Generative BI and NL2SQL Agent Architecture on AWS - Safe Natural-Language Analytics with Bedrock, Athena, and Guardrails
First Published:
Last Updated:
1. Introduction
Ask a large language model to "show me last quarter's revenue by region," and it will happily write a SELECT. That part — text-to-SQL, or NL2SQL — is the part most demos show. It is also the part that matters least in production.
The hard problem is not generating SQL. It is executing model-authored SQL safely against a real data warehouse or data lake without giving a non-deterministic component the keys to your data. A generated query can be subtly wrong (joining on the wrong key, double-counting a fan-out), accidentally expensive (scanning a multi-terabyte table with no partition predicate), or — if your boundaries are weak — destructive or exfiltrating (a DROP, an UNLOAD to an attacker-controlled bucket, a cross-tenant read). A natural-language interface widens the attack surface, because the SQL is now derived from free text that an end user, or an upstream document, controls.
This article is a single Level 400 implementation walkthrough of one named reference architecture for Generative BI / NL2SQL on AWS that treats safe execution as the spine, not an afterthought. The flow is: natural language → an agent grounds itself in catalog metadata → the agent proposes SQL → a safe execution layer validates and runs it read-only, on an allow-list, with a hard scan ceiling → results are formatted and returned with a grounded natural-language summary. We build the agent on Amazon Bedrock AgentCore Runtime with the Strands Agents framework and Bedrock's Converse tool-use loop, execute on Amazon Athena over an AWS Glue Data Catalog, fence the data with AWS Lake Formation and least-privilege IAM, and apply Amazon Bedrock Guardrails at the edges.
One honesty note up front, which the rest of the article keeps faith with: passing the allow-list does not prove a query is safe. Allow-lists, read-only enforcement, scan caps, and Guardrails are layers of a defense-in-depth posture; each reduces risk, none of them is a proof of safety. We will be explicit about what each layer does and does not guarantee, and we will not present "the validator returned OK" as equivalent to "this query is correct and harmless." For attack-procedure detail and concrete prompt-injection payloads, this article deliberately stays at the architecture level and delegates to the responsible-AI cluster.
1.1 Who this is for and what we will not re-explain
This is written for AI application developers and data-platform engineers who can already stand up a Bedrock agent and run an Athena query, and who now need to make natural-language analytics safe to put in front of users. It assumes the Level 300 building blocks and delegates them:
- AgentCore Runtime hosting, session memory, and streaming are covered in Amazon Bedrock AgentCore Implementation Guide Part 1: Runtime, Memory, and Code Interpreter Patterns. We build on it rather than repeat it.
- Generic agent vocabulary — the agentic loop, tool use, ReAct-style reasoning, MCP — lives in the AI Agent Engineering Glossary.
- Bedrock service terms — the Converse API, Knowledge Bases, Guardrails, Bedrock Agents — live in the Amazon Bedrock Glossary.
What is in scope here is the cross-service walkthrough: the request path, the reproducible implementation of each component, the failure modes that cross component boundaries, the observability needed to diagnose them, and the cross-cutting concerns — least-privilege IAM, data boundaries, idempotency, and Guardrails — that hold the whole thing together. Pricing and scan-billing numbers are out of scope by site policy; where cost matters, we talk about it in terms of scan volume and control, and point to the official AWS Pricing pages for the numbers.
2. The Reference Architecture at a Glance
The named architecture has seven roles. Read it once top to bottom; the rest of the article is a deep dive into each box and the arrows between them.
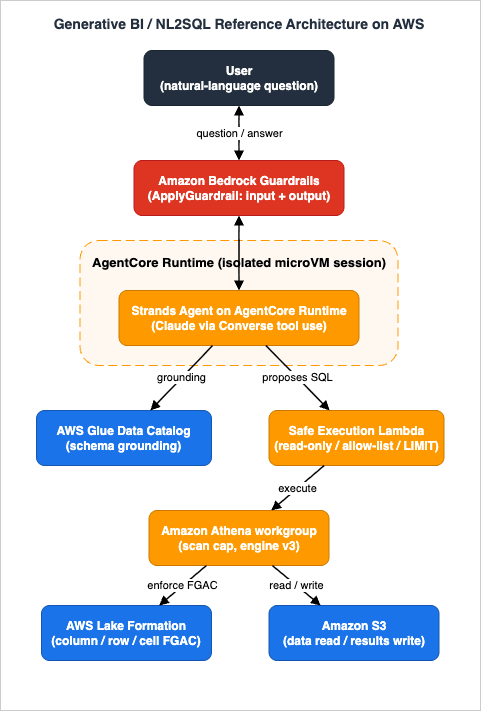
The role of each component, one line each:
- Amazon Bedrock Guardrails — an independent content-safety check applied to the user's question on the way in and the model's answer on the way out, via the
ApplyGuardrailAPI, decoupled from model invocation. - Amazon Bedrock AgentCore Runtime — a serverless, framework-agnostic host that runs each user session in its own isolated microVM, so one conversation's reasoning state cannot leak into another's.
- The Strands agent (Claude on Bedrock) — the reasoning component. It decomposes the question, grounds itself in catalog metadata, and emits a tool call carrying a proposed SQL statement. It never connects to the data store itself.
- AWS Glue Data Catalog — the metastore the agent reads to learn which databases, tables, and columns exist, and what they mean. This is how we stop the model from inventing columns.
- The safe execution layer (AWS Lambda) — the trust boundary. It receives proposed SQL from the agent, validates it (read-only, allow-listed, bounded), binds literal values as execution parameters, and only then submits it to Athena under a constrained role.
- Amazon Athena (with a dedicated workgroup) — the serverless query engine. The workgroup enforces a per-query bytes-scanned ceiling, a fixed encrypted results location, and engine version 3 (required for fine-grained access control).
- AWS Lake Formation + Amazon S3 — Lake Formation enforces column-, row-, and cell-level data filters on top of IAM; S3 holds the lake data (read-only to the execution role) and the query results (write-only to a separate prefix).
Two arrows are worth calling out now because they define the security model. First, the agent and the execution layer are different trust zones: the agent can propose anything, but only the execution layer can run anything, and it runs only what survives validation. Second, every privileged action flows through the safe execution Lambda's IAM role, which is scoped so tightly that even a perfectly valid-looking malicious query cannot reach data the user is not entitled to. The danger-SQL rejection branch (Section 6) and the per-query flow (Section 9) make these concrete.
Before building this, it is worth knowing that AWS already offers a fully managed version of the front half of this picture. The next section sets that managed baseline as the floor, and explains exactly when you should graduate from it to the architecture above.
3. Managed NL2SQL as the Floor, and When to Own the Execution Path
If your only requirement is "let users ask questions in English and get answers from a warehouse," you may not need to build an agent at all. Amazon Bedrock Knowledge Bases added managed structured-data retrieval — a fully managed natural-language-to-SQL workflow — at re:Invent 2024. You connect a knowledge base to a structured store, and Bedrock analyzes query patterns, query history, and schema metadata to convert a natural-language question into SQL, executes it through the query engine, and returns either the rows or a generated natural-language answer.
The managed path exposes three operations, and the choice between them is the whole point:
RetrieveAndGenerate— generates SQL, runs it, and processes the result through an LLM into a natural-language response. The one-call experience.Retrieve— generates SQL, runs it, and returns the data without LLM post-processing. You format the result yourself.GenerateQuery— returns only the SQL it generated, without executing it. This is the interesting one for safety-conscious teams: it decouples generation from execution, so your own code can review, log, gate, or rewrite the statement before anything touches the data.
The managed query engine is Amazon Redshift, and the supported structured stores are Amazon Redshift (provisioned or serverless) and the AWS Glue Data Catalog (governed by Lake Formation), including Amazon SageMaker Lakehouse. To improve generation accuracy you supply optional query configurations: a maximum query time, free-text descriptions of tables and columns, inclusions/exclusions that limit which tables and columns the generator may reference, and curated queries (natural-language-question / SQL pairs as few-shot examples).
That inclusions/exclusions knob deserves a direct quote, because it is exactly the kind of thing that gets misread as a security control. The Bedrock documentation states plainly that inclusions and exclusions "aren't a substitute for guardrails and is only intended for improving model accuracy." In other words, telling the managed generator "only use these tables" steers it toward better SQL; it does not enforce that the executed query stays within those tables. Enforcement is still the job of IAM and Lake Formation underneath. Keep that distinction; it is the same distinction this entire article is built around.
When the managed floor is enough. Use Bedrock Knowledge Bases structured-data retrieval when your data already lives in Redshift or a Lake Formation-governed catalog, your governance is already expressed as Lake Formation grants, you want the fastest path to a working conversational analytics feature, and you are comfortable with Redshift as the execution engine. It is the right default, and it inherits Lake Formation's fine-grained access control for free.
When to own the execution path. Graduate to the custom architecture in this article when you need things the managed workflow does not give you: execution on Athena over an S3 data lake rather than Redshift; an explicit, auditable validation step you control (your own read-only and allow-list rules, your own LIMIT enforcement, your own logging of every proposed-then-rejected query); a multi-step agent that clarifies ambiguous questions, calls other tools, or composes analytics with non-SQL actions; or a hard per-query scan ceiling enforced at the engine. The rest of this article is that custom path. Think of it the way Agentic RAG Architecture on Amazon Bedrock treats static RAG: the managed feature is the floor you build up from, not a competitor.
For the foundational Bedrock concepts referenced here — Knowledge Bases, embeddings, the Converse API — see the Amazon Bedrock Glossary.
4. Schema Grounding with the Glue Data Catalog
An LLM that has never seen your schema will confidently reference a customers.signup_date column that does not exist, or join orders to users on a column that is not a key. Schema grounding is the practice of giving the agent an accurate, current, scoped description of the data it is allowed to query, so that its generated SQL references only real objects. It is the single highest-leverage accuracy intervention in NL2SQL, and it is also a security boundary: the catalog you expose to the agent defines the universe of tables it can even name.
4.1 Reading the catalog
The AWS Glue Data Catalog is the metastore Athena already uses, so it is the natural grounding source. The relevant read APIs are GetDatabases, GetTables, and GetTable. GetTables returns a TableList, where each table carries its columns under StorageDescriptor.Columns (each column has a Name and a Type), plus partition keys and table-level properties. The call supports an Expression regular-expression filter on table names and is paginated (MaxResults up to 100 per page), so production code uses a paginator.
import boto3
glue = boto3.client("glue")
def load_schema(database: str, allowed_tables: set[str]) -> list[dict]:
"""Return a grounding-ready schema for the allow-listed tables only."""
schema = []
paginator = glue.get_paginator("get_tables")
for page in paginator.paginate(DatabaseName=database):
for table in page["TableList"]:
name = table["Name"]
if name not in allowed_tables:
continue # never describe a table the agent may not query
columns = [
{"name": c["Name"], "type": c["Type"], "comment": c.get("Comment", "")}
for c in table["StorageDescriptor"]["Columns"]
]
partitions = [k["Name"] for k in table.get("PartitionKeys", [])]
schema.append({
"table": name,
"comment": table.get("Description", ""),
"columns": columns,
"partition_keys": partitions,
})
return schemaNote the allow-list filter inside the loop. Grounding scope and execution scope must agree. If you describe a table to the agent that the execution layer will refuse to run against, you are inviting the model to generate queries that are always rejected — a poor experience — and you are leaking the existence and shape of a table the user may not be entitled to know about. The set of tables you ground on should be exactly the set the execution role is permitted to read.
4.2 Turning metadata into grounding context
Raw column names are rarely self-explanatory. amt_usd_net, dt, and st mean something to the team that built the table and nothing to the model. Two mechanisms close that gap:
- Catalog comments. Glue tables and columns carry
Comment/Descriptionfields. Curating them ("dt: partition key, ingestion date inYYYY-MM-DD; always filter on this for recent data") improves generation more than any prompt tweak, and it benefits every consumer of the catalog, not just the agent. - Partition awareness. Surfacing partition keys to the agent and instructing it to filter on them is both an accuracy and a control measure: a query that filters
dt >= date '2026-04-01'scans a fraction of what an unpartitioned scan would. This is the first line of defense against the "accidentally expensive" failure mode; the workgroup scan ceiling in Section 6 is the backstop.
The grounding context handed to the model is then a compact, structured rendering of the allow-listed tables — names, typed columns, comments, partition keys, and a few curated join hints — placed in the system prompt or supplied through a describe_schema tool. Because this context is identical across many turns, it is a good candidate to keep at the front of the prompt for prompt-cache reuse; the Amazon Bedrock Glossary covers prompt caching mechanics.
A subtle but important point: grounding curbs hallucinated columns, but it does not guarantee semantic correctness. The model can reference only-real columns and still write a wrong query — summing gross instead of net, or fanning out a one-to-many join. Grounding raises the floor on validity; it does not certify the answer. Section 9 returns to how you actually evaluate correctness.
5. The Agent: Tool Use and SQL Generation
This is the reasoning core. The design rule that makes everything downstream tractable is a one-sentence separation of powers: the agent proposes SQL; it never executes SQL. The agent's only way to touch data is to call a tool, and that tool is the safe execution layer, which decides what actually runs.
5.1 Hosting on AgentCore Runtime with Strands
We host the agent on Amazon Bedrock AgentCore Runtime, which provides a serverless, framework-agnostic environment for deploying agents built with any framework (Strands Agents, LangGraph, CrewAI, or custom) and any model. Two of its properties matter specifically for a data-querying agent:
- Session isolation. Each user session runs in a dedicated microVM with isolated CPU, memory, and filesystem; after the session ends, the microVM is terminated and its memory sanitized. For an agent that holds schema context, partial results, and a user's identity in working state, this hard per-session boundary is what keeps one tenant's analytics session from contaminating another's.
- Extended execution. Runtime supports both real-time interactions and long-running workloads up to 8 hours, which accommodates the multi-turn clarify-generate-execute-refine loops that real analytical questions require.
The agent itself is a Strands agent whose model is Claude on Bedrock. On Amazon Bedrock you invoke current Claude models through a cross-Region inference profile — for example us.anthropic.claude-opus-4-8 for the strongest reasoning, or us.anthropic.claude-sonnet-4-6 where you want a faster, lighter generation step. SQL generation benefits from the model's reasoning depth (the joins and aggregations in real questions are where text-to-SQL goes wrong), so enabling adaptive thinking on the generation turn is worthwhile; model selection and reasoning controls should be verified against current model availability rather than hard-coded. The foundational Runtime, Memory, and deployment patterns are in Amazon Bedrock AgentCore Implementation Guide Part 1; we do not repeat them.
5.2 Defining the SQL tool with the Converse API
Bedrock's Converse API exposes tool use through a toolConfig containing a toolSpec for each tool. A toolSpec has a name, a required inputSchema (JSON Schema describing the parameters), an optional description, and an optional strict flag that enforces the output schema on the model's tool-use response. The loop is the standard agentic one: you send the conversation plus toolConfig; when the model decides to use a tool it returns a tool-use block; your application executes the corresponding tool, appends the tool result to the message list, and calls Converse again. AWS documents this exact pattern for a custom text-to-SQL agent.
The tool we expose is deliberately narrow. It accepts a generated SQL string and a list of bound parameter values — and nothing that would let the model name a database, a workgroup, an output location, or an IAM role. Those are fixed by the execution layer, not chosen by the model.
TOOLCONFIG = {
"tools": [
{
"toolSpec": {
"name": "run_sql_query",
"description": (
"Execute a single read-only SELECT against the analytics "
"catalog and return the result rows. Reference only tables and "
"columns from the provided schema. Use ? placeholders for every "
"literal value and pass the values in 'parameters' in order. "
"Always include a LIMIT. You cannot create, modify, or delete data."
),
"inputSchema": {
"json": {
"type": "object",
"properties": {
"sql": {
"type": "string",
"description": "A single SELECT statement with ? placeholders for literals.",
},
"parameters": {
"type": "array",
"items": {"type": "string"},
"description": "Values bound to the ? placeholders, in order.",
},
"rationale": {
"type": "string",
"description": "One sentence: what this query answers.",
},
},
"required": ["sql", "parameters", "rationale"],
}
},
"strict": True,
}
}
]
}
Three design choices in that schema are load-bearing. The ?-placeholder convention pushes the model toward parameterized values, which the execution layer will bind as Athena execution parameters (Section 6) — the literal an end user injected becomes data, not SQL syntax. The rationale field gives the audit log a human-readable record of intent next to every executed query. And strict: true makes the tool input conform to the schema, so the execution layer always receives a well-formed {sql, parameters, rationale} object rather than free text it must parse defensively.
5.3 The generation turn and interactive clarification
A good NL2SQL agent does not answer every question immediately; it knows when a question is under-specified and asks. "Show me top customers" is ambiguous — top by revenue or by order count, over what period, how many. The agent should either ask a clarifying question or state its assumption explicitly in the rationale and proceed. This is an ordinary part of the agentic loop (see "agentic loop" and "tool use" in the AI Agent Engineering Glossary); the only NL2SQL-specific guidance is to make the assumption visible to the user, because a confidently wrong default is worse in analytics than in chat — people make decisions on these numbers.
The agent's system prompt does the steering: it carries the grounded schema, instructs the model to write a single read-only SELECT, to reference only listed tables and columns, to parameterize literals, and to always bound results with LIMIT. None of these instructions is a security control. They improve the rate at which the model produces acceptable SQL on the first try, which reduces rejections and round-trips, but the system prompt is derived from text and can be steered by adversarial input. Enforcement happens after generation, in the layer the model cannot talk its way past.
5.4 The managed alternative: Bedrock Agents action groups
If you prefer AWS to orchestrate the loop rather than hosting a Strands agent yourself, Amazon Bedrock Agents is the managed alternative. You define an action group whose backing AWS Lambda function is the safe execution layer, and Bedrock drives the orchestration, prompt construction, and tool invocation. The security model is identical — the action-group Lambda is still the only thing that touches Athena, and it still validates before executing — but you trade the control and portability of AgentCore Runtime + Strands for a managed orchestration loop. The choice does not change anything in Section 6; the safe execution layer is the same component either way. Bedrock Agents and action-group terms are defined in the Amazon Bedrock Glossary.
6. Safe Execution: Read-Only, Allow-Lists, and Least Privilege
This is the heart of the architecture. Everything above produces a proposed query; this layer decides whether it runs, and constrains what it can do if it does. It is a single AWS Lambda function — the only component with permission to call Athena — and it applies a stack of independent controls. The figure shows them as a stack precisely because they are independent: each catches a different class of problem, and you assume any one of them can be bypassed.
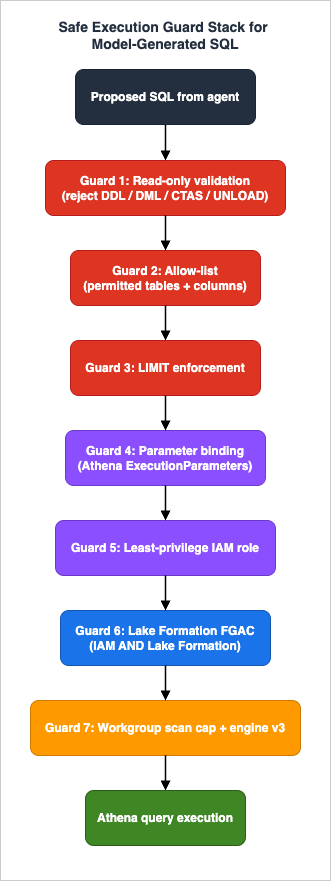
The guards are layered deliberately: cheap, deterministic string-level checks first (so an obviously bad query never reaches the engine), then the platform-level controls that hold even if the string-level checks are imperfect. We walk them in order, but the design principle is that the IAM and Lake Formation layers (Guards 5–6) are the ones you actually trust. The string-level validation (Guards 1–3) is valuable — it gives fast, clear rejections and a clean audit trail — but SQL is a large grammar, and a parser-based allow-list is a filter, not a proof. State that to yourself plainly so you never let "it passed validation" stand in for "it is safe."
6.1 Guard 1–3: Read-only, allow-list, and LIMIT validation
The first three guards are deterministic checks on the proposed statement. Validate, do not sanitize: if a statement does not clearly conform, reject it and return a helpful message to the agent (which can revise), rather than trying to "fix" it.
- Read-only. Parse the statement and require it to be a single
SELECT(orWITH … SELECT). Reject anything else —INSERT,UPDATE,DELETE,CREATE,DROP,ALTER,CREATE TABLE AS SELECT,INSERT INTO,UNLOAD, and any multi-statement input. Use a real SQL parser (for examplesqlglot) and inspect the parsed statement type; do not rely on substring matching fordrop, which both over-blocks (a column literally nameddropoff_time) and under-blocks (obfuscated or comment-split keywords). - Allow-list. From the parsed tree, extract every referenced table and column and confirm each is in the allow-list — the same allow-list used for grounding (Section 4) and, critically, the same set the execution role can read (Guard 5). A reference to anything outside the list is a rejection, not a warning.
- LIMIT. Ensure the statement carries a row
LIMITno greater than a configured ceiling; inject one if absent. This bounds result size and formatting cost, and it is a second-order brake on runaway queries.
import sqlglot
from sqlglot import exp
class SqlRejected(Exception):
pass
def validate_select(sql: str, allowed: dict[str, set[str]], max_limit: int) -> str:
statements = sqlglot.parse(sql, read="athena")
if len(statements) != 1:
raise SqlRejected("Exactly one statement is allowed.")
tree = statements[0]
if not isinstance(tree, exp.Query): # exp.Query covers SELECT, UNION, and WITH ... SELECT
raise SqlRejected("Only read-only SELECT statements are permitted.")
# Reject any DDL/DML node anywhere in the tree.
forbidden = (exp.Insert, exp.Update, exp.Delete, exp.Create, exp.Drop,
exp.Alter, exp.Command)
if any(tree.find(node) for node in forbidden):
raise SqlRejected("Data-modifying or DDL statements are not allowed.")
# Allow-list every referenced table and column.
for table in tree.find_all(exp.Table):
if table.name not in allowed:
raise SqlRejected(f"Table not permitted: {table.name}")
for column in tree.find_all(exp.Column):
tbl = column.table or _single_table(tree)
if tbl and column.name != "*" and column.name not in allowed.get(tbl, set()):
raise SqlRejected(f"Column not permitted: {tbl}.{column.name}")
# Enforce a bounded LIMIT.
limit = tree.args.get("limit")
if limit is None or int(limit.expression.name) > max_limit:
tree = tree.limit(max_limit)
return tree.sql(dialect="athena")
This code is illustrative, not a drop-in. The point is the shape: parse, classify, allow-list, bound — and fail closed. Anything the validator is unsure about is rejected. The honest framing matters here more than anywhere: a parser-based allow-list catches the broad, common, and accidental cases extremely well, and it is genuinely worth having. It is not, and cannot be, a guarantee that no harmful SELECT exists. That is why it is Guard 2 of 7, not the only guard.
6.2 Guard 4: Parameterized values, not string-built SQL
When a question contains a literal an end user controls — a customer name, a date, a status — that literal must be carried as data, never concatenated into SQL text. Athena supports parameterized queries in two forms, and both exist specifically to help prevent SQL injection. The first form is execution parameters: you place ? placeholders in any DML query and supply the values sequentially at execution time; this is a single step and is not workgroup-specific. The second form is prepared statements (PREPARE / EXECUTE … USING / DEALLOCATE PREPARE), which are workgroup-scoped named statements.
For an agent, execution parameters fit best: the model emits SQL with ? placeholders and a separate ordered list of values (exactly what the run_sql_query tool schema enforces), and the execution layer passes those values to Athena's StartQueryExecution as ExecutionParameters.
import boto3, hashlib, json
athena = boto3.client("athena")
def execute(sql: str, parameters: list[str], identity: dict) -> str:
# Idempotency: identical (sql, parameters) under the same identity reuse one execution.
token = hashlib.sha256(
json.dumps([sql, parameters, identity["sub"]], sort_keys=True).encode()
).hexdigest()
resp = athena.start_query_execution(
QueryString=sql, # contains ? placeholders only
ExecutionParameters=parameters, # bound as data, never concatenated
QueryExecutionContext={"Database": ANALYTICS_DB, "Catalog": "AwsDataCatalog"},
WorkGroup=ANALYTICS_WORKGROUP, # carries the scan cap + result location
ClientRequestToken=token, # idempotency (min 32 chars)
ResultReuseConfiguration={
"ResultReuseByAgeConfiguration": {"Enabled": True, "MaxAgeInMinutes": 60}
},
)
return resp["QueryExecutionId"]
Be precise about what this does and does not cover. Execution parameters bind literal values — the WHERE status = ? case. They cannot parameterize identifiers: table names, column names, and schema names are still part of the SQL text. That is exactly why the allow-list (Guard 2) exists and is non-negotiable — identifiers are protected by the allow-list, literals by parameter binding. The two guards cover different halves of the same problem, which is why neither is sufficient alone.
6.3 Guard 5: Least-privilege IAM for the execution role
The safe execution Lambda runs under an IAM role that is the real perimeter. Scope it to exactly the actions and resources the workload needs, and nothing adjacent:
athena:StartQueryExecution,athena:GetQueryExecution,athena:GetQueryResults, andathena:GetQueryRuntimeStatistics, restricted to the single analytics workgroup.glue:GetTable/glue:GetTables/glue:GetDatabaseon the allow-listed databases and tables only — so even catalog reads are scoped.s3:GetObject/s3:ListBucketon the data prefixes the queries read, ands3:PutObject/s3:GetObjecton the separate results prefix Athena writes to. No write permission to the data location. Nos3:DeleteObjectanywhere it is not required.- KMS decrypt/encrypt on the specific keys protecting the data and results, if SSE-KMS is in use.
The role conspicuously lacks glue:CreateTable, glue:UpdateTable, glue:DeleteTable, athena:* wildcards, and any write to the data lake. Even if a malformed-but-valid SELECT slips past Guards 1–4, IAM ensures it can only read data the role is entitled to and write only to the results prefix. This is the layer that turns a logic bug into a contained read instead of a breach. Least-privilege IAM is the cross-cutting theme of the whole series; the AI Agent Engineering Glossary anchors the agent-side terminology.
6.4 Guard 6: Lake Formation fine-grained access control
IAM scopes which tables and S3 prefixes the role can touch. AWS Lake Formation narrows that further to which columns, rows, and cells within a table a principal may see, using data filters that provide column-level, row-level, and cell-level security. Two facts make Lake Formation the right place to enforce data boundaries rather than trying to do it in generated SQL:
- IAM and Lake Formation are complementary; a request must pass both. Lake Formation permissions combine with IAM permissions — for a query to succeed it must clear IAM and Lake Formation checks. Lake Formation does not loosen IAM; it only further restricts. This is why a row filter ("analysts in region EU see only EU rows") enforced in Lake Formation cannot be bypassed by a cleverly generated query: the engine applies the filter regardless of what the SQL says.
- It requires Athena engine version 3. Fine-grained access control on Athena queries against data registered with Lake Formation requires engine v3, which is why the workgroup (Guard 7) pins that engine. Supported table formats include Apache Iceberg, Apache Hudi, and Apache Hive.
The practical consequence is a clean division of labor. Tenant and confidentiality boundaries belong in Lake Formation, expressed as row and column filters tied to the querying principal, not in prompt instructions or in the validator. The agent never needs to know a tenant boundary exists; it generates an ordinary query, and Lake Formation returns only the rows and columns that principal is entitled to. That is far more robust than asking a language model to remember to add WHERE tenant_id = ? every time — and it means a forgotten predicate is a non-event rather than a cross-tenant leak.
6.5 Guard 7: The workgroup as a control plane
The final guard is the Athena workgroup, which is where engine-level controls live. Create a dedicated workgroup for the NL2SQL feature and configure it so the controls cannot be overridden per query:
BytesScannedCutoffPerQuerysets an upper limit on the bytes a single query may scan; a query that would exceed it is cancelled by Athena. This is the hard backstop for the "accidentally expensive / large scan" failure mode — the one a generated query is most likely to trigger by omitting a partition predicate. We discuss it in terms of scan volume and control, not billing; the dollar figures live on the official AWS Pricing page.EnforceWorkGroupConfigurationmakes the workgroup's settings authoritative, so a client cannot supply its own output location or disable the scan cap. Combined with a least-privilege role restricted to this one workgroup, the execution layer literally cannot run a query outside these constraints.- A fixed, encrypted results location. The workgroup pins the S3 output location and its encryption (
SSE_S3,SSE_KMS, orCSE_KMS), so results land in one known, encrypted, access-controlled place. - Engine version 3, as required by Lake Formation fine-grained access control (Guard 6).
The workgroup is what makes the other guards enforceable rather than advisory. A scan cap a client can turn off is not a cap; EnforceWorkGroupConfiguration is what turns the configuration into policy.
6.6 The danger-SQL rejection branch, and an honest summary
Putting Guards 1–7 together, the per-query flow has two terminal branches. A query that is read-only, allow-listed, bounded, parameterized, within the role's IAM scope, within the principal's Lake Formation filters, and under the scan cap runs, and its results are filtered by Lake Formation to exactly what the user may see. A query that fails any guard is rejected: the string-level guards reject before Athena is ever called (returning a clear reason the agent can act on), and the platform guards reject at the engine (IAM denial, Lake Formation filter, or scan-cap cancellation), which the execution layer surfaces as a controlled error. Section 9's flow figure shows this branch end to end.
The honest summary: this stack makes the common, accidental, and broad-class dangerous queries fail safely, and it ensures that anything which does execute is confined by IAM and Lake Formation to data the user is entitled to. It is a strong, layered posture. It is not a proof that no harmful read is possible, and you should not describe it as one to your stakeholders. The correct claim is "model-generated SQL executes only read-only, only against allow-listed data, only within the user's data-access boundary, with a hard scan ceiling, and every query is logged" — which is true, useful, and defensible. For the deeper safety topics this article only touches — prompt-injection patterns, content filtering depth — see the responsible-AI cluster, including Responsible-AI Guardrails Architecture on AWS.
7. Results, Formatting, and Visualization
Once a query has run, the execution layer reads the results from Athena (GetQueryResults, or by reading the result file from the workgroup's S3 location for large outputs) and shapes them into a compact structure the agent can reason over — typically the column names, types, a capped number of rows, and the row count. That structure becomes the tool result appended to the Converse message list, and the agent's next turn produces a grounded natural-language summary: "EU revenue was X across Y orders, up Z% from the prior period," with the summary derived from the returned rows rather than from the model's parametric memory.
This grounding step is the analytics analogue of citation in RAG: the answer must be traceable to the data that was actually returned. Two practices keep it honest:
- Summarize only what was returned. Instruct the agent to base every number in its answer on the tool result, and to say so when the result is empty or truncated, rather than filling gaps. An empty result set is a valid, important answer ("no orders matched"), not a prompt to invent one.
- Return the query and the row count alongside the prose. Surfacing the executed SQL (and its
rationale) lets a user verify the question was interpreted as intended — the single most effective trust-building feature in a generative BI product.
7.1 Idempotency and a boundary-safe cache
Two StartQueryExecution parameters from Section 6 double as performance and safety features. ClientRequestToken makes execution idempotent: a retried tool call with identical SQL and parameters returns the same QueryExecutionId rather than launching a duplicate scan — important in an agentic loop where retries happen. ResultReuseConfiguration enables query result reuse: if an identical query ran within MaxAgeInMinutes, Athena serves the cached result instead of rescanning, reducing scan volume for repeated questions.
Result reuse is safe here precisely because of the Lake Formation boundary. Reuse keys on the exact query text and parameters, and the data boundary is enforced per principal at execution time, so two different users issuing the "same" question still run under their own Lake Formation filters — you are not caching one tenant's filtered rows and serving them to another. Keep result-reuse windows modest for freshness, and never use reuse as a substitute for the per-principal filtering that makes it safe.
7.2 Visualization
For charts and dashboards, the natural AWS surface is Amazon QuickSight, and its generative-BI capability (Amazon Q in QuickSight) can take natural-language questions directly against curated datasets. A common division of labor is to let the conversational agent answer ad-hoc analytical questions over the governed catalog, and to hand recurring, visual, shareable reporting to QuickSight. The execution layer's structured result is also a clean input to a charting step if you render inside your own application. Visualization specifics are out of scope for this implementation walkthrough; the architectural point is that the safe execution layer produces governed, structured results that any presentation layer can consume.
8. Cross-Cutting: Guardrails, Auditing, and Data Boundaries
Three concerns cut across every component: content safety, auditability, and data isolation. They are what make the difference between a demo and something you can put in front of regulated users.
8.1 Guardrails at the edges
Amazon Bedrock Guardrails provides content-safety controls that you apply independently of model invocation through the ApplyGuardrail API. The call takes a guardrailIdentifier, a guardrailVersion, a source of INPUT or OUTPUT, the content to assess, and an outputScope of INTERVENTIONS or FULL; it returns the assessment without invoking any model. Because it is decoupled, you apply it at both edges of the architecture: on the input to screen the user's question (denied topics, prompt-attack signals, sensitive-information patterns) before the agent reasons over it, and on the output to screen the generated summary before it reaches the user. Guardrails works with agent frameworks including Strands Agents, including agents deployed on AgentCore — so the same guardrail policy applies whether you host the agent yourself or use Bedrock Agents.
Guardrails is one independent layer among several, not the whole safety story, and this article only touches it. The depth — denied-topic design, contextual grounding checks, PII handling, and how Guardrails composes with WAF and Comprehend in a multi-layer content-safety pipeline — is the subject of Responsible-AI Guardrails Architecture on AWS, and the prompt-injection specifics it deliberately omits live in the existing WAF and defense-in-depth articles referenced there.
8.2 Auditing: who asked what, and what ran
A generative BI system must be able to answer, after the fact, "who asked this question, what SQL did the model generate, what did it scan, and what came back." The components for that audit trail already exist:
- The agent layer logs each user question, the model's generated SQL, its
rationale, and whether the query was accepted or rejected (and why). This is the record that ties a natural-language request to a concrete statement. - Athena query history records every executed
QueryExecutionId, its SQL, status, and — viaGetQueryRuntimeStatistics— the bytes scanned and timing. - AWS CloudTrail records the
StartQueryExecutionAPI calls and the IAM principal that made them. - Amazon CloudWatch holds the Lambda logs and custom metrics (acceptance rate, rejection reasons, scan volume per query).
Together these let you reconstruct any interaction and detect patterns — a spike in rejections, an unusual scan volume, a user probing for tables outside their allow-list. Audit is also where the "passing the allow-list ≠ safe" principle pays off operationally: because every proposed query is logged, not just every executed one, you can see what the model attempted and rejected, which is exactly the signal you want for monitoring and for improving grounding.
8.3 Data boundaries and multi-tenancy
For multi-tenant or confidential workloads, the data boundary must be structural, not advisory. As Section 6.4 argued, Lake Formation is the right enforcement point: express tenant isolation and confidentiality as row, column, and cell filters bound to the querying principal, so the engine returns only entitled data regardless of the generated SQL. The agent's own identity and the end user's identity should be distinct — AgentCore Identity assigns identities to agents and integrates with your IdP — so that the execution layer can assume a per-user or per-tenant role (or pass the user identity through to Lake Formation) and the data boundary follows the user, not the agent. The result is that the same agent, the same code, and the same catalog serve every tenant, while each tenant sees only its own data because the boundary lives in the platform, below the SQL. This mirrors the isolation patterns in the multi-tenant SaaS article in this series; the cross-cutting rule is the same one repeated throughout: enforce boundaries in the platform, never in the prompt.
9. Observability, Evaluation, and Failure Modes
A Level 400 system is defined as much by how it fails as by how it works. NL2SQL has a characteristic set of failure modes that cross component boundaries, and each has a recognizable symptom, a root cause in a specific component, an isolation step, and a remediation. The end-to-end flow figure traces a single query through the architecture, including the rejection branch, so you can locate where each failure occurs.
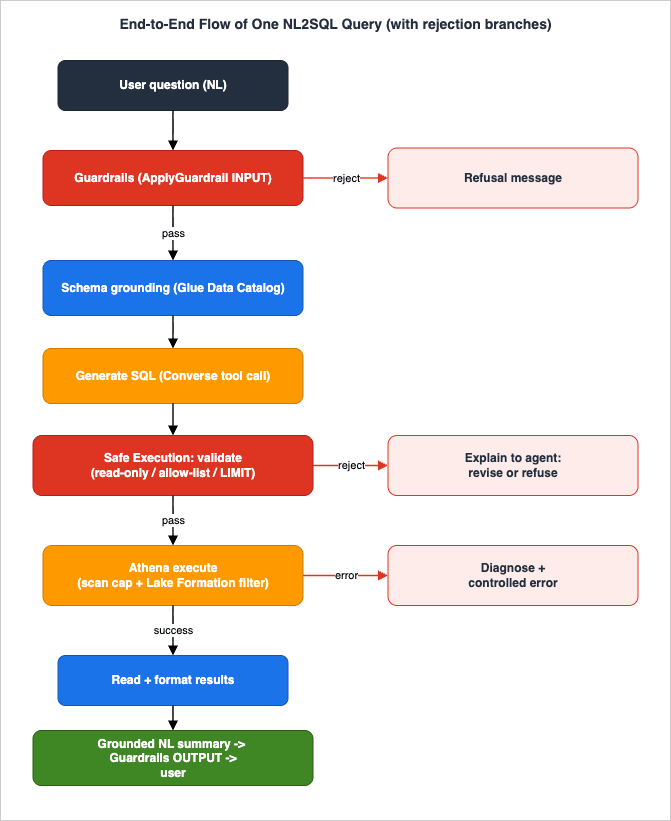
9.1 Failure-mode table
| Symptom | Likely root cause | Where to look | Isolation step | Remediation |
|---|---|---|---|---|
| Answer references a column that does not exist; query errors with "column not found" | Hallucinated schema; grounding stale or incomplete | Agent grounding context vs. live Glue catalog | Diff the grounded schema against GetTables; check StorageDescriptor.Columns | Refresh grounding from Glue; add column comments; tighten the allow-list so only described columns are referenceable |
| Query rejected by the validator that a human would consider fine | Allow-list too narrow, or parser over-blocking a benign construct | Safe execution Lambda logs; the rejection reason | Re-run validation locally on the generated SQL; inspect the parsed tree | Extend the allow-list deliberately; fix the parser rule; never widen by disabling read-only checks |
| Query is cancelled mid-run | Scan-cap exceeded — a large / unpartitioned scan | Athena query status CANCELLED; GetQueryRuntimeStatistics bytes scanned | Check whether the query filtered on a partition key | Strengthen partition-awareness in grounding; keep the scan cap; consider narrowing the question with the user |
| "Access denied" with valid-looking SQL | IAM scope vs. Lake Formation filter — the two are distinct | CloudTrail for the StartQueryExecution principal; Lake Formation grants for that principal | Determine which check failed: IAM (resource/action) or Lake Formation (table/column/row) | Adjust the correct layer — never relax both reflexively; usually the principal lacks a Lake Formation grant, which may be intentional |
| Empty result set surprises the user | Correct query, no matching rows, or a Lake Formation row filter removed them | Athena result row count; Lake Formation row filters for the principal | Re-run as an entitled principal in a test context to see if rows exist behind the filter | If the filter is correct, this is working as designed — have the agent state "no rows matched" plainly |
| Query times out | Genuinely heavy query, or engine contention | Athena status; runtime statistics; workgroup engine version | Compare scanned bytes and stages to a known-good query | Add partition predicates via grounding; bound result size with LIMIT; revisit the data layout (partitioning / format) |
| Agent loops, re-proposing rejected queries | Rejection reasons not fed back usefully, or under-specified question | Agent transcript; tool-result messages | Confirm the validator returns an actionable reason the model can act on; check for ambiguity | Return precise rejection messages; have the agent ask a clarifying question; cap retries (a latency budget) |
9.2 The metrics that matter
Instrument the cross-component metrics, not just per-service ones: query acceptance vs. rejection rate (and rejection-reason distribution), bytes scanned per query (from GetQueryRuntimeStatistics), end-to-end latency split across grounding / generation / execution / formatting, clarification rate, and result-reuse hit rate. AgentCore Observability and Bedrock model invocation logging give the agent-side traces; CloudWatch and Athena query history give the execution-side numbers. A rising rejection rate usually means grounding has drifted from the catalog; a rising scan volume usually means partition predicates are being dropped — both are detectable before they become incidents.
9.3 Evaluating SQL correctness
The hardest question — "is the generated SQL correct, not merely valid and safe?" — is an evaluation problem, not an execution one. Validity (does it parse, does it reference real columns) and safety (does it stay read-only and in bounds) are enforced by the architecture above. Correctness (does it answer the question the user actually asked, with the right joins and aggregations) requires evaluation: a curated set of natural-language questions with known-good SQL or known-good answers, execution-match or result-match scoring, and LLM-as-judge for the natural-language summary. Building that evaluation harness — and wiring it into a regression gate so a prompt or grounding change cannot silently degrade accuracy — is the subject of LLMOps Observability and Evaluation Architecture on AWS, and this NL2SQL system is a natural consumer of it.
10. Variations: Redshift, Lakehouse, and BI Tools
The architecture's spine — agent proposes, execution layer validates, platform enforces — is engine-agnostic. A few substitutions are worth knowing:
- Amazon Redshift instead of Athena. If your data lives in a Redshift warehouse, the safe execution layer submits to Redshift (via the Redshift Data API) instead of Athena. The guard stack is the same — read-only validation, allow-list, parameter binding, least-privilege role, Lake Formation where applicable. Note that Redshift is also the engine behind the managed Bedrock Knowledge Bases path (Section 3), so on Redshift the build-vs-buy decision is sharpest: you may get most of this for free from the managed feature unless you specifically need your own validation and orchestration.
- SageMaker Lakehouse and open table formats. A lakehouse over Iceberg or Hudi tables, governed by Lake Formation in the Glue Data Catalog, slots in directly — Athena engine v3 supports fine-grained access control on Iceberg, Hudi, and Hive formats, so the Lake Formation boundary (Guard 6) holds across them.
- BI tools as the front end. For visual, shareable, recurring reporting, Amazon QuickSight with Amazon Q (generative BI) is the managed surface, taking natural-language questions against curated datasets. The pattern that scales is to let the conversational agent own ad-hoc, multi-step analytical questions over the governed catalog, and let QuickSight own dashboards and self-serve visualization — with both reading from the same Lake Formation-governed data so the boundary is consistent across surfaces.
The constant across all variations is that the data boundary lives in the platform (IAM + Lake Formation), the execution is owned by a least-privilege layer, and the model only ever proposes. Change the engine and the BI front end freely; do not move the trust boundary into the model.
11. Frequently Asked Questions
Is it ever safe to let the model execute SQL directly?
No — not against data you care about. The separation of "the model proposes, a least-privilege layer executes" is the core control. Even with a strong model, direct execution gives a non-deterministic component an execution capability and an IAM identity, which is exactly what you do not want on the data path. The cost of the indirection is small; the risk reduction is large.
Why both an allow-list and parameterized queries — isn't one enough?
They protect different things. Parameter binding (Athena execution parameters) protects literal values so an injected string is treated as data. The allow-list protects identifiers — table, column, and schema names — which parameter binding cannot cover, because identifiers are part of the SQL text. You need both, plus the IAM and Lake Formation layers beneath them.
Does passing the validator mean the query is safe?
No, and this is the most important caveat in the article. The validator catches the broad, common, and accidental dangerous cases and gives fast, clear rejections — it is genuinely valuable. But SQL is a large grammar and a parser-based allow-list is a filter, not a proof. Real safety comes from the layers the model cannot influence: least-privilege IAM and Lake Formation fine-grained access control. Treat validation as one layer of seven, not as a guarantee.
Should I build this or use Bedrock Knowledge Bases structured-data retrieval?
Start with the managed feature if your data is in Redshift or a Lake Formation-governed catalog and you do not need a custom execution path — it is the floor, and it inherits Lake Formation's access control. Build the custom architecture when you need Athena over a data lake, your own auditable validation step, a multi-step agent, or a hard engine-level scan ceiling. Section 3 has the full decision.
How do I stop a generated query from scanning the entire lake?
Two layers. Surface partition keys in grounding and instruct the agent to filter on them (the accuracy-side measure), and set BytesScannedCutoffPerQuery on a workgroup with EnforceWorkGroupConfiguration so Athena cancels any query that exceeds the ceiling regardless of what the SQL says (the enforcement-side backstop). The first reduces scans; the second caps them.
Where do tenant boundaries belong?
In Lake Formation, as row / column / cell filters bound to the querying principal — never in the prompt and never in the validator. Because IAM and Lake Formation must both pass, a forgotten WHERE tenant_id = ? becomes a non-event rather than a cross-tenant leak: the engine applies the filter regardless of the generated SQL.
12. Summary
The signature of a production NL2SQL system is not a clever prompt that writes good SQL; it is a safe execution architecture that lets model-generated SQL run only read-only, only against allow-listed data, only within the user's data-access boundary, with a hard scan ceiling, and with every query logged. This article assembled that as one named reference architecture: a Strands agent on AgentCore Runtime that grounds itself in the Glue Data Catalog and proposes SQL through a Converse tool call; a safe execution Lambda that validates (read-only, allow-list, bounded), binds literals as Athena execution parameters, and submits under a least-privilege role; an Athena workgroup that enforces a per-query scan cap and engine v3; and Lake Formation fine-grained access control plus IAM as the data boundary the model cannot cross. Guardrails sit at both edges, and CloudTrail, Athena query history, and CloudWatch make every interaction auditable.
The two ideas worth carrying away are the separation of powers — the model proposes, a least-privilege layer executes, the platform enforces — and the honesty discipline that passing a validator is one layer of defense, not a proof of safety. Build up from the managed floor (Bedrock Knowledge Bases structured-data retrieval) when you need control the managed path does not give you; delegate the deep dives on Guardrails and evaluation to the responsible-AI and LLMOps articles in this series; and keep the trust boundary in the platform, never in the prompt.
13. References
- Amazon Bedrock AgentCore — What is Amazon Bedrock AgentCore
- Amazon Bedrock AgentCore — Host agent or tools with AgentCore Runtime
- Amazon Bedrock Knowledge Bases — Turning data into a knowledge base (structured data)
- Amazon Bedrock Knowledge Bases — Build a knowledge base by connecting to a structured data store
- Amazon Bedrock Knowledge Bases — Generate a query for structured data (GenerateQuery)
- Amazon Bedrock Knowledge Bases — Create a knowledge base by connecting to a structured data store
- Building a custom text-to-SQL agent using Amazon Bedrock and Converse API (AWS Machine Learning Blog)
- Amazon Bedrock — ApplyGuardrail API reference
- Amazon Bedrock Guardrails (ApplyGuardrail, independent application)
- Amazon Athena — Use parameterized queries
- Amazon Athena — Workgroup data usage controls (BytesScannedCutoffPerQuery)
- Amazon Athena — Use Athena to query data registered with AWS Lake Formation
- AWS Lake Formation — Data filtering and cell-level security
- AWS Glue — Table API (GetTables, StorageDescriptor.Columns)
- Amazon Athena — Pricing (for scan-cost figures, not covered here)
Related Articles on This Site
- Amazon Bedrock AgentCore Implementation Guide Part 1: Runtime, Memory, and Code Interpreter Patterns
The AgentCore Runtime foundations this architecture hosts the agent on. - AI Agent Engineering Glossary - Memory, Tools, Orchestration, and Protocols Explained
Agent-side terminology: the agentic loop, tool use, and MCP. - Amazon Bedrock Glossary - A Reference for AI Engineers and Architects
Bedrock service terms: the Converse API, Knowledge Bases, Guardrails, and Bedrock Agents.
References:
Tech Blog with curated related content