Designs with Amazon OpenSearch Service for that analysis.
4.2 What a Long-Term Memory Record Should Look Like
Whatever the substrate, resist storing bare strings. A memory record that can be managed over time needs an envelope. A minimal shape that has served well:{
"memory_id": "mem_01HXAMPLE",
"type": "semantic",
"namespace": "/users/user-123/preferences",
"content": "Prefers infrastructure changes to be proposed as CDK diffs before applying.",
"source": {
"kind": "extracted",
"session_id": "sess_0142",
"evidence_event_ids": ["evt_889", "evt_891"]
},
"confidence": 0.86,
"written_at": "2026-06-02T09:14:00Z",
"last_confirmed_at": "2026-06-02T09:14:00Z",
"expires_at": null,
"supersedes": "mem_01HOLDER"
}Every field earns its place later in this guide:
namespace enables tenant isolation (section 9), source and confidence make write policies auditable (section 7), written_at / last_confirmed_at / expires_at are the raw material of staleness management (section 6), and supersedes turns "the user changed their mind" into an explicit chain instead of two contradictory records tied in a similarity search. Managed services give you parts of this envelope for free — AgentCore Memory records carry namespaces and timestamps natively — but no platform currently fills in confidence or supersession semantics for you; those remain application-level design.5. Procedural Memory: The Least Mature, Highest-Leverage Layer
5.1 What Procedural Memory Actually Is
Procedural memory is the agent's knowledge of how to do things. CoALA's definition is usefully concrete: language agents carry procedural knowledge in two forms — implicitly in the LLM's weights, and explicitly in the agent's own code and prompts. You cannot (and should not) modify the first form at runtime. The second form is the design surface: the system prompt's rules of engagement, the playbooks and runbooks the agent consults, the skills it can load, and any rules it has learned from experience.In practice, explicit procedural memory shows up in three implementation styles:
- Prompt rules — distilled instructions that live in (or are injected into) the system prompt. LangChain's LangMem treats procedural memory exactly this way: the agent's own prompt rules are updated over time based on feedback, so the agent's "habits" improve without touching code.
- Playbooks / runbooks — named, structured procedures stored as documents and retrieved when a matching situation arises ("how we roll back a deployment", "how to triage a failed pipeline"). The agent reads the playbook into working memory at execution time.
- Skills — packaged procedures with progressive disclosure: a short description always visible, full instructions loaded on demand. Anthropic's Agent Skills implement this as folders with a SKILL definition whose body loads only when relevant, which is procedural memory with built-in working-memory hygiene.
It is worth noting honestly that the managed platforms have not productized this layer under this name. Amazon Bedrock AgentCore Memory has built-in strategies for preferences, facts, summaries, and episodes, but nothing labeled procedural; the closest functional neighbor is the episodic strategy's reflection capability, which consolidates lessons across episodes — useful raw material for procedures, but not a managed procedure store. mem0's State of AI Agent Memory 2026 report, surveying the ecosystem, describes the tooling for managing procedural memory specifically as "still early-stage." In my assessment — and this is an editorial judgment, not a claim from any vendor report — that immaturity is exactly why procedural memory is the highest-leverage layer to design deliberately: it is where an agent's performance compounds, and where the ecosystem gives you the least off-the-shelf help.
5.2 Why Procedural Memory Compounds
Semantic memory makes an agent informed; procedural memory makes it better at its job. A fact retrieved at the right moment saves a lookup. A validated procedure retrieved at the right moment saves the entire trial-and-error trajectory that produced it — every wrong turn, every failed tool call, every burned token. Teams see this concretely: the second time an agent performs a task with a playbook distilled from the first time, the trace is shorter, cheaper, and more reliable. Procedural memory is also the layer that transfers across users and sessions most cleanly. A user preference belongs to one user; a hard-won procedure for "how to safely modify the shared CI config" benefits every future session of every user. That transferability is what makes the layer compound — and also what makes it dangerous, which is why the write path needs a gate.5.3 Promotion with Validation: The One Write Path That Must Not Be Automatic
The central design rule of this section: an unvalidated procedure must never be automatically promoted into permanent procedural memory. A bad fact in semantic memory misleads one retrieval; a bad procedure in procedural memory misleads every future execution of that task class, with the agent's full confidence behind it. The failure mode is well known from human runbooks — someone documents a workaround that happened to work once, and it calcifies into "the way we do it" — except an agent will follow the bad runbook tirelessly and at scale.A promotion pipeline that has the right safety properties looks like this:
1. Candidate capture - during/after a session, the agent (or an extraction
pass over episodes) drafts a candidate procedure
2. Evidence attachment - the candidate links to the episodes that motivated it
(session IDs, outcomes, tool traces)
3. Validation gate - at least one of:
a) replay: the procedure is executed in a sandbox
or staging environment and succeeds
b) repetition: the same procedure independently
succeeded in N separate episodes
c) review: a human approves the diff
4. Versioned write - the procedure lands in version control / a prompt
registry with provenance metadata, never by in-place
mutation of the live prompt
5. Scoped rollout - new procedures apply to low-risk task classes first;
regressions trigger rollback to the prior versionNote what this pipeline implies about storage: procedural memory wants to live in version-controlled, diffable, human-reviewable form — files in a repository, not rows in a vector store. The retrieval problem for procedures is mild (there are usually tens to hundreds of them, addressable by name and short description), while the governance problem is severe (you need diffs, reviews, rollbacks, and audit). Choose the substrate for the hard problem, not the easy one.
A practical starting point that avoids over-engineering: keep candidate procedures in a
candidates/ area written freely by the agent, and promote to the live playbooks/ area only through the validation gate. The agent can be told, in its system prompt, that candidates are suggestions and playbooks are law. This two-tier structure costs almost nothing and prevents the single worst outcome — silent self-modification of the agent's own operating rules.5.4 What a Playbook Record Looks Like
The format matters less than the metadata, but a concrete shape removes ambiguity. A playbook that supports retrieval, validation, and rollback carries a short always-loadable header and a body loaded on demand:# playbooks/rollback_failed_deployment.yaml
name: rollback_failed_deployment
description: >
Roll back a failed deployment of an internal service to the last
healthy version. Use when post-deploy health checks fail twice.
applies_to: ["deployment", "incident-response"]
version: 3
status: active # candidate | active | deprecated
provenance:
promoted_from: ["sess_0091", "sess_0117"] # episodes that motivated it
validated_by: "replay" # replay | repetition | review
approved_by: "platform-team"
preconditions:
- "Previous version artifact still exists in the registry"
- "No schema migration ran as part of the failed deploy"
steps:
- "Freeze the pipeline for the affected service"
- "Re-deploy the previous artifact version"
- "Re-run health checks; confirm two consecutive passes"
- "Record the incident episode with outcome and root-cause notes"
escalation: "If a migration ran, stop and page a human - do not roll back data."Only
name, description, and applies_to need to sit in the agent's standing context (the progressive-disclosure trick that skills formalize); the body is fetched when the situation matches. The status field and provenance block are what make section 5.3's pipeline real: a candidate cannot masquerade as law, and every active procedure can answer "why do we do it this way?" with episode references rather than folklore.6. Forgetting by Design: TTL, Decay, and Staleness Management
6.1 Forgetting Is a Feature
Naive intuition says an agent that remembers more is better. Operating experience says otherwise: an agent that never forgets accumulates contradictions (the user's old preference and new preference are both "remembered"), retrieves noise (the one-off detail from March outranks the durable rule from January because it is more recent or more similar), and acts on dead facts (the endpoint that moved, the colleague who changed teams, the API that deprecated). mem0's State of AI Agent Memory 2026 report lists memory staleness among the open problems of the field, alongside issues like treating change as replacement rather than evolution across sessions — which is to say, the industry's own assessment is that forgetting and freshness are unsolved at the tooling level and must currently be solved at the design level.Design-level forgetting has three mechanisms, in increasing order of sophistication: time-based expiry (TTL), usage-based decay, and staleness detection. They compose; mature systems use all three on different memory types.
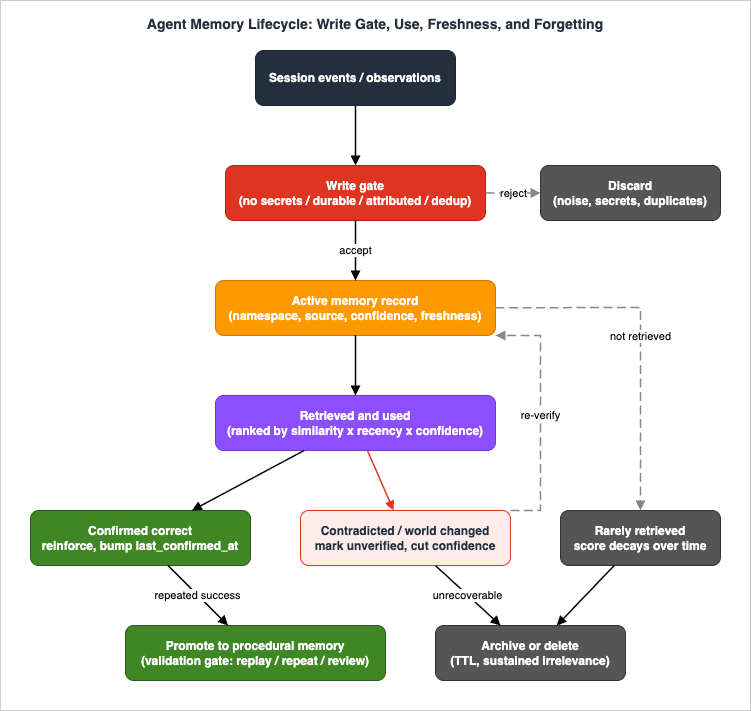
6.2 TTL: The Blunt Instrument That Should Be Everywhere
A time-to-live is the cheapest forgetting mechanism and the one with the least excuse for absence. Raw episodic data in particular should always carry one: transcripts and event logs grow without bound, are dominated by detail that loses value within days, and frequently carry compliance constraints on retention. Managed services expose this directly — Amazon Bedrock AgentCore Memory's short-term memory takes an event expiry configuration (eventExpiryDuration) that controls how long raw events are retained, configurable up to 365 days — and self-built stores can implement it with native TTL features (Amazon DynamoDB TTL attributes, Amazon OpenSearch Service index lifecycle policies, Amazon S3 lifecycle rules).The design decision is not whether to set TTLs but how they differ by type. A reasonable default ladder:
| Memory content | Default lifetime posture |
|---|---|
| Raw working-memory snapshots, intermediate tool outputs | Session-scoped; gone at session end |
| Raw episodes (transcripts, event logs) | Short TTL (days to a few months), driven by debugging and compliance needs |
| Episode summaries | Medium TTL; cheaper to keep than raw, still ages |
| Semantic facts | No fixed TTL; governed by staleness checks (6.4) and supersession |
| Preferences | No TTL; revised by supersession when the user changes them |
| Procedures | Never TTL'd; versioned and deprecated explicitly (section 5) |
The asymmetry is deliberate: TTLs apply hardest to the bulky, low-density layers, while the distilled layers are governed by smarter mechanisms. Expiring a raw transcript whose facts were already extracted costs nothing; expiring the extracted fact because a calendar said so is arbitrary.
6.3 Usage-Based Decay: Let Retrieval Behavior Vote
TTL treats all records of an age equally; decay lets actual usage discriminate. The idea, borrowed loosely from human memory research, is that a memory's effective relevance should combine semantic similarity with recency and reinforcement. A simple, implementable scoring function at retrieval time:def effective_score(record, similarity, now):
age_days = (now - record.last_confirmed_at).days
recency_factor = 0.5 ** (age_days / record.half_life_days)
reinforcement = min(1.0, 0.6 + 0.1 * record.times_retrieved_and_confirmed)
return similarity * recency_factor * reinforcement * record.confidenceTwo implementation notes matter more than the exact formula. First, decay the score, not the data — a low effective score demotes a record in retrieval ranking, and only sustained irrelevance (score below threshold for a long period, never retrieved) queues it for archival. This keeps decay reversible. Second, reinforce on confirmation, not on retrieval alone: a record that gets retrieved and then contradicted by the session should have its confidence cut, not its recency refreshed. Touching
last_confirmed_at only when the memory proved correct turns ordinary agent operation into a continuous, free validation signal.6.4 Staleness Detection: The Memory Was True; The World Changed
TTL and decay are proxies. The real problem is that a memory's truth depends on facts outside the memory store, and those facts change. Three patterns address staleness directly:Freshness metadata at write time. Every semantic record carries
written_at, last_confirmed_at, an optional expires_at for facts with known horizons ("the certificate expires in May"), and ideally a validity_basis — a machine-checkable statement of what the fact depends on:{
"content": "The deployment pipeline for service-a runs on the shared runner pool.",
"written_at": "2026-03-10T08:00:00Z",
"last_confirmed_at": "2026-05-28T11:30:00Z",
"expires_at": null,
"validity_basis": {
"kind": "file_content",
"ref": "infra/ci/service-a.yaml",
"checksum": "sha256:7f3a..."
}
}Verification on consequential use. Not every retrieval deserves a freshness check, but consequential actions do. The pattern is a tiered policy: memories backing irreversible or high-impact actions (deploys, deletions, external communications) are re-verified against their
validity_basis before the action proceeds; memories that merely color a conversation are used as-is, with their age surfaced to the model ("note: last confirmed 84 days ago") so the model can hedge or re-check on its own judgment. Exposing the timestamp to the model is nearly free and surprisingly effective — models are reasonably good at deciding to double-check old information when they can see that it is old.Invalidation hooks from the world. Where the depended-on systems emit change events, subscribe and invalidate proactively: a webhook on the CI config repository marks every memory whose
validity_basis references a changed file as unverified, demoting it in retrieval until re-confirmed. This is the same supersession machinery as section 4.2, driven by external events instead of new conversations. It will never cover everything — hence the other two patterns — but for the systems an agent acts on most (repositories, ticketing, infrastructure state), event-driven invalidation converts the worst staleness incidents into non-events.The composite posture is worth stating as a rule: every memory is written with the metadata needed to question it later. Forgetting machinery cannot be retrofitted onto bare strings; it has to be designed into the record shape from the first write.
7. Memory Write Policies: What Deserves to Be Remembered
7.1 The Write Gate
Symmetric to forgetting is the discipline of not remembering noise in the first place. An agent that persists everything it encounters fills its stores with transient trivia, secrets it should never have kept, and one-off observations that will outrank durable knowledge in future retrievals. A write policy is a small set of tests applied before anything enters long-term memory:def should_remember(candidate):
if contains_secrets(candidate.content): # never persist credentials/tokens
return Reject("secret material")
if not durable(candidate): # will this matter beyond the session?
return Reject("session-scoped detail")
if not attributable(candidate): # can we point at the evidence?
return Reject("no source episode")
existing = find_similar(candidate, threshold=0.92)
if existing:
return Consolidate(existing) # update/supersede, don't duplicate
return Accept(confidence=estimate_confidence(candidate))The four tests carry the weight. Secrets never enter memory — both Anthropic's memory tool documentation and general security guidance are explicit on this, because memory stores are durable, retrievable surfaces with weaker handling guarantees than purpose-built secret managers. Durability separates "the user prefers terse answers" (remember) from "the user asked for a terse answer to this one question" (don't); the practical heuristic is whether the statement would be useful in a session about a different task. Attribution requires every record to reference the episodes that justify it, which is what makes confidence estimation, later auditing, and poisoning forensics (section 9) possible at all. Consolidation routes near-duplicates into updates of the existing record rather than new rows — the single most effective measure against the gradual retrieval-quality rot that plagues vector-store memories.
7.2 Extraction and Consolidation as a Background Process
Who applies the write gate? The emerging consensus answer is: not the agent in its hot loop. Inline writing ("save this now, mid-task") burns working-memory budget on bookkeeping and produces hasty, redundant records. The better pattern is asynchronous extraction: the session writes cheap raw events; a background process later reads recent episodes, extracts candidate facts and preferences, consolidates them against existing records, and writes the survivors.This is precisely how Amazon Bedrock AgentCore Memory is built — raw events written via
CreateEvent are processed asynchronously by an extraction stage and a consolidation stage (the official documentation describes consolidation as merging newly extracted information with existing information), and the results become retrievable memory records some seconds later. Letta's sleep-time agents express the same idea at the framework level: a background agent shares memory with the primary agent and revises it between interactions. If you build your own, the asynchronous shape has one consequence you must design for: memories from the current conversation are not instantly retrievable, so anything the agent needs within the session must stay in working memory or the scratchpad rather than round-tripping through the long-term store.One last write-policy decision is confidence at write time. A preference stated explicitly by the user ("always use TypeScript") deserves higher confidence than one inferred from a single behavior; a fact confirmed across five episodes outranks a fact seen once. Recording that difference as a number (even a crude one) is what allows retrieval ranking (6.3), verification tiering (6.4), and conflict resolution ("explicit statement beats inference") to work mechanically instead of by intuition.
8. Memory in Managed Platforms
8.1 Amazon Bedrock AgentCore Memory: The Current Shape
Amazon Bedrock AgentCore Memory, generally available since October 2025, is the most complete managed implementation of the episodic-to-semantic pipeline described in section 7, and a useful concrete anchor for everything this guide has discussed in the abstract. Its model:- Short-term memory stores raw interactions as immutable, timestamped events, organized by actor (
actorId) and session (sessionId), with retention controlled by an event expiry setting configurable up to 365 days. This is the episodic substrate, with TTL built in. - Long-term memory is populated asynchronously by strategies that extract and consolidate records from events into hierarchical namespaces (templates like
/users/{actorId}/preferences), and is retrieved by exact listing or by semantic search viaRetrieveMemoryRecords.
As of this writing the official documentation lists four built-in strategy types: user preferences (
userPreferenceMemoryStrategy), semantic facts (semanticMemoryStrategy), session summaries (summaryMemoryStrategy), and an episodic strategy (episodicMemoryStrategy) that captures interactions as structured episodes — scenario, intent, actions, outcomes — and supports cross-episode reflections. If you have read earlier coverage (including my own Amazon Bedrock AgentCore Implementation Guide Part 1, written when three strategies were documented), note that the episodic strategy is a later addition — check the current documentation rather than assuming the three-strategy picture.Beyond the built-ins, the service now spans three strategy categories that map neatly onto a build-versus-buy gradient:
| Strategy category | What you control | What stays managed |
|---|---|---|
| Built-in | Which strategies, which namespaces | Extraction logic, consolidation, models, schemas |
| Built-in with overrides | Extraction/consolidation prompts and model selection | Pipeline orchestration, record schemas |
| Self-managed | The entire extraction/consolidation pipeline (triggered via notifications and conversation payloads delivered to your infrastructure; you write records back through batch APIs such as BatchCreateMemoryRecords) | Event storage, record storage, retrieval, namespaces |
A configuration sketch for a memory resource combining strategies (shape per the official documentation; field names evolve, so verify before use):
{
"name": "support-agent-memory",
"eventExpiryDuration": 90,
"memoryStrategies": [
{ "userPreferenceMemoryStrategy": { "name": "prefs",
"namespaceTemplates": ["/users/{actorId}/preferences"] } },
{ "semanticMemoryStrategy": { "name": "facts",
"namespaceTemplates": ["/users/{actorId}/facts"] } },
{ "summaryMemoryStrategy": { "name": "summaries",
"namespaceTemplates": ["/summaries/{actorId}/{sessionId}"] } }
]
}8.2 The Claude Memory Tool: The Client-Side Counterpart
Anthropic's approach on the Claude Developer Platform is instructive precisely because it is the opposite shape: the memory tool (memory_20250818) defines the model-facing interface — commands to view, create, edit, and delete files under a /memories directory — while the storage backend is entirely yours. Claude decides what to write and when to consult it; you decide where files live, how they are scoped per user, and what governance applies. Enabling it is a one-line tool declaration; everything interesting happens in your handler:{
"tools": [
{ "type": "memory_20250818", "name": "memory" }
]
}Your handler receives the tool's file commands (
view, create, str_replace, insert, delete, rename) and executes them against your storage — which is precisely where the write gate of section 7 and the per-user scoping of section 9 get enforced, since every memory operation funnels through code you own. Paired with context editing and compaction (section 3), the memory tool implements the scratchpad-and-archive pattern with the platform handling the model-side ergonomics and you handling persistence. It is the right starting point when your memory needs are agent notes and learned context rather than multi-user fact extraction pipelines.8.3 Where the Managed Boundary Actually Falls
Putting sections 5 through 7 against what the platforms ship yields a clear division of labor. Managed services currently cover: episodic capture with TTL, asynchronous extraction and consolidation into preferences/facts/summaries/episodes, namespace scoping, semantic retrieval, and (in AgentCore's self-managed mode) the plumbing to run your own pipeline against managed storage. They do not currently cover: procedural memory with validation gates (section 5.3), confidence and supersession semantics (sections 4.2, 7.2), staleness detection against external systems (section 6.4), usage-based decay ranking (section 6.3), or cross-store consistency when your memory spans multiple substrates. That uncovered list is not a criticism — it is the part of memory design that is inherently application-specific — but it is the honest answer to "can I just use the framework's memory feature?": yes for the pipeline, no for the lifecycle. Plan to own the lifecycle either way.9. Security and Privacy of Agent Memory
9.1 Memory as an Attack Surface
A memory store is a persistence mechanism that feeds future prompts, which makes it a prompt-injection amplifier with a time delay. Memory poisoning is the cleanest example: if an attacker can influence what gets remembered — through a manipulated conversation, a compromised document that gets ingested, or a tool result crafted to look like a durable fact — the malicious instruction does not need to succeed now. It waits in the store and executes in a future session, against a future task, possibly for a different user, long after the injection event scrolled out of any reviewed transcript. The write gate of section 7 is therefore a security control, not just hygiene: attribution requirements mean every record can be traced to its source episodes during incident response, and the consolidation step is a natural place for content screening. Treat anything crossing from untrusted input into long-term memory with the same suspicion as anything crossing into tool execution. The layered defenses for injection generally — input screening, output mediation, least-privilege tools — are covered in my AI Agent Defense in Depth Model, and the tool-side variant of this attack class is the subject of MCP Tool Poisoning Defense Guide - Client-Side Defense in Depth for AI Agents.The complementary risk is exfiltration through memory: cross-tenant leakage, where one user's remembered facts surface in another user's session, and cross-purpose leakage, where information collected in one context is retrieved in another that the user never anticipated. Both are scoping failures, and the defense is structural rather than behavioral.
9.2 Isolation by Namespace, Enforced Below the Model
The non-negotiable rule: memory isolation must be enforced by the storage layer, never by asking the model to be careful. Per-user and per-tenant scoping belongs in the query path — the retrieval call physically cannot address another tenant's records. AgentCore Memory's namespace design supports exactly this: records live under hierarchical namespaces (for example/users/{actorId}/...), and namespace values can be used as IAM condition keys, so an execution role can be restricted to namespaces matching the current actor. Self-built equivalents are per-tenant indexes or mandatory namespace filters injected by the data-access layer rather than by the prompt. The trailing design question — what is shared versus private — should be answered explicitly per memory type: preferences are private to a user; semantic facts may be team-scoped; validated procedures are usually organization-scoped (that transferability is their value, per section 5.2). Make each type's scope a declared property, not an accident of which store it landed in.9.3 PII, Retention, and the Right to Be Forgotten
Long-term memory of user interactions is personal data processing, and the lifecycle machinery this guide has already argued for on engineering grounds is the same machinery privacy compliance requires. Concretely: minimize at the write gate (extract the durable preference, not the raw utterance containing a phone number); set retention by type with the TTL ladder of section 6.2, letting raw episodic data expire fastest; keep deletion actually deletable — a user-deletion request must reach the vector index entries, the system-of-record rows, and any summaries derived from that user's episodes, which is only tractable if records carry attribution linking derived memories back to their sources; and never let secrets in (section 7.1), because a memory store will not have the rotation, scoping, and audit characteristics of a secrets manager. None of this is exotic — it is the section 4-through-7 record envelope doing double duty — which is rather the point: a memory system designed for lifecycle management is most of the way to one designed for privacy.10. A Design Checklist
The following checklist condenses this guide into review questions. It is intended for design reviews of new agents and audits of existing ones; "no" answers are not necessarily wrong, but they should be deliberate.| # | Area | Question |
|---|---|---|
| 1 | Taxonomy | Is every persisted artifact classified as working / episodic / semantic / procedural, with exactly one lifecycle each? |
| 2 | Working memory | Is there an explicit context budget, and are all three mechanisms (prune, summarize, retrieve-on-demand) in use? |
| 3 | Working memory | Does the agent keep a structured scratchpad that survives compaction and bootstraps the next session? |
| 4 | Substrate | Is each retrieval mode (similarity / key / relationship / predicate) served by an appropriate store rather than everything through one vector index? |
| 5 | Record shape | Do records carry namespace, source attribution, confidence, and freshness timestamps from the first write? |
| 6 | Procedural | Are procedures version-controlled, diffable, and human-reviewable? |
| 7 | Procedural | Does promotion to live procedures require validation (replay, repetition, or review) — never automatic? |
| 8 | Forgetting | Does raw episodic data carry a TTL aligned with debugging and compliance needs? |
| 9 | Forgetting | Is retrieval ranking sensitive to age and confirmation history, not just similarity? |
| 10 | Staleness | Do consequential actions trigger re-verification of the memories they depend on? |
| 11 | Staleness | Are external change events (repos, infra) wired to invalidate dependent memories where feasible? |
| 12 | Write policy | Is there a write gate testing for secrets, durability, attribution, and duplication? |
| 13 | Write policy | Is extraction/consolidation asynchronous, with in-session needs served by working memory instead? |
| 14 | Security | Is tenant isolation enforced in the storage/query layer (namespaces, IAM conditions), not by prompting? |
| 15 | Privacy | Can a user-deletion request reach raw episodes, extracted records, and derived summaries? |
| 16 | Platform | Is the managed/self-built boundary explicit — pipeline from the platform, lifecycle owned by you? |
11. Common Pitfalls
Remembering everything. The most common failure is the absence of a write gate: every observation becomes a permanent record, and within months retrieval returns mostly noise. The fix is section 7's gate plus a one-time cleanup pass; the prevention is treating "should this be remembered?" as a question with a default answer of no.Forgetting nothing. The mirror image: stores with no TTLs, no decay, no supersession. The system works impressively in the demo and degrades in production at the speed of the world's change rate. If your design review cannot answer "how does a wrong memory die?", it is not done.
Promoting unvalidated procedures. Letting the agent edit its own standing instructions or playbooks without a validation gate converts one lucky workaround into a permanent habit. Procedures are code; ship them like code.
Confusing session state with knowledge. Persisting the working scratchpad wholesale "so nothing is lost" fills long-term memory with half-finished plans and stale intermediate conclusions that retrieval later presents as facts. Persist conclusions through the write gate; let the scratchpad die with the session (the episode log already preserves the raw history).
One store for everything. Routing preferences, episodes, facts, and procedures through a single vector index because it was already there. Each misrouted type loses its natural management mechanism: preferences lose exact lookup, bookkeeping loses queries, procedures lose diffs and review.
Isolation by prompt. "Only use memories belonging to the current user" as a system-prompt instruction rather than a query-path constraint. This is not a memory bug waiting to happen; it is an access-control vulnerability already shipped.
Trusting vendor benchmark numbers as design inputs. Memory-system benchmarks published by memory-system vendors are directionally informative and competitively contested; published figures have drawn public rebuttals from competitors. Benchmark on your own workload — retrieval precision on your queries, staleness incidents on your change rate — before committing to an architecture.
Designing memory before designing the agent's job. Memory infrastructure added speculatively ("we'll need long-term memory eventually") tends to fit the imagined agent, not the real one. The file-based scratchpad of section 3.3 is deliberately boring and almost always the right first system; graduate to extraction pipelines when observed retrieval needs demand them.
12. Frequently Asked Questions
Q1. Do I need a vector database for agent memory?Not necessarily, and not first. If your agent's memory needs are its own notes, learned context, and a modest set of procedures, version-controlled files with a memory-tool interface are sufficient and far easier to govern. A vector store earns its place when you have a large, growing body of extracted facts or episode summaries that must be recalled by meaning rather than by name. Even then it serves as the similarity index, not the system of record — keep the managed envelope (attribution, confidence, freshness) in a store that can answer non-similarity questions.
Q2. What is procedural memory in practice - not in theory?
Concretely: the rules in your system prompt, the playbook documents your agent consults before known task types, and the skills it can load on demand. "Building procedural memory" means capturing candidate procedures from successful episodes, validating them (replay, repetition, or human review), and landing them in version control with provenance — then loading them just-in-time rather than stuffing every rule into every prompt. It is the layer where an agent's performance compounds across sessions, and currently the layer with the least platform support, so plan to build the promotion pipeline yourself.
Q3. How do I keep memories from going stale?
Three layers, cheapest first: write freshness metadata (
written_at, last_confirmed_at, optional expires_at, and a machine-checkable validity basis) on every record from day one; surface age to the model at retrieval and re-verify memories that back consequential actions; and where the depended-on systems emit change events, invalidate dependent memories proactively. Also let normal operation help you: bump last_confirmed_at when a retrieved memory proves correct, and cut confidence when the session contradicts it.Q4. Should I just use my framework's or platform's built-in memory?
Use it for what it covers: episodic capture with TTL, asynchronous extraction into preferences/facts/summaries, namespacing, and semantic retrieval are commodity machinery you should not rebuild. Own what it does not cover: write-gate policy, confidence and supersession, staleness detection, procedural memory with validation, and deletion that spans derived records. The realistic posture is "managed pipeline, self-owned lifecycle" — and a thin abstraction over the platform's API so lifecycle logic is not welded to one vendor's record shape.
Q5. How much memory should the agent see per turn?
As little as answers the task: identifiers and a small curated working set in context, contents fetched just-in-time through retrieval tools. A practical smell test: if most retrieved memories are not referenced by the agent's subsequent reasoning, the retrieval k is too high or the ranking too loose. Spend the saved budget on headroom — long agentic sessions die at the margins.
Q6. How does memory interact with multi-agent systems?
Scope it like you scope everything else in multi-agent design: working memory is per-agent by construction; episodic logs should record which agent did what; semantic memory is usually shared at team scope (with namespaces per tenant still enforced below the model); and procedural memory is where sharing pays most, since one agent's validated playbook transfers to its peers. The hazard to design against is write contention on shared records — route all writes through the same gate-and-consolidate pipeline rather than letting multiple agents mutate records directly.
13. Summary
Reliable long-running agents are built on memory that was designed, not accumulated. The design reduces to a small number of commitments made early. Classify every persisted artifact into working, episodic, semantic, or procedural memory — the taxonomy is grounded in CoALA and standard cognitive science, shared by the major frameworks, and gives each artifact exactly one lifecycle. Treat the context window as a budgeted resource managed by pruning, summarization, and just-in-time retrieval, with a structured scratchpad as the agent's anchor. Choose storage substrates by retrieval mode rather than habit, and wrap every record in an envelope of namespace, attribution, confidence, and freshness from the first write. Guard the write path with a gate that rejects secrets, noise, and duplicates — and guard the procedural write path hardest of all, because unvalidated procedures are the one class of bad memory that compounds. Build forgetting in from the start: TTLs on raw episodes, decay in retrieval ranking, staleness detection for facts the world can change. Take the managed pipeline where platforms offer it — Amazon Bedrock AgentCore Memory's event-to-strategy architecture and the Claude memory tool are both solid foundations — and own the lifecycle on top, because no platform currently owns it for you.Memory is where an agent stops being a stateless function and starts being a system. Design it with the same care as the rest of your architecture, and most of what gets called "agent unreliability" never appears.
14. References
- Cognitive Architectures for Language Agents - Sumers, Yao, Narasimhan, Griffiths (arXiv)
- A Survey on the Memory Mechanism of Large Language Model based Agents - Zhang et al. (arXiv)
- State of AI Agent Memory 2026 (Mem0 Engineering)
- LangGraph - Memory concepts (LangChain Docs)
- LangMem SDK for agent long-term memory (LangChain Blog)
- Memory blocks - core memory (Letta Docs)
- Sleep-time agents (Letta Docs)
- Agent Memory: How to Build Agents that Learn and Remember (Letta Blog)
- Amazon Bedrock AgentCore Memory (AWS Docs)
- AgentCore Memory - How it works: short-term and long-term memory (AWS Docs)
- AgentCore Memory - Configure built-in strategies (AWS Docs)
- AgentCore Memory - Self-managed strategies (AWS Docs)
- Amazon Bedrock AgentCore is now generally available (AWS What's New)
- Building smarter AI agents: AgentCore long-term memory deep dive (AWS Machine Learning Blog)
- Effective context engineering for AI agents (Anthropic Engineering)
- Managing context on the Claude Developer Platform (Anthropic)
- Effective harnesses for long-running agents (Anthropic Engineering)
- Memory tool (Claude Developer Platform Docs)
Related Articles in This Series
- Enterprise AI Agent Design Notes - Part 1: Comparing the Three Major Clouds and Designing Your Architecture
The platform-selection prequel to this article: local versus cloud-hosted agents and the three major cloud agent platforms. - Enterprise AI Agent Design Notes - Part 3: Cloud Selection, Cost, and Operations
Use-case-driven cloud selection, agent protocols, governance, and operations for enterprise agent deployments. - AI Agent Engineering Glossary - Memory, Tools, Orchestration, and Protocols Explained
The shared vocabulary this article builds on, including the memory-related terms in its Memory section. - Amazon Bedrock AgentCore Implementation Guide Part 1: Runtime, Memory, and Code Interpreter Patterns
Hands-on implementation of AgentCore Memory with code: events, strategies, namespaces, and integration patterns. - AI Agent Defense in Depth Model
The layered security model that section 9's memory-poisoning and isolation guidance plugs into.
References:
Tech Blog with curated related content
Written by Hidekazu Konishi