AWS History and Timeline regarding Amazon Aurora - Overview, Engines, Features, Summary of Updates, and Introduction
First Published:
Last Updated:
This time, I have created a historical timeline for Amazon Aurora, the cloud-native relational database engine that AWS purpose-built for the cloud and announced at re:Invent in November 2014. Amazon Aurora separates database compute from a distributed, log-structured storage layer that automatically replicates data six ways across three Availability Zones, and it is offered in MySQL-compatible and PostgreSQL-compatible editions.
Over the years, Amazon Aurora has grown well beyond a single engine into a family that includes Aurora Serverless v1 and v2, Aurora Global Database, Babelfish for Aurora PostgreSQL, Aurora I/O-Optimized, Aurora Optimized Reads, zero-ETL integrations, Aurora Limitless Database, and the separately branded Amazon Aurora DSQL.
Just like before, I am summarizing the main features while following the birth of Amazon Aurora and tracking its feature additions and updates as a Current Overview, Functions, Features of Amazon Aurora.
This article focuses on representative service-level milestones (announcements, previews, general availability, and major capabilities), not on every minor engine version or single-region expansion. I hope these will provide clues as to what has remained the same and what has changed in Amazon Aurora and the engines it is compatible with.
Because Amazon Aurora is offered through the Amazon RDS API, this timeline is intended to be read alongside the Amazon RDS timeline and the Amazon DynamoDB timeline, forming a three-part view of the history of databases on AWS.
Background and Method of Creating Amazon Aurora Historical Timeline
The reason for creating a historical timeline of Amazon Aurora this time is that Aurora has now been generally available for around a decade, has expanded from a single MySQL-compatible engine into a broad family of editions and deployment options, and sits at the center of many of the most demanding relational workloads running on AWS.Another reason is that since the announcement of Amazon Aurora in November 2014, AWS has steadily added compatibility editions (MySQL, then PostgreSQL), new deployment shapes (Serverless v1 and v2, Global Database, Limitless Database), and operational and analytical capabilities (Backtrack, Parallel Query, Optimized Reads, I/O-Optimized, Babelfish, zero-ETL integrations, and more). Therefore, I wanted to organize the information of Amazon Aurora with the following approaches.
- Tracking the history of Amazon Aurora and organizing the transition of updates
- Summarizing the feature list and characteristics of Amazon Aurora and its engines
There may be slight variations in the dates on the timeline due to differences in the timing of announcements or article postings in the references used.
The content posted is limited to major features related to the current Amazon Aurora and necessary for the feature list and overview description.
In other words, please note that the items on this timeline are not all updates to Amazon Aurora features, but are representative updates that I have picked out.
Amazon Aurora was first introduced as a MySQL-compatible engine at re:Invent 2014 (Amazon Aurora - New Cost-Effective MySQL-Compatible Database Engine for Amazon RDS), and the MySQL-compatible edition became generally available in July 2015 (Now Available - Amazon Aurora).
Amazon Aurora Historical Timeline (Updates from November 12, 2014)
Now, here is a timeline related to the functions of Amazon Aurora. As of the time of writing this article, the history of Amazon Aurora spans more than a decade since its announcement in November 2014.2014 | 2015 | 2016 | 2017 | 2018 | 2019 | 2020 | 2021 | 2022 | 2023 | 2024 | 2025 | 2026
* The table can be sorted by clicking on the column names.| Date | Summary |
|---|---|
| 2014-11-12 | Amazon Aurora is announced at AWS re:Invent 2014. Aurora is introduced as a new MySQL-compatible relational database engine purpose-built for the cloud, combining the performance and availability of commercial databases with the cost-effectiveness of open source. Its distributed storage layer automatically replicates data six ways across three Availability Zones. References: Amazon Aurora - New Cost-Effective MySQL-Compatible Database Engine for Amazon RDS |
| 2015-07-27 | Amazon Aurora (MySQL-compatible) becomes Generally Available (GA). The initial release is MySQL 5.6-compatible, supports up to 15 low-latency Aurora Replicas over the shared storage volume, and provides storage that automatically grows in increments up to 64 TB. References: Now Available - Amazon Aurora |
| 2015-12-07 | Encryption at rest for Amazon Aurora is announced. Aurora clusters, automated backups, snapshots, and replicas can be encrypted using AWS KMS with AES-256 encryption. References: New - Encryption at Rest for Amazon Aurora |
| 2016-06-01 | Amazon Aurora adds cross-region read replicas. A read replica of an Aurora MySQL cluster can be created in a different AWS Region for low-latency reads for globally distributed users and for cross-region disaster recovery. References: Amazon Aurora Now Supports Cross-Region Read Replicas |
| 2016-09-08 | Amazon Aurora introduces a cluster reader endpoint. A single reader endpoint load-balances read connections across all Aurora Replicas in a cluster, simplifying application configuration and transparently scaling read capacity as replicas are added or removed. References: Reader Endpoint for Amazon Aurora |
| 2016-11-30 | Amazon Aurora announces PostgreSQL compatibility in preview. AWS previews a PostgreSQL-compatible edition of Aurora at re:Invent 2016, bringing Aurora's distributed storage architecture to PostgreSQL workloads. References: Announcing PostgreSQL Compatibility for Amazon Aurora |
| 2017-03-07 | Amazon Aurora adds encryption support for globally distributed deployments. Encrypted Aurora databases can be replicated across AWS Regions, and encrypted snapshots can be copied across Regions, enabling secure cross-region disaster recovery. References: Amazon Aurora Announces Encryption Support for Globally Distributed Database Deployments |
| 2017-04-24 | IAM database authentication for Amazon Aurora MySQL is announced. Database connections can authenticate using AWS IAM users and roles with short-lived tokens, removing the need to store long-lived database passwords in application configuration. References: Manage Access to Your Amazon RDS for MySQL and Amazon Aurora Databases Using AWS IAM |
| 2017-08-29 | Amazon Aurora supports fast database cloning. Using a copy-on-write protocol on the shared storage layer, a multi-terabyte Aurora cluster can be cloned in minutes without copying the data, which is useful for testing, development, and running analytical queries on production-like data. References: Amazon Aurora Supports Fast Database Cloning |
| 2017-10-24 | Amazon Aurora PostgreSQL-compatible edition becomes Generally Available (GA). The initial release is PostgreSQL 9.6-compatible and introduces Performance Insights for database load monitoring. References: Announcing General Availability of Amazon Aurora with PostgreSQL Compatibility |
| 2017-11-29 | Amazon Aurora Multi-Master is announced in preview. Multi-Master allows multiple read/write instances across Availability Zones for continuous write availability (Aurora MySQL). This feature was later discontinued as of February 28, 2023. References: Sign Up for the Preview of Amazon Aurora Multi-Master |
| 2017-11-29 | Amazon Aurora Serverless v1 is previewed at re:Invent 2017. Aurora Serverless v1 is an on-demand configuration that automatically starts, scales, and stops the database based on application needs, with per-second billing (Aurora MySQL). References: In the Works - Amazon Aurora Serverless |
| 2018-02-06 | The MySQL 5.7-compatible edition of Amazon Aurora becomes Generally Available (GA). The release adds JSON support, spatial indexes, and generated columns to Aurora MySQL. References: Amazon Aurora is Compatible with MySQL 5.7 |
| 2018-05-10 | Amazon Aurora Backtrack is released for Aurora MySQL. Backtrack rewinds an Aurora cluster in place to a prior point in time (within a configurable window of up to 72 hours) in seconds, without restoring data from a snapshot. References: Amazon Aurora Backtrack - Turn Back Time |
| 2018-08-09 | Amazon Aurora Serverless v1 becomes Generally Available (GA) for Aurora MySQL. Aurora Serverless v1 automatically scales compute capacity up and down and pauses when idle for intermittent or unpredictable workloads. References: Amazon Aurora Serverless Brings Serverless Computing to Relational Databases |
| 2018-09-20 | Amazon Aurora Parallel Query becomes Generally Available (GA) for Aurora MySQL. Parallel Query pushes the processing of analytical queries down into the Aurora distributed storage layer to accelerate analytics over transactional data. References: Amazon Aurora Parallel Query is Generally Available |
| 2018-11-27 | Amazon Aurora Global Database is announced. Aurora Global Database lets a single Aurora cluster span multiple AWS Regions using storage-based replication with typically sub-second lag, with fast cross-region failover for disaster recovery (initially Aurora MySQL). References: Announcing Amazon Aurora Global Database |
| 2019-05-30 | The Data API for Amazon Aurora Serverless is launched. The Data API exposes a secure HTTP endpoint for running SQL statements against Aurora Serverless v1 (MySQL-compatible) without managing persistent database connections, making it well suited to AWS Lambda and other serverless callers. References: New Data API for Amazon Aurora Serverless |
| 2019-07-09 | Amazon Aurora Serverless v1 becomes available for Aurora PostgreSQL. The automatic start, stop, and scaling model of Aurora Serverless v1 is extended to PostgreSQL-compatible Aurora. References: Amazon Aurora with PostgreSQL Compatibility Supports Serverless |
| 2019-08-08 | Amazon Aurora Multi-Master becomes Generally Available (GA) for Aurora MySQL. Multi-Master provides multiple read/write instances across Availability Zones for continuous write availability. (Aurora Multi-Master was later discontinued as of February 28, 2023.) References: Amazon Aurora Multi-Master is Now Generally Available |
| 2019-11-26 | Amazon Aurora Machine Learning integration is announced. Aurora MySQL can call Amazon SageMaker and Amazon Comprehend directly from SQL for low-latency ML inference such as fraud detection and sentiment analysis. References: Amazon Aurora Supports Machine Learning Directly from the Database |
| 2019-11-26 | Amazon Aurora Global Database expands to support up to five secondary Regions. A single Aurora Global Database can now add as many as five secondary Regions for broader geographic read scaling and multi-region disaster recovery. References: Amazon Aurora Global Database Supports Multiple Secondary Regions |
| 2020-03-10 | Amazon Aurora Global Database becomes available for Aurora PostgreSQL. Cross-region storage-based replication with sub-second lag and fast disaster recovery is extended to the PostgreSQL-compatible edition. References: Amazon Aurora with PostgreSQL Compatibility Supports Amazon Aurora Global Database |
| 2020-06-03 | Database Activity Streams becomes available for Amazon Aurora MySQL. Database Activity Streams delivers a near real-time, protected stream of database activity to Amazon Kinesis for auditing and compliance, extending to Aurora MySQL a capability previously offered for Aurora PostgreSQL. References: Database Activity Streams now available for Aurora with MySQL compatibility |
| 2020-06-19 | Amazon Aurora Global Database adds write forwarding for Aurora MySQL. Applications connected to a secondary Region reader can issue writes that are transparently forwarded to the primary Region writer, removing the need to manage a separate write path (write forwarding later came to Aurora PostgreSQL in 2023). References: Amazon Aurora Global Database supports read replica write forwarding |
| 2020-06-30 | Amazon RDS Proxy becomes Generally Available for Amazon Aurora. RDS Proxy is a fully managed, highly available database proxy that pools and shares connections to Aurora MySQL- and Aurora PostgreSQL-compatible clusters (as well as Amazon RDS for MySQL and PostgreSQL), helping serverless and high-concurrency applications avoid exhausting database connections and reducing client recovery time after failover. It integrates with AWS Secrets Manager and AWS IAM for connection authentication. References: Amazon RDS Proxy is now generally available |
| 2020-09-24 | Amazon Aurora increases the maximum storage size to 128 TiB. The cluster volume limit doubles from 64 TB to 128 TiB for both the MySQL- and PostgreSQL-compatible editions, with storage continuing to scale automatically in fixed increments as data grows. References: Amazon Aurora Increases Maximum Storage Size to 128TB |
| 2020-12-01 | Amazon Aurora Serverless v2 is previewed at re:Invent 2020. Aurora Serverless v2 introduces instant, fine-grained, non-disruptive scaling and adds support for Multi-AZ deployments, Aurora Global Database, and read replicas that Serverless v1 lacked (initially for the Aurora MySQL 5.7-compatible edition). References: Introducing the Next Version of Amazon Aurora Serverless in Preview |
| 2020-12-01 | Babelfish for Aurora PostgreSQL is announced in preview at re:Invent 2020. Babelfish enables Aurora PostgreSQL to understand Microsoft SQL Server's TDS wire protocol and T-SQL dialect, allowing many SQL Server applications to run on Aurora PostgreSQL with minimal code changes. References: Babelfish for Amazon Aurora PostgreSQL Available in Preview |
| 2021-02-11 | Amazon Aurora Global Database adds managed planned failover. A managed cross-region failover can promote a secondary Region to primary without data loss while preserving the global database topology, simplifying planned regional maintenance. References: Amazon Aurora Global Database Supports Managed Planned Failover |
| 2021-03-12 | Amazon Aurora adds support for AWS Graviton2-based R6g instances. Both the Aurora MySQL- and PostgreSQL-compatible editions can run on Arm-based Graviton2 R6g database instances, which AWS positioned as delivering up to 35% better price/performance than comparable x86 instances. References: Achieve up to 35% better price/performance with Amazon Aurora using new Graviton2 instances |
| 2021-10-28 | Babelfish for Aurora PostgreSQL becomes Generally Available (GA). The Microsoft SQL Server TDS and T-SQL compatibility layer becomes generally available, letting SQL Server clients connect to Aurora PostgreSQL without rewriting most queries. References: Babelfish for Aurora PostgreSQL is Now Generally Available |
| 2021-11-18 | Amazon Aurora MySQL version 3 (MySQL 8.0-compatible) becomes Generally Available (GA). Aurora MySQL 8.0 compatibility adds features such as instant DDL, window functions, common table expressions, and JSON improvements. References: Amazon Aurora MySQL Supports MySQL 8.0 |
| 2022-04-21 | Amazon Aurora Serverless v2 becomes Generally Available (GA). Serverless v2 supports both Aurora MySQL- and Aurora PostgreSQL-compatible editions with instant, non-disruptive, fine-grained scaling in 0.5 ACU increments. References: Amazon Aurora Serverless v2 is Generally Available |
| 2022-11-27 | Amazon RDS Blue/Green Deployments is announced with support for Aurora MySQL. Blue/Green Deployments create a synchronized staging (green) environment of a production (blue) database and enable a fast, low-downtime cutover for upgrades and changes. References: Amazon RDS Blue/Green Deployments for Safer, Simpler, and Faster Updates |
| 2022-11-29 | Amazon Aurora zero-ETL integration with Amazon Redshift is announced. The integration makes transactional data written to Aurora available in Amazon Redshift within seconds for near real-time analytics and machine learning, without building custom ETL pipelines. References: Amazon Aurora zero-ETL Integration with Amazon Redshift |
| 2023-05-11 | Amazon Aurora I/O-Optimized becomes Generally Available (GA). This cluster configuration removes per-I/O charges in exchange for higher instance and storage rates, providing more predictable pricing and savings for I/O-intensive workloads. References: Amazon Aurora I/O-Optimized |
| 2023-05-11 | Amazon Aurora adds support for AWS Graviton3-based R7g instances. Both the Aurora MySQL- and PostgreSQL-compatible editions can run on Arm-based Graviton3 R7g database instances, building on the earlier Graviton2 R6g support with DDR5 memory and improved price/performance for memory-intensive database workloads. References: Amazon Aurora MySQL and PostgreSQL support for Graviton3 based R7g instance family |
| 2023-09-01 | Amazon RDS Extended Support is announced for Amazon Aurora. Extended Support lets Aurora MySQL- and PostgreSQL-compatible clusters keep running on a major engine version for up to three additional years past the end of community standard support, giving teams more time to plan major-version upgrades. References: Amazon Aurora and Amazon RDS announces Extended Support for MySQL and PostgreSQL databases |
| 2023-10-24 | Amazon Aurora PostgreSQL adds pgvector 0.5.0 with HNSW indexing. Hierarchical Navigable Small World (HNSW) indexing enables low-latency approximate nearest-neighbor vector similarity search, making Aurora PostgreSQL a vector store for generative AI and retrieval-augmented generation (RAG). References: Amazon Aurora PostgreSQL Supports pgvector 0.5.0 with HNSW Indexing |
| 2023-10-26 | Amazon RDS Blue/Green Deployments adds support for Aurora PostgreSQL. Low-downtime cutover for major and minor version upgrades, schema changes, and parameter changes is extended to the PostgreSQL-compatible edition. References: Amazon RDS Blue/Green Deployments for Aurora PostgreSQL and RDS for PostgreSQL |
| 2023-11-07 | Amazon Aurora MySQL zero-ETL integration with Amazon Redshift becomes Generally Available (GA). Near real-time replication of Aurora MySQL transactional data to Amazon Redshift is now generally available. References: Amazon Aurora MySQL zero-ETL Integration with Amazon Redshift is Generally Available |
| 2023-11-08 | Amazon Aurora Optimized Reads for Aurora PostgreSQL is announced. Optimized Reads uses local NVMe SSD storage on r6gd and r6id instances as a tiered cache for pages evicted from memory, improving query latency for datasets larger than instance memory, including pgvector similarity search. References: Amazon Aurora PostgreSQL Optimized Reads |
| 2023-11-09 | Amazon Aurora Global Database for PostgreSQL adds write forwarding. Applications connected to a secondary Region reader can forward writes to the primary Region writer, a capability previously available only for Aurora MySQL. References: Amazon Aurora Global Database for PostgreSQL Supports Write Forwarding |
| 2023-11-27 | Amazon Aurora Limitless Database is previewed at re:Invent 2023. Limitless Database scales Aurora PostgreSQL write throughput beyond a single writer through automatic sharding across multiple Aurora Serverless instances, presented as a single database endpoint. References: Amazon Aurora Limitless Database (Preview) |
| 2023-12-21 | A redesigned Amazon RDS Data API launches for Aurora Serverless v2 and Aurora provisioned (PostgreSQL-compatible). The rebuilt Data API removes the request-rate limits of the original Serverless v1 Data API and adds support for Aurora Serverless v2 and provisioned Aurora PostgreSQL clusters, enabling connection-free SQL access at higher scale. References: Amazon Aurora PostgreSQL now supports RDS Data API |
| 2024-01-31 | Amazon Aurora PostgreSQL adds support for PostgreSQL 16. Aurora PostgreSQL-Compatible Edition supports PostgreSQL major version 16, adding SQL/JSON constructors, more query parallelism, and the pg_stat_io statistics view. References: Amazon Aurora PostgreSQL-Compatible Edition Supports PostgreSQL 16 |
| 2024-09-30 | The Amazon RDS Data API expands to Aurora MySQL. The redesigned RDS Data API adds support for Aurora MySQL-compatible Serverless v2 and provisioned clusters, bringing connection-free HTTP SQL access to parity across the Aurora MySQL and PostgreSQL editions. References: Amazon Aurora MySQL now supports RDS Data API |
| 2024-10-03 | Amazon Aurora Serverless v2 increases maximum capacity to 256 ACUs. The maximum scale of Aurora Serverless v2 doubles from 128 ACUs (256 GiB) to 256 ACUs (512 GiB) for larger, more demanding serverless workloads. References: Amazon Aurora Serverless v2 Supports Up to 256 ACUs |
| 2024-10-15 | Amazon Aurora PostgreSQL zero-ETL integration with Amazon Redshift becomes Generally Available (GA). Near real-time analytics from Aurora PostgreSQL to Amazon Redshift is now generally available, with data filtering and AWS CloudFormation support. References: Amazon Aurora PostgreSQL zero-ETL Integration with Amazon Redshift is Generally Available |
| 2024-10-22 | Amazon Aurora Global Database adds a global writer endpoint. A single global writer endpoint automatically routes writes to the current primary Region and follows the primary after a managed planned failover or switchover, so applications no longer need to be reconfigured when the primary Region changes. References: Amazon Aurora launches Global Database writer endpoint |
| 2024-10-31 | Amazon Aurora PostgreSQL Limitless Database becomes Generally Available (GA). Limitless Database launches with PostgreSQL 16.4 compatibility in select Regions, enabling horizontal write scale-out to millions of transactions per second and petabyte-scale storage through automatic sharding. References: Amazon Aurora PostgreSQL Limitless Database is Generally Available |
| 2024-11-20 | Amazon Aurora Serverless v2 adds support for scaling to 0 ACUs. Serverless v2 can automatically pause to 0 ACUs after a period of inactivity, eliminating the previous 0.5 ACU minimum during idle periods, and resumes automatically on the first connection. References: Amazon Aurora Serverless v2 Supports Scaling to Zero Capacity |
| 2024-12-03 | Amazon Aurora DSQL is previewed at re:Invent 2024. Aurora DSQL is a new serverless, distributed SQL database with PostgreSQL compatibility and an active-active multi-Region architecture designed for high availability, strong consistency, and virtually unlimited horizontal scaling. References: Amazon Aurora DSQL (Preview) |
| 2025-05-01 | Amazon Aurora PostgreSQL adds support for PostgreSQL 17. Aurora PostgreSQL-Compatible Edition supports PostgreSQL major version 17 (initially 17.4), tracking the latest community PostgreSQL release with its performance and SQL/JSON improvements. References: Amazon Aurora PostgreSQL Compatible Edition supports PostgreSQL major version 17 |
| 2025-05-27 | Amazon Aurora DSQL becomes Generally Available (GA). With GA, Aurora DSQL adds support for AWS Backup, AWS PrivateLink, AWS CloudFormation, AWS CloudTrail, AWS KMS customer managed keys, and PostgreSQL views, and launches in several AWS Regions. References: Amazon Aurora DSQL is Now Generally Available |
| 2025-07-03 | Amazon Aurora PostgreSQL increases the maximum storage size to 256 TiB. The cluster volume limit doubles from 128 TiB to 256 TiB for the PostgreSQL-compatible edition on recent engine versions, with storage scaling automatically and customers paying only for the storage they use. References: Amazon Aurora PostgreSQL Database Clusters Now Support up to 256 TiB of Storage Volume |
| 2025-07-17 | Amazon OpenSearch Service zero-ETL integration with Amazon Aurora becomes available. The integration continuously synchronizes data from Aurora MySQL and Aurora PostgreSQL into Amazon OpenSearch Service within seconds using OpenSearch Ingestion change data capture, enabling full-text, fuzzy, and vector search over relational data without building custom pipelines. References: Amazon OpenSearch Service now supports integration with Amazon Aurora MySQL and PostgreSQL |
| 2025-07-30 | Amazon Aurora MySQL increases the maximum storage size to 256 TiB. The cluster volume limit doubles from 128 TiB to 256 TiB for the MySQL-compatible edition on Aurora MySQL version 3.10 (MySQL 8.0.42-compatible) and later, matching the increase delivered for Aurora PostgreSQL earlier the same month. References: Amazon Aurora MySQL database clusters now support up to 256 TiB of storage volume |
| 2026-05-21 | Amazon Aurora MySQL 8.4 (the first MySQL LTS) becomes Generally Available. Aurora MySQL 8.4 aligns Aurora MySQL major versioning with the community MySQL Long-Term Support (LTS) release line (using version numbers such as 8.4.x) and strengthens default security, enforcing TLS 1.2/1.3 and the caching_sha2_password authentication plugin for new clusters. References: Amazon Aurora MySQL 8.4 is now generally available |
Current Overview, Functions, Features of Amazon Aurora
From here, I will explain in more detail the main features of the current Amazon Aurora.Amazon Aurora is a fully managed relational database engine that AWS designed specifically for the cloud. It is offered through the Amazon RDS API, but its architecture differs significantly from the traditional Amazon RDS engines: instead of attaching a local storage volume to a single instance, Aurora separates the database compute instances from a purpose-built, log-structured, distributed storage layer that is shared by the writer and its read replicas, and that automatically replicates data six ways across three Availability Zones.
Amazon Aurora is offered in two compatibility editions, Aurora MySQL-Compatible Edition and Aurora PostgreSQL-Compatible Edition, and in several deployment and scaling shapes including provisioned instances, Aurora Serverless v2, Aurora Global Database, and Aurora Limitless Database. Amazon Aurora DSQL is a separately branded, distributed SQL database in the Aurora family and is discussed at the end of this section.
Amazon Aurora Use Cases
Amazon Aurora is used across a wide range of relational workloads on AWS. The main use cases include the following:- High-Performance Web and Mobile Application Backends
Hosting transactional databases that need higher performance and availability than self-managed MySQL or PostgreSQL, with up to 15 Aurora Replicas for read scaling and fast failover. - SaaS Multi-Tenant Backends
Hosting per-tenant or shared-tenant databases for SaaS providers using Aurora's read scaling, fast failover, and Aurora Serverless v2 for variable workloads. - Serverless and Variable Workloads
Using Amazon Aurora Serverless v2 with fine-grained autoscaling (including scaling to 0 ACUs) for spiky, intermittent, or unpredictable workloads. - Globally Distributed Reads and Disaster Recovery
Using Amazon Aurora Global Database to replicate to up to five secondary Regions with typically sub-second lag, with managed planned failover and write forwarding. - Lift-and-Shift of SQL Server Applications
Using Babelfish for Aurora PostgreSQL to run many existing Microsoft SQL Server applications on Aurora PostgreSQL without rewriting most application code. - Real-Time Analytics on Transactional Data
Using Aurora zero-ETL integration with Amazon Redshift to analyze Aurora data in near real time without managing custom data pipelines. - Generative AI and Retrieval-Augmented Generation (RAG)
Storing vector embeddings in Aurora PostgreSQL via the pgvector extension with HNSW indexing and integrating with Amazon Bedrock and Amazon SageMaker. - Very High Write Throughput and Petabyte-Scale OLTP
Using Amazon Aurora PostgreSQL Limitless Database to scale writes horizontally beyond a single writer instance through automatic sharding.
Specific Use Case Examples
- SaaS Application Backend
A multi-tenant SaaS platform runs Amazon Aurora PostgreSQL with several Aurora Replicas for read scaling and Amazon RDS Proxy to pool database connections across many AWS Lambda invocations. - Real-Time BI Dashboard
A retailer keeps Amazon Aurora MySQL as the system of record and configures zero-ETL integration with Amazon Redshift so business intelligence dashboards reflect order data within seconds of writes. - Enterprise SQL Server Migration
An enterprise lifts existing Microsoft SQL Server applications onto Amazon Aurora PostgreSQL using Babelfish, avoiding most application rewrites. - Generative AI RAG Backend
A document-search application stores vector embeddings in Amazon Aurora PostgreSQL using pgvector with HNSW indexing and queries them from an Amazon Bedrock agent. - Globally Distributed Disaster Recovery
A global service uses Amazon Aurora Global Database with managed planned failover to run regular cross-region disaster recovery drills with minimal data loss. - Cost-Efficient Internal Tooling
A spiky internal application runs on Amazon Aurora Serverless v2 that scales to 0 ACUs when idle and resumes automatically on the first connection.
Amazon Aurora Architecture: Separation of Compute and Storage
The defining characteristic of Amazon Aurora is the separation of database compute from a purpose-built, distributed storage layer. The writer instance sends redo log records (rather than full modified data pages) to the storage fleet, which materializes pages and replicates them six ways across three Availability Zones with self-healing. Up to 15 Aurora Replicas share the same storage volume, so adding a read replica does not copy the data; replicas read pages from the shared storage with replication lag typically in the low milliseconds. This design is what enables fast failover, fast replica creation, continuous backup to Amazon S3, and capabilities such as Aurora Backtrack.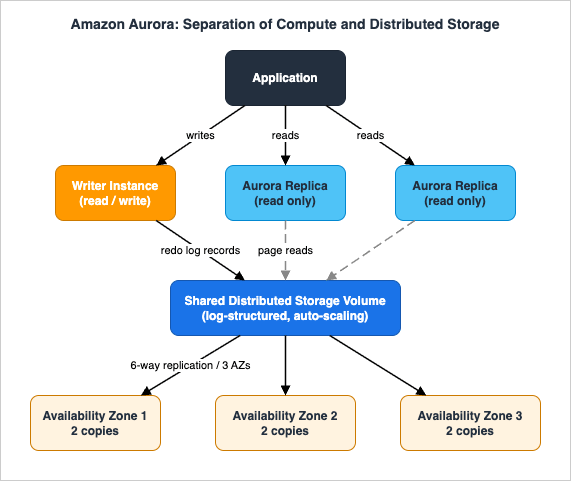
Amazon Aurora Database Engines
Amazon Aurora is offered in two compatibility editions that share the same distributed storage architecture but expose different SQL dialects and ecosystems.Aurora MySQL-Compatible Edition
- Generally available since July 2015; the initial release was MySQL 5.6-compatible.
- Became MySQL 5.7-compatible in February 2018, added MySQL 8.0 compatibility (Aurora MySQL version 3) in November 2021, and added MySQL 8.4 LTS compatibility (the first MySQL LTS, with aligned 8.4.x version numbering) in May 2026.
- Supports Aurora Backtrack for in-place rewind, Parallel Query for analytical pushdown, Aurora Machine Learning (Amazon SageMaker and Amazon Comprehend), and zero-ETL integration with Amazon Redshift.
Aurora PostgreSQL-Compatible Edition
- Previewed at re:Invent 2016 and generally available since October 2017; the initial release was PostgreSQL 9.6-compatible, and Aurora has since tracked newer major versions up to PostgreSQL 17.
- Supports Babelfish (a Microsoft SQL Server TDS/T-SQL compatibility layer), the pgvector extension with HNSW indexing for vector search, Aurora Optimized Reads (a local NVMe tiered cache), and Aurora Limitless Database.
Amazon Aurora Deployment and Scaling Options
- Aurora Provisioned: traditional always-on instance-based deployment with up to 15 Aurora Replicas per cluster.
- Aurora Serverless v1 (legacy): the original on-demand auto-scaling configuration that starts, scales, and stops automatically.
- Aurora Serverless v2 (current): fine-grained autoscaling in 0.5 ACU steps, up to 256 ACUs, including scaling to 0 ACUs; supports Multi-AZ, Global Database, read replicas, and the Amazon RDS Data API.
- Aurora Global Database: spans a primary and up to five secondary Regions with storage-based replication (typically sub-second lag), managed planned failover, and write forwarding for both MySQL and PostgreSQL.
- Aurora Limitless Database: horizontal write scale-out for Aurora PostgreSQL through automatic sharding behind a single endpoint.
Amazon Aurora Key Functions and Features
- Shared distributed storage layer with 6-way replication across 3 Availability Zones and continuous backup to Amazon S3.
- Up to 15 Aurora Replicas per cluster over the shared storage, which also serve as automatic failover targets.
- Aurora Backtrack (Aurora MySQL) for in-place rewind without restoring from a snapshot.
- Aurora Parallel Query (Aurora MySQL) for analytical pushdown into the distributed storage layer.
- Aurora Optimized Reads (Aurora PostgreSQL) using local NVMe SSD as a tiered cache and temporary table store.
- Aurora I/O-Optimized cluster configuration that removes per-I/O charges for I/O-intensive workloads.
- AWS Graviton-based DB instances (the Graviton2 R6g and Graviton3 R7g families and later) for improved price/performance on both Aurora MySQL and Aurora PostgreSQL.
- Babelfish for Aurora PostgreSQL for Microsoft SQL Server TDS/T-SQL compatibility.
- Aurora zero-ETL integration with Amazon Redshift for near real-time analytics.
- Amazon RDS Data API for connection-free SQL access from AWS Lambda and other compute.
- Amazon RDS Blue/Green Deployments for low-downtime upgrades of Aurora MySQL and Aurora PostgreSQL.
- Amazon RDS Proxy for connection pooling in front of serverless and high-concurrency applications.
- Aurora Machine Learning integration with Amazon SageMaker and Amazon Comprehend.
- Aurora PostgreSQL pgvector with HNSW indexing for generative AI and retrieval-augmented generation.
- Security and monitoring: IAM database authentication, AWS KMS encryption at rest, TLS in transit, and Performance Insights.
Amazon Aurora High Availability and Read Replicas
Amazon Aurora was designed for high availability from the ground up, and most of its availability characteristics derive from the shared distributed storage layer rather than from instance-level replication.Aurora Replicas
An Aurora cluster has one writer (primary) instance and up to 15 Aurora Replicas. Because all instances in a cluster share the same distributed storage volume, Aurora Replicas do not require a separate copy of the data and typically lag the writer by only a few milliseconds. Aurora Replicas serve read traffic through the cluster reader endpoint and double as automatic failover targets.Failover and the Cluster Endpoints
Each Aurora cluster exposes a writer (cluster) endpoint that always points to the current primary instance and a reader endpoint that load-balances connections across the Aurora Replicas. If the writer fails, Aurora promotes an existing Aurora Replica to be the new writer, and because the storage layer is shared, this failover typically completes faster than a traditional restore. Where no replica exists, Aurora recreates the writer against the same durable storage volume.Amazon Aurora Global Database
Amazon Aurora Global Database extends a cluster across AWS Regions using storage-based replication with replication lag that is typically under one second. A global database has one primary Region and up to five secondary Regions, supports managed planned failover for controlled Region rotation, and supports write forwarding so that applications in a secondary Region can send writes that are forwarded to the primary Region for both Aurora MySQL and Aurora PostgreSQL.Note on Aurora Multi-Master
Note: Aurora Multi-Master, which allowed multiple writer instances within a single Region, reached general availability for Aurora MySQL in 2019 but was discontinued as of February 28, 2023. For new designs requiring active-active writes, AWS positions Amazon Aurora DSQL (active-active across Regions) rather than the former single-Region Multi-Master.Amazon Aurora Storage, Backup, and Recovery
Shared Distributed Storage
Aurora storage is a managed, log-structured, distributed volume that automatically grows in fixed increments as data is added, up to 256 TiB per cluster on recent engine versions (the earlier limit was 128 TiB), with no manual provisioning. Data is replicated six ways across three Availability Zones, and the storage layer is self-healing: it continuously scans for and repairs errors using the redundant copies.Continuous Backup and Point-in-Time Recovery (PITR)
Aurora continuously backs up the cluster volume to Amazon S3 without affecting database performance. Within the backup retention window, point-in-time recovery can restore a new cluster to any second, which is finer-grained than the log-upload-interval recovery of the instance-based Amazon RDS engines.Aurora Backtrack
For Aurora MySQL, Aurora Backtrack rewinds the existing cluster in place to a previous point in time within a configurable window of up to 72 hours, without creating a new cluster from a snapshot. It is well suited to quickly recovering from an erroneous data change such as an accidental bulk delete.Snapshots and Database Cloning
Manual snapshots are retained until explicitly deleted and can be copied across Regions and shared across AWS accounts for migration and disaster recovery. Aurora also supports fast database cloning, which uses a copy-on-write protocol on the shared storage to create a new writable cluster almost instantly without duplicating the data, which is useful for testing and analytics on production-like data.Amazon Aurora Security
Network Isolation
Aurora clusters run inside an Amazon VPC, and inbound and outbound database traffic is controlled by VPC security groups. Connectivity from on-premises environments can be established through AWS Direct Connect or AWS Site-to-Site VPN, and Aurora DSQL additionally supports AWS PrivateLink.IAM and Access Management
AWS IAM controls API-level access to Aurora resources such as creating, modifying, and deleting clusters and instances. For data-plane access, IAM database authentication issues short-lived tokens for Aurora MySQL and Aurora PostgreSQL, removing the need to store long-lived database passwords in application configuration.Encryption at Rest and in Transit
Aurora uses AWS KMS to encrypt data at rest with AES-256, covering the cluster volume, automated backups, snapshots, and replicas. Encryption can be enabled at creation, and existing unencrypted clusters can be encrypted by snapshot copy. All Aurora engines support TLS/SSL connections for encryption in transit.Database Activity Streams and Secrets Manager
Database Activity Streams provide a near real-time stream of database activity to Amazon Kinesis for Aurora MySQL and Aurora PostgreSQL, supporting audit and compliance use cases. Aurora also integrates with AWS Secrets Manager for managed master user password storage and automatic rotation, so credentials do not need to be embedded in application code.Amazon Aurora Monitoring
Amazon CloudWatch Metrics
Aurora automatically publishes metrics for CPU utilization, freeable memory, volume read/write IOPS, throughput, replication lag, connection count, and many more to Amazon CloudWatch, where they can drive dashboards and alarms.Enhanced Monitoring
Enhanced Monitoring streams operating-system-level metrics at up to one-second granularity to Amazon CloudWatch Logs, which is useful for diagnosing CPU, memory, and process pressure that is not visible from the database layer alone.Performance Insights
Performance Insights visualizes database load by SQL statement, wait event, user, and host for Aurora MySQL and Aurora PostgreSQL, with optional long-term retention, helping to identify the queries and wait events that dominate database load.Amazon DevOps Guru for RDS
Amazon DevOps Guru for RDS applies machine learning to Performance Insights and other telemetry to detect performance anomalies in Aurora and Amazon RDS databases and to suggest likely root causes and remediation.Amazon Aurora Integration with AWS Services
Amazon Aurora integrates with many other AWS services across networking, identity, encryption, observability, analytics, machine learning, data movement, compute, and backup:- Networking: Amazon VPC, AWS PrivateLink, AWS Direct Connect, AWS Site-to-Site VPN.
- Identity: AWS IAM, AWS Secrets Manager, AWS IAM Identity Center (for console federation).
- Encryption: AWS KMS for at-rest encryption, including customer managed keys.
- Observability: Amazon CloudWatch, AWS CloudTrail, Amazon DevOps Guru, AWS X-Ray (for application-side tracing).
- Analytics and Search: Amazon Redshift (zero-ETL integration), Amazon OpenSearch Service (zero-ETL integration for full-text and vector search), Amazon Athena Federated Query, Amazon QuickSight.
- Machine Learning: Amazon SageMaker and Amazon Comprehend (via Aurora Machine Learning), and Amazon Bedrock (via Aurora PostgreSQL pgvector for retrieval-augmented generation).
- Data Movement: AWS Database Migration Service (DMS), AWS Schema Conversion Tool (SCT), AWS Glue.
- Compute: AWS Lambda (with Amazon RDS Proxy or the RDS Data API), Amazon EC2, Amazon ECS, Amazon EKS, AWS Fargate.
- Backup: AWS Backup with cross-region and cross-account copy.
Amazon Aurora Best Practices
Performance
- Use Amazon Aurora I/O-Optimized for I/O-intensive workloads to obtain more predictable pricing without per-I/O charges.
- Use Aurora Optimized Reads on r6gd/r6id instances for Aurora PostgreSQL workloads with large temporary tables, sorts, or pgvector similarity search.
- Right-size instance classes based on Performance Insights and Amazon CloudWatch data, and use Aurora Serverless v2 for variable workloads.
- Offload read traffic to Aurora Replicas via the reader endpoint, and use Aurora Parallel Query (Aurora MySQL) for analytical queries.
Availability
- Run at least one Aurora Replica in a different Availability Zone so that automatic failover has a promotion target.
- Use Amazon Aurora Global Database for cross-region disaster recovery with sub-second replication lag, and test failover with managed planned failover.
- Place Amazon RDS Proxy in front of serverless and high-concurrency applications to absorb connection storms during failover.
Security
- Enable encryption at rest at cluster creation and use customer managed AWS KMS keys where required.
- Use IAM database authentication for short-lived credentials and store any remaining secrets in AWS Secrets Manager with managed rotation.
- Restrict inbound access with tightly scoped security groups and enable Database Activity Streams for audit logging where required.
Operations
- Use Amazon RDS Blue/Green Deployments for low-downtime major and minor version upgrades of Aurora MySQL and Aurora PostgreSQL.
- Enable Enhanced Monitoring and Performance Insights with adequate retention for diagnostic visibility.
- Use parameter groups to manage engine configuration consistently across many clusters.
- Track each engine's major-version end-of-support dates and treat Amazon RDS Extended Support only as a temporary bridge while planning major-version upgrades.
Relationship between Amazon Aurora and Amazon RDS
Amazon Aurora is offered through the Amazon RDS management API and shares many operational concepts with Amazon RDS, such as Multi-AZ deployments, snapshots, parameter groups, Amazon RDS Proxy, and Amazon RDS Blue/Green Deployments. However, Aurora's distributed storage layer, replica model, failover behavior, and serverless options differ substantially from the other Amazon RDS engines (MySQL, PostgreSQL, MariaDB, Oracle, Microsoft SQL Server, and IBM Db2). For the full history of the seven engines hosted by Amazon RDS, see the AWS History and Timeline regarding Amazon RDS. For terminology and a comparison of the quorum-based replication model that Aurora uses, see the AWS Database Glossary and the Comparison of AWS Databases Using the Quorum Model.Relationship between Amazon Aurora and Amazon Aurora DSQL
Amazon Aurora DSQL is a separate lineage within the Aurora family: a serverless, distributed SQL database with PostgreSQL compatibility and an active-active multi-Region architecture that provides strong consistency. It was previewed at re:Invent in December 2024 and became generally available in May 2025. Aurora DSQL is not the same as Aurora Serverless or the Aurora MySQL/PostgreSQL editions; rather, it is a new distributed-SQL architecture aimed at the highest levels of availability and horizontal scale, and it has its own operational and billing model.Frequently Asked Questions about Amazon Aurora History
When was Amazon Aurora announced and when did it reach GA?
Amazon Aurora was announced at re:Invent on November 12, 2014. The MySQL-compatible edition became Generally Available on July 27, 2015.When did the Amazon Aurora PostgreSQL-compatible edition launch?
Aurora PostgreSQL compatibility was previewed at re:Invent on November 30, 2016, and the PostgreSQL-compatible edition became Generally Available on October 24, 2017 (PostgreSQL 9.6-compatible initially).What is the difference between Aurora Serverless v1 and Aurora Serverless v2?
Aurora Serverless v1 (previewed at re:Invent 2017 and generally available for Aurora MySQL in August 2018) scales capacity by doubling and is best suited to intermittent workloads. Aurora Serverless v2 (previewed at re:Invent 2020 and generally available on April 21, 2022) scales in fine-grained 0.5 ACU steps, supports Multi-AZ, Global Database, and read replicas, and can scale to 0 ACUs.When did Amazon Aurora Global Database launch?
Amazon Aurora Global Database was announced on November 27, 2018 for Aurora MySQL and extended to Aurora PostgreSQL on March 10, 2020. It later added support for up to five secondary Regions, managed planned failover, and write forwarding for both engines.What is Babelfish for Aurora PostgreSQL?
Babelfish for Aurora PostgreSQL is a Microsoft SQL Server TDS protocol and T-SQL dialect compatibility layer. It was previewed at re:Invent 2020 and became Generally Available on October 28, 2021, allowing many existing SQL Server applications to run on Aurora PostgreSQL with minimal code changes.What is Amazon Aurora zero-ETL integration with Amazon Redshift?
It replicates transactional data from Amazon Aurora into Amazon Redshift within seconds without building and managing ETL pipelines. It was announced in November 2022, became Generally Available for Aurora MySQL on November 7, 2023, and for Aurora PostgreSQL on October 15, 2024.What is Amazon Aurora Limitless Database?
Amazon Aurora Limitless Database provides horizontal write scale-out for Aurora PostgreSQL through automatic sharding behind a single endpoint. It was previewed at re:Invent on November 27, 2023 and became Generally Available on October 31, 2024 (PostgreSQL 16.4-compatible).How does Amazon Aurora DSQL relate to Amazon Aurora?
Amazon Aurora DSQL is a separate serverless, distributed SQL database (PostgreSQL-compatible, with active-active multi-Region writes and strong consistency) within the Aurora brand. It was previewed on December 3, 2024 and became Generally Available on May 27, 2025. It is distinct from Aurora Serverless and from the Aurora MySQL- and PostgreSQL-compatible editions.References:
Tech Blog with curated related content
AWS Documentation(What is Amazon Aurora?)
AWS Documentation(Document History for Amazon Aurora)
AWS History and Timeline regarding Amazon RDS
AWS History and Timeline regarding Amazon DynamoDB
AWS Database Glossary
Comparison of AWS Databases Using the Quorum Model
Summary
In this article, I created a historical timeline of Amazon Aurora and looked at the list of features and overview of Amazon Aurora.Since its announcement in November 2014 and the GA of its MySQL-compatible edition in July 2015, Amazon Aurora has reimagined the relational database for the cloud by separating compute from a purpose-built distributed storage layer that replicates data six ways across three Availability Zones.
Amazon Aurora has continued to expand through the PostgreSQL-compatible edition, Aurora Serverless v1 and v2, Aurora Global Database, Babelfish for Aurora PostgreSQL, Aurora I/O-Optimized, Aurora Optimized Reads, zero-ETL integrations with Amazon Redshift, Aurora Limitless Database, and most recently the separately branded Amazon Aurora DSQL. Together these features have steadily lowered the operational burden of running relational databases while enabling new patterns such as near real-time analytics, generative AI retrieval, and globally distributed SQL.
I would like to continue monitoring the trends of what kind of features Amazon Aurora will provide in the future.
This timeline will be updated as Amazon Aurora continues to evolve.
In addition, there is also a historical timeline of all AWS services including services other than Amazon Aurora, as well as related timelines for other databases, so please have a look if you are interested.
AWS History and Timeline - Almost All AWS Services List, Announcements, General Availability(GA)
AWS History and Timeline regarding Amazon RDS - Overview, Engines, Features, Summary of Updates, and Introduction
AWS History and Timeline regarding Amazon DynamoDB - Overview, Functions, Features, Summary of Updates, and Introduction
Written by Hidekazu Konishi