GraphRAG Architecture on AWS - Multi-Hop Retrieval with Amazon Bedrock Knowledge Bases and Neptune Analytics
First Published:
Last Updated:
This article is about that second class of question, and about a managed AWS pattern for answering it: GraphRAG with Amazon Bedrock Knowledge Bases and Amazon Neptune Analytics. Instead of treating the corpus as a flat bag of vectors, GraphRAG additionally builds a knowledge graph of the entities, facts, and relationships extracted from your documents, stores it alongside the embeddings in Neptune Analytics, and at retrieval time traverses that graph to pull in connected context that a pure vector search would miss. The result is multi-hop, cross-document retrieval that is also more explainable, because the connections it followed are explicit edges in a graph rather than an opaque similarity score.
The scope here is deliberately narrow and deep. This is a Level 400 implementation walkthrough of a single named reference architecture, not a survey of graph databases or an introduction to RAG. The mechanics of ingestion, chunking, embedding model selection, vector-store options, and content safety are already covered in my Amazon Bedrock RAG Architecture Guide, and this article delegates those topics there rather than repeating them. The agentic side of RAG — query planning, retrieval grading, and self-correction loops — is the subject of the companion Agentic RAG Architecture on Amazon Bedrock. What follows concentrates on the part those articles do not cover: how a graph gets built automatically, how hybrid vector-plus-graph retrieval actually behaves, when multi-hop traversal helps, and — just as important — when it does not.
1. Introduction: Why Relationship-Following Questions Break Vector RAG
A vector retriever answers the question "which chunks are most similar to this query?" That framing has a built-in assumption: that the information needed to answer the question is concentrated in text that resembles the question. For a large fraction of enterprise questions, that assumption simply does not hold.Consider a corpus of corporate filings, research notes, and incident reports. Ask "Which suppliers are exposed to the same port disruption that affected our Q3 logistics, and which of our product lines depend on them?" There may be no single chunk that mentions the port disruption, the affected suppliers, and the dependent product lines together. The port disruption is described in one report. The supplier relationships are in a procurement document. The product-line dependencies are in an engineering bill of materials. A vector search retrieves passages similar to the phrasing of the question, which tends to surface the one document that talks about "port disruption" and nothing else. The chain of relationships that actually answers the question is never assembled, because no individual passage embodies it.
This is the multi-hop problem. The answer requires hopping from an event, to the entities affected by it, to the entities related to those, and so on. Each hop is a relationship, and relationships are exactly what a flat vector index does not represent. You can paper over a single hop by retrieving a larger top-k and hoping the generation model stitches the passages together, but recall degrades quickly: the more hops you need, the more likely it is that an intermediate passage is not similar enough to the original query to be retrieved at all, and once a link in the chain is missing, the chain is broken.
GraphRAG addresses this by adding a second representation of the corpus. During ingestion it extracts entities and the relationships between them and materializes a knowledge graph. At query time it still starts from a vector search — semantics are a good way to find an entry point into the corpus — but it then follows the graph edges around those entry points to gather connected information. The generation model receives not just the top-k similar chunks, but the chunks plus their graph neighborhood, which is far more likely to contain the distributed facts a multi-hop question depends on.
Two properties make the managed Bedrock implementation attractive for production. First, the graph is built and maintained automatically — you do not model the schema, write extraction prompts, or hand-tune a graph pipeline. Second, retrieval is a single API call: the same
Retrieve and RetrieveAndGenerate operations you already use for vector RAG transparently perform the vector-then-graph retrieval. That keeps the application surface identical to a vector RAG system while changing the retrieval behavior underneath.This article walks the full path: the reference architecture (Section 2), where vector RAG remains the right floor and where graphs earn their keep (Section 3), automatic graph construction on Neptune Analytics (Section 4), the hybrid retrieval mechanism and its multi-hop behavior and limits (Section 5), grounded and explainable generation (Section 6), the cross-cutting concerns of least-privilege IAM, data boundaries, and graph maintenance (Section 7), observability and failure modes (Section 8), and the cases where GraphRAG is overkill (Section 9).
2. The Reference Architecture at a Glance
The reference architecture has a single backbone: documents in Amazon S3 are ingested by an Amazon Bedrock knowledge base configured for GraphRAG, which uses a graph construction foundation model and an embedding model to populate an Amazon Neptune Analytics graph that holds both the vector index and the entity/relationship graph; at query time the application calls the Bedrock Agent Runtime retrieval APIs, which perform a vector search followed by graph traversal, and pass the enriched context to a generation model that returns a grounded, cited answer.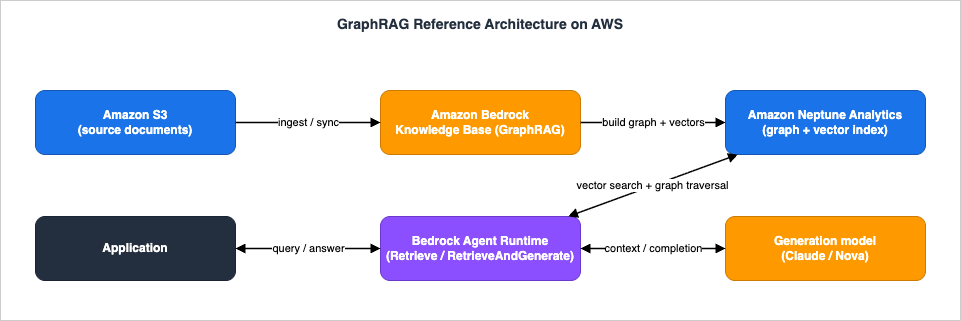
- Amazon S3 — the source of truth for documents. For GraphRAG, S3 is the only supported data source. Folders under a bucket map naturally to data sources and partitions.
- Amazon Bedrock Knowledge Bases (GraphRAG) — the managed control plane. It orchestrates parsing, chunking, embedding, entity/relationship extraction, and graph construction; it owns the data-source configuration and the service role.
- Embedding model — converts chunks into vectors. Amazon Titan Text Embeddings and Cohere Embed are supported; the vector dimension you choose must match what the Neptune Analytics vector index was created with.
- Graph construction model — a foundation model invoked during ingestion to extract entities and relationships from each chunk. Selecting it automatically enables contextual enrichment.
- Amazon Neptune Analytics — a memory-optimized graph engine that stores the embeddings and the graph in one place, and supports vector similarity search inside graph traversals. This co-location is what makes the hybrid retrieval a single round trip.
- Bedrock Agent Runtime (
Retrieve/RetrieveAndGenerate) — the query-time data plane. One call performs the vector search and graph traversal;RetrieveAndGenerateadditionally calls a generation model and returns a cited answer. - Generation model — composes the final answer from the retrieved-and-traversed context. This is where you select a current Anthropic Claude or Amazon Nova model.
The thing worth internalizing before going deeper is that GraphRAG is not a separate service you bolt onto a vector store. It is a storage and retrieval configuration of a Bedrock knowledge base in which Neptune Analytics replaces the usual vector store and additionally holds a graph. The application-facing API is unchanged; the behavior underneath is what differs.
3. Vector RAG as the Floor, and When Graphs Help
Before adding a graph, be honest about what vector RAG already gives you, because for many workloads it is sufficient and a graph is pure overhead. Vector RAG — ingestion, chunking, embeddings, vector store, retrieval, generation, and content safety — is covered end to end in the Amazon Bedrock RAG Architecture Guide, and everything there is the floor this architecture builds on. GraphRAG does not replace any of it; it changes the storage backend and adds a traversal step.The decision of whether to go from vector to graph comes down to the shape of your questions, not the size of your corpus. A useful test: when you read a representative question, can the answer be found in a single passage, or does it require connecting facts that live in different passages and different documents?
| Question shape | Better served by | Why |
|---|---|---|
| Fact lookup ("What is the warranty period for product X?") | Vector RAG | The answer is concentrated in one passage that is semantically similar to the query. |
| Summarize-this-document ("Summarize the Q3 risk report") | Vector RAG | Relevant passages cluster within one document and resemble the query. |
| Multi-hop relationship ("Which products use a component sourced from the disrupted supplier?") | GraphRAG | The chain event → supplier → component → product spans documents; no single passage carries it. |
| Cross-document synthesis ("How do these three incidents relate, and what is the common root cause?") | GraphRAG | Shared entities across documents become explicit graph nodes that traversal can connect. |
| Global "themes" question over a whole corpus | Neither (see Section 9) | Both vector and neighborhood-traversal retrieval are local; corpus-wide aggregation is a different problem. |
The honest framing is that GraphRAG raises the ceiling on relationship-following and cross-document reasoning while adding cost and operational surface: a Neptune Analytics graph to provision and maintain, a graph construction model invoked during ingestion, and a graph that must be kept in sync with the corpus. If your traffic is dominated by single-passage lookups, that surface buys you little. If a meaningful share of your questions only resolve by connecting facts across documents, it is exactly the right tool. Many production systems route between the two rather than choosing once — a topic the Agentic RAG article develops, where a planning step decides which retrieval strategy a given query needs.
4. Automatic Graph Construction with Neptune Analytics
The defining property of Bedrock Knowledge Bases GraphRAG is that you do not build the graph. You point a knowledge base at an S3 prefix, choose two models — an embedding model and a graph construction model — and the service extracts entities, facts, and relationships from your documents and materializes a graph in Neptune Analytics, with no graph modeling on your part. This section covers what gets built, where the vectors and graph co-exist, and how the graph stays current.4.1 What the graph contains
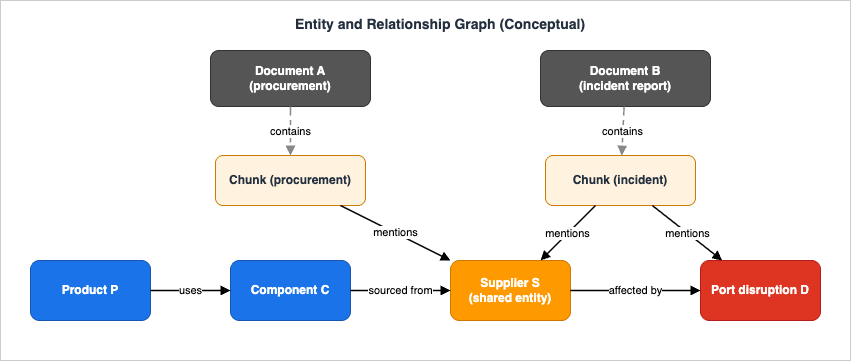
During ingestion, the knowledge base parses and chunks each document (the same chunking machinery as vector RAG), embeds the chunks, and — this is the graph-specific part — invokes the graph construction model on the chunks to extract entities and the relationships among them. It then writes a graph whose structure connects chunks to their source documents and entities to the chunks they appear in. The embeddings for the chunks live in the same Neptune Analytics graph, in a vector search index.The practical consequence of "entities to chunks" and "chunks to documents" is that two documents that never cite each other become connected the moment they mention the same entity. A supplier named in a procurement PDF and the same supplier named in an incident report become a single entity node with edges to chunks in both documents. That shared node is the bridge a multi-hop query crosses, and it is created automatically by the extraction step rather than by any explicit cross-reference in the source text.
4.2 Vectors and graph co-located in Neptune Analytics
Amazon Neptune Analytics is a memory-optimized graph engine that provides graph queries, graph algorithms, and native vector similarity search through a single endpoint. GraphRAG relies on this co-location: because the chunk embeddings and the entity/relationship graph live in the same store, retrieval can do a vector search and then traverse from the matched nodes without a second system or a cross-store join.Provisioning the graph has a few fixed properties worth knowing before you create one:
- The vector search index can only be created when the graph is created. You cannot add a vector index to an existing Neptune Analytics graph afterward, so a graph intended for GraphRAG must be created with vector search configured.
- The vector dimension must match the embedding model. Titan Text Embeddings G1 is 1,536 dimensions; Titan Text Embeddings V2 supports 1,024, 512, and 256; Cohere Embed (English and Multilingual) is 1,024. A mismatch between the index dimension and the embedding model is a configuration error, not a runtime one — decide the embedding model first.
- Capacity is measured in m-NCUs (memory-optimized Neptune Capacity Units), each providing roughly one GiB of memory with corresponding compute and networking. You can resize later; starting small and scaling up is the documented guidance.
- Networking is managed for you. When you associate the graph with a knowledge base, Bedrock creates the network connection to Neptune Analytics; you do not configure public connectivity or private endpoints for GraphRAG to work.
There are two ways to get the graph. The simplest is quick create: in the Bedrock console, create a "Knowledge Base with vector store," choose Amazon Neptune Analytics (GraphRAG) as the vector database with the Quick create a new vector store option, and Bedrock provisions the graph and vector index for you. The alternative is to create the Neptune Analytics graph and vector index yourself and select it as an existing store, supplying the graph ARN and the vector/metadata field names. Quick create is the right default unless you have a reason to manage the graph lifecycle independently.
4.3 The graph construction model and contextual enrichment
The graph construction model is chosen when you create the knowledge base or configure the data source, and selecting it automatically enables contextual enrichment — the extraction of entities and relationships per chunk. Supported choices for graph construction include Anthropic Claude Haiku 4.5 and the Amazon Nova family (including Nova 2 and Nova models with a text input modality). Some models are available only through cross-Region inference profiles.Two facts deserve emphasis because they are easy to get wrong from older examples. First, model lifecycle matters: Anthropic Claude 3 Haiku, used in early GraphRAG walkthroughs, has moved to Legacy status. Select a currently supported model and check the Bedrock Model lifecycle page before deploying rather than copying a model ID from a tutorial. Second, when the graph construction model runs through a cross-Region inference profile, your data is stored only in the source Region (the Region of the knowledge base and the Neptune Analytics graph); the destination Region is used for inference only. That distinction matters for data-residency reviews and is covered again in Section 7.
The data source carries the extraction configuration. With the AWS CLI you first create the data source with a context-enrichment configuration that names the graph construction model:
{
"dataSourceConfiguration": {
"type": "S3",
"s3Configuration": {
"bucketArn": "arn:aws:s3:::example-graphrag-datasets",
"inclusionPrefixes": ["example-dataset/"]
}
},
"vectorIngestionConfiguration": {
"contextEnrichmentConfiguration": {
"type": "BEDROCK_FOUNDATION_MODEL",
"bedrockFoundationModelConfiguration": {
"modelArn": "arn:aws:bedrock:us-west-2:111122223333:inference-profile/us.anthropic.claude-haiku-4-5-20251001-v1:0",
"enrichmentStrategyConfiguration": {
"method": "CHUNK_ENTITY_EXTRACTION"
}
}
}
}
}
aws bedrock-agent create-data-source \
--name graph_rag_source \
--description "Data source for GraphRAG" \
--knowledge-base-id KB_ID \
--cli-input-json file://datasource.json
CHUNK_ENTITY_EXTRACTION method is what turns chunks into entities and relationships. The modelArn shown uses a cross-Region inference profile (note the inference-profile/us.anthropic... form); for models that support a direct invocation in your Region you can use the foundation-model/... ARN form instead.4.4 Connecting the data source to a knowledge base with Neptune Analytics storage
The knowledge base ties the graph store to the embedding model. The storage configuration uses theNEPTUNE_ANALYTICS type, pointing at the graph ARN with a field mapping for the metadata and text fields, while the knowledge base configuration declares the embedding model:{
"storageConfiguration": {
"type": "NEPTUNE_ANALYTICS",
"neptuneAnalyticsConfiguration": {
"graphArn": "arn:aws:neptune-graph:us-west-2:111122223333:graph/g-abc123example",
"fieldMapping": {
"metadataField": "metadata",
"textField": "text"
}
}
},
"knowledgeBaseConfiguration": {
"type": "VECTOR",
"vectorKnowledgeBaseConfiguration": {
"embeddingModelArn": "arn:aws:bedrock:us-west-2::foundation-model/amazon.titan-embed-text-v2:0"
}
}
}
aws bedrock-agent create-knowledge-base \
--name knowledge-base-graphrag \
--role-arn arn:aws:iam::111122223333:role/BedrockExecutionRoleForKnowledgeBase \
--cli-input-json file://knowledgebase.json
AWS::Bedrock::KnowledgeBase carries the storage and embedding configuration, and AWS::Bedrock::DataSource carries the S3 source and the graph construction model:Resources:
GraphRagKnowledgeBase:
Type: AWS::Bedrock::KnowledgeBase
Properties:
Name: knowledge-base-graphrag
RoleArn: arn:aws:iam::111122223333:role/BedrockExecutionRoleForKnowledgeBase
KnowledgeBaseConfiguration:
Type: VECTOR
VectorKnowledgeBaseConfiguration:
EmbeddingModelArn: arn:aws:bedrock:us-west-2::foundation-model/amazon.titan-embed-text-v2:0
StorageConfiguration:
Type: NEPTUNE_ANALYTICS
NeptuneAnalyticsConfiguration:
GraphArn: arn:aws:neptune-graph:us-west-2:111122223333:graph/g-abc123example
FieldMapping:
MetadataField: metadata
TextField: text
GraphRagDataSource:
Type: AWS::Bedrock::DataSource
Properties:
Name: graph_rag_source
KnowledgeBaseId: !Ref GraphRagKnowledgeBase
DataSourceConfiguration:
Type: S3
S3Configuration:
BucketArn: arn:aws:s3:::example-graphrag-datasets
InclusionPrefixes:
- example-dataset/
VectorIngestionConfiguration:
ContextEnrichmentConfiguration:
Type: BEDROCK_FOUNDATION_MODEL
BedrockFoundationModelConfiguration:
ModelArn: arn:aws:bedrock:us-west-2:111122223333:inference-profile/us.anthropic.claude-haiku-4-5-20251001-v1:0
EnrichmentStrategyConfiguration:
Method: CHUNK_ENTITY_EXTRACTION
FieldMapping names the graph properties that hold the chunk text and metadata, and must match how the graph and its index were set up.The embedding model in the knowledge base configuration must produce vectors of the dimension the Neptune Analytics vector index was created with. If you created the graph with a 1,024-dimension index, use
amazon.titan-embed-text-v2:0 configured for 1,024, or a Cohere Embed model; do not pair it with a 1,536-dimension Titan G1 index.4.5 Ingestion and incremental sync
After the knowledge base and data source exist, you ingest. A sync extracts the graph structure and converts the raw documents into embeddings using the configured models:aws bedrock-agent start-ingestion-job \
--knowledge-base-id KB_ID \
--data-source-id DS_ID
KnowledgeBaseDocuments API lets you add, update, or delete individual documents in a single action without a full data-source sync, which suits event-driven pipelines where individual files change frequently. Either way, the graph is derived from the corpus: when a document changes, the entities and relationships extracted from it change, and the graph is updated accordingly on the next sync or direct-ingestion call. Keeping the graph current is therefore an ingestion-pipeline concern, not a separate graph-maintenance job — a point Section 7 returns to.A re-sync is idempotent at the document level: re-ingesting a changed document replaces the entities and edges previously extracted from it, and removing a document from S3 deletes its contributions from the graph on the next sync. You therefore reason about graph state in terms of the current corpus, not an accumulating history of edits — which is what makes a scheduled sync (or direct ingestion of just the changed files) a complete freshness strategy rather than one that drifts over time.
4.6 Build-time limits to design around
A handful of fixed limits shape how you structure a GraphRAG knowledge base:- S3 is the only supported data source. Non-S3 connectors (web crawlers, Confluence, SharePoint, and so on) are not available for GraphRAG. If your corpus lives elsewhere, stage it into S3 first.
- File count per data source is capped. Each data source supports up to 1,000 files, increasable to a maximum of 10,000 through a service-limit request. Alternatively, partition the bucket into folders, each holding up to 1,000 files, with each folder a data source — a clean way to scale and also to enforce data boundaries (Section 7).
- Graph build is not customizable. Configuration options to customize how the graph is built are not supported; you select the models and chunking strategy, but you do not tune the extraction schema.
- Autoscaling is not supported for the Neptune Analytics graph. You size m-NCUs and resize deliberately; the graph does not scale capacity automatically.
- Hierarchical chunking returns child chunks only. If you choose hierarchical chunking, GraphRAG retrieves the child chunks during search and does not substitute their parent chunks, so results carry the specific child content rather than the broader parent context. Default chunking is the documented recommendation for GraphRAG.
5. Hybrid Retrieval: Vector Search plus Graph Traversal
This is the core of the architecture: what happens when a query arrives. The short version is vector first, then graph. The longer version is what makes multi-hop work, and what its limits are.5.1 The retrieval mechanism, step by step
When you callRetrieve or RetrieveAndGenerate against a GraphRAG knowledge base, the service performs the following, all inside a single API call:- Initial vector search. The query is embedded and a semantic search finds the top-k most relevant chunks/nodes — the entry points into the corpus.
- Find linked graph nodes. For the matched chunks, GraphRAG retrieves the related graph nodes or chunk identifiers that are linked to them — the entities in those chunks, and the chunks connected through shared entities.
- Traverse the neighborhood. It expands on those related nodes by traversing the surrounding graph and retrieving their details from the graph store, gathering connected content that the initial vector search did not surface on its own.
- Assemble enriched context. The matched chunks plus their graph neighborhood become the retrieval result. For
RetrieveAndGenerate, this enriched context is passed to the generation model; forRetrieve, it is returned to your application to use as you see fit.
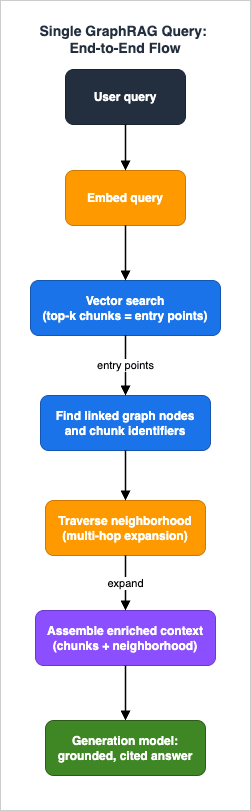
To make this concrete, take the supply-chain question from Section 1. The vector search on "port disruption affecting Q3 logistics" lands on the incident-report chunk that describes event D — the entry point. From that chunk, GraphRAG follows the graph to the entities it mentions, reaching supplier S; from S it traverses the "sourced from" edge to component C, and from C the "used in" edge to product line P. None of the procurement or bill-of-materials chunks resembled the original query, so a pure vector search would never have ranked them highly; the traversal reaches them in a few hops because the shared entities are explicit nodes rather than coincidental text similarities. The chunks gathered along that path — incident report, procurement record, bill of materials — become the enriched context the generation model reasons over to answer which product lines are exposed.
5.2 Calling it from your application
The retrieval call is the ordinary Bedrock Agent Runtime API. To retrieve only (and orchestrate generation yourself):aws bedrock-agent-runtime retrieve \
--knowledge-base-id KB_ID \
--retrieval-query '{"text": "Which product lines depend on suppliers affected by the Q3 port disruption?"}'
import boto3
agent_runtime = boto3.client("bedrock-agent-runtime")
resp = agent_runtime.retrieve(
knowledgeBaseId="KB_ID",
retrievalQuery={"text": "Which product lines depend on suppliers affected by the Q3 port disruption?"},
retrievalConfiguration={
"vectorSearchConfiguration": {
"numberOfResults": 10
}
},
)
for result in resp["retrievalResults"]:
print(result["content"]["text"], result.get("score"), result["location"])
retrievalResults carries the chunk text (content.text), a relevance score, and a location identifying the source — for an S3 data source, the object URI — so you can render provenance directly from the retrieve response without a second lookup. The same neighborhood the traversal gathered is reflected in the set of results you receive, which is why a multi-hop query returns chunks from documents the literal query terms never matched.To retrieve and generate in one call, supply a generation model ARN:
resp = agent_runtime.retrieve_and_generate(
input={"text": "Which product lines depend on suppliers affected by the Q3 port disruption?"},
retrieveAndGenerateConfiguration={
"type": "KNOWLEDGE_BASE",
"knowledgeBaseConfiguration": {
"knowledgeBaseId": "KB_ID",
"modelArn": "arn:aws:bedrock:us-west-2:111122223333:inference-profile/us.anthropic.claude-opus-4-8",
"retrievalConfiguration": {
"vectorSearchConfiguration": {
"numberOfResults": 10
}
},
},
},
)
print(resp["output"]["text"])
for citation in resp["citations"]:
for ref in citation["retrievedReferences"]:
print(ref["location"])
5.3 Controlling retrieval: numberOfResults, filters, and the SEMANTIC-only nuance
A fewvectorSearchConfiguration parameters govern the vector phase that seeds the traversal:numberOfResultssets how many source chunks the vector search returns, with a valid range of 1 to 100. Because these chunks are the entry points for traversal, this number influences not just the immediate matches but the breadth of the neighborhood explored. A larger value broadens entry points (and the traversal that follows); a smaller value keeps retrieval tight. Tune it against latency and answer quality rather than maximizing it.filterapplies metadata filters to the knowledge base data-source metadata before returning results, which is the mechanism for tenant and sensitivity boundaries (Section 7).rerankingConfigurationcan reorder the initial vector results with a reranker model before they seed traversal. Reranking is developed in depth in the Agentic RAG article; here it is enough to know it operates on the vector phase.
One parameter is a common source of confusion:
overrideSearchType with values HYBRID or SEMANTIC. This option lets you force a hybrid of vector embeddings and raw keyword text — but it is available only for an Amazon OpenSearch Serverless vector store with a filterable text field. For other vector store configurations, including Neptune Analytics, only SEMANTIC search is available.This is worth stating carefully because the word "hybrid" means two different things here. The API's
HYBRID means vector plus keyword search within a single index, and it does not apply to GraphRAG. GraphRAG's "hybrid" means vector plus graph traversal, which is the built-in behavior of the Neptune Analytics store and is not controlled by overrideSearchType. Do not try to "turn on hybrid" for a GraphRAG knowledge base via that parameter — the vector-plus-graph behavior is already what you get, and the keyword-hybrid mode is simply a different store's feature.5.4 When multi-hop helps, when it is wasted, and when it over-expands
Multi-hop traversal is powerful but not free, and being precise about its envelope is the difference between a system that feels insightful and one that feels noisy.Where it clearly helps. Questions whose answer is a path through entities — supply-chain exposure, incident correlation, legal precedent chains, "how is A connected to C through B" — are exactly what traversal is for. Here the graph supplies links the vector search would never have ranked highly, and the generation model receives a connected sub-graph of evidence rather than a handful of loosely related passages. The published GraphRAG use cases (financial market research, manufacturing data correlation, cybersecurity incident analysis) are all of this shape: facts dispersed across documents, connected by shared entities.
Where it is wasted. For single-passage fact lookups and single-document summaries, the traversal step adds latency and tokens without improving the answer, because the relevant content was already in the top-k vector results. The neighborhood it gathers is, at best, harmlessly redundant. If your traffic is dominated by these questions, you are paying for a graph you do not use — the routing point from Section 3.
Where it over-expands. This is the failure mode specific to graph retrieval. A "hub" entity — one that appears in a great many chunks (a common product name, a frequently mentioned standard, the company's own name) — has a large neighborhood. Traversing from a hub pulls in a wide, weakly-relevant set of chunks, diluting the genuinely relevant evidence with noise and inflating the context handed to the generation model. The symptom is answers that wander into tangentially related material, or that cite many sources but reason shallowly. Over-expansion is the graph analogue of retrieving too large a top-k in vector RAG, and Section 8 treats how to detect and contain it. The levers are upstream: a tighter
numberOfResults to limit entry points, and corpus hygiene so that genuinely distinct entities are not collapsed into one over-connected hub.The honest summary is that GraphRAG improves recall on relationship questions at the cost of precision risk from over-connected entities and latency from traversal. It is the right default for corpora rich in cross-document relationships and the wrong default for corpora of independent, self-contained documents.
6. Generation, Grounding, and Explainability
Retrieval produces evidence; generation turns it into an answer. With GraphRAG the generation step is the same Bedrock generation call as vector RAG, but two things change in character: the context is a connected neighborhood rather than a flat list, and the provenance is more legible because the connections are explicit.6.1 Generation over a connected neighborhood
When you useRetrieveAndGenerate, the enriched context — matched chunks plus their traversed neighborhood — is passed to the generation model along with the query, and the model composes a grounded answer. You select the generation model with modelArn; current choices on Amazon Bedrock include Anthropic Claude models (for example us.anthropic.claude-opus-4-8, us.anthropic.claude-sonnet-4-6, us.anthropic.claude-haiku-4-5-20251001-v1:0) and the Amazon Nova family. Model selection is a generation-quality and latency decision; verify the current model IDs and their context windows against the Bedrock model catalog and the model documentation rather than from memory, because the lineup moves quickly. (For Claude model identifiers, characteristics, and context windows, the canonical source is Anthropic's model documentation; this article deliberately states no pricing — consult the official Amazon Bedrock pricing page.)Because the retrieved context for a multi-hop question is a connected set of facts, the generation model is being asked to reason across the neighborhood, not just paraphrase the closest passage. This is where the larger, more capable generation models earn their cost: the value of GraphRAG is partly realized in retrieval (assembling the right evidence) and partly in generation (reasoning over it coherently). A weak generation model handed a rich neighborhood will still produce a shallow answer.
6.2 Explainability: citations and explicit connections
A recurring claim for GraphRAG is that it is more explainable than pure vector RAG, and it is worth being precise about why.RetrieveAndGenerate returns citations — the retrieved references that grounded the answer, with their source locations — exactly as vector RAG does, so you can show users which documents the answer came from. The additional explainability of GraphRAG comes from the graph itself: the connections the retrieval followed are explicit edges between entities and chunks, not an opaque similarity score. When an answer asserts that product line P is exposed to disruption D, the supporting structure is a traceable path P → component C → supplier S → event D in the graph, and you can surface or audit that path.Two caveats keep this claim honest. First, explainability is about retrieval provenance, not a guarantee of correctness — a traceable path can still be built on a mis-extracted relationship (Section 8). Second, contextual grounding checks and other content-safety controls — verifying that the generated answer is actually grounded in the retrieved context, blocking disallowed topics, and redacting sensitive content — are a separate concern handled by Amazon Bedrock Guardrails, which
RetrieveAndGenerate can apply. The mechanics of Guardrails (contextual grounding, denied topics, PII, independent ApplyGuardrail) are out of scope here and belong to a dedicated responsible-AI treatment; this article only notes the integration point so the architecture is complete. For the agentic pattern that grades retrieval quality and re-queries when grounding is weak — the natural next step once you can detect a poorly grounded answer — see Agentic RAG Architecture on Amazon Bedrock.7. Cross-Cutting: IAM, Data Boundaries, and Graph Maintenance
A retrieval architecture is only production-ready when the horizontal concerns are handled: who can call what, how tenant and sensitivity boundaries are enforced, and how the graph stays correct over time.7.1 Least-privilege IAM across the chain
There are two distinct identities to scope. The knowledge base service role is assumed by Bedrock to build and query the graph; the caller identity is your application invoking the runtime APIs.The service role needs access to the Neptune Analytics graph, the S3 source bucket, and the models. The Neptune Analytics portion is a focused set of graph actions on the specific graph ARN:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "NeptuneAnalyticsAccess",
"Effect": "Allow",
"Action": [
"neptune-graph:GetGraph",
"neptune-graph:ReadDataViaQuery",
"neptune-graph:WriteDataViaQuery",
"neptune-graph:DeleteDataViaQuery"
],
"Resource": [
"arn:aws:neptune-graph:us-west-2:111122223333:graph/g-abc123example"
]
}
]
}
bedrock:InvokeModel on the embedding and graph construction models. A convenient property of the managed flow is that when you select a graph construction model, the required model-invocation permissions are added to the service role automatically — but you should still review the role to confirm it is scoped to the specific graph ARN and S3 prefix rather than a wildcard, because the auto-added permissions cover models, not your blast-radius decisions on the graph and bucket.The caller identity needs only
bedrock:Retrieve and/or bedrock:RetrieveAndGenerate on the knowledge base, plus bedrock:InvokeModel on the generation model when using RetrieveAndGenerate:{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "QueryKnowledgeBase",
"Effect": "Allow",
"Action": [
"bedrock:Retrieve",
"bedrock:RetrieveAndGenerate"
],
"Resource": "arn:aws:bedrock:us-west-2:111122223333:knowledge-base/KB_ID"
},
{
"Sid": "InvokeGenerationModel",
"Effect": "Allow",
"Action": "bedrock:InvokeModel",
"Resource": "arn:aws:bedrock:us-west-2::foundation-model/anthropic.claude-sonnet-4-6"
}
]
}
bedrock:InvokeModel to the inference-profile ARN and the destination foundation-model ARNs it routes to, following the cross-Region inference prerequisites. Either way, the caller does not need direct neptune-graph:* permissions — the application never touches Neptune directly; Bedrock mediates every graph access through the service role. This indirection is a security feature: your application's blast radius is "can ask this knowledge base questions," not "can read or write the graph."7.2 Data boundaries: partitioning and metadata filters
Two complementary mechanisms enforce who-sees-what. The coarse-grained one is partitioning by data source: because each S3 folder can be its own data source (each up to 1,000 files), a natural tenant or sensitivity boundary is one data source — and, if isolation must be hard, one knowledge base and one graph — per tenant. Separate graphs guarantee that traversal can never cross a tenant boundary, because the edges to cross simply do not exist in another tenant's graph.The fine-grained one is metadata filtering at query time via the
filter parameter, which restricts results to chunks whose metadata matches an expression before they are returned. This is the right tool for sensitivity tiers within a shared corpus. The caveat from Section 5.3 applies: confirm the metadata-filter behavior for the Neptune Analytics GraphRAG store against the official documentation before relying on it as a hard security boundary, and prefer separate graphs when the boundary is between mutually distrusting tenants rather than between sensitivity tiers of the same tenant.A residency note from Section 4 belongs here too: when the graph construction model runs via a cross-Region inference profile, the ingested data is stored only in the source Region; the destination Region performs inference and does not retain the data. For most residency reviews the relevant fact is that the knowledge base and the Neptune Analytics graph — where your data actually lives — are single-Region resources.
7.3 Graph maintenance: the graph is derived, not authored
The most important operational mental model is that the graph is a derived artifact of the corpus. You never edit nodes and edges by hand; you change documents in S3 and re-ingest, and the graph is rebuilt from the new extractions. This has three consequences:- Freshness is an ingestion concern. Keeping the graph current means keeping ingestion current — scheduled syncs for batch updates, or direct ingestion via the
KnowledgeBaseDocumentsAPI for event-driven updates as individual files change. - Correctness is an extraction concern. The graph is only as good as the entity/relationship extraction. Improving graph quality means improving the inputs (cleaner source documents, a more capable graph construction model) rather than patching the graph.
- Lifecycle is a two-step delete. Deleting the knowledge base does not delete the underlying Neptune Analytics graph; you must delete the graph separately, or set the data-source deletion policy to
RETAIN. Until the graph is explicitly deleted, it continues to exist (and to incur charges). Bake this into teardown runbooks and infrastructure-as-code so orphaned graphs do not accumulate.
8. Observability and Failure Modes
The failure modes of GraphRAG overlap with vector RAG but add graph-specific ones. The discipline is the same: name the symptom, find the root cause, isolate it, and correct it — with metrics and logs, not guesswork.8.1 What to observe
Observe the three stages separately, because a bad answer can originate in any of them:- Ingestion / graph build. Ingestion job status and document-level success/failure, the count of files processed against your per-data-source limit, and sync duration. A failed or partial sync means the graph does not reflect the corpus.
- Retrieval. The number and scores of vector matches (the entry points), the size of the traversed neighborhood, and end-to-end retrieval latency. A neighborhood that is consistently huge is the over-expansion signal from Section 5.4.
- Generation. Model invocation logs and latency. Amazon Bedrock model invocation logging captures the generation calls; route logs to CloudWatch (or S3) and alarm on error rates and latency budgets.
Concretely, the
Retrieve response carries a per-result score and location for every entry point — log these to see whether the vector phase is landing on relevant chunks before traversal even begins. Ingestion health comes from the ingestion-job APIs: a GetIngestionJob call reports per-document indexed and failed counts, so a partial sync surfaces as a concrete failed-document count rather than a silent gap in the graph. For the generation step, enable Amazon Bedrock model invocation logging, route it to CloudWatch, and alarm on error rate and p90 latency against your budget.For the generation step, Bedrock invocation logging and CloudWatch are the baseline. For end-to-end tracing across retrieval and generation in an agentic system, the observability and evaluation tooling — traces, step metrics, and automated quality gates — is the subject of a dedicated LLMOps treatment and is delegated there; this article covers the GraphRAG-specific signals only.
8.2 Failure modes, symptom to remedy
| Failure mode | Symptom | Root cause and remedy |
|---|---|---|
| Extraction noise | Answers assert relationships that are not real; citations trace to a wrong or hallucinated edge. | The graph construction model mis-extracted entities or relationships. Remedy upstream: cleaner source documents, a more capable graph construction model, and spot-checking the graph (the Neptune console graph explorer lets you inspect what was built). The graph is derived — fix the inputs, re-ingest. |
| Over-expansion (hub entities) | Answers wander into weakly related material; many citations but shallow reasoning; large traversed neighborhoods. | Traversal started from or passed through an over-connected hub entity. Lower numberOfResults to tighten entry points; improve corpus hygiene so distinct entities are not collapsed into one node; consider partitioning the corpus so hubs are scoped. |
| Missing connection (under-recall) | A multi-hop question returns an incomplete answer; the connecting document exists but was not used. | The relationship was never extracted (so the edge does not exist), or the entry-point vector search did not land near the chain. Verify the entity exists in the graph; broaden entry points modestly; ensure the connecting documents were ingested successfully. |
| Sync failure / stale graph | Answers reflect outdated facts; recently changed documents are not represented. | An ingestion job failed or has not run since the corpus changed. Check ingestion job status and per-document results; re-run sync or use direct ingestion for the changed files. |
| Dimension / config mismatch | Knowledge base creation or ingestion fails; vectors are rejected. | The embedding model dimension does not match the Neptune Analytics vector index. The index dimension is fixed at graph creation — recreate the graph with the correct dimension or switch to a matching embedding model. |
| Latency budget exceeded | End-to-end response time is too high for the use case. | Traversal breadth (driven by entry points and hub connectivity) and generation-model choice dominate latency. Reduce numberOfResults, contain over-expansion, and consider a faster generation model for latency-sensitive paths. |
| Orphaned graph after teardown | A Neptune Analytics graph persists (and incurs charges) after the knowledge base is gone. | Deleting the knowledge base does not delete the graph. Delete the graph explicitly, or use a RETAIN data-source deletion policy and manage the graph lifecycle in IaC. |
The cross-cutting blast-radius observation is that a single mis-extracted relationship does not stay local: because traversal follows edges, a wrong edge can pull an unrelated chunk into the neighborhood of many queries that pass through the affected entity. That is why extraction quality and corpus hygiene are leverage points — they affect not one answer but every traversal that crosses the affected node. Containment is therefore upstream (extraction, hygiene, partitioning) far more than downstream (post-filtering answers).
9. Variations and Limits: When GraphRAG Is Overkill
GraphRAG is a sharp tool with a specific edge, and using it where a simpler approach suffices is its own kind of mistake. A few boundaries worth drawing:- Self-contained corpora. If your documents are independent and most answers live in a single passage, a flat vector store is simpler, cheaper, and lower-latency. The graph adds a store to provision, a model to invoke during ingestion, and a traversal step that returns redundant context. Stay with vector RAG (the RAG Architecture Guide).
- Corpus-wide "global" questions. Both vector search and neighborhood traversal are local — they start from entry points and expand around them. Questions that require aggregating across the entire corpus ("what are the top five themes across all 50,000 documents?") are a different problem that neighborhood-traversal GraphRAG does not directly solve; they need a summarization or community-detection approach over the whole graph rather than per-query traversal.
- Highly dynamic corpora. Because the graph is rebuilt from extractions on ingestion, very high document-churn rates make graph freshness an ongoing cost. Direct ingestion mitigates this, but if the corpus changes faster than you can re-extract, the graph will trail reality.
- Need for a custom graph schema. GraphRAG does not let you customize how the graph is built. If your use case needs a hand-modeled ontology, typed relationships, or graph algorithms beyond traversal, a self-managed approach — Neptune Analytics directly, or the open-source GraphRAG toolkit, or a framework integration — gives you control that the fully managed path intentionally hides. That control is a different article; the managed path is the right default when you want GraphRAG's benefits without graph expertise.
On cost: this article states no figures by policy, but the qualitative shape matters for the decision. GraphRAG adds the always-on cost of a Neptune Analytics graph (sized in m-NCUs, not autoscaled), the ingestion-time cost of invoking the graph construction model on every chunk, and the per-query cost of a larger generation context. Weigh those against the value of answering relationship questions that vector RAG cannot. Consult the official Amazon Bedrock and Amazon Neptune Analytics pricing pages for current figures; design the architecture on question shape and the budget on those pages.
10. Frequently Asked Questions
Is GraphRAG generally available, or still preview?It is generally available. Amazon Bedrock Knowledge Bases GraphRAG with Amazon Neptune Analytics moved from a re:Invent 2024 preview to general availability, and is fully integrated into Bedrock Knowledge Bases.
Do I need to know graph modeling or a query language?
No. The graph is created and maintained automatically from your S3 documents; you select an embedding model and a graph construction model and Bedrock extracts the entities and relationships. You do not author the schema or write Gremlin/openCypher for the managed retrieval path.
Which data sources are supported?
Amazon S3 only. Stage other sources into S3 first.
Does retrieval require a different API than vector RAG?
No. The same
Retrieve and RetrieveAndGenerate operations work; the vector-then-graph behavior happens server-side in a single call, so application code is unchanged.Can I turn on "hybrid" search with
overrideSearchType: HYBRID?Not for GraphRAG. The
HYBRID option (vector plus keyword) applies only to an Amazon OpenSearch Serverless store with a filterable text field; for Neptune Analytics only SEMANTIC is available. GraphRAG's "hybrid" is vector plus graph traversal, which is built in and not controlled by that parameter.What embedding dimensions do I need?
The Neptune Analytics vector index dimension must match the embedding model: Titan G1 is 1,536; Titan V2 supports 1,024 / 512 / 256; Cohere Embed is 1,024. The index dimension is fixed when the graph is created.
In which Regions is GraphRAG available?
At the time of writing, Europe (Frankfurt), Europe (London), Europe (Ireland), US West (Oregon), US East (N. Virginia), Asia Pacific (Tokyo), and Asia Pacific (Singapore). Confirm current Region availability in the official documentation before deploying.
What happens to the graph when I delete the knowledge base?
Nothing automatically — the Neptune Analytics graph is not deleted with the knowledge base. Delete it explicitly or use a
RETAIN deletion policy, and remember it continues to incur charges until removed.When should I not use GraphRAG?
When your corpus is self-contained and answers are single-passage (use vector RAG), when you need corpus-wide global aggregation (a different technique), or when you need a custom graph schema (a self-managed approach).
11. Summary
Vector RAG answers "which passage looks like this question?" and that is the wrong question when the answer is a chain of relationships spanning several documents. GraphRAG on AWS adds a second representation — a knowledge graph of entities and relationships, built automatically from your S3 corpus and co-located with the embeddings in Amazon Neptune Analytics — and changes retrieval from "find similar chunks" to "find similar chunks, then traverse their graph neighborhood." That vector-first, graph-second mechanism is what makes multi-hop, cross-document retrieval work, and it is exposed through the sameRetrieve and RetrieveAndGenerate calls you already use, so the application surface does not change.The architecture is genuinely managed: you choose an embedding model and a graph construction model, point a knowledge base at S3, and Bedrock extracts entities, builds the graph, and stores vectors and graph together. The engineering judgment is in knowing the envelope — multi-hop traversal raises recall on relationship questions but adds latency and a precision risk from over-connected hub entities — and in the cross-cutting discipline: least-privilege IAM scoped to the specific graph and bucket, data boundaries by partitioning and metadata filters, a graph kept current through ingestion because it is derived rather than authored, observability split across ingestion, retrieval, and generation, and a teardown that explicitly deletes the graph. Used where the question shape calls for it, GraphRAG answers questions vector RAG cannot; used everywhere, it is overhead. Match the tool to the question, and delegate the floor — static RAG, the agentic loop, content safety, and evaluation — to the focused guides those topics deserve.
12. References
- Build a knowledge base with Amazon Neptune Analytics graphs (Amazon Bedrock User Guide)
- Create an Amazon Bedrock knowledge base with Amazon Neptune Analytics graphs
- Prerequisites for using a vector store you created for a knowledge base
- Create a service role for Amazon Bedrock Knowledge Bases (Neptune Analytics permissions)
- Query a knowledge base connected to an Amazon Neptune Analytics graph
- Amazon Bedrock Agent Runtime API Reference: Retrieve
- Amazon Bedrock Agent Runtime API Reference: RetrieveAndGenerate
- KnowledgeBaseVectorSearchConfiguration (numberOfResults, filter, overrideSearchType, reranking)
- Amazon Bedrock model lifecycle
- Increase throughput with cross-Region inference (Amazon Bedrock)
- What is Amazon Neptune Analytics?
- Announcing general availability of Amazon Bedrock Knowledge Bases GraphRAG with Amazon Neptune Analytics (AWS Machine Learning Blog)
- Build GraphRAG applications using Amazon Bedrock Knowledge Bases (AWS Machine Learning Blog)
- Amazon Bedrock RAG Architecture Guide (static RAG foundation)
- Agentic RAG Architecture on Amazon Bedrock
- AI Agent Engineering Glossary
- Amazon Bedrock Glossary
References:
Tech Blog with curated related content
Written by Hidekazu Konishi