AWS History and Timeline regarding Amazon Simple Queue Service - Overview, Functions, Features, Summary of Updates, and Introduction to SQS
First Published:
Last Updated:
This time, I have created a historical timeline for Amazon Simple Queue Service (Amazon SQS), which was first announced as an AWS infrastructure service in November 2004 and provides a fully managed message queuing service.
As Amazon SQS will celebrate its 20th anniversary since the announcement in November 2024, I wrote this article as an early celebration, although it is quite premature.
Just like before, I am summarizing the main features while following the birth of Amazon SQS and tracking its feature additions and updates as a "Current Overview, Functions, Features of Amazon SQS".
I hope these will provide clues as to what has remained the same and what has changed, in addition to the features and concepts of each AWS service.
Background and Method of Creating Amazon SQS Historical Timeline
The reason for creating a historical timeline of Amazon SQS this time is none other than that Amazon SQS will celebrate its 20th anniversary since the announcement in 2024.Amazon SQS was the first AWS service announced as an AWS infrastructure service in November 2004 (*1).
Therefore, 2024 is also a milestone year marking the 20th anniversary of the announcement of AWS infrastructure services.
Another reason is that since Amazon SQS emerged as the first AWS infrastructure service in November 2004, it has continued to be used in distributed systems, microservices, serverless applications, etc., even as IT trends have changed, providing a fully managed message queuing service. Therefore, I wanted to organize the information of Amazon SQS with the following approaches.
- Tracking the history of Amazon SQS and organizing the transition of updates
- Summarizing the feature list and characteristics of Amazon SQS
There may be slight variations in the dates on the timeline due to differences in the timing of announcements or article postings in the references used.
The content posted is limited to major features related to the current Amazon SQS and necessary for the feature list and overview description.
In other words, please note that the items on this timeline are not all updates to Amazon SQS features, but are representative updates that I have picked out.
*1) Refer to Introducing the Amazon Simple Queue Service.
Apart from infrastructure services, a service called "Alexa Web Information Service (AWIS)" was listed in the AWS What's New archive for 2004 prior to Amazon SQS, on 2004-10-04.
Also, the first service to reach General Availability (GA) was Amazon Simple Storage Service (Amazon S3), which was announced and became GA on 2006-03-14.
Amazon SQS Historical Timeline (Updates from November 3, 2004)
Now, here is a timeline related to the functions of Amazon SQS. The history of Amazon SQS spans more than 21 years from November 2004, and the service passed its 20th anniversary in November 2024.2004 | 2006 | 2011 | 2012 | 2013 | 2014 | 2015 | 2016 | 2017 | 2018 | 2019 | 2020 | 2021 | 2022 | 2023 | 2024 | 2025
* The table can be sorted by clicking on the column names.| Date | Summary |
|---|---|
| 2004-11-03 | Amazon Simple Queue Service (Amazon SQS) is announced. [Source] |
| 2006-07-11 | Amazon Simple Queue Service (Amazon SQS) becomes generally available (GA). [Source] |
| 2011-10-06 | Support for Amazon SQS is added to the AWS Management Console. [Source] |
| 2011-10-21 | Support for Delay Queues, Message Timers, and Batch APIs is introduced. [Source] |
| 2012-11-05 | Announcement of Amazon SQS API version 2012-11-05. [Source] |
| 2012-11-08 | Support for long polling is introduced. [Source] |
| 2012-11-21 | Ability to subscribe Amazon SQS queues to Amazon SNS topics using AWS Management Console for Amazon SQS. [Source] |
| 2013-06-18 | Maximum payload size is increased from 64KB to 256KB. [Source] |
| 2014-01-29 | Support for dead-letter queues is added. [Source] |
| 2014-05-06 | Support for message attributes is added. [Source] |
| 2014-07-16 | AWS CloudTrail now logs API actions for Amazon SQS. [Source] |
| 2014-12-08 | Ability to delete messages in a queue using the PurgeQueue API action is added. [Source] |
| 2014-12-29 | Amazon SQS Java Messaging Library for JMS becomes available. [Source] |
| 2015-10-27 | Amazon SQS Extended Client Library for Java, allowing to send and receive messages with payloads up to 2GB using Amazon S3, becomes available. [Source] |
| 2016-03-30 | Amazon CloudWatch Events now supports Amazon SQS queues as event targets. [Source] |
| 2016-08-31 | ApproximateAgeOfOldestMessage CloudWatch metric becomes available for monitoring the elapsed time of the oldest message in a queue. [Source] |
| 2016-11-17 | FIFO (First-In-First-Out) queues become available, and existing queues are now named Standard queues. [Source] |
| 2017-04-24 | Amazon SQS Extended Client Library for Java and Amazon SQS Java Messaging Library for JMS begin supporting FIFO queues. [Source] |
| 2017-04-28 | Support for server-side encryption (SSE) is introduced. [Source] |
| 2017-05-01 | Amazon SQS becomes a HIPAA eligible service. [Source] |
| 2017-05-19 | Amazon SQS Extended Client Library for Java can now be used in conjunction with Amazon SQS Java Messaging Library for JMS. [Source] |
| 2017-10-19 | Tags become usable for Amazon SQS queues, allowing for the tracking of cost allocations using cost allocation tags. [Source] |
| 2017-12-07 | All API actions except ListQueues now support resource-level permissions. [Source] |
| 2018-04-10 | Amazon CloudWatch Events now supports Amazon SQS FIFO queues as event targets. [Source] |
| 2018-06-28 | AWS Lambda now supports Amazon SQS Standard queues as event sources. [Source] |
| 2018-12-13 | Support for AWS PrivateLink using Amazon VPC Endpoints is introduced, allowing private connections to AWS services supporting VPCs. [Source] |
| 2019-04-04 | VPC endpoint policy support is introduced. [Source] |
| 2019-07-25 | Temporary queue client becomes available. [Source] |
| 2019-08-22 | Support for Tag-on-create during queue creation is introduced. AWS IAM keys 'aws:TagKeys' and 'aws:RequestTag' can be specified. [Source] |
| 2019-08-28 | Support for troubleshooting queues using AWS X-Ray is introduced. [Source] |
| 2019-11-19 | AWS Lambda now supports Amazon SQS FIFO queues as event sources. [Source] |
| 2019-12-11 | One-minute Amazon CloudWatch metrics become available. [Source] |
| 2020-06-22 | Pagination support for the ListQueues and ListDeadLetterSourceQueues APIs is introduced, allowing for the specification of the maximum number of results returned from a request. [Source] |
| 2020-12-17 | High throughput mode for messages in FIFO queues is preview released. [Source] |
| 2021-05-27 | High throughput mode for messages in FIFO queues becomes generally available (GA). [Source] |
| 2021-11-23 | Managed server-side encryption (SSE-SQS) using Amazon SQS-owned encryption keys becomes available. [Source] |
| 2021-12-01 | Support for redrive in Standard queues' dead-letter queues is introduced. [Source] |
| 2022-10-04 | Support for default enabling of server-side encryption (SSE-SQS) using Amazon SQS-managed encryption keys is introduced. [Source] |
| 2022-11-17 | Attribute-Based Access Control (ABAC) is introduced. [Source] |
| 2023-07-27 | API requests using the AWS JSON protocol become available in Amazon SQS. Compared with the AWS query protocol, the JSON protocol reduces request/response processing overhead. [Source] |
| 2023-11-27 | Support for redrive in FIFO queues' dead-letter queues is introduced. [Source] |
| 2024-02-06 | Amazon SQS Extended Client Library for Python, allowing to send and receive messages with payloads up to 2GB using Amazon S3, becomes available. [Source] |
| 2024-07-05 | Two new Amazon CloudWatch metrics for FIFO queues are introduced. The NumberOfDeduplicatedSentMessages and ApproximateNumberOfGroupsWithInflightMessages metrics help detect duplicate producers and troubleshoot FIFO throughput by monitoring in-flight message groups. [Source] |
| 2024-11-21 | The in-flight message limit for FIFO queues is increased from 20,000 to 120,000 messages. Consumers can now process up to 120,000 messages concurrently from a FIFO queue, removing a common scaling constraint for high-throughput consumers. [Source] |
| 2025-04-21 | Internet Protocol version 6 (IPv6) is supported on public API endpoints. Clients can communicate with Amazon SQS using IPv6, IPv4, or dual-stack configurations, simplifying network architecture for IPv6-native applications. [Source] |
| 2025-07-18 | IPv6 support is extended to VPC endpoints via AWS PrivateLink. IPv6 API requests can now be made through interface VPC endpoints, not just public endpoints, enabling private dual-stack connectivity from within a VPC. [Source] |
| 2025-07-21 | Fair queues are introduced to mitigate noisy-neighbor impact in multi-tenant Standard queues. By including a message group ID when sending to a Standard queue, a tenant sending too many messages or slow-processing messages sees its own dwell time increase while other tenants' messages keep flowing without added delay; no consumer-side changes are required. [Source] |
| 2025-07-31 | Amazon SNS standard topics gain support for message group IDs, extending Amazon SQS fair queue behavior to subscribed queues. When a message group ID is included in messages published to an SNS standard topic, SNS forwards it to all subscribed SQS Standard queues, automatically activating fair queue behavior across them. [Source] |
| 2025-08-04 | The maximum message payload size is increased from 256 KiB to 1 MiB. Standard and FIFO queues can now send and receive payloads up to 1 MiB without offloading data to Amazon S3 or splitting messages, and the AWS Lambda event source mapping for Amazon SQS was updated in tandem to support 1 MiB payloads. [Source] |
| 2025-11-13 | Amazon EventBridge adds support for targeting Amazon SQS fair queues. EventBridge rules can route events directly to SQS fair queues by specifying a MessageGroupId as a static value or a JSON path expression, preserving consistent processing times across tenants. [Source] |
| 2025-11-14 | AWS Lambda introduces Provisioned Mode for Amazon SQS event source mappings. Provisioned Mode lets customers configure a minimum and maximum number of dedicated event pollers for an SQS event source, providing faster scaling and higher concurrency for applications with unpredictable traffic bursts and strict latency requirements. [Source] |
Current Overview, Functions, Features of Amazon SQS
Here, I will explain in detail the main features of the current Amazon SQS.Amazon Simple Queue Service (Amazon SQS) is a highly reliable and scalable fully managed messaging queuing service for microservices, distributed systems, and serverless applications.
Amazon SQS provides a messaging service with high reliability and durability, enabling asynchronous processing and efficient message exchange between applications.
Furthermore, its auto-scaling and data redundancy capabilities accommodate system load fluctuations and prevent message loss.
Moreover, its pay-as-you-go pricing model delivers a cost-effective solution, and high security is achieved through access management with AWS Identity and Access Management (IAM) and data encryption in transit and at rest.
In addition to these features, easy integration with other AWS services allows for rapid development and flexible operation of applications.
Use Cases for Amazon SQS
Amazon SQS is utilized in various scenarios, designed to enhance system fault tolerance and scalability.The main use cases for the message queuing service provided by Amazon SQS include:
- Asynchronous communication
Transfers messages asynchronously between applications, allowing system components to scale and process independently. - Load leveling
Accommodates peak-time loads and sudden traffic spikes by holding messages in the queue, preventing overload in subsequent systems. - Integration of distributed systems
Exchanges messages between different system components within a distributed architecture.
Specific Examples of Use Cases
For example, here are some specific use case scenarios:- E-commerce order system
Transmits order information received from a web application to SQS, and the order processing service retrieves and processes messages from the queue sequentially. This ensures that order data is processed securely without loss, even if customers place orders simultaneously, minimizing the risk of the order processing system going down. - Communication between microservices
When adopting a microservices architecture, message exchanges between services can be conducted using SQS. Using a message queue helps maintain loose coupling between services, allowing the overall system to operate more resiliently. - Big data applications
Collects data through SQS from data aggregation points and delivers it for batch or stream processing. This enables the processing of data at various speeds.
Amazon SQS Conceptual Diagram
From here, I will explain the main features and characteristics of Amazon SQS, but before that, to make it easier to imagine the overall picture of Amazon SQS, I will show you the conceptual diagram of Amazon SQS next.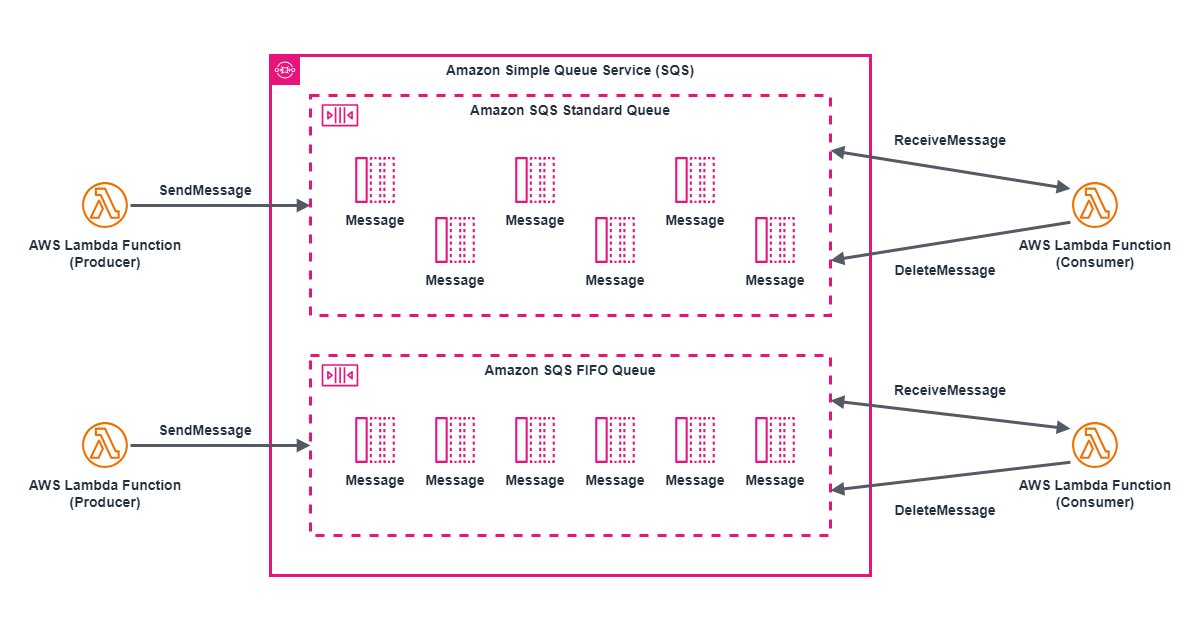
Amazon SQS provides actions to operate basic queues.
The system responsible for sending messages to the Amazon SQS queue is called a producer, and the system responsible for receiving and deleting messages from the Amazon SQS queue is called a consumer.
In the conceptual diagram above, it is assumed that both the producer and consumer are implemented with AWS Lambda Functions.
The producer sends messages to the Amazon SQS queue with
SendMessage, the consumer receives messages from the Amazon SQS queue with ReceiveMessage, and once message processing is complete, the consumer deletes the message with DeleteMessage.In addition to the API actions mentioned in the conceptual diagram, such as
SendMessage, ReceiveMessage, DeleteMessage, there are also batch processing API actions like SendMessageBatch, ReceiveMessage, DeleteMessageBatch.Amazon SQS Standard Queues can handle messages with nearly unlimited throughput but do not guarantee the order of messages and may deliver duplicate messages.
On the other hand, Amazon SQS FIFO Queues have a limited throughput but guarantee the order of messages and exactly one message delivery.
Following this, I will explain about these Amazon SQS Standard Queues and Amazon SQS FIFO Queues.
Amazon SQS Standard Queues
Amazon SQS Standard Queues are robust managed message queuing services that provide mechanisms for asynchronously sending and receiving messages between distributed systems.The main features of standard queues include:
- Unlimited transactions
Standard queues support an unlimited number of transactions, with no upper limit on the number of calls to API actions such asSendMessage,ReceiveMessage, andDeleteMessage. This is suitable for applications requiring high processing volume or throughput. - At least once delivery guarantee
Standard queues guarantee that messages will be delivered at least once. However, it is important to note that standard queues may deliver messages multiple times. - Best effort order maintenance
In most cases, messages in standard queues are received in the order they were sent. However, standard queues do not guarantee strict ordering of messages, and the order may occasionally be switched, so it is recommended to use FIFO queues when complete order is required.
In addition, fair queues, introduced on 2025-07-21, mitigate the noisy-neighbor problem in multi-tenant Standard queues: by including a message group ID when sending messages to a Standard queue, a tenant that sends too many messages or whose messages are slow to process sees only its own dwell time increase, while other tenants' messages keep flowing without added delay, with no consumer-side changes required.
Amazon SQS FIFO Queues
Amazon SQS FIFO Queues (FIFO queues) are queue services designed for specific use cases that provide strict message ordering and eliminate duplicate messages.FIFO queues ensure that messages are retrieved from the queue in the order they were sent, thanks to the order maintenance feature, and guarantee "exactly once delivery" through the deduplication feature.
Strict Message Ordering (Order Maintenance Feature)
In FIFO queues, the order of messages sent is strictly maintained. Messages are processed based on the first-in-first-out principle, and their order is not changed within the same message group.Exactly Once Processing (Deduplication Feature)
Unlike standard queues, FIFO queues minimize duplicate messages. By default, FIFO queues are set with a five-minute deduplication window, during which a message with the same Message Deduplication ID sent again within this period is not added to the queue more than once. There are two methods for deduplication:- Automatic generation of Message Deduplication ID
When content-based deduplication is enabled, Amazon SQS automatically generates a unique message deduplication ID using a SHA-256 hash of the message content. This ID is generated from the message body content, and message attributes are not considered. - Explicit specification of Message Deduplication ID
Developers can specify their own message deduplication ID when sending a message. If a message with the same ID is sent within the same deduplication window, the corresponding message will be added to the queue only once.
Transition from Standard Queues to FIFO Queues
When existing applications using standard queues require the strict order and exactly once processing features, an appropriate transition to FIFO queues is necessary. This transition is often used when aiming to ensure strict message order maintenance and deduplication in practice.However, direct conversion from standard queues to FIFO queues is not possible, and the transition is made using one of the following procedures:
- Delete the existing standard queue and create a new FIFO queue
- Simply add a new FIFO queue and retain the existing standard queue
Summary of transition process and points to consider when transitioning from standard queues to FIFO queues:
Transition Process
- Queue recreation
Direct conversion from a standard queue to a FIFO queue is not possible. You must either create a new FIFO queue or delete the existing standard queue and recreate it as a FIFO queue. - Application adjustment
Changes to the application code are required to utilize the unique features of FIFO queues (such as message group ID and deduplication ID).
Points to Consider
- Using high throughput mode
Enabling high throughput mode for FIFO queues maximizes message sending throughput. However, this mode has specific limitations, so please check the details in the AWS documentation before use. - Setting delays
In FIFO queues, delays can be set for the entire queue rather than individual messages. If individual message delays are necessary, corresponding adjustments on the application side are required. - Using message groups
Grouping similar or related tasks allows messages to maintain their order while being processed in parallel by multiple processors. Proper design of message group IDs is important for effective scaling. - Deduplication strategy
Using deduplication IDs helps prevent the same message from being processed multiple times. Additionally, content-based deduplication functionality can also be enabled. - Visibility timeout management
If message processing takes a long time and an extension of the visibility timeout is necessary, consider adding a receive request attempt ID to each ReceiveMessage action to manage retry attempts for receive requests.
High Throughput for FIFO Queues
High throughput for FIFO queues provides support for increasing the number of requests per second per API.Enabling high throughput for FIFO queues allows you to increase the number of requests per second per API.
To increase the number of requests for FIFO queues, you can increase the number of message groups used.
Amazon SQS stores FIFO queue data in partitions.
Partitions, which are automatically replicated across multiple availability zones within an AWS region, are the storage allocated for the queue.
Users do not manage partitions; Amazon SQS handles partition management.
High throughput can be enabled for new FIFO queues or existing FIFO queues.
The following three options are provided when creating or editing FIFO queues:
- Enable high throughput FIFO This allows higher throughput for messages in the current FIFO queue.
- Deduplication range Specifies whether deduplication occurs across the entire queue or on a per-message group basis.
- FIFO throughput limit Specifies whether the throughput limit for messages in the FIFO queue is set for the entire queue or on a per-message group basis.
- The deduplication range is set to message group
- The FIFO throughput limit is set per message group ID
If changes are necessary to these automatic settings, the queue will automatically revert to the normal throughput mode, but deduplication will continue to occur as specified by the user.
After creating or editing the queue, you can send, receive, and delete messages at a high transaction rate.
In high throughput mode for FIFO queues, each partition supports up to 3,000 messages per second with batching, or up to 300 messages per second for send, receive, and delete operations, and overall queue throughput scales by distributing messages across more message groups; the default high-throughput quotas have been raised repeatedly and vary by Region, so refer to the Amazon SQS service quotas for the latest values.
However, this limit is applied per message group ID, so increasing the number of message groups can enhance the overall throughput of the queue.
Differences and Comparisons between Amazon SQS Standard Queues and Amazon SQS FIFO Queues
The differences and comparisons between Amazon SQS Standard Queues and Amazon SQS FIFO Queues are summarized in the table below.
| Comparison Item | Amazon SQS Standard Queues | Amazon SQS FIFO Queues |
|---|---|---|
| Delivery Guarantee | At least one delivery. (There is a possibility of duplicate deliveries.) |
Exactly one delivery. |
| Delivery Order | Best effort basis. (The order may change.) |
Maintains First-In-First-Out order within the message group. |
| Throughput | Nearly unlimited. | Up to 300 transactions per second, per API actions (SendMessage, ReceiveMessage, or DeleteMessage). In batch operations, up to 3000 messages per second, per API actions (SendMessageBatch, ReceiveMessage, or DeleteMessageBatch). Enabling high throughput mode allows allocation of even higher throughput. |
Main Features of Amazon SQS
Below, I will describe the key features available for both Amazon SQS Standard queues and FIFO queues.(Note that the maximum message payload size, which had been 256 KiB since 2013-06-18, was increased to 1 MiB on 2025-08-04 for both Standard and FIFO queues.)
Short Polling and Long Polling
Amazon SQS offers two message reception methods: short polling and long polling.Short polling is the default setting and is effective in environments where messages arrive frequently, but long polling helps reduce costs and improve efficiency in low message arrival environments.
Short Polling
During short polling, ReceiveMessage requests are made to a subset of the queue (a randomly selected group of servers), and available messages are immediately returned.Even if no messages exist, SQS returns a response immediately.
Therefore, if there are few messages in the queue, you may retrieve messages in successive requests, but one request may not capture all messages.
Repeated requests can evenly receive messages from the queue, but repeated requests when no messages are present incur costs and increase traffic.
Long Polling
Long polling involves waiting for the time specified by theReceiveMessageWaitTimeSeconds parameter, querying all SQS servers during this time.SQS holds off on the response until at least one message is found or the specified wait time has expired.
If new messages arrive, they are immediately returned as a response, and the system continues to wait for more messages up to the maximum number of messages until the wait time expires.
If no messages are found when the wait time ends, an empty response is returned.
Long polling reduces unnecessary requests and minimizes the occurrence of false empty responses (cases where messages are available but not included in the response), improving cost efficiency.
Long polling is enabled by setting
ReceiveMessageWaitTimeSeconds to a value greater than zero, with a maximum of 20 seconds of waiting allowed.Since no additional traffic occurs during the wait time, cost performance is improved.
This allows for efficient message processing when the frequency of message arrival is low or when the application has sufficient processing capacity.
Dead-letter Queues
Dead-letter queues are used to isolate messages that fail to process, aiding in debugging and issue analysis.A message is automatically moved to a dead-letter queue after exceeding a specified number of receive attempts (
maxReceiveCount). This feature is crucial for isolating problematic messages and facilitating cause analysis.Dead-letter queues are not created automatically. You must create a queue to use as a dead-letter queue.
Additionally, a FIFO queue's dead-letter queue must also be a FIFO queue, and similarly, a standard queue's must be a standard queue.
Dead-letter queues and other queues must exist within the same AWS account and region.
maxReceiveCount specifies how many times a message is received from the source queue before it is moved to the dead-letter queue.Setting a lower value moves messages to the dead-letter queue after fewer receive attempts, such as in cases of network errors or client dependency errors.
However, it is necessary to set the value of
maxReceiveCount considering sufficient retry opportunities so the system can recover from errors.Once the cause of a message's failure has been identified, or when messages are consumable again, a Redrive Policy can be used to move messages from the dead-letter queue back to the source queue.
Moving messages from the dead-letter queue incurs charges based on the number of API calls, billed according to Amazon SQS pricing.
To set up a dead-letter queue, first create a queue to be used as the dead-letter queue.
Then, in the settings for the source queue, you specify the queue to use as the dead-letter queue and set the value of
maxReceiveCount.This ensures that messages that fail to process are automatically moved to the designated dead-letter queue.
Scenarios for using dead-letter queues include cases where message processing fails, and it is necessary to identify the problem's cause and take appropriate action.
For instance, when integration with an external service fails or when the message format is incorrect.
To move messages from a dead-letter queue, you use the Redrive Policy.
Redrive Policy is a setting used to move messages back to the original source queue from a dead-letter queue.
By setting a Redrive Policy, you can reprocess messages accumulated in the dead-letter queue.
For debugging and troubleshooting dead-letter queues, you can utilize CloudWatch metrics.
By monitoring metrics related to the dead-letter queue, you can understand the number of failed messages and the number of messages lingering in the dead-letter queue.
Based on this information, you can take appropriate action.
When setting up and using dead-letter queues, there are numerous implementation considerations and best practices, making proper design and operation crucial.
For example, setting the size of the dead-letter queue appropriately and regularly monitoring messages lingering in the dead-letter queue are recommended.
These considerations should be carefully addressed to ensure proper setup and operation.
Visibility Timeout
The "visibility timeout" is the period during which other consumers (applications that receive and process messages) cannot receive a message while it is being processed.During this timeout period, Amazon SQS blocks the message from being received by other consumers.
The default visibility timeout is 30 seconds, but it can be set between 0 seconds and 12 hours.
The correct setting of the visibility timeout is crucial. The consumer must complete the processing and deletion of the message within this period.
If the timeout expires before processing is completed, the message may be received again by another consumer. This reduces the risk of the same message being processed multiple times.
However, even with the visibility timeout set, standard queues cannot completely prevent the duplicate reception of messages (due to the "at-least-once delivery" policy).
On the other hand, FIFO queues use the message deduplication ID and the receive request attempt ID, allowing producers and consumers to retry sending and receiving as needed.
In-flight Messages
Amazon SQS messages have three states:- State after being sent by the producer to the queue
- State after being received from the queue by the consumer
- State after being deleted from the queue
Conversely, messages that have been received by the consumer but not deleted are in "in-flight" state, and there is a limit to their number.
The limit for in-flight messages is 120,000 for both standard queues and FIFO queues (the FIFO queue limit was increased from 20,000 to 120,000 on 2024-11-21).
Visibility timeout allows you to change the default value per queue, or specify a particular timeout value when receiving messages.
If a processing time of more than 12 hours is required, it would be advisable to consider using AWS Step Functions.
Best Practices for Visibility Timeout
If the processing time for a message is uncertain, implement a heartbeat in the consumer process.For example, set the initial visibility timeout to 2 minutes and continue to add 2 minutes of timeout every minute as long as the consumer is processing.
If you find that the timeout is insufficient after starting the process, you can specify a new timeout value using the
ChangeMessageVisibility action to extend or shorten the visibility timeout.Also, if you decide not to process, you can set the timeout to zero using the
ChangeMessageVisibility action, making the message immediately visible to other components for reprocessing.Delay Queues
Amazon SQS delay queues allow you to withhold messages from being delivered to consumers for a specified period.This feature is useful, for example, when consumer applications need additional time to process messages.
Messages sent to a delay queue remain invisible to consumers within the queue until the specified delay period has elapsed.
The default (minimum) delay time is 0 seconds, and the maximum delay time is as follows:
- For standard queues, the maximum delay time is 900 seconds (15 minutes)
- For FIFO queues, the maximum delay time is 900 seconds (15 minutes)
The new setting applies only to messages added after the change. In FIFO queues, by contrast, the delay setting is retroactive and also affects messages already in the queue.
Delay queues are similar to visibility timeouts, but the main differences between the two are as follows.
- Delay queues: messages are hidden immediately after being added to the queue
- Visibility timeouts: messages are hidden after being retrieved from the queue
Using message timers, you can set a unique delay time for each message, up to a maximum of 900 seconds (15 minutes), which is the same maximum value for the queue-level
DelaySeconds attribute.If both the queue-level
DelaySeconds attribute and the message timer DelaySeconds value are set, the message timer value takes precedence.In other words, if a message timer is set, the queue's
DelaySeconds value is ignored.By using delay queues and message timers together, you can set a default delay time for the entire queue while specifying individual delay times for specific messages.
Message Timers
Amazon SQS message timers allow you to specify the initial invisibility period for each message added to the queue.This means that even though a message has arrived in the queue, it will not be visible to the consumer until after the set time has passed.
For example, a message with a 45-second timer will be invisible to the consumer for the first 45 seconds after it reaches the queue.
The minimum (default) delay time is 0 seconds, but you can set a delay of up to 15 minutes.
Message timers can be set when sending messages using the AWS Management Console or AWS SDK.
However, message timers cannot be set for individual messages in FIFO (first-in, first-out) queues.
If you want to set a delay for messages in a FIFO queue, you need to use delay queues, which allow you to set a delay period for the entire queue.
Also, the message timer setting for an individual message takes precedence over the Amazon SQS delay queue's
DelaySeconds value set.This means that the message timer setting overrides the delay queue setting.
Differences Between Visibility Timeout, Delay Queues, and Message Timers
The main differences between Visibility Timeout, Delay Queues, and Message Timers are summarized as follows:- Delay Queues
Messages are hidden immediately after being added to the queue.
Delay Queues are set for the entire queue, so the delay applies to all messages added to the queue. This delay prevents messages from being obtained by consumers until a specified time has elapsed.
- Visibility Timeout
Messages are hidden after being retrieved from the queue.
This setting makes a message invisible to other consumers for a certain period after it has been read by a consumer. This prevents duplicate handling of messages and ensures that consumers have time to complete processing of the messages.
- Message Timers
Delay times can be set for individual messages.
This allows for the control of the time a specific message is visible to consumers after being added to the queue. Message Timers can set different delay times for individual messages, unlike Delay Queues, allowing for more fine-grained delay management on a per-message basis.
Temporary Queues
The Amazon SQS temporary queue feature provides a queue for temporary use between clients and servers, similar to the request-response pattern.To dynamically generate these temporary queues while maintaining high throughput and keeping costs low under application management, the "Temporary Queue Client" is available.
This client automatically maps multiple temporary queues created for a specific process to a single Amazon SQS queue.
This allows the application to reduce API calls and improve throughput, even if traffic to each temporary queue is low.
When a temporary queue is no longer needed, the client automatically deletes it.
This happens even if all processes using the client do not shut down properly.
Benefits of temporary queues include:
- Functioning as lightweight communication channels dedicated to specific threads or processes
- Capability to be created and deleted without incurring additional costs
- API compatibility with non-temporary (regular) Amazon SQS queues (existing code can send and receive messages)
LoginServer class to process login requests from clients, launching a thread that polls the queue for login requests and calls the handleLoginRequest() method for each message.Inside the
handleLoginRequest() method, you would call the doLogin() method to perform the login process.To ensure proper cleanup of queues, it is necessary to call the
shutdown() method when the application no longer uses the temporary queue client.Similarly, you can use the
shutdown() method of the AmazonSQSRequester interface. This ensures that temporary queues are properly deleted, preventing resource wastage.Here are specific examples of applications that benefit from the characteristics of Amazon SQS's temporary queues, which are ideal for temporary message exchanges similar to the request-response pattern:
- Web Application Login Processes
When users enter information into a login form, it is sent from the web server to the backend server for authentication. In this case, creating a temporary queue for each login request enables efficient and independent message exchange between the web server and backend.
- Integration with External APIs
Applications sending requests to external API services and receiving responses. For example, when integrating with payment services or social media APIs, using temporary queues to manage message exchanges between requests and responses can enhance stability and scalability.
- Asynchronous File Processing
Applications that process files uploaded by users asynchronously in the background. Using temporary queues to manage file processing requests allows for efficient background processing while maintaining responsiveness in the user interface.
- Chat Applications
Chat applications facilitate message exchanges between users. Creating a temporary queue for each user's message sending request allows for scalable and real-time message management of sending and receiving.
- Distributed Processing Systems
Systems that perform large-scale data processing distributed across multiple worker nodes. Using temporary queues to manage job assignments and the transfer of intermediate results between worker nodes can achieve efficient and fault-tolerant distributed processing.
Attribute-Based Access Control (ABAC)
In Amazon SQS, Attribute-Based Access Control (ABAC) allows you to finely manage access permissions based on tags assigned to users or AWS resources using IAM policies.This enables authenticated IAM principals to edit policies and manage permissions without directly managing access to Amazon SQS queues based on associated tags and aliases.
Using ABAC allows you to scale permission management by setting IAM access permissions using tags added according to business roles.
It also reduces the need to update policies every time a new resource is added.
Furthermore, you can create ABAC policies by tagging IAM principals, and design policies that allow Amazon SQS operations when the tags on the IAM user role match the tags on an Amazon SQS queue.
The benefits of using ABAC include reducing the need to create different policies for different roles, thereby lessening operational burdens.
Additionally, it allows for quick scaling of members, and permissions for new resources are automatically granted if appropriately tagged.
Moreover, you can restrict resource access using the permissions of IAM principals and track which users are accessing resources through AWS CloudTrail.
Specific controls with ABAC include creating IAM policies that only allow operations on Amazon SQS queues under conditions where resource tags or request tags match specific keys and values.
You can also create IAM users and Amazon SQS queues with ABAC policies using the AWS Management Console or AWS CloudFormation.
Proper utilization of ABAC can make Amazon SQS operations safer and more flexible, meeting the security requirements of large organizations while allowing efficient resource management.
Best Practices for Amazon SQS
Best Practices Common to Standard and FIFO Queues
To use Amazon SQS efficiently and cost-effectively, the following best practices are recommended. These apply to both Standard Queues and FIFO Queues.- Efficient Message Processing
Set the Visibility Timeout based on the time it takes to receive, process, and delete a message. The maximum value for Visibility Timeout is 12 hours, but it may not be possible to fully set it for each message, so caution is needed. Also, if the processing time for messages is unknown, consider extending the timeout periodically during work after setting the initial Visibility or Timeout. - Handling Request Errors
If using AWS SDK, automatic retries and backoff logic are available. If not using SDK, please wait a certain amount of time before retrying the ReceiveMessage action. It is desirable for the waiting time to back off exponentially, for example, waiting 1 second before the first retry, 2 seconds for the second, and 4 seconds for the third. - Setting Up Long Polling
Long polling can be used to avoid unnecessary polling and reduce costs. The WaitTimeSeconds parameter can be set up to 20 seconds. Note that the HTTP response timeout should be set longer than this parameter. For example, if setting WaitTimeSeconds to 20 seconds, set the HTTP response timeout to more than 30 seconds. - Capturing Problematic Messages
It is important to set up to move difficult-to-process messages to the Dead-letter Queue and obtain accurate CloudWatch metrics. Moving failed messages to the Dead-letter Queue allows you to isolate problematic messages without delaying the processing of the main queue and investigate the cause of the errors. - Retention Period Settings for Dead-letter Queues
The Dead-letter Queue (DLQ) temporarily stores messages that could not be processed normally, allowing you to check them later for troubleshooting or analysis. Therefore, it is common to set the message retention period of the DLQ longer than that of the normal queue. This allows you to investigate and address problematic messages over an adequate period.
Standard Queue: When a message is moved to the Dead-letter Queue, the timestamp at the time of enqueue is retained, and the retention period continues from that point.
FIFO Queue: When a message is moved to the Dead-letter Queue, the timestamp is reset, and a new retention period begins.
Thus, the management of the retention period of the DLQ varies depending on the type of queue. Understanding this difference is important for designing and managing an effective message processing system. - Avoiding Inconsistent Message Processing
As a problem specific to distributed systems, there are cases where messages are marked as delivered but not received by consumers. Therefore, it is not recommended to set the maximum number of receptions to the Dead-letter Queue to 1. Setting the maximum number of receptions to 2 or more can reduce the risk of losing messages due to temporary errors. - Implementing a Request-Response System
When implementing a request-response pattern or RPC (Remote Procedure Call) system, it is important to efficiently use the response queue (the message queue used by clients to receive responses from the server). Instead of creating a new response queue for each message, set one response queue for each producer (the sender of the request) at system startup. Also, using a correlation ID to match requests and responses simplifies the management of the response queue and improves the overall performance of the system. This allows for efficient processing of multiple requests and responses, reducing system response times and optimizing resources. - Cost Reduction
Batch processing of message actions and using the Buffered Asynchronous Client included in the Java AWS SDK can combine client-side buffering and request batching. This reduces the number of API requests and can cut costs. - Using the Appropriate Polling Mode
Long polling is recommended to avoid unnecessary ReceiveMessage calls even when the queue is empty. This method holds responses until the server receives a message or the set wait time expires, reducing the number of API calls and saving costs. On the other hand, short polling returns a response immediately regardless of whether there are messages in the queue, which is suitable for applications that require immediacy but can increase costs due to charges for empty responses. Therefore, it is important to select the optimal polling mode considering both cost and response speed based on the application's requirements.
FIFO Queues Best Practices
To make the most efficient use of Amazon Simple Queue Service (SQS) FIFO queues, it is important to understand and appropriately apply several best practices. Below, I explain the optimal usage of message deduplication ID and message group ID.Using Message Deduplication ID
- Ensuring Message Uniqueness
The message deduplication ID is a token that ensures the sent messages are not duplicated. Messages successfully sent with a specific message deduplication ID are accepted but not delivered within a 5-minute deduplication interval, preventing duplication and ensuring uniqueness. - Providing Message Deduplication ID
Producers need to specify the message deduplication ID for messages with the exact same content, messages with the same content but different attributes, or messages with different content but should be considered duplicates by SQS (including retry counts). This allows SQS to handle duplicate messages appropriately.
Deduplication in Single Producer/Single Consumer Systems
In systems with a single producer and a single consumer, enable content-based deduplication for messages with unique content. In this case, producers can omit the message deduplication ID. Consumers are not required to provide the receive request attempt ID, but it is considered a best practice. This allows for simple system design.Designing for Outage Recovery
The deduplication process of FIFO queues is time-sensitive. When designing applications, producers and consumers must be able to recover from client or network outages. Specifically, producers need to recognize the 5-minute deduplication interval of SQS. If an outage lasts longer than 5 minutes, producers should resend messages using a new message deduplication ID.Using Message Group ID
- Implementing Message Grouping
Messages with the same message group ID are processed sequentially in strict order regarding that message group (order is not guaranteed between different message groups). By alternately processing multiple ordered message groups within the queue, multiple consumers can handle processing, while each user's session data is processed in FIFO order. This ensures message order within the group while achieving parallel processing.
Deduplication in Multi-Producer/Multi-Consumer Systems
In systems with multiple producers and multiple consumers, where throughput and latency are prioritized, generating a unique message group ID for each message is recommended. This prevents duplication, although order is not guaranteed. It ensures system scalability while preventing message duplication.Using Receive Request Attempt ID
- Deduplication of Requests
In case of connection issues between the SDK and Amazon SQS during prolonged network outages, it is best practice to provide the receive request attempt ID and use the same ID for retries when SDK operations fail. This prevents the same message from being received multiple times due to network issues.
References:
Tech Blog with curated related content
AWS Documentation (Amazon Simple Queue Service)
Frequently Asked Questions about Amazon SQS History
- When did Amazon SQS launch?
- Amazon Simple Queue Service (Amazon SQS) was announced in November 2004 as the first AWS infrastructure service (in beta), and became generally available in July 2006, after Amazon S3 (GA in March 2006) and before Amazon EC2 reached GA.
- When did Amazon SQS FIFO queues launch?
- FIFO (First-In-First-Out) queues with exactly-once processing became available on November 17, 2016, at which point the existing queues were named Standard queues. High throughput mode for FIFO queues was released in preview on December 17, 2020, and became generally available on May 27, 2021.
- How has the Amazon SQS maximum message size changed?
- The maximum payload size was increased from 64 KB to 256 KB on June 18, 2013, and from 256 KiB to 1 MiB on August 4, 2025. For larger payloads, the Extended Client Libraries for Java (2015) and Python (2024) can store payloads of up to 2 GB in Amazon S3.
- When did Amazon SQS support server-side encryption?
- Server-side encryption using AWS KMS (SSE-KMS) was introduced on April 28, 2017. SQS-managed encryption keys (SSE-SQS) became available on November 23, 2021, and SSE-SQS became enabled by default for newly created queues in the fall of 2022.
- When did dead-letter queues and DLQ redrive become available?
- Dead-letter queues (DLQs) were added on January 29, 2014. Dead-letter queue redrive, which moves messages from a DLQ back to a source queue, was introduced for Standard queues on December 1, 2021, and for FIFO queues on November 27, 2023.
- What are Amazon SQS fair queues and when did they launch?
- Fair queues, launched on July 21, 2025, mitigate the noisy-neighbor problem in multi-tenant Standard queues. By including a message group ID, a tenant sending too many or slow-processing messages sees only its own dwell time increase, while other tenants' messages keep flowing. Amazon SNS standard topics gained fair-queue support on July 31, 2025, and Amazon EventBridge added fair-queue targets on November 13, 2025.
- When did AWS Lambda support Amazon SQS as an event source?
- AWS Lambda added Amazon SQS Standard queues as an event source on June 28, 2018, and FIFO queues on November 19, 2019. On November 14, 2025, AWS Lambda introduced Provisioned Mode for SQS event source mappings, which provides dedicated event pollers for faster scaling and higher concurrency.
Summary
In this session, I created a historical timeline for Amazon SQS and explored the list and overview of Amazon SQS features.Amazon Simple Queue Service (Amazon SQS), a message queuing service for distributed computing environments, was announced as the first AWS infrastructure service in 2004 and reached GA in 2006.
Initially announced in November 2004, the reaction at the time was "Huh? Why would Amazon do that?" (Reference: The AWS Blog: The First Five Years).
Almost 20 years later, Amazon SQS continues to provide an extremely important component of messaging and queuing for modern computing such as microservices architecture, distributed systems, and serverless computing, continually updating its features.
As evident from the current situation, the vision and design philosophy at the time of the initial announcement of Amazon SQS, which was difficult to understand, accurately captured the future needs and progression of system architecture.
Amazon SQS was already realizing the concepts of serverless, microservices, and fully managed services at that time by prioritizing use through APIs rather than GUI, making it a flexible IaaS that can be easily integrated with other systems in a loosely coupled manner and adapt to changes in use purposes.
I would like to continue watching the trends of what kind of features Amazon SQS will continue to provide in the future.
In addition, there is also a timeline of the entire AWS services including Amazon SQS, so please have a look if you are interested.
AWS History and Timeline - Almost All AWS Services List, Announcements, General Availability(GA)
AWS History and Timeline regarding Amazon SNS - Overview, Functions, Features, Summary of Updates, and Introduction to Amazon Simple Notification Service
I have also written related historical timelines for the services that Amazon SQS works most closely with:
This timeline will be updated as Amazon SQS continues to evolve.
Written by Hidekazu Konishi