AWS History and Timeline regarding Amazon Kinesis - Overview, Functions, Features, Summary of Updates, and Introduction
First Published:
Last Updated:
Over more than a decade it has grown from a single stream-processing service into a family of services - Amazon Kinesis Data Streams, Amazon Data Firehose (formerly Amazon Kinesis Data Firehose), Amazon Managed Service for Apache Flink (formerly Amazon Kinesis Data Analytics), and Amazon Kinesis Video Streams - that together cover ingestion, stateful stream processing, delivery to data lakes and analytics stores, and live video.
Because the Kinesis family has accumulated a long list of capabilities, and because two of its services have been renamed, it is easy to lose track of when a given capability actually arrived and what a service is called today: When did Amazon Kinesis Data Streams launch? When did Firehose appear, and when did it become "Amazon Data Firehose"? When did Kinesis Data Analytics become "Amazon Managed Service for Apache Flink"? When did on-demand capacity, Enhanced Fan-Out, or WebRTC video streaming arrive? This article answers those questions in one place.
This article organizes the history of Amazon Kinesis into a single chronological timeline, drawn from primary AWS sources, and then summarizes the Current Overview, Functions, Features of Amazon Kinesis. It is intended as a reference page you can return to whenever you need to confirm when a particular Amazon Kinesis capability became available. The focus is on major, service-level releases and the two renames that define what Amazon Kinesis is today, not on every minor SDK revision or single-Region rollout.
Background and Method of Creating Amazon Kinesis Historical Timeline
The purpose of this timeline is twofold:- Tracking the history of Amazon Kinesis and organizing the transition of its updates over time.
- Summarizing the feature list and characteristics of the Amazon Kinesis family as it stands today.
- What's New with AWS?
- AWS News Blog
- Amazon Kinesis Data Streams Document history
- Amazon Data Firehose Developer Guide
Please note that the items on this timeline are not all updates to Amazon Kinesis features, but are representative updates that I have picked out. Pricing changes and single-Region expansions are intentionally omitted; AWS pricing changes frequently, so for current pricing always consult the official Amazon Kinesis pricing pages.
A note on naming, because it is central to this timeline. The names in the Amazon Kinesis family have evolved through several steps, and AWS preserved full backward compatibility throughout (APIs, endpoints, IAM policies, and Amazon CloudWatch metrics were unchanged). The major naming chains are:
- Amazon Kinesis → Amazon Kinesis Streams → Amazon Kinesis Data Streams. The original 2013 service was simply called Amazon Kinesis. When Amazon Kinesis Firehose launched on October 7, 2015, AWS began calling the original service Amazon Kinesis Streams to distinguish the two, and it was later renamed again to Amazon Kinesis Data Streams as part of the family-wide "Data" alignment described below.
- Amazon Kinesis Firehose → Amazon Kinesis Data Firehose → Amazon Data Firehose. Firehose launched in 2015 as Amazon Kinesis Firehose, became Amazon Kinesis Data Firehose in the same "Data" alignment, and was finally renamed to Amazon Data Firehose on February 9, 2024. The CLI namespace remains
firehose. - Amazon Kinesis Analytics → Amazon Kinesis Data Analytics → Amazon Managed Service for Apache Flink. The SQL analytics service launched in 2016 as Amazon Kinesis Analytics, became Amazon Kinesis Data Analytics in the "Data" alignment, and was renamed to Amazon Managed Service for Apache Flink on August 30, 2023. The SDK/CLI identifier remains
kinesisanalyticsv2.
Throughout this article, the modern names are used as the primary names, with the former names noted where it aids historical clarity. In the timeline itself, each entry uses the name that the service or feature carried at that point in time (for example, "Amazon Kinesis Firehose" and "Amazon Kinesis Data Analytics" for events before their respective renames), so the chronology reflects how the names actually evolved.
Because Amazon Kinesis is a family of four services rather than a single product, the timeline below interleaves milestones from all of them - Amazon Kinesis Data Streams (ingestion), Amazon Data Firehose (delivery), Amazon Managed Service for Apache Flink (processing), and Amazon Kinesis Video Streams (media) - in a single chronological order. Reading it top to bottom shows not only when individual capabilities arrived, but also how the family grew outward from the original 2013 stream-processing service into a complete streaming-data platform.
Amazon Kinesis was first announced in November 2013 at AWS re:Invent. The original announcement is preserved here: Amazon Kinesis - Real-Time Processing of Streaming Big Data.
Amazon Kinesis Historical Timeline (Updates from November 14, 2013)
Now, here is a timeline related to the functions of the Amazon Kinesis family. As of the time of writing this article, the history of Amazon Kinesis spans more than a decade since its announcement in November 2013, across the four services that make up the family today.2013 | 2014 | 2015 | 2016 | 2017 | 2018 | 2019 | 2020 | 2021 | 2022 | 2023 | 2024 | 2025 | 2026
* The table can be sorted by clicking on the column names.
| Date | Summary |
|---|---|
| 2013-11-14 | Amazon Kinesis is announced at AWS re:Invent as a managed service for real-time processing of streaming big data. It was introduced as a limited preview, designed to capture and process large volumes of data from sources such as website clickstreams, financial transactions, social media feeds, and operational logs. References: Amazon Kinesis - Real-Time Processing of Streaming Big Data |
| 2013-12-17 | Amazon Kinesis opens to the public in beta form. With the public beta, AWS also added support for the CORS (Cross-Origin Resource Sharing) standard, allowing JavaScript running in a web browser to put data into Amazon Kinesis directly. This is the service later known as Amazon Kinesis Data Streams. References: Amazon Kinesis - Public Beta Now Open |
| 2014-11-13 | AWS Lambda is announced with Amazon Kinesis as one of its initial event sources. This pairing made serverless stream processing possible: a Lambda function can be invoked automatically as records arrive on a Kinesis data stream, without managing any consumer fleet. References: AWS Lambda - Run Code in the Cloud |
| 2015-06-02 | The Amazon Kinesis Producer Library (KPL) is introduced. The KPL is a highly configurable, high-performance library that simplifies writing records to a data stream, with automatic batching, aggregation, and retry handling for producers. References: Amazon Kinesis Data Streams Document history |
| 2015-10-02 | The Amazon Kinesis Agent becomes available for writing to data streams. The agent is a standalone Java application that continuously monitors files and sends new records to a data stream, making it easy to ingest log files without writing custom producer code. References: Amazon Kinesis Data Streams Document history |
| 2015-10-07 | Amazon Kinesis Firehose is introduced as the easiest way to load streaming data into AWS. Firehose is a fully managed service that captures and automatically loads streaming data into Amazon S3 and Amazon Redshift, batching, compressing, and encrypting data before delivery, with no application to write or resources to manage. It launched in the US East (N. Virginia), US West (Oregon), and EU (Ireland) Regions. References: Introducing Amazon Kinesis Firehose |
| 2015-10-07 | The original Amazon Kinesis service is renamed Amazon Kinesis Streams. Alongside the launch of Amazon Kinesis Firehose on the same day, AWS began calling the original 2013 stream-processing service "Amazon Kinesis Streams" to distinguish it from the new delivery service; as the Firehose launch announcement put it, "Two years ago we introduced Amazon Kinesis, which we now call Amazon Kinesis Streams." This service was later renamed again to Amazon Kinesis Data Streams as part of the family-wide "Data" alignment (see the naming note above). References: Introducing Amazon Kinesis Firehose |
| 2016-04-19 | Enhanced, shard-level Amazon CloudWatch metrics arrive for Amazon Kinesis Streams. Operators gained finer-grained visibility into stream behavior, monitoring metrics per shard to detect hot shards and tune capacity. References: Amazon Kinesis Data Streams Document history |
| 2016-04-19 | Amazon Kinesis Firehose adds Amazon Elasticsearch Service as a delivery destination, along with enhanced monitoring. Firehose could now stream data continuously into Amazon Elasticsearch Service (later Amazon OpenSearch Service) domains, and could log data-delivery errors to Amazon CloudWatch Logs for easier troubleshooting. References: Amazon Kinesis Firehose adds Amazon Elasticsearch Data Ingestion and Enhanced Monitoring Features |
| 2016-08-11 | Amazon Kinesis Analytics launches, letting you process streaming data in real time with standard SQL. Built on a proprietary SQL engine, it allowed developers to run continuous queries against streaming data using tumbling, sliding, and custom windows, without managing processing infrastructure. This service is the ancestor of today's Amazon Managed Service for Apache Flink. References: Amazon Kinesis Analytics - Process Streaming Data in Real Time with SQL |
| 2016-11-15 | Amazon Kinesis Streams adds the UpdateShardCount API for automatic, API-driven resharding, along with DescribeLimits. Instead of manually splitting and merging shards, you can scale a stream up or down to a specific shard count with a single API call, and monitor your account's shard usage against its limit. References: Automate Amazon Kinesis Streams scaling and shard limit monitoring using new APIs |
| 2017-07-07 | Server-side encryption (SSE) becomes available for Amazon Kinesis Streams. Using AWS KMS keys, data is automatically encrypted at rest as it enters the stream and decrypted on retrieval, helping meet strict regulatory requirements without changes to producers or consumers. References: Amazon Kinesis Data Streams Document history |
| 2017-11-29 | Amazon Kinesis Video Streams launches at AWS re:Invent. It became the newest member of the Kinesis family, letting you ingest streaming video (or other time-encoded data) from millions of devices, storing it durably and in encrypted form with time-based indexes for playback and vision-enabled applications using services such as Amazon Rekognition Video. References: Amazon Kinesis Video Streams - Serverless Video Ingestion and Storage for Vision-Enabled Apps |
| 2017-12-05 | Amazon Kinesis Firehose is now referred to as Amazon Kinesis Data Firehose in AWS announcements. Following the launch of Amazon Kinesis Video Streams, AWS began aligning the data services in the family under the "Amazon Kinesis Data ..." names. This is the earliest official AWS announcement I have found using "Amazon Kinesis Data Firehose"; the November 21, 2017 console-enhancements post still used "Amazon Kinesis Firehose." APIs, endpoints, IAM policies, and CloudWatch metrics were unchanged. References: Amazon Kinesis Data Firehose announces the general availability of Splunk as a destination |
| 2017-12-21 | Amazon Kinesis Analytics is now referred to as Amazon Kinesis Data Analytics in AWS announcements. Continuing the family-wide "Data" naming, this is the earliest official AWS announcement I have found using "Amazon Kinesis Data Analytics" for the SQL analytics service previously called "Amazon Kinesis Analytics." References: Amazon Kinesis Data Analytics can now Output Real-Time SQL Results to AWS Lambda |
| 2018-02-06 | Amazon Kinesis Streams is now referred to as Amazon Kinesis Data Streams in AWS announcements. The original stream-processing service - called "Amazon Kinesis Streams" since 2015 - followed the rest of the family into the "Data" naming a little later; this is the earliest official AWS announcement I have found using "Amazon Kinesis Data Streams." References: 10x Higher API Call Rates for Amazon Kinesis Client Library (KCL) Applications |
| 2018-07-13 | Amazon Kinesis Video Streams adds HTTP Live Streams (HLS) output. Customers could create fully managed HLS endpoints to play back live and on-demand video in standard web and mobile players without building any transmuxing infrastructure. References: Amazon Kinesis Video Streams Adds Support For HLS Output Streams |
| 2018-08-02 | Amazon Kinesis Data Streams adds Enhanced Fan-Out and an HTTP/2 data retrieval API. Enhanced Fan-Out gives each registered consumer its own dedicated read throughput (up to 2 MB/s per shard per consumer) via the push-based SubscribeToShard API, removing contention between multiple consumers reading the same stream and enabling streaming up to 65% faster with 5x higher fan-out. References: Stream data 65% faster with 5x higher fan-out using new Kinesis Data Streams features |
| 2018-11-27 | Amazon Kinesis Data Analytics adds support for Java applications built on Apache Flink. This added a programmable option alongside SQL, with more than 25 pre-built stream-processing operators based on Apache Flink, exactly-once processing semantics, and durable application state - the beginning of the service's shift toward Apache Flink. References: Amazon Kinesis Data Analytics Now Supports Java-based Stream Processing Applications |
| 2019-12-04 | Amazon Kinesis Video Streams adds support for real-time, two-way media streaming with WebRTC. This fully managed capability includes a signaling endpoint plus managed STUN/TURN servers, enabling low-latency, peer-to-peer audio and video for use cases such as video doorbells, baby monitors, and camera-enabled devices. References: Amazon Kinesis Video Streams adds support for real-time two-way media streaming with WebRTC |
| 2020-07-29 | Amazon Kinesis Data Firehose adds delivery to generic HTTP endpoints and third-party providers. Firehose could now deliver streaming data directly to HTTP endpoints and partners such as Datadog, New Relic, MongoDB, and Splunk, broadening it from a data-lake loader into a general streaming delivery service. References: Amazon Kinesis Data Firehose now supports data delivery to HTTP endpoints |
| 2020-11-04 | Amazon Kinesis Data Streams increases the maximum data retention to one year. The retention period can be extended from the 24-hour default up to 365 days, so the same stream can serve both real-time consumers and longer-term reprocessing (for example, training machine learning models or meeting data-retention requirements) without moving data elsewhere. References: Amazon Kinesis Data Streams enables data stream retention up to one year |
| 2021-05-27 | Amazon Kinesis Data Analytics Studio launches, providing an interactive notebook experience powered by Apache Zeppelin and Apache Flink. Developers could query data streams interactively using SQL, Python, or Scala, and promote notebook code to a production stream-processing application with a few clicks. References: Announcing Amazon Kinesis Data Analytics Studio |
| 2021-08-31 | Amazon Kinesis Data Firehose introduces dynamic partitioning. Firehose can continuously partition streaming data in transit using keys within the data (such as customer_id) and deliver it into corresponding Amazon S3 prefixes, making analytics on the resulting data lake faster and more cost-efficient. References: Introducing Dynamic Partitioning in Amazon Kinesis Data Firehose |
| 2021-11-29 | Amazon Kinesis Data Streams introduces the on-demand capacity mode. On-demand streams automatically scale capacity to match traffic, so you no longer need to provision and manage shards; you pay for throughput used rather than for provisioned capacity. This complements the original provisioned (shard-based) mode. References: Amazon Kinesis Data Streams Document history |
| 2022-05-04 | Amazon Kinesis Video Streams adds managed support for image extraction. New APIs and SDKs let customers extract images from video streams on demand or automatically in real time, delivering them to Amazon S3 for use in machine learning pipelines (such as Amazon Rekognition and Amazon SageMaker) and for enhanced playback experiences. References: Amazon Kinesis Video Streams announces managed support for image extraction |
| 2022-12-01 | Amazon EventBridge Pipes becomes generally available, with Amazon Kinesis Data Streams as a supported source and target. Pipes provides a simpler, point-to-point way to connect event producers and consumers with optional filtering and enrichment; a Kinesis data stream can be used as a Pipes source (with shared-throughput or Enhanced Fan-Out consumers) or as a target, complementing AWS Lambda for stream integration. References: Amazon EventBridge Pipes is now generally available |
| 2023-03-01 | Amazon Kinesis Data Streams increases the On-Demand write throughput limit to 1 GB/s. The On-Demand write limit rose 5x from 200 MB/s to 1 GB/s per stream (with a further increase to 2 GB/s following in October 2023), making On-Demand suitable for much higher-volume workloads without shard management. References: Amazon Kinesis Data Streams increases On-Demand write throughput limit to 1 GB/s |
| 2023-08-15 | Amazon Kinesis Video Streams improves image extraction to 5 frames per second. The managed image-extraction capability increased its sampling frequency from one image every three seconds to 5 frames per second, supporting higher-fidelity machine learning inference and richer playback experiences. References: Amazon Kinesis Video Streams improves image sampling frequency to 5 frames per second |
| 2023-08-30 | Amazon Kinesis Data Analytics is renamed to Amazon Managed Service for Apache Flink. The rename reflects the service's evolution into a fully managed, serverless Apache Flink service; existing applications continued to run without changes, and the kinesisanalyticsv2 API identifier was retained. References: Announcing Amazon Managed Service for Apache Flink Renamed from Amazon Kinesis Data Analytics |
| 2023-09-27 | Amazon Kinesis Data Firehose adds Amazon MSK (Apache Kafka) as a fully managed source for delivery to Amazon S3. Customers can read directly from an Amazon MSK provisioned or serverless cluster and load the data into Amazon S3 with no connector code, including across AWS accounts. References: Amazon MSK now supports fully managed data delivery to Amazon S3 using Kinesis Data Firehose |
| 2023-11-08 | Amazon Kinesis Video Streams WebRTC ingestion becomes generally available. Beyond peer-to-peer streaming, customers can now ingest WebRTC media to the cloud for secure storage, playback, and analytical processing using an enhanced WebRTC SDK and cloud APIs. References: Amazon Kinesis Video Streams WebRTC Ingestion is now generally available |
| 2023-11-22 | Amazon Kinesis Data Streams adds the ability to share a data stream across AWS accounts. Producers and consumers in different accounts can be granted resource-level access to the same stream, simplifying multi-account streaming architectures. References: Amazon Kinesis Data Streams Document history |
| 2023-12-26 | Amazon Kinesis Data Firehose adds zero buffering. Customers can configure a delivery stream to deliver data without the default buffering interval, so most records reach destinations within seconds, enabling lower-latency, near-real-time use cases. References: Amazon Kinesis Data Firehose now supports zero buffering |
| 2024-02-09 | Amazon Kinesis Data Firehose is renamed to Amazon Data Firehose. The name change applies to the AWS Management Console, documentation, and service web pages; service endpoints, APIs, the AWS CLI (firehose), IAM policies, and Amazon CloudWatch metrics are unchanged, and existing applications continue to work as before. References: Introducing Amazon Data Firehose, formerly known as Amazon Kinesis Data Firehose |
| 2024-03-18 | Amazon Managed Service for Apache Flink adds in-place version upgrades for Apache Flink. Customers can upgrade an existing application to a newer Apache Flink runtime in place, retaining snapshots, logs, metrics, tags, and configuration, which makes it far easier to keep streaming applications on supported Apache Flink versions over time. References: Amazon Managed Service for Apache Flink adds in-place version upgrades for Apache Flink |
| 2024-04-17 | Amazon Data Firehose adds direct integration with Snowflake using Snowpipe Streaming. Firehose can deliver streaming records to Snowflake row by row within seconds, removing the need to batch through interim storage and reducing latency, cost, and complexity for loading streams into Snowflake. References: Stream data into Snowflake using Amazon Data Firehose and Snowflake Snowpipe Streaming |
| 2024-10-01 | Amazon Data Firehose can now deliver data streams directly into Apache Iceberg tables in Amazon S3. Firehose integrates with Apache Iceberg so that records from sources such as Kinesis Data Streams, Amazon MSK, and Direct PUT can be delivered into Iceberg tables, with routing to different tables and insert, update, or delete operations, and exactly-once delivery. References: Amazon Data Firehose delivers data streams into Apache Iceberg format tables in Amazon S3 |
| 2024-11-15 | Amazon Data Firehose adds continuous replication of database changes to Apache Iceberg tables in Amazon S3 (preview). Firehose can capture changes from databases such as MySQL and PostgreSQL and replicate them into Apache Iceberg tables, automatically creating tables to match source schemas and evolving them as the source changes. References: Amazon Data Firehose supports continuous replication of database changes to Apache Iceberg Tables in Amazon S3 |
| 2024-11-20 | Amazon Kinesis Data Streams On-Demand mode scales to 10 GB/s write and 20 GB/s read per stream. On-Demand streams now automatically scale to write up to 10 GB/s and serve up to 20 GB/s of reads per stream, a 5x increase from the previous 2 GB/s write and 4 GB/s read limits, removing capacity planning for very high-volume workloads. References: Amazon Kinesis Data Streams On-Demand mode supports streams writing up to 10GB/s |
| 2025-03-14 | Amazon Data Firehose integration with Amazon S3 Tables becomes generally available. Firehose can deliver real-time streaming data directly into Amazon S3 Tables (managed Apache Iceberg tables optimized for analytics), without code development or multi-step processes. References: Amazon Data Firehose now delivers real-time streaming data into Amazon S3 Tables |
| 2025-09-01 | Amazon Kinesis Data Analytics for SQL applications begins its planned discontinuation. From this date AWS provides only limited support for the legacy SQL service; new SQL applications cannot be created from October 15, 2025, and existing applications are scheduled to be deleted starting January 27, 2026. AWS recommends Amazon Managed Service for Apache Flink (including its Studio notebooks) instead. References: What Is Amazon Kinesis Data Analytics for SQL Applications? |
| 2025-10-15 | Amazon Kinesis Data Streams adds support for resilience testing with AWS Fault Injection Service (FIS). Teams can deliberately inject faults against data streams to validate how their streaming applications behave under failure conditions. References: Amazon Kinesis Data Streams Document history |
| 2025-10-28 | Amazon Kinesis Data Streams adds support for large records up to 10 MiB. The maximum record size increased tenfold from 1 MiB to 10 MiB, and the maximum PutRecords request size from 5 MiB to 10 MiB, simplifying ingestion of larger intermittent payloads - such as rich event documents for IoT analytics, change data capture, and generative AI workloads - without splitting them across multiple records; the per-shard throughput limits (1 MB/s for writes, 2 MB/s for reads) are unchanged. References: Amazon Kinesis Data Streams now supports 10x larger record sizes |
| 2025-11-04 | Amazon Kinesis Data Streams launches On-Demand Advantage mode. On-Demand Advantage lets customers warm on-demand streams to handle instant throughput increases up to 10 GB/s or 10 million events per second, with a simpler pricing structure, eliminating the need to over-provision or build custom scaling solutions. References: Amazon Kinesis Data Streams launches On-demand Advantage mode |
| 2025-11-13 | Amazon Kinesis Video Streams adds WebRTC Multi-Viewer. Real-time audio and video can be streamed to up to three concurrent viewers via WebRTC while simultaneously recording the session to the cloud for storage, playback, and analytical processing, without increasing compute or bandwidth on the device. References: Amazon Kinesis Video Streams WebRTC Multi-Viewer |
| 2025-11-20 | Amazon Kinesis Data Streams now supports up to 50 enhanced fan-out consumers for On-Demand Advantage streams. The higher fan-out limit (up from the default of 20 consumers per stream) lets customers attach many more independent, low-latency, high-throughput consumers to the same stream, unlocking broader parallel processing without contention. References: Amazon Kinesis Data Streams now supports up to 50 enhanced fan-out consumers |
| 2026-03-31 | Amazon Managed Service for Apache Flink adds support for Apache Flink 2.2. The major runtime upgrade brings improvements such as Java 17 support and serialization and I/O enhancements, continuing the service's role as a fully managed home for current Apache Flink versions. References: Amazon Managed Service for Apache Flink now supports Apache Flink 2.2 |
Current Overview, Functions, Features of Amazon Kinesis
Here, I will explain the main features of the current Amazon Kinesis family.Amazon Kinesis is a set of fully managed services for collecting, processing, analyzing, and delivering real-time, streaming data at any scale.
Rather than a single product, it is best understood as four complementary services that together cover the full lifecycle of streaming data:
- Amazon Kinesis Data Streams - a serverless, durable data stream for ingesting and storing real-time records that many applications can read in parallel.
- Amazon Data Firehose (formerly Amazon Kinesis Data Firehose) - a fully managed delivery service that loads streaming data into data lakes, warehouses, search, table formats, and third-party destinations.
- Amazon Managed Service for Apache Flink (formerly Amazon Kinesis Data Analytics) - a fully managed, serverless Apache Flink service for stateful stream processing and analytics.
- Amazon Kinesis Video Streams - a fully managed service for ingesting, storing, and streaming video and other time-encoded data, including real-time WebRTC media.
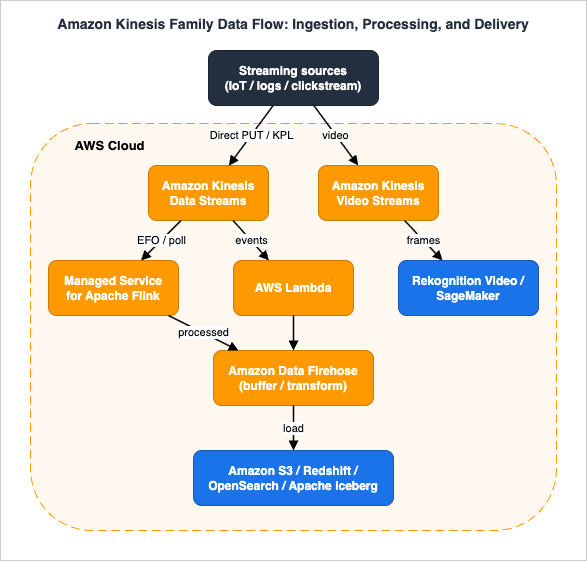
The following table summarizes how the four services relate to one another. They are complementary rather than alternatives: a typical pipeline ingests with Amazon Kinesis Data Streams, processes with Amazon Managed Service for Apache Flink, and delivers with Amazon Data Firehose, while Amazon Kinesis Video Streams handles media.
* You can sort the table by clicking on the column name.
| Service | Primary role | Typical sources | Typical destinations / outputs |
|---|---|---|---|
| Amazon Kinesis Data Streams | Durable, real-time ingestion and storage for parallel consumers | Producers via KPL, AWS SDK, Kinesis Agent, Direct PUT | AWS Lambda, Managed Service for Apache Flink, Amazon Data Firehose, EventBridge Pipes |
| Amazon Data Firehose | Fully managed delivery (load, transform, partition) | Kinesis Data Streams, Amazon MSK, Direct PUT, AWS service logs | Amazon S3, Redshift, OpenSearch, Apache Iceberg, S3 Tables, Splunk, Snowflake, HTTP endpoints |
| Amazon Managed Service for Apache Flink | Stateful stream processing and analytics (Apache Flink) | Kinesis Data Streams, Amazon MSK, Amazon S3 | Kinesis Data Streams, Amazon Data Firehose, Amazon S3, custom sinks |
| Amazon Kinesis Video Streams | Ingest, store, and stream video and time-encoded media | Cameras, IoT devices, browsers (Producer SDK, WebRTC) | HLS / DASH playback, WebRTC, Amazon Rekognition Video, Amazon SageMaker |
Amazon Kinesis Use Cases
Amazon Kinesis is used wherever data has the most value the moment it is created.The main use cases for the family include:
- Real-time analytics and dashboards
Continuously compute metrics, aggregations, and alerts over streaming data so dashboards reflect what is happening now, not what happened yesterday. - Log and event ingestion pipelines
Collect application, infrastructure, and security logs at scale and deliver them to data lakes, search, and observability tools in near real time. - Data lake and warehouse ingestion
Reliably load high-volume streams into Amazon S3 (including Apache Iceberg and Amazon S3 Tables), Amazon Redshift, and Amazon OpenSearch Service for downstream analytics. - Clickstream and IoT telemetry
Capture website clickstreams, mobile events, and device telemetry for personalization, monitoring, and predictive maintenance. - Event-driven and serverless processing
Trigger AWS Lambda or stream-processing applications as records arrive, building decoupled, scalable architectures. - Live and two-way video
Ingest video from millions of devices for playback, computer vision, and real-time WebRTC communication such as video doorbells and remote monitoring.
Specific Examples of Use Cases
For example, here are some more specific scenarios:- Real-time personalization
A media or retail platform streams user interactions through Amazon Kinesis Data Streams and processes them with Amazon Managed Service for Apache Flink to update recommendations within seconds. - Centralized log analytics
Application and AWS service logs (including AWS WAF, Amazon VPC Flow Logs, and Amazon CloudWatch Logs) flow through Amazon Data Firehose into Amazon S3 and Amazon OpenSearch Service for search and visualization. - Streaming ETL into a lakehouse
Amazon Data Firehose delivers streaming records directly into Apache Iceberg tables or Amazon S3 Tables, making them immediately queryable by analytics engines without a separate ETL job. - IoT predictive maintenance
Sensor telemetry is ingested by Amazon Kinesis Data Streams and analyzed by Apache Flink applications to detect anomalies and trigger maintenance before equipment fails. - Connected-home video
A camera-enabled doorbell uses Amazon Kinesis Video Streams with WebRTC to provide live two-way audio and video to a mobile app, while recording the session to the cloud for later playback. - Clickstream analytics for a digital product
A web and mobile product streams billions of interaction events per day through Amazon Kinesis Data Streams; AWS Lambda and Apache Flink applications compute real-time metrics and feed dashboards, while Amazon Data Firehose lands the raw events in an Amazon S3 data lake (as Apache Iceberg tables) for historical analysis.
A typical end-to-end pipeline draws on several of these services at once: producers write to Amazon Kinesis Data Streams; one or more consumers process the data (an Amazon Managed Service for Apache Flink application for stateful analytics, an AWS Lambda function for lightweight transformations, or both, each with its own Enhanced Fan-Out throughput); and Amazon Data Firehose loads either the raw or the processed records into Amazon S3, Amazon Redshift, Amazon OpenSearch Service, or Apache Iceberg tables for storage and analytics. Amazon Kinesis Video Streams runs alongside this data pipeline for any media workloads. Understanding which service owns each stage is the key to reading both the architecture and the timeline below.
Amazon Kinesis Data Streams
Amazon Kinesis Data Streams is the ingestion and storage backbone of the family: a serverless service that durably captures real-time data records and makes them available to multiple consumers in parallel.- Streams and shards
A data stream is composed of shards (in provisioned mode), each providing a fixed unit of capacity for writes and reads. Records are distributed across shards by partition key, and data is retained for a configurable period (24 hours by default, extendable up to 365 days). - Provisioned vs. on-demand capacity
In provisioned mode you choose and manage the number of shards. In on-demand mode (introduced November 29, 2021) the service scales capacity automatically and you pay for throughput used. On-demand throughput limits have grown over time - from an initial 200 MB/s write to 1 GB/s (March 2023), 2 GB/s (October 2023), and 10 GB/s write with 20 GB/s read (November 2024) - and On-Demand Advantage mode (2025) lets you warm capacity for instant, very large throughput increases and attach up to 50 enhanced fan-out consumers. - Enhanced Fan-Out
Registered consumers can each receive their own dedicated read throughput (up to 2 MB/s per shard per consumer) through the push-based SubscribeToShard API over HTTP/2, eliminating read contention when many applications consume the same stream. - Producer and consumer libraries
The Amazon Kinesis Producer Library (KPL) simplifies high-throughput writes with batching and aggregation, while the Amazon Kinesis Client Library (KCL) handles consumer coordination, checkpointing, and load balancing across workers. - Large records
As of 2025, Amazon Kinesis Data Streams supports records up to 10 MiB, simplifying ingestion of larger payloads. - Ordering and partition keys
Each record is written with a partition key that determines its shard; within a shard, records are delivered to consumers in the order they were written, which lets applications preserve per-key ordering (for example, all events for a given user or device) while still scaling horizontally across shards. - Resharding and retention
You can change a provisioned stream's capacity by splitting and merging shards, or by calling the UpdateShardCount API to scale to a target shard count; data retention can be extended from the 24-hour default up to 365 days so the same stream serves both real-time consumers and longer-term reprocessing. - Security and resilience
Server-side encryption with AWS KMS protects data at rest, cross-account stream sharing simplifies multi-account designs, AWS PrivateLink enables private connectivity from a VPC, and integration with AWS Fault Injection Service enables resilience testing.
Amazon Data Firehose (formerly Amazon Kinesis Data Firehose)
Amazon Data Firehose is the family's fully managed delivery service. You configure a Firehose stream by choosing a source and a destination, and Firehose handles the scaling, buffering, transformation, and delivery with no servers to manage.- Destinations
Firehose delivers to Amazon S3, Amazon Redshift, Amazon OpenSearch Service, Apache Iceberg tables, Amazon S3 Tables, Splunk, Snowflake, generic HTTP endpoints, and partners such as Datadog, New Relic, MongoDB, and Dynatrace. - Sources
Firehose can read from Amazon Kinesis Data Streams, Amazon Managed Streaming for Apache Kafka (Amazon MSK), the Direct PUT API, and many AWS service log sources (such as AWS WAF logs, Amazon VPC Flow Logs, and Amazon CloudWatch Logs). - Transformation and format conversion
Firehose can invoke an AWS Lambda function to transform records in flight and can convert JSON into columnar formats such as Apache Parquet and Apache ORC for efficient analytics. - Buffering and latency
Firehose buffers by size or time before delivery; with zero buffering (2023) it can deliver most records within seconds for lower-latency use cases. - Dynamic partitioning
Firehose can partition streaming data in transit using keys within the data and deliver into corresponding Amazon S3 prefixes, improving the performance and cost of downstream queries. - Error handling and backup
Firehose automatically retries failed deliveries and can back up raw or transformed records to an Amazon S3 bucket, and it can log delivery errors to Amazon CloudWatch Logs, so data is not silently lost when a destination is temporarily unavailable. - Direct PUT vs. stream sources
Producers can send records to Firehose directly with the Direct PUT API, or Firehose can read continuously from an existing Amazon Kinesis Data Streams stream or Amazon MSK topic, letting the same delivery service sit behind either an ingestion stream or producers writing to it directly.
Amazon Managed Service for Apache Flink (formerly Amazon Kinesis Data Analytics)
Amazon Managed Service for Apache Flink is the family's stateful stream-processing and analytics service. It began in 2016 as Amazon Kinesis Analytics with a proprietary SQL engine, added a Java/Apache Flink programmable option in 2018, introduced the Studio notebook experience in 2021, and was renamed to its current name on August 30, 2023.- Apache Flink foundation
You build streaming applications using Apache Flink in Java, Python, SQL, or Scala, with rich time semantics, windowing, exactly-once processing semantics, and durable application state. - Fully managed and serverless
There are no servers or clusters to manage; the service handles provisioning and scaling, and you pay for the resources your applications consume (measured in Kinesis Processing Units, KPU). - Studio notebooks
Amazon Managed Service for Apache Flink Studio offers an interactive Apache Zeppelin notebook environment to query streams and develop applications before promoting them to production. - Broad connectivity
Applications can read from and write to sources and destinations such as Amazon Kinesis Data Streams, Amazon MSK, and Amazon S3. - Durability through snapshots
Application state is checkpointed and can be captured as snapshots (savepoints), so an application can be stopped, scaled, or upgraded and then resumed from a consistent point without losing in-flight computation. - In-place version upgrades
Existing applications can be upgraded to newer Apache Flink runtime versions in place (for example, to Apache Flink 2.x), retaining snapshots, logs, metrics, tags, and configuration, which keeps long-running streaming applications on supported versions. - Legacy SQL applications
The original Kinesis Data Analytics for SQL applications are being discontinued (new applications cannot be created from October 15, 2025), with AWS recommending Apache Flink and Studio for new work.
Amazon Kinesis Video Streams
Amazon Kinesis Video Streams is the family's media service, built to ingest, store, and stream video and other time-encoded data from millions of devices.- Ingestion and durable storage
Incoming streams arrive over secure TLS connections, are encrypted with AWS KMS, and are stored in time-indexed form for playback and analysis. - Playback
HLS (HTTP Live Streams) and DASH output let you play back live and on-demand video in standard web and mobile players without building transmuxing infrastructure. - WebRTC
Kinesis Video Streams provides a fully managed WebRTC capability - signaling plus managed STUN/TURN - for low-latency, two-way, peer-to-peer audio and video; WebRTC ingestion to the cloud became generally available in 2023, and WebRTC Multi-Viewer (up to three concurrent viewers) arrived in 2025. - Producer SDK and fragments
A device-side Producer SDK sends media to the cloud, where it is stored as time-indexed fragments; consumer APIs such as GetMedia and GetMediaForFragmentList let applications retrieve exactly the segments they need for processing or playback. - Image extraction
Kinesis Video Streams can extract still images from a stream on demand or automatically in real time (delivered to Amazon S3), which feeds machine learning pipelines and powers thumbnails and timeline scrubbing in playback applications. - Analytics integration
Video can be analyzed with Amazon Rekognition Video and Amazon SageMaker for computer vision and machine learning use cases.
Amazon Kinesis Key Functions and Features (Across the Family)
- Real-time, at-scale ingestion - Capture large volumes of streaming data per second from many producers.
- Serverless, fully managed operation - No clusters to provision for ingestion, delivery, or (with on-demand and serverless options) processing.
- Durable, replayable storage - Amazon Kinesis Data Streams retains records so multiple consumers can read independently and reprocess history.
- Parallel, independent consumers - Multiple applications can read the same stream, with Enhanced Fan-Out giving each its own throughput.
- Flexible delivery - Amazon Data Firehose loads data into lakes, warehouses, search, table formats, and third-party tools with transformation and partitioning.
- Stateful stream processing - Apache Flink applications provide windowing, exactly-once semantics, and durable state.
- Security and governance - Encryption at rest with AWS KMS, AWS IAM access control, AWS PrivateLink connectivity, and cross-account sharing.
- Replay and reprocessing - Because Amazon Kinesis Data Streams retains records (up to 365 days), consumers can replay history to recover from failures, backfill a new consumer, or reprocess data with updated logic.
- Open formats and lakehouse delivery - Amazon Data Firehose can convert records to Apache Parquet or ORC and deliver into Apache Iceberg tables and Amazon S3 Tables, making streaming data immediately usable by lakehouse query engines.
- Observability - Amazon CloudWatch metrics (including shard-level metrics) and AWS CloudTrail logging for monitoring and auditing.
Amazon Kinesis Pricing Models (Structure)
Each service in the family bills on dimensions that match what it does. This article does not list specific prices, because AWS pricing changes over time; for current figures, always consult the official pricing pages for Amazon Kinesis Data Streams, Amazon Data Firehose, Amazon Managed Service for Apache Flink, and Amazon Kinesis Video Streams. At a structural level:- Amazon Kinesis Data Streams - In provisioned mode, you are billed by shard over time plus the volume of records written, with separate charges for extended data retention and Enhanced Fan-Out (per consumer and per volume retrieved). In on-demand mode, you are billed by the data ingested, retrieved, and stored, plus a per-stream charge, so capacity scales without shard management.
- Amazon Data Firehose - You are billed primarily by the volume of data ingested into a Firehose stream, with additional charges for optional features such as format conversion, dynamic partitioning, and certain destinations.
- Amazon Managed Service for Apache Flink - You are billed by the compute and memory your applications consume, measured in Kinesis Processing Units (KPU) over time, including the resources used by Studio notebooks.
- Amazon Kinesis Video Streams - You are billed by the volume of data ingested, stored, and consumed, with separate dimensions for WebRTC signaling and TURN streaming minutes.
Amazon Kinesis Region Availability
The core Amazon Kinesis services are available in a broad set of AWS Regions, including AWS GovCloud (US) for several of them, while newer features and destinations often roll out Region by Region after their initial launch. Because availability evolves continuously, this article does not enumerate Regions; for authoritative, current coverage, consult the AWS Regional Services List and each service's documentation. When designing for data residency or latency, confirm that the specific service and feature you depend on (for example, a particular Firehose destination or a Kinesis Video Streams WebRTC capability) is available in your target Region.Integration with Other AWS Services
The Amazon Kinesis family is deeply integrated with the rest of AWS.Amazon Kinesis Data Streams is a native event source for AWS Lambda, enabling serverless stream processing, and integrates with Amazon EventBridge Pipes for point-to-point event flows.
Amazon Data Firehose delivers to Amazon S3, Amazon Redshift, Amazon OpenSearch Service, Apache Iceberg tables, and Amazon S3 Tables, and reads from Amazon MSK.
Amazon Managed Service for Apache Flink processes data from Amazon Kinesis Data Streams and Amazon MSK.
Amazon Kinesis Video Streams integrates with Amazon Rekognition Video and Amazon SageMaker for media analytics.
This connectivity is what makes Amazon Kinesis the backbone of streaming architectures on AWS - for a hands-on architecture that uses these services together, see the AWS Streaming Data Pipeline Architecture Guide.
Best Practices for the Amazon Kinesis Family
The history above shows a consistent direction of travel - less capacity management, broader delivery, and stronger durability. A few practices follow naturally from how the services work today:- Choose on-demand unless you have steady, predictable traffic - On-demand mode (and On-Demand Advantage for very large spikes) removes shard planning; reserve provisioned mode for steady workloads where you want to manage shard count and cost directly.
- Use Enhanced Fan-Out when multiple consumers read the same stream - Dedicated per-consumer throughput avoids the contention that occurs when several applications share a shard's read capacity, and the higher consumer limits make wide fan-out practical.
- Design partition keys for even distribution and required ordering - Choose partition keys that spread load across shards while keeping related records (which must stay ordered) on the same shard, and avoid keys that concentrate traffic into a hot shard.
- Let Amazon Data Firehose handle delivery rather than writing custom loaders - For loading streams into Amazon S3, Redshift, OpenSearch, Apache Iceberg, or third-party tools, a Firehose stream with transformation and partitioning is simpler and more reliable than bespoke consumer code, and it backs up failed records to Amazon S3.
- Prefer Apache Flink over the legacy SQL service for new processing - Build new stream-processing applications on Amazon Managed Service for Apache Flink (or its Studio notebooks), since Kinesis Data Analytics for SQL applications is being discontinued.
- Encrypt, restrict, and observe - Enable server-side encryption with AWS KMS, apply least-privilege IAM policies, use AWS PrivateLink for private access, and monitor Amazon CloudWatch metrics (including shard-level metrics) so capacity and delivery issues are visible early.
Frequently Asked Questions about Amazon Kinesis History
When did Amazon Kinesis (Data Streams) launch?Amazon Kinesis was announced at AWS re:Invent on November 14, 2013 as a managed service for real-time processing of streaming big data, and opened to the public in beta on December 17, 2013. This original service is what is known today as Amazon Kinesis Data Streams.
When did Amazon Kinesis Data Firehose launch, and when did it become Amazon Data Firehose?
Amazon Kinesis Firehose was introduced on October 7, 2015 as the easiest way to load streaming data into AWS (initially to Amazon S3 and Amazon Redshift). It was renamed to Amazon Data Firehose on February 9, 2024; the rename affected only names in the console, documentation, and web pages, while APIs, endpoints, the AWS CLI, IAM policies, and Amazon CloudWatch metrics were unchanged.
When was Kinesis Data Analytics renamed to Amazon Managed Service for Apache Flink?
Amazon Kinesis Data Analytics was renamed to Amazon Managed Service for Apache Flink on August 30, 2023. The service originally launched as a SQL-based service in 2016, added a Java/Apache Flink option in 2018, and introduced Studio notebooks in 2021; existing applications continued to run unchanged after the rename, and the kinesisanalyticsv2 API identifier was retained.
When did Amazon Kinesis Video Streams launch?
Amazon Kinesis Video Streams launched at AWS re:Invent on November 29, 2017. It later added HLS output in 2018, real-time two-way WebRTC media in 2019, generally available WebRTC ingestion to the cloud in 2023, and WebRTC Multi-Viewer in 2025.
When did Amazon Kinesis Data Streams add on-demand capacity mode?
The on-demand capacity mode for Amazon Kinesis Data Streams was introduced on November 29, 2021, removing the need to provision and manage shards. AWS later increased on-demand throughput limits over time and launched On-Demand Advantage mode on November 4, 2025 for instant, very large throughput increases.
How do Data Streams, Data Firehose, Managed Service for Apache Flink, and Video Streams differ?
They cover different stages of the streaming lifecycle: Amazon Kinesis Data Streams ingests and durably stores records for many parallel consumers; Amazon Data Firehose delivers streaming data into destinations such as Amazon S3, Amazon Redshift, Amazon OpenSearch Service, and Apache Iceberg tables with optional transformation; Amazon Managed Service for Apache Flink performs stateful stream processing and analytics with Apache Flink; and Amazon Kinesis Video Streams ingests, stores, and streams video and other time-encoded media, including real-time WebRTC.
When did Amazon Kinesis Data Streams add Enhanced Fan-Out?
Enhanced Fan-Out and the HTTP/2 SubscribeToShard API launched on August 2, 2018, giving each registered consumer up to 2 MB/s of dedicated read throughput per shard and removing read contention between consumers. The maximum number of enhanced fan-out consumers per stream was later increased, reaching up to 50 for On-Demand Advantage streams in 2025.
What is the difference between Amazon Kinesis Data Streams provisioned and on-demand capacity modes?
In provisioned mode you choose and manage the number of shards, each providing a fixed unit of read and write capacity. In on-demand mode (introduced November 29, 2021) Amazon Kinesis Data Streams automatically scales capacity to match traffic and you pay for throughput used rather than for provisioned shards; On-Demand Advantage mode (2025) additionally lets you warm capacity for instant, very large throughput increases.
References:
Tech Blog with curated related content
AWS Documentation (Amazon Kinesis Data Streams)
AWS Documentation (Amazon Data Firehose)
What's New with AWS?
AWS News Blog
Summary
In this article, I assembled a historical timeline for the Amazon Kinesis family and summarized its current overview, functions, and features.From the November 2013 launch of the original Amazon Kinesis (today's Amazon Kinesis Data Streams), the family has grown to span ingestion (Amazon Kinesis Data Streams), delivery (Amazon Data Firehose, formerly Amazon Kinesis Data Firehose), stateful processing (Amazon Managed Service for Apache Flink, formerly Amazon Kinesis Data Analytics), and live and two-way video (Amazon Kinesis Video Streams).
Two renames - Amazon Kinesis Data Analytics to Amazon Managed Service for Apache Flink (August 30, 2023) and Amazon Kinesis Data Firehose to Amazon Data Firehose (February 9, 2024) - are the most important naming changes to keep in mind when reading older documentation and blog posts; in both cases AWS preserved full API and operational compatibility.
A clear theme runs through this history. Over the years, Amazon Kinesis has steadily removed operational burden (from manual shard management toward on-demand and On-Demand Advantage capacity), broadened how streaming data is delivered (from Amazon S3 and Amazon Redshift toward Apache Iceberg tables, Amazon S3 Tables, Snowflake, and a long list of third-party destinations), deepened processing (from a proprietary SQL engine toward a fully managed Apache Flink service with in-place version upgrades), and extended into media (from video ingestion and HLS playback toward real-time, multi-viewer WebRTC). Reading the timeline as a whole, the family has grown from a single 2013 stream-processing service into a complete platform for real-time data and media on AWS.
For a hands-on architecture that uses these services together, see the AWS Streaming Data Pipeline Architecture Guide, and for related batch, lakehouse, and routing context, see the Large-Scale Batch Generative AI Pipeline on AWS, the AWS Data Lakehouse Architecture Guide, and the AWS Messaging and Event Routing Decision Guide.
In addition, there is also a timeline of the entire range of AWS services including Amazon Kinesis, so please have a look if you are interested.
AWS History and Timeline - Almost All AWS Services List, Announcements, General Availability(GA)
Related timelines in this series:
AWS History and Timeline regarding Amazon SQS
AWS History and Timeline regarding Amazon EventBridge
AWS History and Timeline regarding Amazon SNS
This timeline will be updated as Amazon Kinesis continues to evolve.
References:
Tech Blog with curated related content
Written by Hidekazu Konishi