Large-Scale Batch Generative AI Pipeline on AWS - Asynchronous Inference at Scale with Bedrock Batch, Step Functions, and SQS
First Published:
Last Updated:
1. Introduction
Most generative-AI articles, including the others in this series, are about the interactive path: a user asks, an agent retrieves and reasons, and an answer streams back in seconds. But a large share of real production work is the opposite shape. You have a corpus — millions of support tickets to summarize, a back-catalog of documents to classify and tag, a product database to enrich, a quarter of call transcripts to extract structured fields from — and you need to run a model over all of it, once, as fast and as cheaply as the platform allows, with nobody watching a progress bar.At that scale the hard problem stops being "how do I call the model" and becomes "how do I run the model over ten million records and survive." A single record failing is normal; the question is whether one poison record fails the whole run. The model throttles you; the question is whether your pipeline backs off or melts down. A worker dies mid-batch; the question is whether the retry double-processes or quietly drops records. The job finishes at 3 a.m.; the question is whether the next stage starts automatically or waits for someone to notice. The engineering value of a large-scale batch pipeline is almost entirely in this operational plane — retry, ordering, idempotency, failure isolation, and completion signaling — not in the inference call itself.
This article is a single, end-to-end implementation walkthrough of one named reference architecture: the Large-Scale Batch Generative AI Pipeline on AWS. It connects Amazon S3, AWS Step Functions (Distributed Map), Amazon Bedrock batch inference (
CreateModelInvocationJob), Amazon SQS with a dead-letter queue, Amazon EventBridge, and a small idempotency ledger in Amazon DynamoDB into a pipeline that ingests a corpus, shards it within service quotas, runs inference in one of two modes, aggregates results, isolates failures, and signals completion to whatever comes next. The pipeline supports two inference execution modes behind one common control plane: a fully asynchronous Bedrock batch job for very large, latency-tolerant corpora, and a synchronous parallel fan-out through Step Functions Distributed Map for moderate volumes that need per-record control or lower turnaround. Choosing between them, and unifying them, is the spine of the design.This is the write path that complements the read paths elsewhere in the series. The batch pipeline produces enriched, summarized, or classified content; the multimodal ingestion details — turning PDFs, images, audio, and video into retrievable text — are the subject of Multimodal Document Intelligence Pipeline on AWS, and the agentic retrieval that later queries the result is covered in Agentic RAG Architecture on Amazon Bedrock. The basics of calling a Bedrock model — the synchronous
InvokeModel and Converse request shapes — are covered in Amazon Bedrock Basic Information and API Examples, and terminology lives in Amazon Bedrock Glossary. This article delegates those topics there and focuses entirely on running inference at scale.A note on currency and scope: Amazon Bedrock's surface area changes quickly, and batch quotas in particular are per-model, per-Region, and adjustable. Every API field and limit here was checked against the official AWS documentation at the time of writing, but you should re-verify current model IDs, regional availability, and Service Quotas values before depending on them. This article contains no pricing figures by editorial policy; throughput and concurrency are discussed quantitatively, but cost is discussed only qualitatively, and you should consult the official Amazon Bedrock pricing page for the economics. It also avoids attack payloads and treats security controls as defense-in-depth rather than guarantees.
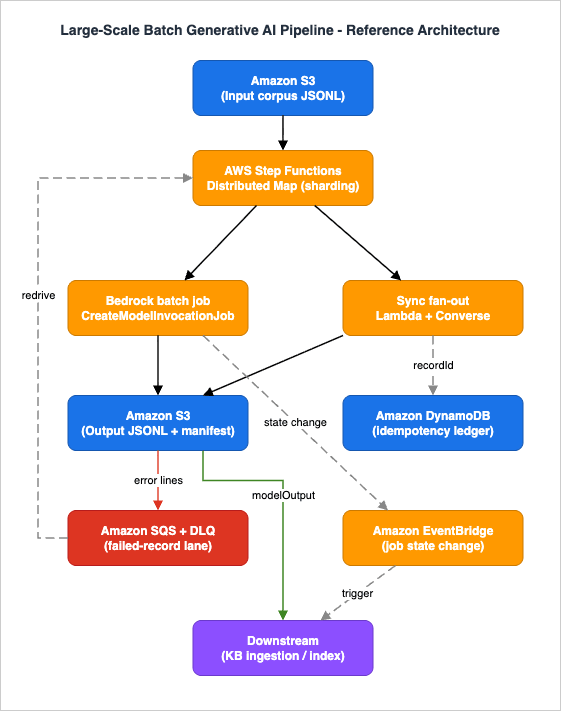
2. The Reference Architecture at a Glance
The Large-Scale Batch Generative AI Pipeline is built from a small set of services, each with one job. Six AWS services plus a foundation model collaborate so that a corpus dropped into a bucket comes out enriched, with failures quarantined and the next stage triggered automatically.| Component | Service / API | Role in the pipeline |
|---|---|---|
| Input and output store | Amazon S3 | Holds the input JSONL corpus and the per-record output plus manifest |
| Orchestrator | AWS Step Functions (Standard) | Drives the pipeline; shards work with Distributed Map |
| Sharder / fan-out | Step Functions Distributed Map | Splits the corpus into child executions with bounded concurrency |
| Inference (mode A) | Bedrock batch CreateModelInvocationJob | Asynchronous, high-throughput inference over a JSONL shard |
| Inference (mode B) | Bedrock Converse / InvokeModel via Lambda | Synchronous per-record inference inside a child execution |
| Failure lane | Amazon SQS + dead-letter queue | Isolates poison records and failed shards for replay |
| Completion signal | Amazon EventBridge | Emits job-state-change events to start the next stage |
| Idempotency ledger | Amazon DynamoDB | Records processed record IDs so replays do not double-count |
The orchestrator is a Step Functions Standard workflow — Standard rather than Express because the pipeline is long-running (batch jobs take hours), needs the full execution history, and Distributed mode is only supported in Standard workflows. Distributed Map is the component that turns "a corpus" into "many bounded units of work": it reads the input from S3, splits it into child workflow executions, and caps how many run at once so the pipeline never exceeds a downstream service's capacity. Each child execution then runs inference in one of the two modes. Mode A submits a Bedrock batch job that reads a JSONL shard from S3 and writes results back to S3; mode B invokes the model synchronously per record. Either way, results land in S3 as one output JSON object per input record, accompanied by a manifest. Records that error are routed to an SQS failure lane backed by a dead-letter queue, and completion is announced through EventBridge so the downstream consumer — knowledge-base ingestion, indexing, analytics — starts without anyone polling. A DynamoDB ledger keyed by record ID makes the whole thing safe to retry.
The rest of this article walks one corpus through this architecture: first the choice between the two inference modes (Section 3), then each mode and the orchestration that drives it (Sections 4–5), then the operational plane that makes it production-grade — idempotency and dead-lettering (Section 6), the cross-cutting concerns (Section 7), the downstream handoff (Section 8), and the failure modes (Section 9).
3. Batch vs Parallel Synchronous Inference
Before any code, decide which inference mode a workload belongs in. This is the single most consequential design decision in the pipeline, and the two modes have genuinely different operational characteristics — they are not interchangeable.Mode A — Bedrock batch inference (
CreateModelInvocationJob). You write a JSONL file of prompts to S3, submit one control-plane API call, and Bedrock processes the whole file asynchronously, writing results back to S3 when done. There is no per-request round trip and no synchronous throttling to manage; Bedrock schedules the work against a separate, dedicated batch capacity pool. It is offered as a discounted asynchronous tier — the qualitative trade is that you give up latency (a job runs over a window of minutes to hours, not seconds) in exchange for high throughput and lower cost on bulk work. Batch jobs have a minimum number of records (you cannot submit a tiny job), a maximum per job and per file, and a cap on concurrent jobs per account per model — all governed by Service Quotas and all per-model. Output order is not guaranteed to match input order.Mode B — synchronous parallel fan-out. Step Functions Distributed Map iterates over the corpus and, for each item (or small batch of items), a Lambda function calls
Converse or InvokeModel synchronously. You see each result immediately, can branch on it per record, and can start downstream work the moment a record finishes. The cost of that control is that you are now subject to the model's on-demand throughput quotas (requests and tokens per minute) and you must manage concurrency yourself so you do not throttle. This mode is right when the volume is moderate, when you need per-record branching or near-real-time turnaround, or when the job is simply below the batch minimum.The decision table:
| Dimension | Mode A — Bedrock batch job | Mode B — synchronous fan-out |
|---|---|---|
| Best for | Very large, latency-tolerant corpora | Moderate volume; per-record control; lower turnaround |
| Latency | Minutes to hours (whole-job) | Seconds per record |
| Throughput limiter | Records/job × concurrent-jobs quota | On-demand TPM/RPM, your concurrency |
| Per-record error handling | After the job, from output error lines | Immediate, inside the child execution |
| Minimum size | Has a per-job minimum-record quota | One record |
| Cost posture (qualitative) | Discounted asynchronous tier | On-demand rates |
| Output ordering | Not guaranteed | You control it |
A mature pipeline often uses both: batch for the nightly bulk run, synchronous fan-out for the smaller incremental top-up that has to land before business hours. The two share the same ingest bucket, the same idempotency ledger, the same failure lane, and the same completion event — which is why this article treats them as two modes of one pipeline rather than two separate systems. The next two sections build each mode.
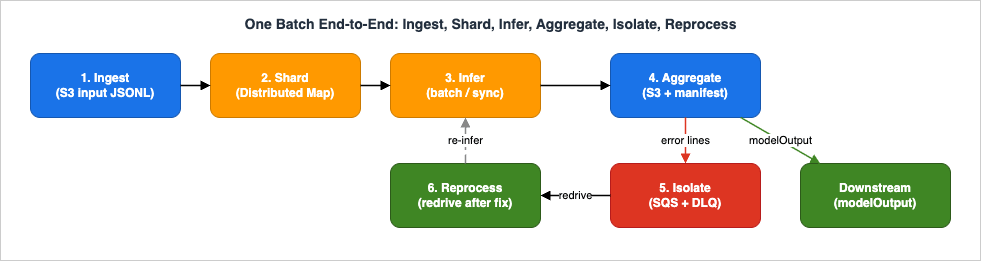
4. Batch Inference with CreateModelInvocationJob
Mode A is the workhorse for bulk corpora. This section covers the job model, the input and output formats, and the sharding strategy that lets a corpus larger than a single job exceed the per-job quota.4.1 The job model
A batch job is a control-plane resource. You callCreateModelInvocationJob on the bedrock endpoint (not the bedrock-runtime data-plane endpoint), and it returns a jobArn. The required fields are a jobName, a roleArn (a service role Bedrock assumes to read your input and write your output), a modelId, an inputDataConfig pointing at an S3 location, and an outputDataConfig pointing at another. Optional fields carry the operational controls that matter at scale: clientRequestToken for idempotency, timeoutDurationInHours to bound runaway jobs, vpcConfig to keep data on private networking, tags for cost allocation and access control, and s3EncryptionKeyId to encrypt output with a customer-managed KMS key.import boto3
bedrock = boto3.client("bedrock", region_name="us-west-2")
response = bedrock.create_model_invocation_job(
jobName="enrich-corpus-2026-06-27-shard-001",
roleArn="arn:aws:iam::ACCOUNT_ID:role/BedrockBatchInferenceRole",
modelId="us.anthropic.claude-haiku-4-5-20251001-v1:0",
clientRequestToken="enrich-corpus-2026-06-27-shard-001", # idempotency
inputDataConfig={
"s3InputDataConfig": {"s3Uri": "s3://corpus-input/shards/shard-001.jsonl"}
},
outputDataConfig={
"s3OutputDataConfig": {
"s3Uri": "s3://corpus-output/2026-06-27/shard-001/",
"s3EncryptionKeyId": "arn:aws:kms:us-west-2:ACCOUNT_ID:key/KEY_ID",
}
},
timeoutDurationInHours=24,
)
job_arn = response["jobArn"]
Submitted, Validating, InProgress, and then Completed, Failed, or Stopped. You can read the status (and progress counters) with GetModelInvocationJob, but at scale you should not poll it; Section 9 wires completion to EventBridge instead. The clientRequestToken is important: if you submit the same token twice — because a retry re-ran your submission step — Bedrock ignores the duplicate rather than starting a second job, which is the first of several idempotency guarantees this pipeline relies on.4.2 Input and output format
The input is a JSONL file: one JSON object per line, each with arecordId and a modelInput. The shape of modelInput depends on the modelInvocationType you choose when creating the job — InvokeModel (the default) means modelInput must match the model's native InvokeModel body, while Converse means it must match the Converse request body. Using a Claude model with the native (Messages) format, a line looks like this:{"recordId": "DOC0000001", "modelInput": {"anthropic_version": "bedrock-2023-05-31", "max_tokens": 1024, "messages": [{"role": "user", "content": [{"type": "text", "text": "Summarize and tag the following document in JSON: ..."}]}]}}
recordId is your correlation key. If you omit it, Bedrock generates one — but you almost always want to supply your own, because it is how you tie an output line back to a source record and how you make the pipeline idempotent (Section 6). A good recordId is a deterministic function of the source record, such as a content hash or a stable document ID, so the same input always carries the same ID.When the job completes, Bedrock writes one output JSONL file per input file, plus a
manifest.json.out summary, to your output location. Each output line echoes the recordId and modelInput and adds either a modelOutput (matching the model's response body) or, on failure, an error object in its place:{"recordId": "DOC0000001", "modelInput": { }, "modelOutput": { }}
{"recordId": "DOC0000002", "modelInput": { }, "error": {"errorCode": 400, "errorMessage": "bad request"}}
error line, and the rest of the job still completes — so a single poison record never fails the batch. Your post-processing reads the output, routes error lines to the failure lane (Section 6), and passes modelOutput lines downstream. Second, order is not guaranteed: the output line order does not necessarily match the input. You must therefore key everything on recordId and never assume positional alignment. The manifest.json.out gives you the totals — totalRecordCount, processedRecordCount, successRecordCount, errorRecordCount, and aggregate input/output token counts — which is the cheapest way to confirm a run's health without reading every line.4.3 Supported models and sharding
Batch inference is supported across many Bedrock foundation models, including Anthropic Claude and Amazon Nova families, and works with both single-Region model IDs and cross-Region inference profiles (theus., eu., apac. prefixes). The exact set of models, Regions, and profile support changes; treat the official "Supported Regions and models for batch inference" page as canonical rather than hard-coding assumptions, and pick the model with Amazon Bedrock Basic Information and API Examples and the current Claude model facts as your reference.The constraint that shapes the architecture is that a single job is bounded. There is a minimum number of records (you cannot submit a trivially small job), a maximum number of records per job and per file, a maximum file and total job size, and a cap on concurrent batch jobs per account per model. These are per-model, per-Region, and most are adjustable through Service Quotas — so look up the current value rather than memorizing one. The architectural consequence is fixed regardless of the exact numbers: a corpus larger than one job's record cap must be split into multiple jobs, and the number of jobs you can run at once is itself capped. Splitting a corpus into right-sized shards, submitting them up to the concurrency limit, and aggregating the results is precisely the orchestration problem that Step Functions Distributed Map solves — which is Section 5.
5. Orchestration with Step Functions Distributed Map
Distributed Map is the orchestration primitive built for exactly this shape of work: process a large-scale dataset from S3 concurrently, with each iteration running as its own child workflow execution. It is the right tool when any of three conditions hold — your dataset exceeds 256 KB, your execution history would exceed 25,000 events, or you need more than 40 parallel iterations — and a bulk generative-AI corpus hits all three.5.1 Why Distributed mode
A Map state has two modes. Inline mode runs iterations inside the parent execution and caps at 40 concurrent branches, which is fine for small lists. Distributed mode runs each iteration as a separate child workflow execution with its own execution history, which lifts the concurrency ceiling to 10,000 parallel child executions and lets the input come straight from a large S3 dataset. Each child is isolated: a failure in one does not corrupt the parent's history, and the parent can apply a failure threshold across all of them. Distributed mode is supported only in Standard workflows (the parent must be Standard), while each child can run as a Standard workflow (idempotent, full history) or an Express workflow (faster and cheaper, but not idempotent) — a choice you make per the child's own retry semantics.5.2 The two orchestration shapes
Distributed Map drives both inference modes from Section 3, with slightly different wiring.Shape A — shard-and-submit (drives Mode A batch jobs). The Distributed Map iterates over a list of shards (each shard being a JSONL file you pre-split to respect the per-job record cap). Each child execution submits one Bedrock batch job for its shard, waits for it to finish, and reports the outcome.
MaxConcurrency is set to the per-model concurrent-jobs quota so the pipeline never tries to run more jobs than Bedrock will accept. The child waits on completion either via the .sync integration pattern or, more loosely coupled, by suspending on a task token that the EventBridge completion handler (Section 9) resumes.Shape B — fan-out (drives Mode B synchronous inference). The Distributed Map's
ItemReader reads the input JSONL directly from S3, and ItemBatcher groups items into small batches so each child execution processes a manageable chunk. The child's ItemProcessor is a Lambda task that calls Converse/InvokeModel per item. Here MaxConcurrency is tuned to the model's on-demand throughput and your Lambda concurrency, not a job quota. A ResultWriter consolidates every child's results back to S3, grouped by status.A condensed Amazon States Language definition for Shape B looks like this:
{
"Comment": "Synchronous batch generative-AI fan-out",
"StartAt": "ProcessCorpus",
"States": {
"ProcessCorpus": {
"Type": "Map",
"ItemReader": {
"Resource": "arn:aws:states:::s3:getObject",
"ReaderConfig": {"InputType": "JSONL"},
"Parameters": {"Bucket": "corpus-input", "Key": "corpus/2026-06-27.jsonl"}
},
"ItemBatcher": {"MaxItemsPerBatch": 100},
"MaxConcurrency": 20,
"ToleratedFailurePercentage": 5,
"ItemProcessor": {
"ProcessorConfig": {"Mode": "DISTRIBUTED", "ExecutionType": "STANDARD"},
"StartAt": "InferBatch",
"States": {
"InferBatch": {
"Type": "Task",
"Resource": "arn:aws:states:::lambda:invoke",
"OutputPath": "$.Payload",
"Parameters": {
"FunctionName": "arn:aws:lambda:us-west-2:ACCOUNT_ID:function:infer-batch",
"Payload.$": "$"
},
"Retry": [
{"ErrorEquals": ["ThrottlingException", "ModelTimeoutException"],
"IntervalSeconds": 2, "BackoffRate": 2.0, "MaxAttempts": 6}
],
"End": true
}
}
},
"ResultWriter": {
"Resource": "arn:aws:states:::s3:putObject",
"Parameters": {"Bucket": "corpus-output", "Prefix": "2026-06-27/results"}
},
"End": true
}
}
}
5.3 The fields that carry the design weight
Four Distributed Map fields do most of the work:MaxConcurrencycaps how many child executions run at once. If you omit it (or set 0), Step Functions does not limit concurrency and will run up to 10,000 — which is almost never what you want, because it will overrun whatever the children call. The official guidance is explicit: do not exceed the capacity of the downstream service. This is the single field that aligns the pipeline's parallelism with Bedrock's quotas (Section 7).ItemBatchergroups items so each child processes a batch rather than one item, which amortizes per-execution overhead.MaxItemsPerBatchis the knob; pick it so a batch is large enough to be efficient but small enough that one poison item does not waste a lot of work.ToleratedFailurePercentage(orToleratedFailureCount) sets a fail-fast threshold: if more than the tolerated fraction of items fail, the whole Map Run fails instead of grinding through a corpus that is clearly broken — for example when a bad prompt template makes every record fail. This is your circuit breaker.ResultWriterconsolidates all child results to S3, grouping executions by status into separate files, so you get a single, queryable record of what succeeded and what failed rather than thousands of scattered outputs.
Each Map Run is a first-class resource with its own ARN, inspectable with
DescribeMapRun, and its child executions emit CloudWatch metrics — which is how you observe progress (Section 9). Running a Distributed Map requires the state-machine role to hold states:StartExecution and states:DescribeExecution on itself, plus least-privilege access to the S3 buckets and to whatever the children invoke (Lambda, or bedrock:CreateModelInvocationJob).6. Idempotency, Ordering, and Dead-Letter Strategy
This is the heart of the operational plane. A pipeline that processes ten million records will, somewhere, retry a child execution after a transient error, re-submit a job after a timeout, or redeliver an SQS message after a visibility-timeout lapse. All of these are at-least-once mechanics, which means the pipeline must be safe to run a record through more than once. Three disciplines make that true.6.1 Idempotency keys
Idempotency operates at two granularities. At the job level,clientRequestToken on CreateModelInvocationJob means a re-submitted job (same token) is ignored rather than duplicated — so a Step Functions retry of the submit step cannot launch a second job over the same shard. At the record level, the recordId is the unit of deduplication. Make it a deterministic function of the source record (a content hash or stable document ID), then keep a small ledger — a DynamoDB table keyed by recordId — and write each record's completion with a conditional put (attribute_not_exists(recordId)). A retried iteration that reprocesses a record finds it already present and skips the downstream side effect:import boto3
from botocore.exceptions import ClientError
ddb = boto3.client("dynamodb", region_name="us-west-2")
def claim_record(record_id: str) -> bool:
"""Return True if this record has not been processed before."""
try:
ddb.put_item(
TableName="batch-idempotency-ledger",
Item={"recordId": {"S": record_id}, "status": {"S": "processed"}},
ConditionExpression="attribute_not_exists(recordId)",
)
return True
except ClientError as e:
if e.response["Error"]["Code"] == "ConditionalCheckFailedException":
return False # already processed - skip the side effect
raise
6.2 Ordering
Batch output order is not guaranteed, and Distributed Map child executions complete in an arbitrary order, so the pipeline must never depend on positional alignment. Two rules follow. First, always join onrecordId, never on line position — when you read the output JSONL, build a map from recordId to result rather than zipping two lists. Second, if a downstream consumer genuinely needs global ordering (rare for enrichment, common for event streams), carry an explicit sequence field in each record and sort downstream, or route the ordered work through a FIFO SQS queue where message-group ordering is preserved. Do not try to recover ordering from the pipeline's execution timing; it isn't there.6.3 Dead-letter strategy
Failures come in three textures, each with its own containment:- Poison records — a single malformed or un-processable record. In Mode A these appear as
errorlines in the output; your post-processor extracts them to an SQS reprocessing queue. In Mode B, a record that fails inside a Lambda batch must not fail the whole batch — configure the SQS event source mapping withReportBatchItemFailuresso the function returns only the failed message IDs inbatchItemFailures, and the rest are deleted. Without this, one poison record forces the entire batch to redeliver, multiplying work. - Repeatedly failing records — a record that fails every attempt. The SQS source queue's
RedrivePolicywith amaxReceiveCountmoves it to a dead-letter queue after the configured number of attempts, isolating it for human inspection instead of looping forever. TunemaxReceiveCountto the most likely failure's recovery time. - Whole-shard or whole-job failures — a shard whose job fails to validate (bad format, missing permission, exhausted quota). The Distributed Map
Catch/Retryand theToleratedFailurePercentagethreshold decide whether to retry the shard or fail the run.
Replay closes the loop. Once you have fixed the root cause — corrected the prompt template, adjusted a quota, repaired malformed inputs — you redrive the dead-letter queue back to its source (SQS supports DLQ redrive natively) or resubmit the failed records as a new, smaller batch job. Because the idempotency ledger (Section 6.1) gates the downstream side effect, redriving cannot double-process the records that already succeeded around the failures. The state diagram below traces a record through claim, inference, success or failure, dead-lettering, and redrive.
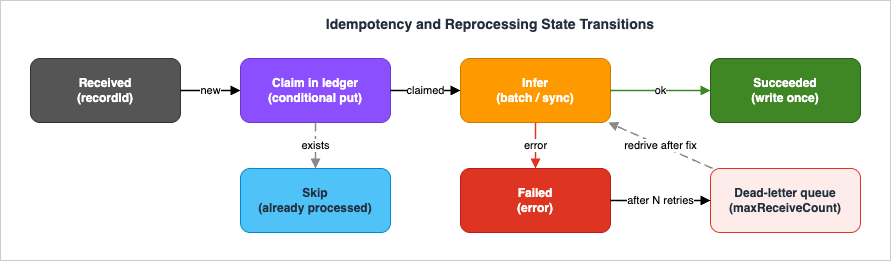
7. Cross-Cutting: IAM, Throttling, and Data Boundaries
Three concerns span every component. None of them belongs to a single box on the diagram, and getting them wrong is how a pipeline that works in a demo fails in production.7.1 Least-privilege IAM
The pipeline has several roles, and each should be scoped to exactly what it touches. The Bedrock batch service role (theroleArn you pass to CreateModelInvocationJob) needs s3:GetObject on the input prefix, s3:PutObject on the output prefix, permission to invoke the specific model, and kms:Decrypt/kms:GenerateDataKey if you encrypt with a customer-managed key — and nothing else. The Step Functions role needs states:StartExecution and states:DescribeExecution on itself for Distributed Map, lambda:InvokeFunction on the inference function (Mode B) or bedrock:CreateModelInvocationJob and iam:PassRole for the batch role (Mode A), and read/write on the orchestration buckets. The Lambda role needs model-invoke permission and the DynamoDB ledger.Two patterns matter at scale. Scope every
Resource to a specific ARN — never Resource: "*" — so a compromised step cannot reach buckets, models, or queues it was never meant to touch. And when you invoke a model through a cross-Region inference profile, the role needs permission on both the inference-profile ARN and the underlying foundation-model ARNs in every Region the profile can route to; a profile that works in one Region and AccessDenieds in another is almost always a missing wildcard-Region model entry. Confirm exact action names against the Service Authorization Reference for Amazon Bedrock rather than assuming they mirror the API names.7.2 Throttling and quota interaction
This is the subtlety that separates a Level 300 understanding from a Level 400 one: the pipeline's effective throughput is the minimum of several interacting limits, and they live in different services. In Mode A the ceiling is records per job multiplied by concurrent jobs per account per model; push past it and submissions are rejected. In Mode B the ceiling is the model's on-demand tokens-per-minute and requests-per-minute; push past it and you getThrottlingException. On top of those sit the Step Functions Distributed Map MaxConcurrency, the Lambda reserved/account concurrency, and SQS throughput. The job of the architect is to set MaxConcurrency (and MaxItemsPerBatch) so the pipeline's parallelism stays at or below whichever downstream limit is the bottleneck — which is exactly why the official Distributed Map guidance warns against exceeding downstream capacity. Because all of these quotas are per-model, per-Region, and mostly adjustable, the right move is to read the current values from Service Quotas, request increases where a workload needs them, and set MaxConcurrency from those numbers rather than guessing. Layer exponential-backoff Retry on ThrottlingException (as in the Section 5 definition) so transient pressure self-heals instead of failing the shard.7.3 Data boundaries
The S3 buckets and the batch role together define the pipeline's data perimeter. Partition input and output by tenant or classification using S3 prefixes, and scope the batch role's bucket permissions to those prefixes so a job for one tenant cannot read or write another's data — the boundary is structural, enforced by IAM and bucket layout, not by anything the model is told. For workloads with stricter requirements, attach avpcConfig to the batch job so traffic stays on private networking, and encrypt output with a customer-managed KMS key (s3EncryptionKeyId). One operational detail to remember: when a batch record references media stored in S3 (for multimodal inputs), all referenced resources must live in the same bucket and folder as the input, and cross-account references require the bucketOwner field — a mismatch here surfaces as a validation failure on an otherwise correct job.8. Downstream: Feeding RAG and Knowledge Bases
A batch pipeline is rarely the end of the story. Its output — summaries, extracted fields, classifications, embeddings-ready text — is usually the write path that populates a system other stages will read. The cleanest handoff is event-driven: the EventBridge completion event (Section 9) triggers the next stage rather than a downstream poller waiting on the pipeline.The most common downstream is retrieval. Bulk enrichment is exactly the kind of work that prepares a corpus for a knowledge base: the batch pipeline cleans, summarizes, and tags raw records at scale, then a knowledge-base ingestion job indexes the enriched output. The heavy lifting of turning messy source documents — PDFs, scans, images, audio, video — into structured, retrievable content is itself a pipeline, and it is the subject of Multimodal Document Intelligence Pipeline on AWS; this batch pipeline is the bulk-enrichment stage that sits alongside it. Once the content is indexed, the read path — agentic, self-correcting retrieval over it — is covered in Agentic RAG Architecture on Amazon Bedrock. The mental model is a clean split: this article builds the write path that fills the index; that article queries it. The general RAG mechanics — chunking, vector stores, ingestion configuration — live in Amazon Bedrock RAG Architecture Guide, and this article delegates them there rather than repeating them.
The connective tissue is the same in every case: the completion event carries the output location, a small Lambda starts the next stage (a knowledge-base ingestion job, an indexing run, an analytics load), and the idempotency ledger ensures that a redriven or replayed batch does not re-trigger downstream work for records that already landed. Keeping the handoff event-driven and idempotent is what lets the two pipelines compose without either one polling or duplicating the other.
9. Observability and Failure Modes
You cannot operate at this scale by watching logs. A ten-million-record run needs aggregate signals that tell you whether it is healthy and which stage broke when it is not — and it needs to announce its own completion rather than make a downstream stage poll.9.1 Instrumenting the pipeline
Three layers of signal cover the architecture:- Batch-job progress and manifest.
GetModelInvocationJobandListModelInvocationJobsreturn live progress counters —totalRecordCount,processedRecordCount,successRecordCount, anderrorRecordCount— so you can compute percent-complete and the running error rate without reading S3. After completion, themanifest.json.outgives the authoritative totals plus aggregate token counts. A risingerrorRecordCountis the earliest signal that a prompt template or an upstream data change has gone wrong. - Step Functions Map Run metrics. Each Map Run emits CloudWatch metrics for its child executions and is inspectable with
DescribeMapRun; the consolidatedResultWriteroutput groups successes and failures into separate S3 files you can query directly. This is how you see fan-out progress and the failure distribution in Mode B. - Completion via EventBridge — no polling. Bedrock emits a
Batch Inference Job State Changeevent (source: aws.bedrock) on a best-effort, near-real-time basis when a job changes state. A rule that matchesdetail.status: "Completed"(andFailed) triggers the post-processing Lambda — extracterrorlines to the failure lane, handmodelOutputlines downstream, record the run. This removes theGetModelInvocationJobpolling loop entirely, which both simplifies the orchestration and avoids the control-plane API throttling that aggressive polling would cause.
{
"source": ["aws.bedrock"],
"detail-type": ["Batch Inference Job State Change"],
"detail": {"status": ["Completed", "Failed", "Stopped"]}
}
9.2 Failure modes and how to isolate them
* You can sort the table by clicking on the column name.| Symptom | Likely root cause | How to isolate | Containment / remediation |
|---|---|---|---|
Job stuck in Validating, then Failed | Bad input format, role/permission, or KMS access | GetModelInvocationJob failure message; validate JSONL and the batch role | Fix the format/permission; resubmit (same clientRequestToken is safe) |
error lines scattered in output | Poison records (bad prompt, oversize, unsupported content) | errorRecordCount in manifest; inspect the error objects | Route to the reprocessing queue; fix and redrive — ledger prevents double-processing |
ThrottlingException in Mode B | On-demand TPM/RPM exceeded | Throttle errors in Lambda logs; CloudWatch model metrics | Lower MaxConcurrency; add backoff Retry; or move the workload to Mode A batch |
| Submissions rejected at scale | Concurrent-jobs-per-model quota hit | CreateModelInvocationJob errors; count in-flight jobs | Set MaxConcurrency to the quota; request an increase via Service Quotas |
| Map Run fails fast partway through | Tolerated-failure threshold exceeded | Map Run status; failure ratio in ResultWriter output | Expected circuit-breaker — fix the systemic cause (usually a prompt/template bug) and rerun |
| Dead-letter queue growing | Records failing every retry | DLQ depth alarm; inspect message bodies | Diagnose the common cause; redrive after the fix |
| Downstream stage never starts | Missed completion event | EventBridge delivery is best-effort; check the rule and target | Add a periodic reconciliation that lists recent jobs as a backstop |
The pattern across every row is the same: because each stage carries its own counters and its failures are isolated into their own lane, a problem surfaces at the stage that caused it — a validation failure, a throttle, a poison record, an over-tight threshold — rather than as an undifferentiated "the batch run was bad." Note the last row in particular: because EventBridge delivery is best-effort, a robust pipeline pairs the event-driven trigger with a lightweight periodic reconciliation (list recent jobs, act on any
Completed ones the event handler missed) so completion is eventually consistent even if an event is dropped.10. Frequently Asked Questions
When should I use a Bedrock batch job versus synchronous fan-out?Use a batch job (
CreateModelInvocationJob) for very large, latency-tolerant corpora where throughput and the discounted asynchronous tier matter more than turnaround. Use synchronous fan-out through Distributed Map when the volume is moderate, when you need per-record branching or near-real-time results, or when the job is below the batch minimum-record quota. Many pipelines use both behind one control plane.How do I process a corpus larger than the per-job record limit?
Split it into shards that each respect the per-job and per-file record caps, then drive the shards through a Step Functions Distributed Map with
MaxConcurrency set to the per-model concurrent-jobs quota. The Map shards, submits up to the limit, waits, and aggregates. The exact caps are per-model and adjustable — read them from Service Quotas.Does batch inference preserve the order of my input records?
No. Output line order is not guaranteed to match input order, and Distributed Map children finish in arbitrary order. Always join results on
recordId, never on position. If you need global ordering downstream, carry an explicit sequence field and sort, or route ordered work through a FIFO SQS queue.How do I make the pipeline safe to retry?
Two levels. Pass a deterministic
clientRequestToken so a re-submitted job is ignored rather than duplicated, and key a DynamoDB ledger on a deterministic recordId with a conditional write so a reprocessed record's downstream side effect happens exactly once. Together they make retries and DLQ redrives safe.How do I know a job finished without polling?
Subscribe to the Amazon EventBridge
Batch Inference Job State Change event (source: aws.bedrock) and match on detail.status. A rule triggers your post-processing Lambda the moment a job completes. Because delivery is best-effort, add a periodic reconciliation as a backstop.Can I keep the data private and encrypted?
Yes. Attach a
vpcConfig to the batch job so traffic stays on private networking, encrypt output with a customer-managed KMS key via s3EncryptionKeyId, and scope the batch role and bucket prefixes per tenant so the data perimeter is enforced by IAM and bucket layout rather than by the model.Is batch inference the same as Provisioned Throughput?
No — they are different capacity models. Batch inference is an asynchronous, S3-in/S3-out tier for bulk work; Provisioned Throughput reserves dedicated capacity for low-latency synchronous serving. They solve different problems; consult the official Amazon Bedrock pricing and documentation for the trade-offs.
11. Summary
Running a generative-AI model over a large corpus is not a bigger version of calling it once — it is a different engineering problem whose center of gravity is the operational plane: retry, ordering, idempotency, failure isolation, and completion signaling. The Large-Scale Batch Generative AI Pipeline on AWS makes that plane explicit and operable. A Step Functions Standard workflow shards the corpus with Distributed Map and bounds concurrency to the downstream limit; the work runs in one of two modes — a Bedrock batch job (CreateModelInvocationJob) for bulk, latency-tolerant corpora, or a synchronous Distributed-Map fan-out for moderate, control-sensitive workloads; results land in S3 as per-record JSONL plus a manifest; poison records and failed shards are isolated into an SQS dead-letter lane with native redrive; a DynamoDB ledger keyed by recordId makes every retry and replay idempotent; and an EventBridge Batch Inference Job State Change event starts the next stage without anyone polling.The architectural through-line is that throughput is governed by the minimum of several interacting quotas in different services, and the architect's job is to align
MaxConcurrency and shard sizing to whichever is the bottleneck — read from Service Quotas, not guessed. Choose the inference mode by volume and latency, shard within the quotas, key everything on recordId, isolate failures to a dead-letter queue, signal completion through EventBridge, and make the downstream handoff event-driven and idempotent — and you have a batch pipeline you can trust over ten million records. The companion article on multimodal ingestion builds the structuring stage that feeds this pipeline, and the agentic-RAG article builds the read path that queries what it produces.12. References
- Amazon Bedrock - Process multiple prompts with batch inference
- Amazon Bedrock - Create a batch inference job
- Amazon Bedrock - Format and upload your batch inference data
- Amazon Bedrock - View the results of a batch inference job
- Amazon Bedrock - Monitor batch inference jobs
- Amazon Bedrock - Supported Regions and models for batch inference
- Amazon Bedrock API Reference - CreateModelInvocationJob
- Amazon Bedrock - Monitor job state changes using Amazon EventBridge
- Amazon EventBridge - Amazon Bedrock events
- AWS Step Functions - Using Map state in Distributed mode
- AWS Step Functions - ItemReader for Distributed Map
- AWS Lambda - Handling errors for an SQS event source (partial batch responses)
- Amazon SQS - Using dead-letter queues
- Powertools for AWS Lambda - Idempotency
- Service Authorization Reference - Actions for Amazon Bedrock
- Amazon Bedrock pricing
Related Articles in This Series
- Multimodal Document Intelligence Pipeline on AWS
The paired pipeline that structures source documents before bulk enrichment. - Agentic RAG Architecture on Amazon Bedrock
The read path that queries what this pipeline produces. - Amazon Bedrock RAG Architecture Guide
Static-RAG mechanics: chunking, vector stores, and ingestion. - Amazon Bedrock Basic Information and API Examples
The synchronous InvokeModel and Converse request shapes. - Amazon Bedrock Glossary
Terminology reference.
References:
Tech Blog with curated related content
Written by Hidekazu Konishi