AWS History and Timeline regarding Amazon Redshift - Overview, Functions, Features, Summary of Updates, and Introduction
First Published:
Last Updated:
This time, I have created a historical timeline for Amazon Redshift, the fully managed, petabyte-scale cloud data warehouse that AWS first announced as a limited preview at re:Invent in November 2012 and made generally available in February 2013. Amazon Redshift was the first data warehouse built for the cloud, using a massively parallel processing (MPP) architecture and columnar storage to run SQL analytics across terabytes to petabytes of structured and semi-structured data with the same SQL-based tools and business intelligence applications that teams already use.
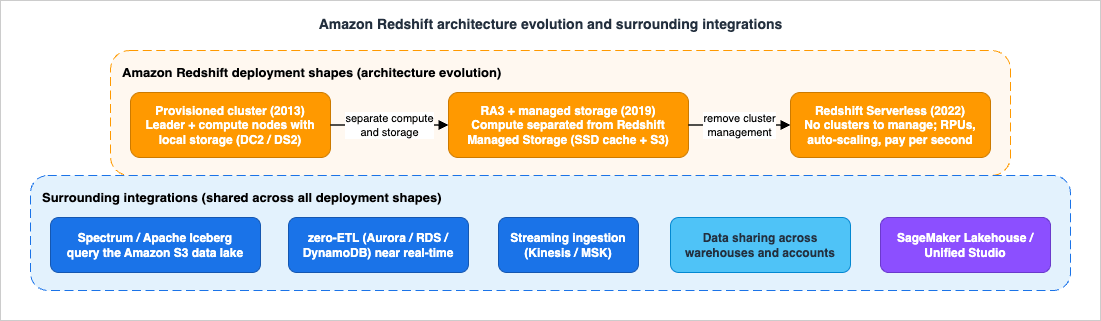
Over the years, Amazon Redshift has grown from a single provisioned-cluster service into a broad analytics platform that includes Amazon Redshift Spectrum for querying data directly in Amazon S3, RA3 nodes that separate compute from managed storage, Amazon Redshift Serverless, data sharing, zero-ETL integrations with operational databases, streaming ingestion, Amazon Redshift ML, generative SQL with Amazon Q, and integration with Amazon SageMaker Lakehouse and Amazon SageMaker Unified Studio.
Just like before, I am summarizing the main features while following the birth of Amazon Redshift and tracking its feature additions and updates as a Current Overview, Functions, Features of Amazon Redshift.
This article focuses on representative service-level milestones (announcements, previews, general availability, and major capabilities), not on every minor cluster version or single-region expansion. I hope these will provide clues as to what has remained the same and what has changed in Amazon Redshift.
Because Amazon Redshift sits at the center of analytics on AWS, this timeline is intended to be read alongside the AWS Data Lakehouse Architecture Guide, the AWS Database Glossary, and the related Amazon DynamoDB and Amazon Aurora timelines.
Background and Method of Creating Amazon Redshift Historical Timeline
The reason for creating a historical timeline of Amazon Redshift this time is that Redshift has now been generally available for more than a decade, has expanded from a single provisioned-cluster data warehouse into a broad analytics platform, and sits at the center of data warehousing, data lake analytics, and machine learning on AWS.Another reason is that since the announcement of Amazon Redshift in November 2012, AWS has steadily added node types (DS2, DC2, RA3), deployment shapes (provisioned clusters and Amazon Redshift Serverless), data lake capabilities (Redshift Spectrum, Apache Iceberg, AWS Lake Formation integration), data movement features (zero-ETL integrations, streaming ingestion, auto-copy), collaboration features (data sharing and multi-data-warehouse writes), security features (RBAC, row-level security, dynamic data masking), and machine learning and generative AI capabilities (Amazon Redshift ML, Amazon Q generative SQL, Amazon Bedrock integration). Therefore, I wanted to organize the information of Amazon Redshift with the following approaches.
- Tracking the history of Amazon Redshift and organizing the transition of updates
- Summarizing the feature list and characteristics of Amazon Redshift
- What's New with AWS?
- AWS News Blog
- Document History for Amazon Redshift
- Recap of Amazon Redshift key product announcements (AWS Big Data Blog)
The content posted is limited to major features related to the current Amazon Redshift and necessary for the feature list and overview description.
In other words, please note that the items on this timeline are not all updates to Amazon Redshift features, but are representative updates that I have picked out.
Amazon Redshift was first announced as a limited preview at re:Invent 2012 (Announcing Amazon Redshift), and the service became generally available in February 2013 (Amazon Redshift - Now Broadly Available).
Amazon Redshift Historical Timeline (Updates from November 28, 2012)
Now, here is a timeline related to the functions of Amazon Redshift. As of the time of writing this article, the history of Amazon Redshift spans more than a decade since its announcement in November 2012.2012 | 2013 | 2015 | 2017 | 2018 | 2019 | 2020 | 2021 | 2022 | 2023 | 2024 | 2025 | 2026
* The table can be sorted by clicking on the column names.| Date | Summary |
|---|---|
| 2012-11-28 | Amazon Redshift is announced as a limited preview at AWS re:Invent 2012. Redshift is introduced as a fast, fully managed, petabyte-scale data warehouse service in the cloud that lets customers analyze data using standard SQL-based tools and business intelligence applications. It is presented as the first cloud data warehouse to remove the complexity of provisioning, managing, and scaling a data warehouse. References: Announcing Amazon Redshift |
| 2013-02-15 | Amazon Redshift becomes generally available. After its limited preview, Redshift opens to all customers as a managed, MPP, columnar data warehouse that can start small and scale to a petabyte or more, integrating with popular SQL and business intelligence tools. References: Amazon Redshift - Now Broadly Available |
| 2015-06-09 | Amazon Redshift introduces Dense Storage (DS2) node types and additional reserved node payment options. The DS2 nodes deliver roughly twice the memory and compute of the previous generation at the same price, improving price-performance for storage-heavy data warehouses. References: Amazon Redshift is Now Faster and More Cost-Effective than Ever |
| 2017-04-19 | Amazon Redshift Spectrum is launched. Spectrum lets a Redshift cluster run SQL queries directly against exabytes of data in Amazon S3 with no loading or ETL, using the same SQL and BI tools, and scales query compute across a shared pool of Spectrum workers. This was a foundational step toward separating storage and compute. References: Amazon Redshift Spectrum - Exabyte-Scale In-Place Queries of S3 Data |
| 2017-10-17 | Amazon Redshift announces Dense Compute (DC2) node types. DC2 nodes deliver about twice the performance of DC1 at the same price for compute-intensive data warehouses with local SSD storage. References: Amazon Redshift Announces Dense Compute (DC2) Nodes |
| 2018-11-15 | Amazon Redshift adds Elastic Resize. Elastic Resize adds or removes nodes from a cluster in minutes to handle changing workloads, making it much faster to scale capacity than the earlier classic resize. References: Amazon Redshift announces Elastic Resize |
| 2019-03-26 | Amazon Redshift Concurrency Scaling becomes generally available. Concurrency Scaling automatically adds transient cluster capacity for bursts of concurrent queries and removes it when demand subsides, keeping query performance fast for many simultaneous users. References: Amazon Redshift Concurrency Scaling |
| 2019-08-09 | Amazon Redshift Spectrum adds column-level access control with AWS Lake Formation. Fine-grained, column-level permissions defined in AWS Lake Formation can be enforced on Spectrum queries against the data lake, tightening governance for Amazon S3-based analytics. References: Amazon Redshift Spectrum now supports column-level access control with AWS Lake Formation |
| 2019-12-03 | Amazon Redshift announces RA3 nodes with managed storage. RA3 nodes (starting with ra3.16xlarge) separate compute from Amazon Redshift Managed Storage, which uses high-performance local SSD as a tier-1 cache and automatically tiers colder data to Amazon S3, so customers scale and pay for compute and storage independently. References: Amazon Redshift announces RA3 nodes with managed storage |
| 2019-12-03 | Amazon Redshift data lake export is announced. The UNLOAD command can export query results to Amazon S3 in the open, columnar Apache Parquet format, making it easy to share warehouse data with the data lake and other analytics engines. References: Announcing Amazon Redshift data lake export |
| 2019-12-03 | Amazon Redshift Federated Query enters preview. Federated Query lets Redshift query live data in Amazon RDS and Amazon Aurora PostgreSQL databases and join it with warehouse and Amazon S3 data, without moving the operational data first. References: Amazon Redshift announces Federated Query (Preview) |
| 2020-04-16 | Amazon Redshift Federated Query becomes generally available. Federated querying to Amazon RDS for PostgreSQL and Amazon Aurora PostgreSQL reaches GA, and support was later extended to MySQL-compatible sources. References: Amazon Redshift announces general availability of Federated Query |
| 2020-09-10 | The Amazon Redshift Data API is announced. The Data API lets applications run SQL against Redshift over HTTPS without managing persistent database connections, which is well suited to serverless and event-driven applications such as AWS Lambda. References: Announcing Data API for Amazon Redshift |
| 2020-12-01 | AQUA (Advanced Query Accelerator) for Amazon Redshift is announced in preview. AQUA is a distributed, hardware-accelerated cache that pushes parts of query processing closer to storage to speed up certain scan- and aggregation-heavy queries on RA3 clusters. References: AWS announces AQUA (Advanced Query Accelerator) for Amazon Redshift (Preview) |
| 2020-12-09 | Amazon Redshift launches the RA3.xlplus node type. RA3.xlplus is the third and smallest member of the RA3 family (after ra3.16xlarge and ra3.4xlarge), bringing RA3's separation of compute and storage and Amazon Redshift Managed Storage to smaller and more cost-conscious data warehouses. References: Amazon Redshift launches RA3.xlplus nodes with managed storage |
| 2020-12-09 | Amazon Redshift Automatic Table Optimization becomes generally available. Automatic Table Optimization uses machine learning to automatically select and apply sort and distribution keys based on query patterns, reducing manual tuning. References: Amazon Redshift announces Automatic Table Optimization |
| 2021-03-10 | Amazon Redshift data sharing and cross-database queries become generally available. Data sharing provides live, secure access to data across Redshift clusters without copying or moving it, and cross-database queries let a single query span databases within a cluster. Data sharing was later extended to cross-account scenarios. References: Announcing general availability of Amazon Redshift data sharing |
| 2021-04-14 | AQUA (Advanced Query Accelerator) for Amazon Redshift becomes generally available. After preview, AQUA reaches GA for RA3 nodes at no additional cost, accelerating qualifying queries. References: AWS announces general availability of AQUA for Amazon Redshift |
| 2021-05-27 | Amazon Redshift ML becomes generally available. Redshift ML lets users create, train, and apply machine learning models using familiar SQL CREATE MODEL statements, with Amazon SageMaker Autopilot training models behind the scenes and predictions run in the warehouse. References: Amazon Redshift ML Is Now Generally Available |
| 2021-09-29 | Amazon Redshift Query Editor v2 is launched. The next-generation, web-based Query Editor v2 provides a modern SQL authoring experience with visual schema browsing, notebook-style query organization, charting, and easy result sharing, directly in the AWS Management Console. References: Amazon Redshift announces the next generation of the Amazon Redshift Query Editor |
| 2021-11-30 | Amazon Redshift Serverless is announced in preview at re:Invent 2021. Redshift Serverless lets users run and scale analytics without provisioning or managing clusters, automatically scaling capacity and charging only for what is used. References: Announcing Amazon Redshift Serverless (Preview) |
| 2022-04-07 | Amazon Redshift adds role-based access control (RBAC). RBAC lets administrators grant database permissions through roles rather than to individual users, simplifying least-privilege management at scale. References: Amazon Redshift announces support for role-based access control (RBAC) |
| 2022-07-12 | Amazon Redshift Serverless becomes generally available. Serverless GA introduces namespaces (database objects, users, and storage) and workgroups (compute resources measured in Redshift Processing Units, or RPUs), with automatic scaling for demanding and unpredictable workloads. References: Amazon Redshift Serverless - Now Generally Available with New Capabilities |
| 2022-07-12 | Amazon Redshift adds row-level security (RLS). RLS lets administrators control access to individual rows in tables based on user roles and policies, complementing column-level controls for fine-grained governance. References: Amazon Redshift now supports row-level security (RLS) |
| 2022-11-29 | Amazon Redshift streaming ingestion for Amazon Kinesis Data Streams and Amazon MSK becomes generally available. Streaming ingestion lets customers ingest hundreds of megabytes per second from Amazon Kinesis Data Streams or Amazon MSK directly into materialized views using SQL, with low latency and no need to first stage data in Amazon S3. References: Amazon Redshift announces general availability of real-time streaming ingestion for Amazon KDS and Amazon MSK |
| 2022-11-29 | The Amazon Redshift integration for Apache Spark becomes generally available. The integration makes it easy and performant for Apache Spark applications running on Amazon EMR, AWS Glue, and Amazon SageMaker to read from and write to Amazon Redshift. References: AWS announces Amazon Redshift integration for Apache Spark |
| 2023-04-20 | Amazon Redshift dynamic data masking becomes generally available. Dynamic data masking protects sensitive data by transforming column values at query time according to masking policies, without changing the stored data. References: Amazon Redshift announces general availability of dynamic data masking |
| 2023-07-25 | Amazon Redshift previews querying of Apache Iceberg tables. Redshift adds the ability to run SQL queries against Apache Iceberg open-table-format datasets in the data lake, broadening interoperability with other engines such as Amazon EMR and Amazon Athena. References: Amazon Redshift announces support for querying Apache Iceberg tables (Preview) |
| 2023-11-01 | Amazon Redshift Multi-AZ for RA3 clusters becomes generally available. A Multi-AZ RA3 deployment runs an active cluster across two Availability Zones, improving availability and providing automatic recovery for business-critical analytics workloads. References: Amazon Redshift now supports Multi-AZ deployments for RA3 clusters |
| 2023-11-07 | The Amazon Aurora MySQL zero-ETL integration with Amazon Redshift becomes generally available. The zero-ETL integration replicates transactional data from Amazon Aurora MySQL into Amazon Redshift within seconds, enabling near real-time analytics without building and managing ETL pipelines. References: Amazon Aurora MySQL zero-ETL integration with Amazon Redshift is now generally available |
| 2024-09-12 | The Amazon RDS for MySQL zero-ETL integration with Amazon Redshift becomes generally available. The integration extends zero-ETL near real-time replication into Redshift to Amazon RDS for MySQL source databases. References: Amazon RDS for MySQL zero-ETL integration with Amazon Redshift is now generally available |
| 2024-09-16 | Amazon Q generative SQL in Amazon Redshift Query Editor becomes generally available. Amazon Q generative SQL adds a natural-language assistant to Query Editor v2 that converts plain-language questions into SQL using schema context, helping users author queries faster. References: Amazon Q generative SQL is now generally available in Amazon Redshift Query Editor |
| 2024-10-15 | The Amazon Aurora PostgreSQL and Amazon DynamoDB zero-ETL integrations with Amazon Redshift become generally available. These integrations bring near real-time replication into Redshift to additional sources, including Amazon Aurora PostgreSQL and Amazon DynamoDB, expanding the zero-ETL family. References: Amazon Aurora PostgreSQL and Amazon DynamoDB zero-ETL integrations with Amazon Redshift now generally available, Amazon Aurora PostgreSQL zero-ETL integration with Amazon Redshift is now generally available |
| 2024-10-30 | Amazon Redshift auto-copy from Amazon S3 becomes generally available. Auto-copy automatically and continuously ingests new files from an Amazon S3 location into Redshift tables as they arrive, simplifying recurring batch loads. References: Amazon Redshift announces general availability of auto-copy from Amazon S3 |
| 2024-10-30 | AI-driven scaling and optimization for Amazon Redshift Serverless becomes generally available. Redshift Serverless uses machine learning to proactively scale and tune capacity based on workload patterns, helping meet price-performance targets without manual configuration. References: Amazon Redshift Serverless with AI-driven scaling and optimization is now generally available |
| 2024-10-30 | The Amazon Redshift ML integration with Amazon Bedrock becomes generally available. Using CREATE EXTERNAL MODEL, Redshift ML can invoke large language models hosted in Amazon Bedrock directly from SQL, bringing generative AI into analytical queries. References: Amazon Redshift adds integration with Amazon Bedrock for generative AI |
| 2024-11-26 | Amazon Redshift multi-data-warehouse writes through data sharing becomes generally available. Multiple Redshift warehouses can now write to the same databases through data sharing, so producer and consumer warehouses can collaborate on shared data with workload isolation. References: Amazon Redshift multi-data warehouse writes through data sharing is now generally available |
| 2024-12-03 | Amazon SageMaker Lakehouse and Amazon SageMaker Unified Studio (preview) are announced with Amazon Redshift integration at re:Invent 2024. SageMaker Lakehouse unifies data across Amazon S3 data lakes and Amazon Redshift data warehouses under Apache Iceberg-compatible access, and SageMaker Unified Studio (preview) brings data, analytics, and AI tooling, including Redshift SQL analytics, into a single experience. References: AWS announces Amazon SageMaker Lakehouse |
| 2025-03-13 | Amazon SageMaker Unified Studio becomes generally available. The unified studio reaches GA, integrating analytics and AI services, including Amazon Redshift, into a single environment for building and collaborating on data and AI projects. References: Amazon SageMaker Unified Studio is now generally available |
| 2025-09-19 | Amazon Redshift Multidimensional Data Layouts (MDDL) become generally available. MDDL dynamically sorts data based on actual query filters rather than fixed columns, delivering up to 10x better end-to-end performance for workloads with repetitive query filters. References: Amazon Redshift announces the general availability of Multidimensional Data Layouts |
| 2025-11-17 | Amazon Redshift adds general availability of write capability to Apache Iceberg tables. Building on Iceberg read support, Redshift adds SQL DDL operations (CREATE, SHOW, DROP) and INSERT for append-only workloads on Apache Iceberg tables, while remaining interoperable with other Iceberg engines. References: Amazon Redshift now supports writing to Apache Iceberg tables |
| 2026-04-23 | Amazon Redshift adds UPDATE, DELETE, and MERGE for Apache Iceberg tables. Row-level UPDATE, DELETE, and MERGE (UPSERT) operations can run directly from Redshift on partitioned and unpartitioned Iceberg tables, including Amazon S3 Tables, supporting change-data-capture and slowly-changing-dimension patterns. References: Amazon Redshift supports UPDATE, DELETE, MERGE for Apache Iceberg tables |
| 2026-05-18 | Amazon Redshift adds ALTER TABLE for Iceberg tables and writes via the AWS Glue Data Catalog mount. Redshift can modify Iceberg schema, partitioning, and properties with ALTER TABLE and write directly through the auto-mounted AWS Glue Data Catalog, which is useful for Iceberg tables federated with AWS Lake Formation. References: Amazon Redshift adds ALTER TABLE for Iceberg tables and writes via the AWS Glue Data Catalog mount |
Current Overview, Functions, Features of Amazon Redshift
Amazon Redshift is a fully managed, petabyte-scale cloud data warehouse service for running SQL analytics on structured and semi-structured data. It uses a massively parallel processing (MPP) architecture with columnar storage and data compression to run complex analytical queries quickly, and it is offered both as provisioned clusters (with RA3 nodes and Amazon Redshift Managed Storage) and as Amazon Redshift Serverless. Redshift connects the data warehouse to the surrounding ecosystem through Amazon Redshift Spectrum and Apache Iceberg for data lake queries, zero-ETL integrations and streaming ingestion for data movement, data sharing for collaboration, and Amazon Redshift ML, Amazon Q generative SQL, and Amazon SageMaker integration for machine learning and AI.Amazon Redshift Use Cases
- Cloud data warehouse migration and modernization: consolidate on-premises and legacy data warehouses into a managed, scalable cloud data warehouse.
- Business intelligence and reporting: power dashboards and BI tools with fast SQL queries over large historical datasets.
- Data lake analytics: query open data in Amazon S3 with Amazon Redshift Spectrum and Apache Iceberg without loading it first.
- Near real-time analytics: combine streaming ingestion and zero-ETL integrations to analyze operational data within seconds of it being generated.
- Self-service and natural-language analytics: let analysts and line-of-business users explore data with Query Editor v2 and Amazon Q generative SQL.
- In-database machine learning and generative AI: build predictive models with Amazon Redshift ML and invoke Amazon Bedrock models from SQL.
- Secure data sharing and data monetization: share live data across teams, accounts, and AWS Data Exchange without copying it.
Specific Examples of Use Cases
- A retailer migrates an on-premises data warehouse to Amazon Redshift RA3 clusters and scales storage independently of compute as historical sales data grows.
- A media company uses Amazon Redshift Serverless for intermittent, unpredictable reporting workloads and pays only for the capacity it consumes.
- A SaaS provider queries clickstream logs stored as Apache Parquet and Apache Iceberg tables in Amazon S3 with Redshift Spectrum, joining them with warehouse dimension tables.
- A gaming company streams player events from Amazon Kinesis Data Streams into Redshift materialized views for live leaderboards and fraud detection.
- A financial services firm enables zero-ETL integration from Amazon Aurora into Redshift to run near real-time analytics on transactions without building ETL pipelines.
- A marketing team uses Amazon Q generative SQL in Query Editor v2 to turn plain-language questions into SQL and Amazon Redshift ML to predict customer churn.
- A data platform team shares curated datasets from a producer warehouse to many consumer warehouses through data sharing, with multi-data-warehouse writes for collaboration.
Amazon Redshift Key Functions and Features
- Massively parallel processing (MPP) and columnar storage: queries are distributed across slices on multiple nodes, and columnar storage with compression minimizes I/O for analytical workloads.
- RA3 nodes and Amazon Redshift Managed Storage (RMS): RA3 nodes separate compute from managed storage that uses local SSD as a tier-1 cache and automatically tiers data to Amazon S3, so compute and storage scale and are paid for independently.
- Amazon Redshift Serverless: runs analytics without managing clusters; capacity is measured in Redshift Processing Units (RPUs) and scales automatically, with AI-driven scaling and optimization and per-second billing.
- Amazon Redshift Spectrum and Apache Iceberg: query data directly in Amazon S3 in open formats without loading it, including read and write support for Apache Iceberg tables.
- Concurrency Scaling: automatically adds transient capacity to handle bursts of concurrent queries and removes it when demand drops.
- Data sharing and multi-data-warehouse writes: provide live, secure access to data across warehouses and accounts without copying, and allow multiple warehouses to write to shared databases.
- zero-ETL integrations: replicate data from Amazon Aurora MySQL and PostgreSQL, Amazon RDS for MySQL, and Amazon DynamoDB into Redshift in near real time without ETL pipelines.
- Streaming ingestion and auto-copy: ingest from Amazon Kinesis Data Streams and Amazon MSK into materialized views, and automatically load new files from Amazon S3 with auto-copy.
- Amazon Redshift ML and Amazon Bedrock integration: create and run machine learning models with SQL via Amazon SageMaker, and invoke Amazon Bedrock large language models from SQL.
- Amazon Q generative SQL and Query Editor v2: a modern web SQL editor with a natural-language assistant that generates SQL from plain-language questions.
- Performance features: Automatic Table Optimization, Multidimensional Data Layouts (MDDL), materialized views, result caching, and AQUA for qualifying queries.
- Security and governance: encryption with AWS KMS, Amazon VPC isolation, AWS IAM access control, role-based access control (RBAC), row-level security, dynamic data masking, and AWS Lake Formation fine-grained access control for data lake queries.
- SageMaker Lakehouse and SageMaker Unified Studio: unify data across Amazon S3 data lakes and Redshift warehouses and bring analytics and AI tooling into a single environment.
Amazon Redshift Architecture
Leader Node and Compute Nodes
A provisioned Amazon Redshift cluster has one leader node and one or more compute nodes. The leader node parses SQL, builds and optimizes query plans, and coordinates parallel execution, while the compute nodes store data and run the query steps in parallel. Each compute node is divided into slices, and each slice processes a portion of the data assigned to it, which is the basis of Redshift's massively parallel processing (MPP) execution.Columnar Storage, Compression, and Zone Maps
Amazon Redshift stores table data in a column-oriented layout, so analytical queries that touch a few columns over many rows read far less data than a row store would. Columns are automatically compressed with encodings suited to their data, and Redshift maintains zone maps (in-memory min/max metadata per block) so the engine can skip blocks that cannot match a query predicate. Together these reduce I/O, which is the dominant cost of large analytical scans.Distribution Styles and Sort Keys
How data is distributed across slices and ordered within a node strongly affects performance. Distribution styles (KEY, EVEN, ALL, and AUTO) control how rows are spread across slices to minimize data movement during joins and aggregations, and sort keys order the data on disk so that range-restricted scans read fewer blocks. With Automatic Table Optimization and Multidimensional Data Layouts, Redshift can choose and adjust these physical design decisions automatically based on observed query patterns.Workload Management, Result Caching, and Materialized Views
Workload management (WLM), including automatic WLM and Concurrency Scaling, governs how queries are queued and how memory and concurrency are allocated. Result caching returns identical repeated queries from cache without re-execution, and materialized views precompute and incrementally maintain the results of expensive joins and aggregations, including over external and shared data, so dashboards and repeated reports run quickly.Amazon Redshift Storage, Ingestion, and the Data Lake
Amazon Redshift Managed Storage
On RA3 nodes and on Amazon Redshift Serverless, data lives in Amazon Redshift Managed Storage (RMS), which uses high-performance local SSDs as a tier-1 cache and automatically tiers data to Amazon S3 based on access patterns. This separation lets compute and storage scale and be paid for independently, and it underpins capabilities such as data sharing and Multi-AZ for RA3.Loading and Unloading Data
Data can be loaded with the COPY command from Amazon S3, Amazon EMR, Amazon DynamoDB, or remote hosts; ingested continuously with auto-copy as new files arrive in Amazon S3; or streamed directly into materialized views from Amazon Kinesis Data Streams and Amazon MSK. Query results and tables can be written back to the data lake with UNLOAD to open formats such as Apache Parquet, and Redshift can read and write Apache Iceberg tables for interoperability with engines such as Amazon Athena and Amazon EMR.Querying the Data Lake
Amazon Redshift Spectrum runs SQL directly against data in Amazon S3 without loading it, scaling query processing across a shared pool of Spectrum workers, and Redshift integrates with the AWS Glue Data Catalog and AWS Lake Formation for shared metadata and fine-grained access control. Through Amazon SageMaker Lakehouse, the same data can be presented under Apache Iceberg-compatible access so that warehouse and data lake data are queried together.Bringing in Operational Data
Zero-ETL integrations replicate transactional data from Amazon Aurora MySQL and PostgreSQL, Amazon RDS for MySQL, and Amazon DynamoDB into Amazon Redshift within seconds, removing the need to build and operate separate ETL pipelines, while Federated Query lets Redshift read live data from supported Amazon RDS and Amazon Aurora databases at query time.Amazon Redshift Security and Governance
Network Isolation
Amazon Redshift clusters and Redshift Serverless workgroups run inside an Amazon VPC, and inbound and outbound access is controlled by VPC security groups. Connectivity from on-premises environments can be established through AWS Direct Connect or AWS Site-to-Site VPN, and enhanced VPC routing can force all traffic between the warehouse and Amazon S3 through the VPC.Identity and Access Management
AWS IAM controls API-level access to Redshift resources such as creating, modifying, and deleting clusters and workgroups, and IAM roles grant Redshift access to other services such as Amazon S3 for COPY, UNLOAD, and Spectrum. For database-level access, IAM-based authentication and AWS Secrets Manager remove the need to embed long-lived passwords in application configuration.Encryption
Amazon Redshift encrypts data at rest using AWS KMS, including customer managed keys, covering the cluster or namespace, automated and manual snapshots, and managed storage. All connections support TLS/SSL for encryption in transit.Fine-Grained Access Control
Role-based access control (RBAC) grants database permissions through roles rather than to individual users, row-level security (RLS) restricts access to specific rows by policy, and dynamic data masking transforms sensitive column values at query time without changing the stored data. For data lake queries, AWS Lake Formation enforces fine-grained, column-level access control on Redshift Spectrum and Iceberg tables.Amazon Redshift Monitoring
Amazon CloudWatch Metrics
Amazon Redshift publishes metrics such as CPU utilization, query duration and counts, database connections, and storage usage to Amazon CloudWatch, where they can drive dashboards and alarms for both provisioned clusters and Redshift Serverless.System Views and the SYS Monitoring Views
Redshift exposes detailed query and system telemetry through system tables and views, including the consolidated SYS monitoring views, which let administrators analyze query history, queue behavior, and resource consumption to identify and tune the queries that dominate load.Query Editor v2 and AWS CloudTrail
Query Editor v2 provides in-console query monitoring and visualization, and AWS CloudTrail records management-plane API calls for auditing. Audit logging can also write connection and user-activity logs to Amazon S3 or Amazon CloudWatch Logs.Amazon Redshift Machine Learning and Generative AI
Amazon Redshift ML lets users create, train, and apply machine learning models with SQL CREATE MODEL statements, using Amazon SageMaker behind the scenes and running predictions in the warehouse. With the Amazon Bedrock integration, Redshift ML can invoke large language models directly from SQL through CREATE EXTERNAL MODEL, and Amazon Q generative SQL in Query Editor v2 turns natural-language questions into SQL using schema context. Together these bring predictive and generative AI into everyday SQL analytics.Amazon Redshift Best Practices
Performance
- Let Automatic Table Optimization and Multidimensional Data Layouts manage sort and distribution choices, and review them with the SYS monitoring views.
- Use materialized views and result caching for repeated dashboard and report queries, and enable Concurrency Scaling for bursty, high-concurrency read and write workloads.
- Use RA3 nodes or Amazon Redshift Serverless so that compute and managed storage scale independently.
Availability
- Use Multi-AZ deployments for RA3 clusters for business-critical workloads that require automatic recovery across Availability Zones.
- Rely on continuous, incremental backups to Amazon S3 and copy snapshots across Regions for disaster recovery.
Security
- Enable encryption at rest with AWS KMS and run the warehouse inside an Amazon VPC with tightly scoped security groups.
- Use RBAC, row-level security, and dynamic data masking for least-privilege access, and AWS Lake Formation for fine-grained access control over data lake queries.
Cost and Operations
- Match the deployment shape to the workload: provisioned RA3 (optionally with reserved nodes) for steady workloads, and Amazon Redshift Serverless for intermittent or unpredictable workloads.
- Use data sharing and multi-data-warehouse writes to isolate workloads while collaborating on shared data, rather than copying datasets between warehouses.
- Prefer zero-ETL integrations and auto-copy over hand-built pipelines to reduce operational overhead for data movement.
Relationship between Amazon Redshift Provisioned (RA3) and Amazon Redshift Serverless
Amazon Redshift is available in two deployment shapes that share the same SQL engine, Amazon Redshift Managed Storage, and ecosystem integrations. Provisioned clusters (built on RA3 node types) give you explicit control over the number and size of nodes and support capabilities such as Multi-AZ for RA3 and reserved-node pricing, which suits steady, predictable workloads where you want to manage capacity directly. Amazon Redshift Serverless removes cluster management entirely: capacity is expressed in Redshift Processing Units (RPUs), scales automatically with AI-driven scaling and optimization, and is billed per second, which suits intermittent, spiky, or unpredictable workloads. Both shapes can participate in data sharing, zero-ETL integrations, streaming ingestion, Redshift Spectrum, and Redshift ML, so teams often combine them, for example a provisioned warehouse for production reporting and a serverless workgroup for ad hoc analytics.Amazon Redshift Integration with AWS Services
Amazon Redshift integrates with many other AWS services across storage, data movement, security, machine learning, and analytics:- Storage and data lake: Amazon S3 (Spectrum, UNLOAD/COPY, auto-copy), AWS Glue Data Catalog, AWS Lake Formation, Amazon S3 Tables, and Apache Iceberg.
- Data movement and streaming: zero-ETL integrations with Amazon Aurora, Amazon RDS, and Amazon DynamoDB; streaming ingestion from Amazon Kinesis Data Streams and Amazon MSK; AWS Glue and AWS Database Migration Service.
- Security and identity: AWS KMS, Amazon VPC, AWS IAM, AWS Secrets Manager, and AWS Lake Formation.
- Machine learning and AI: Amazon SageMaker (Redshift ML and SageMaker Lakehouse / Unified Studio), Amazon Bedrock, and Amazon Q.
- Analytics and BI: Amazon QuickSight, Amazon Athena, Amazon EMR, and Apache Spark via the Amazon Redshift integration for Apache Spark.
- Compute and operations: AWS Lambda (via the Data API), Amazon CloudWatch, and AWS CloudTrail.
Frequently Asked Questions about Amazon Redshift History
When was Amazon Redshift announced and when did it reach GA?
Amazon Redshift was announced as a limited preview at AWS re:Invent on November 28, 2012, and it became generally available on February 15, 2013.When did Redshift Spectrum launch?
Amazon Redshift Spectrum launched on April 19, 2017. It lets a Redshift cluster run SQL queries directly against data in Amazon S3 with no loading or ETL, and it was an early step toward separating storage and compute.When did RA3 nodes launch?
Amazon Redshift announced RA3 nodes with managed storage on December 3, 2019, starting with ra3.16xlarge. RA3 separates compute from Amazon Redshift Managed Storage, which caches hot data on local SSD and tiers colder data to Amazon S3, so compute and storage scale independently.When did Amazon Redshift Serverless become GA?
Amazon Redshift Serverless was announced in preview at re:Invent on November 30, 2021, and it became generally available on July 12, 2022. Serverless introduced namespaces and workgroups, with capacity measured in Redshift Processing Units (RPUs) that scale automatically.When did zero-ETL integrations launch?
The Amazon Aurora MySQL zero-ETL integration with Amazon Redshift became generally available on November 7, 2023. Amazon RDS for MySQL followed on September 12, 2024, and the Amazon Aurora PostgreSQL and Amazon DynamoDB zero-ETL integrations became generally available on October 15, 2024.When did Streaming Ingestion launch?
Amazon Redshift streaming ingestion for Amazon Kinesis Data Streams and Amazon Managed Streaming for Apache Kafka (Amazon MSK) became generally available on November 29, 2022. It ingests streaming data directly into materialized views using SQL, without first staging the data in Amazon S3.How does Amazon Redshift relate to Amazon SageMaker Lakehouse and Amazon SageMaker Unified Studio?
At re:Invent 2024 (December 3, 2024), AWS announced Amazon SageMaker Lakehouse, which unifies data across Amazon S3 data lakes and Amazon Redshift data warehouses under Apache Iceberg-compatible access, and Amazon SageMaker Unified Studio in preview, which brings data, analytics, and AI tooling, including Redshift SQL analytics, into one experience. Amazon SageMaker Unified Studio became generally available on March 13, 2025. In this model, Amazon Redshift is the data warehouse engine within a broader, unified lakehouse and AI platform.References:
Tech Blog with curated related content
Amazon Redshift (Service Page)
AWS Documentation (Amazon Redshift Management Guide)
AWS Documentation (Document History for Amazon Redshift)
AWS Data Lakehouse Architecture Guide
AWS Database Glossary
Generative BI and NL2SQL agent architecture on AWS
Comparison of AWS Databases Using the Quorum Model
Summary
In this article, I created a historical timeline of Amazon Redshift and looked at the list of features and overview of Amazon Redshift.Since its announcement as a limited preview in November 2012 and its general availability in February 2013, Amazon Redshift has been the first data warehouse built for the cloud, using a massively parallel processing architecture and columnar storage to deliver fast SQL analytics at scale.
Amazon Redshift has continued to expand through Redshift Spectrum, RA3 nodes with managed storage, Amazon Redshift Serverless, data sharing and multi-data-warehouse writes, zero-ETL integrations, streaming ingestion, Amazon Redshift ML, Amazon Q generative SQL, Apache Iceberg read and write support, and integration with Amazon SageMaker Lakehouse and Amazon SageMaker Unified Studio. Together these capabilities have steadily blurred the boundary between the data warehouse and the data lake while bringing machine learning and generative AI into SQL analytics.
I would like to continue monitoring the trends of what kind of features Amazon Redshift will provide in the future.
This timeline will be updated as Amazon Redshift continues to evolve.
In addition, there is also a historical timeline of all AWS services including services other than Amazon Redshift, as well as related timelines for other databases, so please have a look if you are interested.
AWS History and Timeline - Almost All AWS Services List, Announcements, General Availability(GA)
AWS History and Timeline regarding Amazon DynamoDB - Overview, Functions, Features, Summary of Updates, and Introduction
AWS History and Timeline regarding Amazon Aurora - Overview, Engines, Features, Summary of Updates, and Introduction
AWS History and Timeline regarding Amazon RDS - Overview, Engines, Features, Summary of Updates, and Introduction
References:
Tech Blog with curated related content
Written by Hidekazu Konishi