AWS Multi-Region Active-Active Architecture Guide - Global Data Replication, Routing, and Failover with Route 53, DynamoDB Global Tables, and Aurora Global Database
First Published:
Last Updated:
This article is the implementation companion to my AWS Disaster Recovery Strategies Guide. That guide is where you choose a strategy: it compares Backup and Restore, Pilot Light, Warm Standby, and Multi-Site Active-Active against RTO and RPO targets. This article assumes you have already made that choice and want to build the most demanding one — a multi-Region active-active topology — at the level of concrete services, data-replication semantics, routing behavior, and failover mechanics. I will not re-derive the four-strategy decision here; I link back to it where the trade-off matters and keep the focus on the active-active implementation.
The reference architecture is deliberately named and concrete: two Regions running an identical application stack, fronted by a global routing tier (Amazon Route 53 or AWS Global Accelerator), backed by a global data tier (Amazon DynamoDB global tables, Amazon Aurora Global Database, and Amazon S3 Cross-Region Replication). Everything in this article walks one request, one item, and one Region failure through that architecture.
Throughout, I keep to a policy of not quoting prices. Multi-Region is the topology most likely to double your spend, and the temptation to "just compare the cost" is exactly why I instead describe the operational and data-volume characteristics and point to the official AWS pricing pages. The numbers that do appear — replica counts, consistency semantics, recovery characteristics — were verified against AWS documentation while writing (see References).
1. Introduction: What "Going Multi-Region" Actually Means
When teams say "let's go multi-Region," they usually mean one of three very different things, and conflating them is the first mistake:- Multi-Region disaster recovery (active-passive). A standby Region exists but normally serves no production traffic. You fail over to it during a disaster. This is Pilot Light or Warm Standby, covered in the DR guide.
- Multi-Region for data residency or latency. Different users are served from different Regions for compliance or proximity, but a given user's data lives in one Region. This is "multi-Region" but not necessarily "active-active" for any single record.
- Multi-Region active-active. Two or more Regions concurrently accept reads and writes for the same logical dataset. Both Regions are "hot." This is the hardest case because the same entity can be written in two places at once.
This article is about the third case, with honest treatment of where it shades into the second. Active-active is not a badge of seniority to be pursued for its own sake — it is justified when you need a Region to absorb the full load with a near-zero recovery time and you can either tolerate eventual consistency or pay the latency cost of synchronous cross-Region replication. For many workloads, an active-passive Warm Standby is the more honest answer, and Section 10 returns to that.
The technical spine of any active-active design is three questions, asked once per data store:
- Replication — how does a write in Region A become visible in Region B, how long does it take, and what is the data-loss window (RPO) if Region A disappears mid-write?
- Routing — how does a client reach a healthy Region, and how fast does traffic shift when a Region degrades?
- Conflict — if the same entity is written in both Regions, what happens, and how do I design so that it rarely or never happens?
The rest of the article answers these three questions for each tier of the reference architecture.
2. The Reference Architecture at a Glance
The architecture is two symmetric stacks — one in a primary Region (hereus-east-1) and one in a secondary Region (here us-west-2) — joined by a global routing tier on top and a global data tier underneath.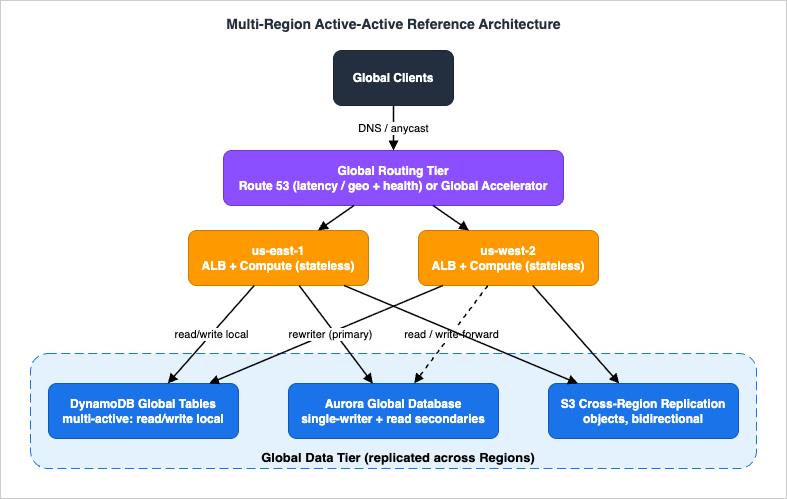
- Global routing tier. Either Amazon Route 53 (DNS-based, using latency or geoproximity routing plus health-check failover) or AWS Global Accelerator (anycast IP based, using the AWS global network and fast health-based failover). Section 3 explains when to reach for each. The deep routing-policy mechanics are delegated to my Amazon Route 53 DNS Architecture Guide.
- Regional application tier. An identical stack in each Region — an Application Load Balancer or API Gateway in front of compute (ECS/Fargate, EKS, EC2, or Lambda). This tier is stateless by design so it can run hot in both Regions; all state is pushed down to the global data tier.
- Global data tier. Three replication mechanisms, one per data shape:
- Amazon DynamoDB global tables for key-value and document state that needs multi-active writes (both Regions write directly to their local replica).
- Amazon Aurora Global Database for relational state, which is single-writer: one Region holds the writer, secondaries are read-only and (optionally) forward writes to the primary.
- Amazon S3 Cross-Region Replication (CRR) for objects and static assets.
The single most important architectural distinction in this whole picture is that DynamoDB global tables are multi-active and Aurora Global Database is single-writer. That one fact drives almost every downstream design decision about write routing, idempotency, and failover, and it is the reason a "fully active-active" system is usually active-active for its DynamoDB-backed services and active-active-reads / single-writer for its relational services. We keep returning to it.
A note on the word "active-active." A topology can be active-active at the routing tier (both Regions take traffic) while being single-writer at one of its data tiers (Aurora). That is not a contradiction — it is the normal, correct shape. The routing tier and each data tier each have their own answer to "where can writes land."
2.1 The Steady-State Request Path
Before any Region fails, it helps to trace one request through the healthy architecture, because that path is exactly what failover has to preserve. Consider a user whose home Region isus-east-1 (Section 7 explains how that home is assigned):- Resolve. The client resolves the application name. Route 53 latency routing (or Global Accelerator's anycast IPs) sends the user to the nearest healthy Region — say
us-east-1. - Read locally. The regional application tier serves reads from its local replicas: the local DynamoDB global table replica and the local Aurora reader. No cross-Region hop is on the read path, which is the whole point of running hot in both Regions.
- Write per store. A write to a DynamoDB-backed service lands on the local replica and propagates outward (MREC, typically within a second). A write to an Aurora-backed service goes to the Aurora primary — directly if
us-east-1holds the writer, or via write forwarding if the user is being served from a secondary Region. An object upload writes the local S3 bucket and replicates by CRR. - Propagate. Within seconds the other Region's replicas converge, so a user served from
us-west-2sees the same data.
The two facts that make this safe are that reads are always local and writes for a given entity always have one authoritative destination (the local DynamoDB replica, the Aurora primary, or the key's home S3 bucket). Failover (Section 8) is the act of changing which Region is "local" and which holds the Aurora primary — nothing about the steady-state path's shape changes, only its target Region.
2.2 Cross-Region Encryption and Least-Privilege IAM
Two cross-cutting concerns are easy to defer and painful to retrofit: how encrypted data crosses Regions, and how each tier's IAM stays least-privilege when resources span Regions.Encryption. Each data store is encrypted at rest with an AWS KMS key in its own Region — each DynamoDB replica, each Aurora cluster, and each S3 bucket uses a key local to that Region, and the managed replication paths handle re-encryption as data moves. For application-level (envelope) encryption where the same ciphertext must be readable in either Region, use AWS KMS multi-Region keys: a primary key and its replicas (created with
ReplicateKey) share the same key ID and key material, so data encrypted in one Region can be decrypted in another without a cross-Region call. One sharp edge to know: Amazon S3 treats multi-Region KMS keys as single-Region keys for replication, so SSE-KMS object replication still requires you to designate a destination KMS key in the destination Region (and grant the replication role kms:Decrypt on the source key and kms:Encrypt on the destination key).Least-privilege IAM. Keep each Region's compute on a Region-scoped role that can reach only that Region's resources wherever possible — cross-Region access should be the deliberate exception (the S3 replication role, the Aurora write-forwarding path), not a broad grant. The S3 replication IAM role is the canonical example: it needs source-side read permissions (such as
s3:GetObjectVersionForReplication) and destination-side s3:ReplicateObject, plus the KMS permissions above. Scoping these per bucket and per key, rather than wildcarding across Regions, is what keeps a compromised role in one Region from reaching the other.3. Global Traffic Routing
The routing tier decides which Region a client reaches and how quickly traffic moves away from an unhealthy Region. AWS gives you two fundamentally different tools, and the choice has real consequences for failover speed. The exhaustive routing-policy treatment lives in my Amazon Route 53 DNS Architecture Guide and the failure-mode treatment in Route 53 Health Check and Failover Pitfalls; here I focus on the active-active routing decision.3.1 Amazon Route 53 (DNS-based routing)
Route 53 routes by answering DNS queries. For active-active you typically combine a latency-based or geoproximity routing policy (send each client to the Region that serves it best) with health checks so that an unhealthy Region's records are withdrawn from responses.Route 53 distinguishes two failover shapes:
- Active-active failover, where all resources serve traffic simultaneously and Route 53 simply stops returning records for endpoints that fail their health checks. This uses any routing policy except failover (latency, geoproximity, weighted, multivalue).
- Active-passive failover, where the
Failoverrouting policy sends traffic to a primary and only shifts to a standby when all primaries are unhealthy.
The critical behavior to understand for active-active is that DNS failover is bounded by DNS, not by Route 53. Route 53 stops returning an unhealthy record quickly, but clients and intermediate resolvers cache answers for the record's TTL. A 60-second TTL means some clients keep hitting the dead Region for up to a minute after Route 53 has already moved on. You trade lower TTL (faster failover) against higher query volume. This is delegated in depth to the pitfalls article, but the headline is: with Route 53, your effective failover time includes the TTL.
There is also a deliberate safety behavior: Route 53 fails open. If every record in a record set appears unhealthy — which usually means your health checks are misconfigured or your whole application is overloaded rather than one Region being down — Route 53 reverts to treating all records as healthy and keeps answering, rather than returning nothing. It is better to send traffic to a possibly-degraded endpoint than to black-hole every user. Design your health checks knowing that "all unhealthy" means "fail open," not "fail closed."
3.2 AWS Global Accelerator (anycast-based routing)
Global Accelerator gives you two static anycast IP addresses fronting the AWS global network. Clients always connect to the same IPs; Global Accelerator decides at the network edge which Regional endpoint to route to. Because the decision is made on every connection (not cached by DNS), failover does not wait for a TTL.The building blocks:
- A listener (port/protocol).
- An endpoint group per Region, each containing endpoints (ALBs, NLBs, EC2 instances, or Elastic IPs).
- A traffic dial per endpoint group (0–100%) that caps the percentage of otherwise-routed traffic the group accepts — useful for gradual shifts and for pinning a percentage to each Region.
- Endpoint weights within a group.
Health checks are run by Route 53 health checkers. For ALB/NLB endpoints, health is taken from the load balancer's own Elastic Load Balancing health checks; for EC2/EIP endpoints you configure the health-check port and must allow the Route 53 health-checker IP ranges through your security groups.
The failover behavior is precise and worth memorizing: when all endpoints in a group are unhealthy or have zero weight, Global Accelerator fails over to a healthy endpoint in another endpoint group, ignoring traffic-dial settings during failover. If it cannot find a healthy endpoint after checking the three closest endpoint groups, it fails open by routing to a random endpoint in the nearest group. When healthy endpoints recover, normal routing resumes within about 30 seconds, though existing active connections stay on their current endpoint until they reset.
3.3 Choosing between them for active-active
* You can sort the table by clicking on the column name.| Concern | Route 53 | AWS Global Accelerator |
|---|---|---|
| Routing mechanism | DNS answers | Anycast IPs on AWS global network |
| Failover speed | Bounded by record TTL + client caching | Seconds; no DNS caching in the path |
| Granularity | Per-record (latency/geo/weighted) | Per-endpoint-group traffic dial + weights |
| Static IPs | No (DNS names) | Yes (two anycast IPs) |
| Fail-open behavior | Yes (all-unhealthy → all-healthy) | Yes (after 3 closest groups → random nearest) |
| Health-check source | Route 53 health checkers | Route 53 health checkers (or ELB for LB endpoints) |
For latency-sensitive active-active where you need failover measured in seconds and clients that cannot be trusted to honor low DNS TTLs, Global Accelerator is the stronger default. Where you need rich DNS-level routing (weighted canaries, geolocation for residency, alias records to many AWS resource types) and can tolerate TTL-bounded failover, Route 53 is the natural fit. Many production designs use both: Route 53 for the apex/alias and friendly names, Global Accelerator for the fast-failover data path. The deeper trade-off, including private hosted zones and the control-plane caveat (Section 8), is in the routing guide.
4. Replicating the Database Tier: DynamoDB Global Tables
DynamoDB global tables are the multi-active heart of an active-active design: each Region has a full replica, you read and write your local replica, and DynamoDB propagates writes to the other replicas. There is no "primary" replica — this is genuinely multi-active. The single-table modeling details are delegated to my Amazon DynamoDB Capacity and Global Tables Guide; here I focus on the replication and consistency semantics that matter for active-active correctness.4.1 Versions and what "current" means
There are two versions of global tables: Version 2019.11.21 (Current) and Version 2017.11.29 (Legacy). Use the current version. The legacy version stamps every item withaws:rep:* system attributes and is harder to reason about; AWS recommends against it for new work. Everything below describes the current version.A global table offers a 99.999% availability SLA, compared to 99.99% for a single-Region table — the extra nine is the whole point of replicating across Regions.
4.2 The two consistency modes (choose at creation, cannot change)
This is the part that has evolved and is easy to get wrong from memory. A global table is created in one of two consistency modes, and you cannot change the mode after creation; all replicas share the same mode.Multi-Region eventual consistency (MREC) — the default. Writes to one replica are replicated asynchronously to the others, typically within a second. If the same item is modified in two Regions at nearly the same time, DynamoDB resolves the conflict with last-writer-wins, using the modification with the latest internal timestamp, on a per-item basis. The item eventually converges everywhere to the last write. A subtle and important caveat: a strongly consistent read against an MREC replica returns the latest version only if the item was last updated in the Region where you are reading; if it was last updated in another Region, you may still read stale data until replication catches up. The RPO of MREC equals the replication lag — usually a few seconds — so a Region loss mid-replication can lose the not-yet-replicated writes. An MREC table can have a replica in any Region where DynamoDB is available, and as many replicas as there are Regions in the AWS partition.
Multi-Region strong consistency (MRSC) — opt-in. Writes are replicated synchronously to at least one other Region before the write returns success, so a strongly consistent read on any replica always returns the latest version and the RPO is zero. This power comes with hard constraints that shape your topology:
- An MRSC global table must be deployed in exactly three Regions — either three replicas, or two replicas plus a witness (a DynamoDB-managed component that stores the data needed for the consistency quorum but that you cannot read from or write to, and that does not appear in your account).
- MRSC is only available within fixed Region sets: a US set (N. Virginia, Ohio, Oregon), an EU set (Ireland, London, Paris, Frankfurt), and an AP set (Tokyo, Seoul, Osaka). An MRSC table cannot span Region sets.
- You can only convert an empty single-Region table to MRSC; you cannot add or remove a single replica afterward.
- Concurrent conflicting writes fail with
ReplicatedWriteConflictException(retryable) rather than silently resolving by last-writer-wins. - TTL and Local Secondary Indexes are not supported in MRSC.
The choice is a latency-versus-consistency trade-off. MREC gives lower write and strongly-consistent-read latency and tolerates an RPO greater than zero. MRSC gives global strong consistency and an RPO of zero at the cost of higher write latency and the three-Region/Region-set constraints. For a two-Region active-active design, MREC is the common choice; MRSC is what you reach for when correctness across Regions (no stale reads, no lost writes) is non-negotiable and you can live within one Region set and three Regions.
4.3 Creating and operating a global table
For the current version, you make a table global by adding replicas withUpdateTable (the standalone update-global-table / create-global-table calls are the legacy path). Adding a replica has no performance impact on the existing table:# Create the base table in the primary Region (on-demand capacity).
aws dynamodb create-table \
--region us-east-1 \
--table-name Orders \
--attribute-definitions AttributeName=orderId,AttributeType=S \
--key-schema AttributeName=orderId,KeyType=HASH \
--billing-mode PAY_PER_REQUEST
# Promote it to a global table by adding a replica in the second Region (MREC).
aws dynamodb update-table \
--region us-east-1 \
--table-name Orders \
--replica-updates '[{"Create": {"RegionName": "us-west-2"}}]'Operationally, the things to watch:
- Streams. MREC replication is built on DynamoDB Streams (they are enabled by default and cannot be disabled on MREC replicas); MRSC does not use Streams for replication. Keep this in mind when you also consume Streams for your own event-driven processing, because your consumers see each Region's stream.
- Capacity. In provisioned mode, keep write capacity aligned across replicas (replicated writes consume write capacity in every replica); on-demand mode sidesteps this and is the simpler default for multi-Region.
- DescribeTable reports the consistency mode and, for MRSC, whether and in which Region a witness is configured.
4.4 Observing replication
MREC global tables publish aReplicationLatency CloudWatch metric per source/destination Region pair — this is your primary signal for "how far behind is the other Region" and therefore your live RPO estimate. Alarm on it. We return to observability in Section 9.5. Replicating the Database Tier: Aurora Global Database
Relational state cannot be multi-active the way DynamoDB global tables are, because a single logical SQL database has one authoritative writer. Amazon Aurora Global Database gives you the next best thing for active-active: one primary (writer) Region and up to several read-only secondary Regions, with storage-level replication that is fast enough to read from the secondaries and promote them quickly on failover. Single-Region Aurora HA (Multi-AZ, replicas, failover within a Region) is delegated to my Amazon RDS and Aurora High Availability Guide; the quorum/replication fundamentals are in Comparison of AWS Databases Using the Quorum Model. Here I cover only the cross-Region behavior.5.1 Topology and replication
An Aurora global database has one primary cluster and up to 10 read-only secondary clusters in different Regions — so a single global database can span up to 11 Regions. Replication is performed by Aurora's dedicated storage infrastructure (not by the database engine replaying a binlog), with typical cross-Region replication latency under a second. There is a capacity interaction worth noting: the total number of reader instances in the primary cluster plus the number of secondary clusters cannot exceed 15, so each secondary you add reduces the number of Aurora Replicas you can run in the primary.For RTO and RPO: Aurora global database RTO is on the order of minutes for a cross-Region failover, and RPO is typically measured in seconds (the asynchronous replication lag at the moment of failure). For Aurora PostgreSQL you can put a managed bound on this with the
rds.global_db_rpo parameter, which tracks and enforces an upper limit on RPO — at the cost of potentially throttling commits on the primary's writer when secondaries fall behind.5.2 Read-local, write-home, and write forwarding
By default, applications in a secondary Region can read locally (low latency) but must send writes to the primary Region's writer endpoint. This is the write-home pattern, and it is the relational counterpart to DynamoDB's multi-active writes: reads are active-active, writes funnel to one Region.Aurora offers write forwarding to make write-home transparent: a secondary cluster automatically forwards write SQL statements to the primary, which applies them and propagates the changes back. Aurora handles the cross-Region networking, session context, and transaction context for you, so your application can issue writes against the secondary endpoint without building its own routing layer. Write forwarding is supported for both Aurora MySQL and Aurora PostgreSQL global databases. The trade-off is latency (each forwarded write makes a cross-Region round trip to the primary) and the consistency level you select for reads of your own forwarded writes — so write forwarding is excellent for low-write, read-heavy secondary workloads and less suitable for write-heavy paths, which you would route directly to the primary Region instead.
5.3 Switchover versus failover (the two ways the primary moves)
This is the operational distinction to get exactly right, because choosing the wrong one during an incident either loses data you did not need to lose or wastes time you do not have.Switchover (formerly called "managed planned failover") is for planned, controlled scenarios — maintenance, "regional rotation" compliance exercises, follow-the-sun write locality, or failing back after a previous failover. Aurora first synchronizes the chosen secondary with the primary, then makes the old primary read-only and promotes the secondary to writer. Because it synchronizes first, switchover has zero data loss (RPO = 0). It maintains the same replication topology (same number of clusters in the same Regions). It requires the primary and secondary to be on the same major and minor engine versions (patch-level compatibility varies by engine version).
Failover is for unplanned outages — an actual Regional impairment. You promote a secondary to be the new primary, accepting that you may lose the writes that had not yet replicated. The RPO is a typically-small, non-zero value measured in seconds, proportional to the replication lag at the moment of failure.
# PLANNED: zero-data-loss switchover to the us-west-2 secondary.
aws rds switchover-global-cluster \
--global-cluster-identifier app-global \
--target-db-cluster-identifier arn:aws:rds:us-west-2:111122223333:cluster:app-uswest2
# UNPLANNED: cross-Region failover, accepting possible data loss.
aws rds failover-global-cluster \
--global-cluster-identifier app-global \
--target-db-cluster-identifier arn:aws:rds:us-west-2:111122223333:cluster:app-uswest2 \
--allow-data-lossTwo operational gotchas:
- A headless secondary cluster (storage replicated but no DB instance, to save cost) must have a DB instance added before you can switch over or fail over to it. If your DR plan assumes an instant promotion of a headless secondary, that assumption is wrong — provisioning the instance is part of your RTO.
- Switchover requires matching engine versions; if you let the secondary drift on patch level, your planned-switchover capability silently degrades. Test it.
5.4 How Aurora fits an active-active routing tier
Because Aurora is single-writer, an active-active front end must route relational writes to whichever Region currently holds the primary, while DynamoDB writes go local. In practice you expose the Aurora writer through a stable name (a Route 53 record or an application-level service-discovery entry) that you repoint as part of failover, and you use write forwarding for the occasional secondary-Region write. Section 7 covers how to keep this honest — the routing tier sending users to "their" Region must not assume that Region is also the relational writer.6. Replicating Object and Static Data: S3 Cross-Region Replication
The third data shape is objects: user uploads, media, exports, static site assets, and the artifacts your application reads at runtime. Amazon S3 Cross-Region Replication (CRR) keeps a bucket in each Region in sync. The bucket-policy and access-control depth is out of scope here (see the S3 security material in the broader cluster); this section is about replication behavior for active-active.6.1 CRR, RTC, and bidirectional replication
- CRR replicates objects from a source bucket to a destination bucket in a different Region (S3 also offers Same-Region Replication, SRR, which is not our concern here). Replication is asynchronous.
- S3 Replication Time Control (RTC) adds a predictable replication SLA: it is designed to replicate 99.9% of new objects within 15 minutes, and it publishes replication metrics so you can alarm on backlog. Use RTC when objects must be available in the other Region within a bounded time.
- For active-active, where either Region may receive uploads, configure bidirectional replication — a replication rule from A→B and B→A — so that an object written in either Region appears in both. AWS explicitly recommends bidirectional replication for keeping the buckets behind an S3 Multi-Region Access Point synchronized.
- Existing objects (written before replication was enabled, or that failed replication) are not replicated by ongoing CRR; backfill them with S3 Batch Replication.
A CloudFormation sketch of one direction of a bidirectional setup, with RTC enabled:
Resources:
PrimaryBucket:
Type: AWS::S3::Bucket
Properties:
BucketName: app-assets-us-east-1
VersioningConfiguration:
Status: Enabled # Versioning is required for replication.
ReplicationConfiguration:
Role: !GetAtt ReplicationRole.Arn
Rules:
- Id: ReplicateToUsWest2
Status: Enabled
Priority: 1
DeleteMarkerReplication:
Status: Enabled
Filter: {}
Destination:
Bucket: arn:aws:s3:::app-assets-us-west-2
ReplicationTime:
Status: Enabled
Time:
Minutes: 15 # S3 RTC: 99.9% of objects within 15 minutes.
Metrics:
Status: Enabled
EventThreshold:
Minutes: 156.2 The two-writer problem for objects
Bidirectional CRR raises the same conflict question as the databases: if the same key is written in both Regions before replication catches up, which version wins? S3 replication, like DynamoDB MREC, converges on a last-writer-wins basis using object timestamps, and versioning (required for replication) preserves the older version rather than destroying it. The clean design is to avoid same-key concurrent writes across Regions — partition the object key space by Region or by tenant (Section 7) so that a given object is only ever written in one Region — rather than to rely on conflict resolution. Replication is for durability and read-locality, not for merging concurrent edits to the same object.A practical front-end for global object access is an S3 Multi-Region Access Point (MRAP): a single global endpoint that routes each request to the nearest bucket. MRAP plus bidirectional CRR gives you read-local objects with a single name, and the
PutBucketReplication API supports up to 1,000 rules per bucket (with KMS-encrypted-object replication supported) if your key space needs fine-grained routing.7. Write Routing, Idempotency, and Conflict Avoidance
This is the section that separates a robust active-active design from one that quietly corrupts data. The previous three sections established that DynamoDB MREC and S3 CRR resolve cross-Region conflicts by last-writer-wins, and Aurora is single-writer. None of those mechanisms merge concurrent writes to the same entity — last-writer-wins silently discards the loser. So the design goal is not "handle conflicts" but "architect so the same entity is almost never written in two Regions at once," and make the writes that do happen idempotent so retries during failover do not double-apply.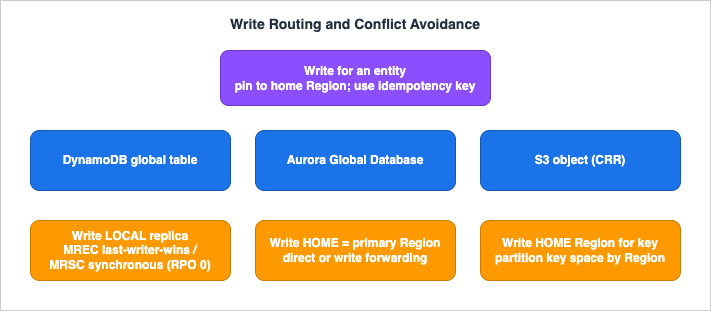
7.1 Pin each entity to a home Region
The most effective technique is entity-level Region pinning: every tenant, user, or aggregate has a designated home Region that owns its writes. Reads can happen anywhere (served from the local replica), but writes for that entity are routed to its home Region. This turns a scary "two Regions writing the same row" problem into a normal "one Region writes, the other reads" problem — which is exactly what Aurora's write-home model and DynamoDB's per-item convergence both handle cleanly.Implementations:
- Store a
homeRegionattribute on the tenant/user record. The routing layer (or the application after authentication) sends write requests to that Region. A user temporarily served by the "wrong" Region (because of a routing or latency decision) still has their writes forwarded to the home Region. - Encode the home Region in the partition key space when it helps (e.g., a leading key segment), so that the data layout itself reflects ownership.
- On failover, the home Region for affected entities is reassigned to the surviving Region as a deliberate, logged operation — not as an implicit side effect of routing.
Region pinning is what makes "active-active" safe: the system is active-active in aggregate (both Regions write different entities concurrently) without ever being active-active for a single entity.
7.2 Make every write idempotent
During failover, retries are unavoidable: clients retry, queues redeliver, and your own failover tooling may re-issue operations. If a write is not idempotent, a retry double-applies it (a second charge, a duplicate order). Make writes idempotent with:- Idempotency keys. The client (or ingress) attaches a unique key per logical operation; the write path records it and treats a repeat as a no-op that returns the original result.
- DynamoDB conditional writes.
ConditionExpression: attribute_not_exists(orderId)makes "create this order" safe to retry — the second attempt fails the condition instead of creating a duplicate.
# Idempotent create: the condition makes a retried PutItem a safe no-op.
aws dynamodb put-item \
--region us-east-1 \
--table-name Orders \
--item '{"orderId": {"S": "ord-9F3A"}, "status": {"S": "PLACED"}}' \
--condition-expression "attribute_not_exists(orderId)"- Version numbers / optimistic concurrency. Carry a
versionattribute and condition writes on the expected version. This both prevents lost updates within a Region and gives you a deterministic signal if a stale cross-Region replica tries to overwrite a newer value.
7.3 Decide write-local versus write-home per data store
Putting it together, a single request often touches more than one data store, each with its own write rule:| Data store | Write model | Where writes land | Conflict handling |
|---|---|---|---|
| DynamoDB global table (MREC) | Multi-active | Local Region replica | Last-writer-wins (per item) |
| DynamoDB global table (MRSC) | Multi-active, synchronous | Local Region replica | ReplicatedWriteConflictException (retry) |
| Aurora Global Database | Single-writer | Primary Region (direct or via write forwarding) | No conflict — one writer |
| S3 (bidirectional CRR) | Effectively single-writer per key | Home Region for that key | Last-writer-wins; avoid by key partitioning |
The discipline is to write this table down for your system and route each store accordingly. The failure mode of skipping it is a request that writes DynamoDB locally in
us-west-2 while its Aurora write is forwarded to a primary in us-east-1, with no plan for what happens to the DynamoDB write if the Aurora write fails — a partial, cross-Region, non-atomic update. The fix is the same as in any distributed system: make the steps idempotent, order them so the authoritative/relational write is the commit point, and reconcile asynchronously (a saga or a Streams-driven repair) rather than pretending the cross-Region multi-store write is a single transaction.8. Failover Mechanics and Control-Plane Dependencies
A Region failover is a choreography across the routing tier and every data tier, and the order and dependencies matter. This section walks the failover and then addresses the dependency that quietly breaks most first attempts: relying on control planes during a Regional event.
8.1 The failover sequence
For a primary-Region (us-east-1) impairment in our reference architecture:- Detect. Health checks (Route 53 / Global Accelerator) mark the Region's endpoints unhealthy; replication-lag and error-rate alarms corroborate that this is a Region event, not a single bad host.
- Shift routing. Global Accelerator moves traffic to the healthy endpoint group within seconds; Route 53 withdraws the unhealthy records, with clients converging over the TTL. The application tier in
us-west-2, already running hot, absorbs the load — which it can only do if it was pre-scaled (Section 8.2). - Promote the relational writer. DynamoDB needs no promotion —
us-west-2was already writing its local replica. Aurora does: you run a failover (failover-global-cluster --allow-data-loss) to promote theus-west-2secondary to primary, accepting the seconds-scale RPO. Repoint the writer endpoint name. - Re-pin entities. Reassign the home Region of affected tenants/users to
us-west-2so their writes now land locally. - Reconcile. When
us-east-1returns, it rejoins as a secondary. Reconcile any DynamoDB writes that were in flight at the moment of failure (last-writer-wins will have converged them, but verify business-critical items) and any Aurora writes lost to the non-zero RPO, using your idempotency keys and version numbers to detect and repair.
The DynamoDB and Aurora halves of this sequence are deliberately asymmetric: the multi-active store needs no promotion (its RPO/RTO for the surviving Region is effectively zero because it was already serving writes), while the single-writer store needs an explicit promotion with a real RPO. This asymmetry is the practical reason teams push as much state as they can into DynamoDB global tables and keep the relational footprint small and well-bounded.
8.2 Static stability: do not depend on the control plane during recovery
The most common reason a tested failover fails in the real event is a hidden dependency on a control plane — the APIs that create and modify resources — at the exact moment that control plane is impaired. AWS's guidance here is explicit and is worth internalizing.AWS separates every service into a data plane (the part that does the work: serving DynamoDB reads/writes, answering DNS queries, routing packets) and a control plane (the part that creates and changes resources: launching instances, creating tables, changing DNS records). The Well-Architected Reliability pillar's REL11-BP04 states the principle directly: rely on the data plane and not the control plane during recovery, because data planes are engineered for much higher availability than control planes. The canonical example is Route 53 itself: its DNS query data plane is designed for a 100% availability SLA and is globally distributed, while its control plane for changing records runs in a single Region and is not covered by that SLA. If your failover plan requires changing a Route 53 record (a control-plane action) during a Regional event, you have built a dependency on the thing most likely to also be stressed.
The design pattern that avoids this is static stability (documented in the AWS Fault Isolation Boundaries whitepaper and the "Static Stability using Availability Zones" Builders' Library paper): build the system so it continues operating without needing control-plane changes when a dependency fails. Concretely, for multi-Region active-active:
- Pre-provision the standby capacity. The
us-west-2application tier must already be running enough capacity to take the full load. Do not plan to scale it out during the event with Auto Scaling control-plane calls that may be throttled or slow. Static stability means paying for idle-ish capacity so that failover is a routing change, not a provisioning change. - Prefer data-plane failover primitives. Use health-check-driven routing (a data-plane behavior) rather than scripts that call control-plane APIs to rewrite DNS. Amazon Route 53 Application Recovery Controller (ARC) exists precisely for this: its routing controls are data-plane operations (designed to keep working during Regional events) that flip pre-created records, instead of you issuing control-plane
ChangeResourceRecordSetscalls mid-incident. ARC also gives you readiness checks that continuously verify the standby is actually ready (capacity, quotas, configuration) so failover does not surprise you. - Pre-create everything you will need. Buckets, tables, replicas, security groups, IAM roles, and DNS records should all exist before the event. A failover that has to create a resource is a failover betting on the control plane.
Watch the quota interactions. Pre-provisioning only works if the standby Region's service quotas allow it. The Aurora capacity rule is a concrete example: the reader instances in the primary cluster plus the number of secondary clusters cannot exceed 15, so a topology with many secondaries leaves fewer in-Region readers to absorb failover load. More broadly, request quota increases (concurrent executions, instances, connections) in the standby Region before the event — a failover that trips a quota is a failover that depended on a control-plane increase at the worst moment. Route 53 ARC readiness checks can verify quota headroom continuously.
Static stability is the difference between a runbook that works in the game-day and one that works in the disaster. The whole point of active-active is that the surviving Region needs no new resources to take over — it only needs traffic pointed at it.
8.3 Rehearse it
A multi-Region failover you have not executed is a hypothesis, not a capability. Rehearse with real mechanisms:- Use switchover (zero data loss) to rotate the Aurora primary on a schedule — this exercises the promotion path without an outage and satisfies "regional rotation" compliance requirements.
- Use Route 53 ARC routing controls (or Global Accelerator traffic dials) to shift live traffic between Regions during a game-day.
- DynamoDB supports fault-injection testing for global tables so you can exercise your application's behavior under replication impairment.
9. Observability and Failure Modes
Active-active systems fail in ways single-Region systems cannot, and most of those failures are invisible unless you instrument replication explicitly. This section catalogs the failure modes and the signals that catch them. The deep observability-architecture treatment (distributed tracing, correlation IDs across services) is delegated to the observability guide in this series.9.1 The signals that matter
| Signal | Source | What it tells you |
|---|---|---|
DynamoDB ReplicationLatency | CloudWatch (per Region pair) | MREC replication lag = live RPO for the key-value tier |
Aurora AuroraGlobalDBRPOLag | CloudWatch (secondary clusters) | Cross-Region replication lag = live RPO for the relational tier |
Aurora AuroraGlobalDBReplicationLag | CloudWatch (older MySQL minor versions) | Same, for engine versions before the RPO-lag metric |
| S3 RTC replication metrics | CloudWatch / S3 | Object-replication backlog against the 15-minute SLA |
| Route 53 / Global Accelerator health-check status | CloudWatch | Whether each Region is considered healthy by the router |
The single most important alarm in an active-active system is on replication lag (
ReplicationLatency, AuroraGlobalDBRPOLag). Rising lag means your effective RPO is growing — you would lose more data than your target if a Region failed right now — and it is an early symptom of a Region beginning to degrade before it fully fails.9.2 The characteristic failure modes
- Single-Region impairment. The clean case Section 8 handles. Detection is health checks plus a correlated spike in one Region's error rate and the other Region's load. The trap is mistaking a partial impairment (some services down) for a full one and failing over more than necessary.
- Replication-lag growth. Often the first sign of trouble. A primary under load, a network event, or an Aurora PostgreSQL
rds.global_db_rpobound throttling commits can all push lag up. Alarm on the lag metrics, not just on hard failures. - Split-brain-style updates. Two Regions write the same entity during a window where each thinks it is authoritative (usually a routing or re-pinning mistake). Under MREC/CRR, last-writer-wins silently picks one and discards the other — no error is raised. The only defense is prevention (Region pinning, Section 7) plus reconciliation tooling (version numbers, Streams-driven audits) that surfaces "an item was written in two Regions" after the fact. This is why Section 7 is the most important section, not this one.
- Health-check flapping. A health check that oscillates between healthy and unhealthy causes traffic to thrash between Regions, doubling connection churn and confusing capacity. Tune health-check thresholds (failure count, interval) so a transient blip does not trigger failover, and remember Route 53 / Global Accelerator fail open when everything looks unhealthy — a flapping-everything condition does not black-hole traffic, but it also will not give you the clean failover you might expect.
- Asymmetric capacity. The surviving Region was not pre-scaled (a static-stability violation) and falls over under the combined load. This is a design bug, not a runtime one — catch it with Route 53 ARC readiness checks and game-days.
9.3 Diagnosing across Regions
When an incident spans Regions, the diagnostic discipline is: (1) confirm scope with health checks and per-Region error rates — is this one Region or both? (2) check replication-lag metrics to quantify the data-loss exposure before deciding to fail over; (3) decide switchover (planned, RPO 0) versus failover (unplanned, RPO seconds) based on whether the primary is actually gone; (4) after recovery, reconcile using idempotency keys and version numbers. Carrying a correlation ID through every tier (the subject of the observability guide) is what lets you reconstruct "what happened to this request" across two Regions.10. Variations: Active-Passive, Pilot Light, and When Active-Active Is Overkill
Active-active is the most expensive and most complex multi-Region topology, and it is frequently the wrong choice. The honest framing is a spectrum of decreasing RTO/RPO against increasing cost and complexity — exactly the spectrum my AWS Disaster Recovery Strategies Guide is built around, and the deep selection belongs there, not here. The short version:- Backup and Restore / Pilot Light — when an RTO of hours and an RPO of minutes-to-hours is acceptable. Most internal systems live here. Active-active is wasteful for them.
- Warm Standby — a scaled-down but always-on copy in the second Region that you scale up on failover. This is the pragmatic sweet spot for many production systems: most of the resilience of active-active, less of the cost and conflict complexity, because the standby normally takes no writes so there is no cross-Region conflict problem at all. Notably, most of this article's data tier still applies — Aurora Global Database, DynamoDB global tables, and S3 CRR are the replication mechanisms for Warm Standby too; the difference is purely whether the second Region serves live write traffic.
- Multi-Site Active-Active (this article) — when you need near-zero RTO, both Regions hot, and you can either tolerate eventual consistency (MREC, last-writer-wins) or pay for MRSC's synchronous writes. Justified for global, latency-sensitive, high-availability workloads where a Region's worth of downtime is unacceptable.
The single best piece of advice: do not adopt active-active to avoid a failover step. Active-active replaces an explicit, rehearsed promotion with a continuous, subtle conflict-avoidance obligation. If your real requirement is "recover fast," Warm Standby with a rehearsed switchover/failover is often the better engineering trade. Choose active-active when the requirement is genuinely "both Regions serve writes," and then implement it with the discipline of Sections 7 and 8.
11. Frequently Asked Questions
Is a DynamoDB global table really multi-active, or is there a primary?
It is genuinely multi-active — there is no primary replica. You read and write your local Region's replica, and DynamoDB propagates writes to the others. In the default MREC mode, concurrent conflicting writes converge by last-writer-wins; in the opt-in MRSC mode, writes are synchronously replicated (RPO 0) and conflicting concurrent writes raise a retryableReplicatedWriteConflictException.Can Aurora Global Database accept writes in two Regions at once?
No. Aurora is single-writer: one Region holds the primary (writer) and the others are read-only secondaries. Write forwarding lets a secondary transparently forward writes to the primary (supported for both Aurora MySQL and PostgreSQL), so your application code can write against a secondary, but the write still executes in the one primary Region. True concurrent multi-Region relational writes are not what Aurora Global Database does.What is the difference between switchover and failover in Aurora Global Database?
Switchover (formerly "managed planned failover") is for planned events and has zero data loss — Aurora synchronizes the secondary before promoting it, and it requires matching engine versions. Failover is for unplanned Regional outages, uses the--allow-data-loss option, and has a small non-zero RPO measured in seconds. Use switchover for maintenance and regional rotation; reserve failover for real disasters.How fast does failover actually happen?
It depends on the tier. Global Accelerator shifts traffic in seconds (no DNS caching); Route 53 failover is bounded by your record TTL plus client caching. DynamoDB global tables need no promotion — the surviving Region was already writing. Aurora needs an explicit failover with an RTO on the order of minutes. Your end-to-end failover time is the slowest of these, which is usually the Aurora promotion.When should I use MRSC instead of MREC for global tables?
Use MRSC when you cannot tolerate stale cross-Region reads or any lost writes (RPO 0) and you can live within its constraints: exactly three Regions within a single Region set (US, EU, or AP), no TTL or LSI, empty-table conversion only. Use the default MREC when lower write latency matters more and an RPO of a few seconds is acceptable — which is the common choice for two-Region active-active.Do I need bidirectional S3 replication?
If both Regions may receive object uploads (true active-active for objects), yes — configure A→B and B→A so an object written in either Region appears in both, and use S3 Batch Replication to backfill existing objects. If only one Region writes objects, one-directional CRR is enough. Either way, avoid concurrent same-key writes across Regions; partition the key space by Region or tenant rather than relying on last-writer-wins.How do I keep configuration and secrets consistent across Regions?
The same discipline that governs the data tier applies to non-database state: replicate it deterministically rather than editing each Region by hand. Store secrets and parameters in a service that supports cross-Region replicas so each Region reads a local copy, deploy identical infrastructure-as-code to both Regions from one source of truth, and treat any per-Region drift (engine patch levels, quotas, configuration) as a failover risk that readiness checks should surface. The principle is the same one running through this whole article: one authoritative definition, replicated outward, never two hand-maintained copies.12. Summary
Multi-Region active-active comes down to three questions asked once per data store — replication, routing, and conflict — and to one discipline: static stability.- The reference architecture is two symmetric stacks joined by a global routing tier (Route 53 and/or Global Accelerator) over a global data tier (DynamoDB global tables, Aurora Global Database, S3 CRR).
- DynamoDB global tables are multi-active (read/write local, MREC last-writer-wins or MRSC synchronous), while Aurora Global Database is single-writer (read-local secondaries, write-home via write forwarding, switchover for planned moves and failover for disasters). That asymmetry drives everything.
- Routing is DNS-bounded with Route 53 or seconds-fast with Global Accelerator, both fail-open by design.
- Conflict avoidance — not conflict resolution — is the real work: pin each entity to a home Region, make every write idempotent, and decide write-local versus write-home per store.
- Failover is a choreography that must not depend on the control plane: pre-provision capacity, use data-plane primitives (Route 53 ARC), and rehearse with switchovers and game-days.
- Observability centers on replication-lag metrics (
ReplicationLatency,AuroraGlobalDBRPOLag) as your live RPO, because the dangerous failures (split-brain writes) raise no errors.
For choosing a strategy rather than implementing the most demanding one, start at the AWS Disaster Recovery Strategies Guide; for single-Region database HA see the Amazon RDS and Aurora High Availability Guide and the Amazon DynamoDB Capacity and Global Tables Guide; for the routing internals see the Amazon Route 53 DNS Architecture Guide and Route 53 Health Check and Failover Pitfalls. Centralized cross-Region logging and audit for these flows is covered in the upcoming Centralized Logging and Audit Architecture on AWS.
13. References
- Amazon DynamoDB Developer Guide - How DynamoDB global tables work (MREC and MRSC)
- Amazon DynamoDB Developer Guide - Global tables: multi-active, multi-Region replication
- Amazon Aurora User Guide - Using Amazon Aurora Global Database
- Amazon Aurora User Guide - Using switchover or failover in Amazon Aurora Global Database
- Amazon Aurora User Guide - Using write forwarding in an Amazon Aurora global database
- AWS Global Accelerator Developer Guide - Endpoint groups for standard accelerators
- AWS Global Accelerator Developer Guide - How failover works for unhealthy endpoints
- Amazon Route 53 Developer Guide - Active-active and active-passive failover
- Amazon Route 53 Developer Guide - How Amazon Route 53 averts failover problems (fail-open)
- Amazon S3 User Guide - Replicating objects (CRR, RTC, and bidirectional replication)
- Amazon S3 User Guide - Configuring replication for Multi-Region Access Points
- AWS Well-Architected Reliability Pillar - REL11-BP04 Rely on the data plane and not the control plane during recovery
- AWS Whitepaper - AWS Fault Isolation Boundaries: Static stability
- Amazon Builders' Library - Static stability using Availability Zones
- Amazon Route 53 Application Recovery Controller Developer Guide
- Hidekazu Konishi - AWS Disaster Recovery Strategies Guide
- Hidekazu Konishi - Amazon RDS and Aurora High Availability Guide
- Hidekazu Konishi - Amazon DynamoDB Capacity and Global Tables Guide
- Hidekazu Konishi - Amazon Route 53 DNS Architecture Guide
- Hidekazu Konishi - Route 53 Health Check and Failover Pitfalls
- Hidekazu Konishi - Comparison of AWS Databases Using the Quorum Model
References:
Tech Blog with curated related content
Written by Hidekazu Konishi