AWS Lambda Durable Functions Practical Guide - Checkpoint and Replay Determinism and When to Use Step Functions Instead
First Published:
Last Updated:
This guide answers the three questions that come up immediately when teams evaluate durable functions. First, how does it actually work — what checkpoint and replay mean mechanically, and what the durable operations (steps, waits, callbacks, chained invocations) do. Second, how do I satisfy the determinism requirement — the strict contract that replay imposes on your code, which is the part most implementers stumble over and the deepest section of this article. Third, when should I still use AWS Step Functions — because durable functions do not replace Step Functions, and AWS publishes an explicit decision framework that this article extends into a practical decision tree, including hybrid architectures that use both.
Everything here is based on the official AWS documentation — the AWS Lambda Developer Guide and the AWS Durable Execution SDK Developer Guide — verified as of this writing in June 2026. Lambda durable functions are a new and fast-moving feature, so verify specifics against the official documentation in the References section before depending on them. This article deliberately avoids pricing figures; durable functions add billable dimensions beyond standard Lambda charges, so review the official AWS Lambda pricing page for current details.
Quick Reference Index
- 1. Introduction
- 2. What Lambda Durable Functions Are
- 3. The Programming Model Walkthrough
- 4. Determinism Requirements: The Heart of Replay
- 5. State, Limits, and Lifecycle
- 6. Durable Functions vs Step Functions: A Decision Framework
- 7. Migration and Coexistence Patterns
- 8. Observability and Testing
- 9. Common Pitfalls
- 10. Frequently Asked Questions
- 11. Summary
- 12. References
1. Introduction
For years, serverless developers have asked for a way to write retries, waits, and multi-step coordination as plain code inside an AWS Lambda function — without stitching together queues, schedulers, and state tables, and without leaving the programming language they already work in. The traditional answer was AWS Step Functions: move the control flow out of the function and into a state machine defined in Amazon States Language (ASL). That answer works well, but it splits one logical workflow across two artifacts — the orchestration graph and the business logic — and for tightly coupled, code-centric workflows that split is a real cost.Lambda durable functions take the other path: keep the workflow in code, and give the code workflow-grade durability. You write ordinary sequential logic; the AWS Durable Execution SDK turns selected operations into checkpoints; and Lambda manages state, retries, suspension, and resumption behind the scenes. The result occupies a genuinely new point in the AWS design space — workflow reliability with Lambda ergonomics — and it raises a genuinely new set of engineering obligations, chief among them the determinism contract that Section 4 examines in depth.
The structure of this guide follows the order in which teams actually need the material: the execution model and rollout status (Section 2), the programming model with verified code (Section 3), determinism (Section 4), configuration, limits, and lifecycle (Section 5), the Step Functions decision (Sections 6 and 7), operations and testing (Section 8), and a consolidated pitfall checklist plus FAQ (Sections 9 and 10).
2. What Lambda Durable Functions Are
2.1 The Checkpoint and Replay Execution Model
Under the hood, durable functions are regular Lambda functions that use a checkpoint/replay mechanism to track progress and support long-running operations through user-defined suspension points — a pattern commonly referred to as durable execution. The complete lifecycle of one logical run is called a durable execution, and it may span many individual Lambda invocations.The mechanism works like this:
- As your function executes, the SDK records a running log of completed durable operations (steps, waits, and others) — the checkpoint log. Each checkpoint stores the operation's identity and its result.
- When the function needs to pause (a wait, a callback, a retry backoff) or is interrupted (a crash, a timeout, an infrastructure failure), Lambda persists the checkpoint log and stops the invocation. Critically, while suspended, the function consumes no compute and the execution environment can be recycled.
- When it is time to resume, Lambda invokes the function again from the beginning. This is replay: your code runs again from the top, but every durable operation that already completed returns its stored result from the checkpoint log instead of re-executing. The function fast-forwards through completed work and continues from where it left off.
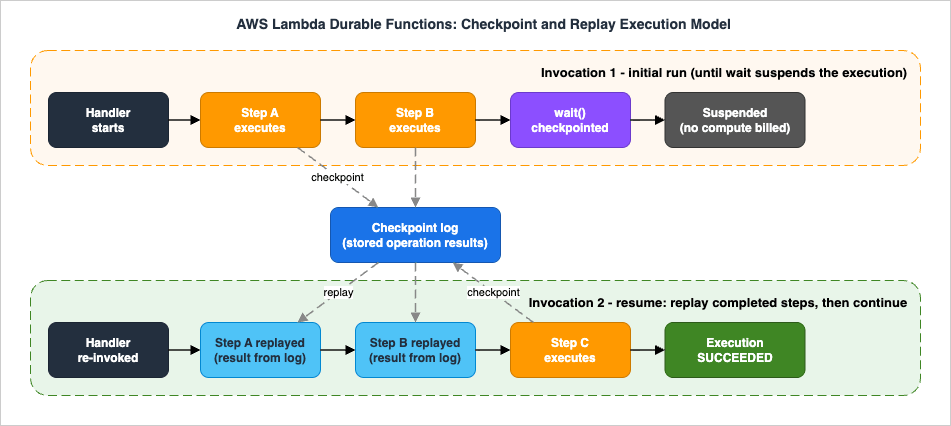
Replay is what gives durable functions their fault tolerance: a crash between step B and step C costs you nothing but a re-invocation, because steps A and B are replayed from the log rather than re-executed. It is also what imposes the determinism contract covered in Section 4 — if the code outside the durable operations takes a different path on replay than it did originally, the log no longer matches the code, and the execution breaks.
Two timeouts govern this model and it is essential to keep them apart. Each individual invocation is still bounded by the standard Lambda function timeout (up to 15 minutes). The durable execution as a whole is bounded by a separate execution timeout of up to one year. A single durable execution that runs for a month might consist of dozens of short invocations separated by long, unbilled suspensions.
2.2 The AWS Durable Execution SDK
You do not manage checkpoints directly. Lambda provides the AWS Durable Execution SDK, which exposes the checkpoint/replay machinery as simple primitives called durable operations. The SDK is available for JavaScript/TypeScript, Python, and Java, and has its own developer guide separate from the Lambda Developer Guide.With the SDK, you wrap your Lambda handler (a wrapper function in JavaScript/TypeScript, a decorator in Python, a base class in Java). The wrapped handler receives a DurableContext alongside the event, in place of the standard Lambda context. The DurableContext provides the durable operations:
- Steps execute business logic with automatic checkpointing and built-in retries.
- Waits suspend execution for a duration without incurring compute charges.
- Callbacks suspend execution until an external system responds — the foundation for human-in-the-loop workflows.
- Invoke calls another Lambda function (durable or standard) and checkpoints its result.
- Additional operations cover concurrency (parallel execution and mapping over collections via child contexts) and condition polling; see the SDK reference for the full per-language list.
2.3 Availability, Runtimes, and Rollout Status
Lambda durable functions were announced at AWS re:Invent in December 2025, initially available in the US East (Ohio) Region. AWS expanded availability quickly:- December 2025: 14 additional Regions, including US East (N. Virginia), US West (Oregon), Europe (Ireland, Frankfurt, Milan, Stockholm, Spain), and Asia Pacific (Tokyo, Singapore, Sydney, Mumbai, Hong Kong, Malaysia, Thailand).
- April 2026: 16 additional Regions, including Asia Pacific (Osaka, Seoul, Hyderabad, Jakarta, Melbourne, Taipei), Europe (London, Paris, Zurich), Canada (Central), Canada West (Calgary), Africa (Cape Town), Israel (Tel Aviv), Mexico (Central), South America (Sao Paulo), and US West (N. California).
That brings durable functions to roughly 31 commercial Regions as of June 2026 — effectively a global rollout. Check the official documentation for the current Region list before planning a deployment in a specific Region.
Supported managed runtimes are Node.js (
nodejs22.x, nodejs24.x), Python (python3.13, python3.14), and Java (java17, java21, java25). Container images (OCI) are also supported, which lets you use other runtime versions by bundling the SDK yourself. The Durable Execution SDK for Java arrived later than the JavaScript and Python SDKs — it entered Developer Preview in February 2026 and reached general availability in April 2026.The name "durable functions" will sound familiar to anyone who has used Azure Durable Functions, which popularized the same checkpoint/replay idea in the Azure ecosystem; this article covers only the AWS implementation.
For the broader arc of how Lambda has evolved — from 5-minute timeouts and a handful of runtimes to durable execution — see AWS History and Timeline regarding AWS Lambda. Lambda functions were historically short-lived and stateless by definition, and durable execution makes long-lived, stateful workflows a first-class Lambda concept. Other Lambda-related articles on this site are indexed in the AWS Lambda Master Index.
3. The Programming Model Walkthrough
3.1 Enabling Durable Execution at Function Creation
Durable execution is a property of the function, configured when you create it — in the console via the Enable durable execution option, or programmatically with theDurableConfig parameter. You cannot simply flip an existing function over; plan durable functions as new functions.aws lambda create-function \
--function-name order-workflow \
--runtime python3.14 \
--handler lambda_function.lambda_handler \
--role arn:aws:iam::123456789012:role/order-workflow-role \
--zip-file fileb://function.zip \
--durable-config '{"ExecutionTimeout": 86400, "RetentionPeriodInDays": 14}'DurableConfig has two fields: ExecutionTimeout (total execution lifetime in seconds) and RetentionPeriodInDays (how long Lambda keeps execution history after completion). Section 5 covers their ranges and implications. In AWS SAM, the same configuration is a DurableConfig property on AWS::Serverless::Function:Resources:
OrderWorkflow:
Type: AWS::Serverless::Function
Properties:
Runtime: python3.14
Handler: lambda_function.lambda_handler
Tracing: Active
DurableConfig:
ExecutionTimeout: 86400
RetentionPeriodInDays: 14The function's execution role needs two additional permissions that the checkpoint machinery uses at runtime:
lambda:CheckpointDurableExecution and lambda:GetDurableExecutionState. The console adds these automatically when it creates the role for you.One operational note on dependencies: the Node.js and Python managed runtimes include the Durable Execution SDK, so you can prototype in the console without packaging anything. For production, AWS recommends bundling the SDK in your deployment package and locking it to a major version, so a runtime update cannot change SDK behavior under in-flight executions. The Java runtimes do not include the SDK, so Java deployments must always bundle it.
npm install @aws/durable-execution-sdk-js # JavaScript / TypeScript
pip install aws-durable-execution-sdk-python # Python3.2 A Minimal Durable Function
The following TypeScript example, adapted from the official getting-started tutorial, processes an order in three checkpointed steps with a wait in the middle:import { withDurableExecution } from "@aws/durable-execution-sdk-js";
export const handler = withDurableExecution(
async (event, context) => {
const orderId = event.orderId;
// Step 1: Validate order (checkpointed)
const validationResult = await context.step(async (stepContext) => {
stepContext.logger.info(`Validating order ${orderId}`);
return { orderId, status: "validated" };
});
// Step 2: Process payment (checkpointed)
const paymentResult = await context.step(async (stepContext) => {
stepContext.logger.info(`Processing payment for order ${orderId}`);
return { orderId, status: "paid" };
});
// Suspend for 10 seconds without consuming compute
await context.wait({ seconds: 10 });
// Step 3: Confirm order (checkpointed)
const confirmationResult = await context.step(async (stepContext) => {
stepContext.logger.info(`Confirming order ${orderId}`);
return { orderId, status: "confirmed" };
});
return {
orderId,
status: "completed",
steps: [validationResult, paymentResult, confirmationResult],
};
}
);The Python equivalent uses two decorators —
@durable_execution on the handler and @durable_step on each step function — and is fully synchronous (the Python SDK does not use async/await):from aws_durable_execution_sdk_python import (
DurableContext,
durable_execution,
durable_step,
)
from aws_durable_execution_sdk_python.config import Duration
@durable_step
def validate_order(step_context, order_id):
step_context.logger.info(f"Validating order {order_id}")
return {"orderId": order_id, "status": "validated"}
@durable_step
def process_payment(step_context, order_id):
step_context.logger.info(f"Processing payment for order {order_id}")
return {"orderId": order_id, "status": "paid"}
@durable_step
def confirm_order(step_context, order_id):
step_context.logger.info(f"Confirming order {order_id}")
return {"orderId": order_id, "status": "confirmed"}
@durable_execution
def lambda_handler(event, context: DurableContext):
order_id = event["orderId"]
validation_result = context.step(validate_order(order_id))
payment_result = context.step(process_payment(order_id))
context.wait(Duration.from_seconds(10))
confirmation_result = context.step(confirm_order(order_id))
return {
"orderId": order_id,
"status": "completed",
"steps": [validation_result, payment_result, confirmation_result],
}When this function runs, the initial invocation executes steps 1 and 2, checkpoints each result, then reaches the wait. Lambda checkpoints the wait, suspends the execution, and ends the invocation — you stop paying for compute. Ten seconds later, Lambda invokes the function again. The handler runs from the top: the two
context.step() calls return their checkpointed results without re-executing, the wait is recognized as satisfied, and execution continues into step 3. That second pass through already-completed code is replay in action, and you can observe it directly in CloudWatch Logs as a second invocation whose step log lines do not repeat.When you test this in the console, note that the console's Durable executions tab shows each execution with its status, timeline of completed steps, checkpoint history, and wait periods — this is the primary debugging view for durable functions (Section 8).
3.3 Steps: Checkpointed Units of Work with Retries
A step is the fundamental unit of durable work: a function whose result is checkpointed, and which the SDK retries automatically on failure according to a configurable retry strategy. Steps give you three guarantees worth internalizing:- Progress tracking: once a step completes, its result is durable. Later failures never roll it back or re-run it.
- At-least-once semantics: if a step fails midway or the invocation is interrupted before the checkpoint lands, the step may run more than once. The code inside a step must therefore be idempotent — use idempotency keys for payments, conditional writes for databases, and similar guards (Section 5.4).
- Retry isolation: a step that throws is retried with backoff by the SDK without restarting the whole workflow; between retry attempts the execution can suspend rather than burn compute.
Two practical design rules from the official best practices: give steps explicit, static names (names are how replay matches operations to checkpoints — never embed timestamps or random values in them), and do not nest a step inside another step; compose concurrency with child contexts instead.
Step granularity is a real design decision. Each step adds a durable operation and checkpointed state, and both are limited per execution (Section 5.2), so "one step per line of code" does not scale. The practical guidance: one step per side effect or per unit of retryable work — one external API call, one database write, one batch of computation — rather than wrapping trivial pure computation that replay can simply re-execute for free.
3.4 Waits: Suspending Without Compute
context.wait() suspends the execution for a duration — seconds to months, bounded only by the execution timeout. The wait is checkpointed, the execution environment is released, and no compute charges accrue while waiting. This is the primitive that makes patterns like "send a reminder after 7 days" or "poll a slow system every hour" economical in Lambda: previously you needed EventBridge Scheduler, SQS delay queues, or Step Functions Wait states to avoid paying for idle function time.Beyond fixed-duration waits, the SDK provides condition-polling waits (wait until a condition function returns true, re-evaluated on a schedule) — see the SDK reference for the per-language API.
3.5 Callbacks: Human-in-the-Loop and External Events
Callbacks are the durable-function equivalent of Step Functions' task tokens (waitForTaskToken). The pattern: your function creates a callback, obtains a unique callback ID, hands that ID to an external system (an approval app, a payment processor, a batch job), and suspends. The external system later reports the outcome through the Lambda API, and your function resumes with the result.The TypeScript SDK provides
createCallback, and a convenience operation waitForCallback that bundles the "submit the ID to the external system" step and the suspension into one operation:import { withDurableExecution } from "@aws/durable-execution-sdk-js";
export const handler = withDurableExecution(
async (event, context) => {
const [callbackPromise, callbackId] = await context.createCallback(
"wait-for-approval",
);
// Deliver callbackId to the external approver (SNS, email, ticketing, ...)
await sendApprovalRequest(callbackId, event.requestId);
// Suspends here - no compute consumed - until the external system responds
const result = await callbackPromise;
return { approved: true, result };
},
);The Python SDK exposes the same model through
create_callback / wait_for_callback:from aws_durable_execution_sdk_python import DurableContext, durable_execution
@durable_execution
def handler(event, context: DurableContext):
def submit(callback_id, ctx):
send_approval_request(callback_id, event["request_id"])
result = context.wait_for_callback(submitter=submit, name="wait-for-approval")
return {"approved": True, "result": result}The external system completes the callback with one of three Lambda API operations:
SendDurableExecutionCallbackSuccess (deliver a result and resume), SendDurableExecutionCallbackFailure (deliver an error), or SendDurableExecutionCallbackHeartbeat (signal "still working" for long-running external work). From the AWS CLI:aws lambda send-durable-execution-callback-success \
--callback-id <callback-id> \
--cli-binary-format raw-in-base64-out \
--result '{"status": "approved"}'The caller of these APIs needs the corresponding IAM permissions (for example
lambda:SendDurableExecutionCallbackSuccess), which gives you a clean authorization boundary: the approving system needs exactly one narrowly scoped permission, not access to your workflow's internals.Two timeout knobs matter here, and the official best practices are emphatic about both. Always set a timeout on callbacks — an unbounded callback wait means an execution that hangs until the execution timeout if the external system never responds. And for external work that should be reporting progress, set a heartbeat timeout shorter than the overall timeout, so a crashed external worker is detected within minutes instead of silently consuming the full wait window. Results that arrive after the timeout has fired are ignored.
If you have implemented approval flows with Step Functions task tokens — as described in How to Add an Approval Flow to AWS Step Functions Workflow (AWS Systems Manager Automation and Amazon EventBridge Edition) — the callback model will feel immediately familiar: the callback ID plays the role of the task token, and the
SendDurableExecutionCallback* APIs play the role of SendTaskSuccess/SendTaskFailure.3.6 Chained Invocations and Composition
context.invoke() calls another Lambda function — durable or standard — and checkpoints the result, suspending the caller while the callee runs:export const handler = withDurableExecution(
async (event, context) => {
const result = await context.invoke(
"process-order",
"arn:aws:lambda:us-east-1:123456789012:function:order-processor:1",
{ orderId: event.orderId }
);
return { statusCode: 200, body: JSON.stringify(result) };
}
);Because the invocation is checkpointed, an interruption in the caller resumes with the callee's result without re-invoking it. Note the qualified ARN (
:1) in the example — durable functions are pinned to versions throughout (Section 4.5) — and one hard constraint: cross-account chained invocations are not supported; caller and callee must be in the same AWS account.For fan-out within a single execution, the SDK provides parallel execution and collection-mapping operations built on child contexts — isolated sub-scopes of the durable execution that can each run their own sequence of durable operations concurrently while preserving deterministic replay. The SDK provides deterministic versions of common concurrency primitives; the rule of thumb is to wrap each concurrent branch in its own child context rather than firing raw language-level concurrency at durable operations. Keep the per-execution operation budget (Section 5.2) in mind before mapping over large collections — durable functions are not the tool for thousand-way fan-out, which is exactly where Step Functions Distributed Map shines (Section 6).
4. Determinism Requirements: The Heart of Replay
This is the section to read twice. The replay model's single non-negotiable contract is: on every invocation, your handler must make the same sequence of durable operation calls, in the same order, with the same operation names and types. The SDK validates replay against the checkpoint log, and code that diverges — a different branch taken, a different step name generated — produces replay errors or, worse, silently wrong results.The official documentation states the rule precisely: any code that is not inside a durable operation must be a pure function of the handler inputs and the results of completed operations. Everything else — everything observable that can differ between two runs — must live inside a step.
4.1 What Counts as Non-Deterministic
The official determinism guide calls out three families of code that must never run bare in the handler:- Time and identity:
Date.now(),time.time(),Instant.now(), UUID generation. - Random numbers:
Math.random(),random.random(),java.util.Random. - External I/O: HTTP calls, database reads, AWS SDK calls, file reads — anything whose answer can change between the original run and a replay.
The fix is always the same shape: wrap the non-deterministic call in a step. A step checkpoints its return value, so on replay the step returns the original value instead of re-executing — the value becomes part of the durable state. The canonical example is generating a transaction ID for a payment:
export const handler = withDurableExecution(
async (event: { amount: number }, context: DurableContext) => {
const transactionId = await context.step(
"generate-transaction-id",
async () => randomUUID(),
);
const receipt = await context.step("charge", async () => {
return charge(event.amount, transactionId);
});
return { transactionId, receipt };
}
);Because
generate-transaction-id is checkpointed, every replay sees the same transactionId, and the charge step always receives the same argument. Without the wrapper, each replay would mint a fresh UUID — and a replay after the charge could double-charge or trip the payment provider's idempotency check with a mismatched ID. The same pattern in Python:import uuid
@durable_step
def generate_transaction_id(ctx):
return str(uuid.uuid4())
@durable_step
def charge(ctx, amount, transaction_id):
return payment_service.charge(amount, transaction_id)
@durable_execution
def handler(event, context: DurableContext):
transaction_id = context.step(generate_transaction_id())
receipt = context.step(charge(event["amount"], transaction_id))
return {"transactionId": transaction_id, "receipt": receipt}4.2 Pass Data Through Return Values, Not Mutations
State that lives outside steps resets to its initial value on every replay, while steps return their cached results. Mixing the two corrupts your data silently. The official guide's example is an accumulator:// Wrong: total mutates outside the step - replay resets it to 0.
export const handler = withDurableExecution(async (event, context) => {
let total = 0;
for (const item of event.items) {
await context.step(`save-${item.id}`, async () => saveItem(item));
total += item.price; // runs again on every replay; steps do not
}
return { total };
});On the first invocation this looks correct. After a mid-loop interruption and replay, the completed
save-* steps are skipped (replayed from the log) but the bare total += item.price lines run again from a fresh total = 0 — and the final total now depends on where the interruption happened. The fix is to route the accumulation through the step's return value, so it is checkpointed along with the work:// Right: each step returns the new running total.
export const handler = withDurableExecution(async (event, context) => {
let total = 0;
for (const item of event.items) {
total = await context.step(`save-${item.id}`, async () => {
await saveItem(item);
return total + item.price;
});
}
return { total };
});The official documentation's warning deserves quoting because the failure mode is so quiet: "Mutating state outside a step fails silently. The first invocation looks correct. Replay resets the mutation while steps return their cached results."
A note on the step names in this example:
save-${item.id} is dynamic but deterministic — it derives from the handler input, so replay regenerates the same names in the same order. That is allowed. What is forbidden is naming derived from non-deterministic values such as timestamps or random numbers.4.3 Keep Branches Stable Across Replay
Control flow decisions made outside steps must depend only on deterministic inputs. If anif or switch consults something non-deterministic, replay can walk a different branch and attempt to return results for operations that never ran:// Wrong: replay may see a different time of day.
if (new Date().getHours() < 12) {
await context.step("morning-work", async () => runMorning());
} else {
await context.step("afternoon-work", async () => runAfternoon());
}An execution that starts at 11:58 and replays at 12:05 attempts the
afternoon-work branch while the log contains morning-work — a divergence the SDK will flag. Capture the decision in a step and branch on the checkpointed result:// Right: the SDK checkpoints the decision itself.
const shift = await context.step("pick-shift", async () => {
return new Date().getHours() < 12 ? "morning" : "afternoon";
});
if (shift === "morning") {
await context.step("morning-work", async () => runMorning());
} else {
await context.step("afternoon-work", async () => runAfternoon());
}The official guide extends this to a category that catches teams off guard: feature flags, environment variables read at runtime, and configuration pulled from a remote store can all change between the first invocation and a replay — a flag flip mid-execution, a deployment that edits an environment variable, a config push. Any such value that influences control flow or step inputs must be captured inside a step at the start of the execution so the evaluation criteria are frozen for the execution's lifetime.
4.4 How the SDK Enforces Determinism
Enforcement is not purely on the honor system. During replay, the SDK validates that the sequence of durable operations your code performs matches the checkpoint log — operation by operation, comparing names and types. If your replayed code calls a step where the log says a wait, or produces operations in a different order, the SDK surfaces a determinism violation instead of silently continuing. This converts most determinism bugs from corrupted state into loud failures, which is the better failure mode — but the validation can only catch structural divergence. A bareDate.now() whose value flows into a step's input without changing the operation sequence is still your responsibility.This enforcement model is also why the concurrency primitives matter: ordinary
Promise.all over durable operations would make the checkpoint completion order nondeterministic across runs. The SDK's deterministic concurrency operations and child contexts exist so that concurrent branches each maintain their own consistent operation sequence.4.5 Versions Are Part of Determinism: Qualified ARNs
Replay re-runs your code. If the code changes between the original invocation and a replay, the operation sequence can change with it — which is just the branching problem of Section 4.3 at deployment granularity. Lambda's design addresses this with version pinning: durable functions must be invoked through a qualified identifier (a version number, an alias, or explicitly$LATEST); unqualified invocation is rejected. When a durable execution starts, it is pinned to the specific function version that started it, and every subsequent resume invokes that same version — even if you have deployed ten new versions since.The operational consequences:
- Use numbered versions or aliases in production, never
$LATEST. Versions are immutable, so replay always sees the code it started with.$LATESTis mutable; an execution started on$LATESTthat resumes after a deployment replays new code against an old checkpoint log, which can fail or — worse — diverge silently. AWS positions$LATESTas acceptable for prototyping only. - Aliases give you safe rolling deployment. When you repoint an alias to a new version, new executions use the new version while in-flight executions continue on the version they started with. No drain, no coordination.
- Old versions must stay deployable. An execution pinned to version 12 may resume weeks later; do not delete versions that may still have live executions, and remember the SDK bundling guidance from Section 3.1 — a major-version SDK change inside a runtime update is exactly the kind of mid-flight change that breaks replay, which is why you pin the SDK in your package.
Even with version pinning, plan for step evolution: renaming a step, removing a step, or reordering steps in a new code version does not affect executions pinned to old versions, but be deliberate when you need executions started on the old version to be stopped, drained, or migrated before retiring it.
5. State, Limits, and Lifecycle
5.1 Two Timeouts, One Execution
To restate the model in configuration terms: the standard Lambda function timeout (up to 15 minutes) bounds each individual invocation; the execution timeout inDurableConfig bounds the durable execution end to end. The execution timeout accepts 60 seconds to 31,536,000 seconds (one year) and defaults to 86,400 seconds (24 hours). Wait time does not count against the function timeout — the function is not running — but it does count against the execution timeout.A subtle interaction worth knowing: you can invoke a durable function synchronously, and the caller then waits for the entire execution including waits — bounded by the synchronous invocation limit of 15 minutes. Synchronous invocation therefore suits short-lived coordination (a saga across three services that completes in seconds); anything that waits longer should be invoked asynchronously, which supports the full one-year execution duration, with completion observed through the execution APIs or EventBridge events (Section 8). Event source mappings (Amazon SQS, Kinesis, DynamoDB Streams) can also trigger durable functions. Durable functions support dead-letter queues for failed invocations but do not support Lambda destinations.
5.2 Checkpoint State and the Operation Budget
Durable state is not free or unbounded. Two per-execution limits surface directly in CloudWatch metrics, which tells you AWS expects you to watch them:- 3,000 durable operations per execution (
DurableExecutionOperations). - 100 MB of durable state written per execution (
DurableExecutionStorageWrittenBytes) — the cumulative size of checkpointed results.
These budgets reframe step design (Section 3.3). A loop that performs one step per item over a 10,000-item collection exhausts the operation budget; batch the items into fewer steps, aggregate state, or hand the fan-out to Step Functions Distributed Map. Similarly, checkpointing a large payload in every step burns the storage budget; checkpoint references (an Amazon S3 key, a record ID) instead of blobs, and keep step return values small.
5.3 Retention: Execution History After Completion
RetentionPeriodInDays (1 to 90 days, default 14) controls how long Lambda keeps the execution history — step results, execution state, the checkpoint log — after an execution reaches a terminal state. The retention clock starts at termination, not at start. After expiry, the history is deleted and the execution can no longer be inspected through the execution APIs or console. Set retention from your debugging and audit needs: 14 days is comfortable for operational debugging; compliance-driven audit trails beyond 90 days need their own export (for example, an EventBridge-triggered archiver writing terminal-state events and GetDurableExecutionHistory output to S3).Note that retention also interacts with idempotency, next.
5.4 Execution Names and Idempotent Starts
Every durable execution has an identity. By default Lambda generates a unique execution ID per invocation; optionally, you can supply an execution name, which acts as an idempotency key for starting executions. Execution names are unique per account and Region, and Lambda's behavior on a name collision is precisely specified:- Same name, same payload, execution running → idempotent start: Lambda returns the existing execution's information instead of starting a duplicate (for synchronous invocations this effectively reattaches the caller to the running execution).
- Same name, same payload, execution completed (and within retention) → Lambda returns the existing execution's information and result; no new execution.
- Same name, different payload →
DurableExecutionAlreadyExistserror, whether the existing execution is running or completed. - Name never used, or previous execution's retention expired → a new execution starts.
This gives you exactly-once workflow starts from at-least-once delivery upstream — pass
order-12345 as the execution name and retried invocations cannot spawn duplicate order workflows. One caveat from the official documentation: event source mappings do not support supplying execution names at launch, so each ESM delivery (including retries) starts a new execution. For idempotent starts from queues and streams, either implement idempotency in your function (for example with Powertools for AWS Lambda) or front the durable function with a standard dispatcher function that invokes it with an explicit execution name.Inside the execution, remember the layering: execution names deduplicate starts; step checkpoints deduplicate completed steps; but step bodies run at-least-once, so the side effects inside a step still need their own idempotency keys (Section 3.3). Durable functions remove a class of duplication problems — they do not remove the need for idempotent side effects.
5.5 The Execution Lifecycle and Its States
A durable execution moves through a small state machine of its own:RUNNING from the first invocation, then a terminal state — SUCCEEDED (handler returned), FAILED (unhandled error), TIMED_OUT (execution timeout exceeded), or STOPPED (canceled via the StopDurableExecution API). You can observe state through the console's Durable executions tab, the execution APIs (GetDurableExecution, GetDurableExecutionHistory), and EventBridge status-change events (Section 8). StopDurableExecution is the operational kill switch for runaway or no-longer-needed executions — remember that an execution can otherwise live for up to a year.6. Durable Functions vs Step Functions: A Decision Framework
"Does this replace Step Functions?" is the most-asked question about durable functions, and AWS's own documentation answers it directly: no. The official comparison page positions the two as serving different developer preferences and architectural patterns — durable functions are optimized for application development within Lambda, while Step Functions is built for workflow orchestration across AWS services. The honest framing is not replacement but a new point in the design space: workflow-grade reliability with code-native ergonomics.6.1 What AWS's Official Guidance Says
Condensing the official "Durable functions or Step Functions" page, use durable functions when:- Your team prefers standard programming languages and familiar development tools (IDE, unit test frameworks, language debuggers, AI coding agents).
- The application logic lives primarily within Lambda functions, with workflow and business logic tightly coupled.
- You want fine-grained control over execution state in code, and fast iteration without switching between code and a visual/JSON workflow designer.
Use Step Functions when:
- You need a visual workflow representation for cross-team visibility, including non-technical stakeholders who must understand and validate the process.
- You orchestrate multiple AWS services and want native, no-code service integrations (Step Functions integrates with 220+ services) instead of writing SDK calls.
- You want zero-maintenance orchestration infrastructure — no runtimes to patch or update, because the state machine itself runs no customer code.
AWS's decision framework asks five questions: What is your primary focus (Lambda application development vs cross-AWS orchestration)? What programming model do you prefer (general-purpose language vs graph-based DSL/visual designer)? How many AWS services are involved (primarily Lambda vs many services)? What development tools do you use (Lambda developer experience, SAM/CDK, unit tests vs visual builder)? Who manages the infrastructure (flexibility within Lambda vs fully managed, runtime-agnostic)?
6.2 A Practical Decision Tree
The official questions are necessary but not sufficient — they do not mention several factors that decide real projects. The decision tree below folds in the operational dimensions from the rest of this article: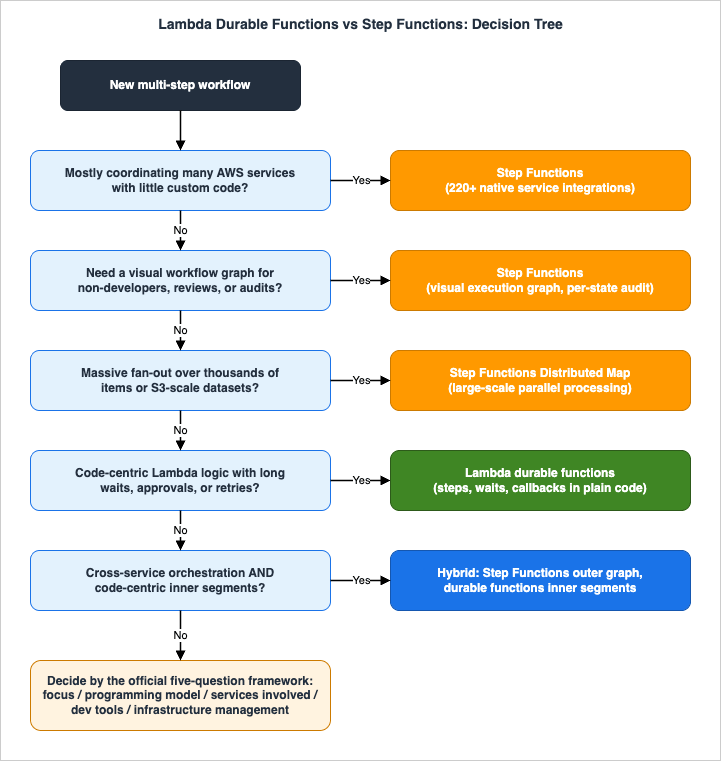
Walking through the added dimensions:
- Scale of fan-out. A durable execution has a 3,000-operation and 100 MB state budget. Step Functions Distributed Map is engineered for exactly the opposite regime — millions of items, S3-sourced datasets, controlled concurrency at scale (see AWS Step Functions Distributed Map - Practical Patterns and Pitfalls for Large-Scale Parallel Workloads). If your workflow's core is wide fan-out over data, durable functions are the wrong primitive, full stop. If the fan-out is one stage of a code-centric workflow, run the stage in Step Functions and the rest as a durable function (Section 7).
- Visibility and audit. Step Functions gives you an execution graph that auditors, operations teams, and product owners can read without seeing code, plus per-state input/output inspection in the console. Durable functions give you an execution timeline of steps and checkpoints in the Lambda console — genuinely useful, but it is a developer's view of code execution, not a stakeholder's view of a business process. Approval-heavy, compliance-heavy workflows often choose Step Functions for this reason alone.
- Human approvals. Both models handle human-in-the-loop well — task tokens in Step Functions, callbacks in durable functions (Section 3.5). The differentiator is the surrounding requirement: if the approval flow must be visible and auditable as a diagram, Step Functions; if it is one suspension point inside a larger code-centric workflow, callbacks keep everything in one place.
- Determinism tolerance. Durable functions impose the Section 4 contract on your team. A team that cannot enforce replay-safe coding discipline across contributors will ship determinism bugs. Step Functions has no equivalent constraint — each state's Lambda function is an ordinary function. This is a real, often decisive, team-capability question.
- Workflow change cadence vs in-flight executions. Both services pin running executions to the definition they started with. But if your workflows run for months and your code changes weekly, the version-management discipline of Section 4.5 becomes a standing operational cost on the durable-functions side.
6.3 Feature Comparison
| Dimension | Lambda durable functions | AWS Step Functions |
|---|---|---|
| Primary focus | Application development in Lambda | Workflow orchestration across AWS |
| Workflow definition | Standard code (JavaScript/TypeScript, Python, Java) | Amazon States Language (JSON DSL), visual designer, or AWS CDK |
| Runs as | Within your Lambda function | Standalone managed service (runs no customer code) |
| Service integrations | Lambda's event-driven model + AWS SDK calls in steps | 220+ services natively, no custom code |
| Max duration | 1 year (execution timeout) | 1 year (Standard workflows) |
| Human-in-the-loop | Callbacks + SendDurableExecutionCallback* APIs | Task tokens (waitForTaskToken) + SendTask* APIs |
| Massive parallelism | Child contexts; bounded by per-execution operation budget | Distributed Map (very large scale) |
| Visibility | Execution timeline + checkpoint history in Lambda console | Visual execution graph, per-state I/O |
| Developer constraint | Determinism contract on handler code | ASL semantics; logic split across states |
| Testing | Language-native unit tests + testing SDK, local and cloud runners | TestState API, Step Functions Local, integration-heavy |
The "best for" summary from AWS's own comparison is a good closing note: distributed transactions, stateful application logic, function orchestration, and AI workflows for durable functions; business process and IT automation, data processing, and cross-service AI workflows for Step Functions.
7. Migration and Coexistence Patterns
7.1 Hybrid Architectures: Outer Graph, Inner Code
The official guidance explicitly endorses using both services together, and the cleanest composition rule is: Step Functions owns the cross-service graph; durable functions own the code-centric segments. A Step Functions state machine orchestrates the high-level process across queues, containers, analytics services, and approvals that need graph-level visibility; where a segment is "twenty steps of tightly coupled business logic in one language," that segment becomes a single durable function invoked as one state — instead of twenty Lambda states with their payloads threaded through ASL.This composition fixes an old Step Functions pain point: state machines whose graphs ballooned because every small code step had to be its own Task state to get retry and checkpoint semantics. With durable functions, retries and checkpoints live inside the code segment, and the state machine shrinks back to the level where a graph adds value — service boundaries, parallel branches, human gates, error routing.
The inverse nesting also works: a durable function can use callbacks to wait on processes that are themselves Step Functions executions, with the state machine reporting completion through the callback APIs. Use whichever direction keeps the visible layer the one your stakeholders need to see.
7.2 Migration Judgment: What Moves, What Stays
AWS's migration guidance is deliberately conservative, and it matches operational common sense:- Existing Step Functions workflows that work: keep them. There is no deprecation pressure and no cost-of-staying. Established cross-service workflows, especially those with operational runbooks and dashboards built around the execution graph, gain nothing from a rewrite.
- New Lambda-centric workflow logic: start with durable functions when the Section 6 tree points that way, and add Step Functions when multi-service orchestration or visual workflow requirements emerge ("start simple, evolve complex").
- The strongest migration candidates are the workarounds, not the workflows: Lambda functions that sleep-loop to poll, SQS delay-queue chains that emulate timers, DynamoDB tables that exist only to remember "where the process got to," recursive self-invocations that fake long-running work. These were always durable execution implemented by hand; replacing them with steps, waits, and callbacks deletes infrastructure rather than rewriting it.
- The weakest migration candidates are Distributed Map workloads, workflows whose graph is the documentation/audit artifact, and ASL-defined processes maintained by teams that do not own application code.
A practical note for migrating task-token flows: the approval pattern in the Step Functions approval flow article maps one-to-one onto callbacks — task token → callback ID,
SendTaskSuccess → SendDurableExecutionCallbackSuccess — so the external approval surface (the approval UI, the notification wiring) survives a migration largely intact; only the workflow side changes.7.3 Coexistence Boundaries
When both services are in play, draw the boundary along three lines. First, state size: anything that needs more than the per-execution durable-state budget belongs outside the durable function (S3 plus references, or Step Functions payload management). Second, blast radius of change: segments that change frequently belong in durable functions where deployment is a code release; segments that must be change-controlled as process definitions belong in ASL. Third, observability audience: put a boundary wherever the audience for "what is this process doing?" changes from developers to anyone else.8. Observability and Testing
8.1 The Console Execution View
The Lambda console gains a Durable executions tab for durable functions: a list of executions with status, and per-execution detail showing the execution timeline (when each step completed), checkpoint history, wait periods, and step results. Logs emitted through the DurableContext logger (context.logger / stepContext.logger) are correlated into the execution and step views, in addition to landing in CloudWatch Logs. For replay debugging, this view is your primary instrument: you can see exactly which operations are in the checkpoint log and where a replay diverged.8.2 CloudWatch Metrics That Matter
Durable functions emit execution-level metrics beyond the standard Lambda set:| Metric | What it tells you |
|---|---|
DurableExecutionStarted / Succeeded / Failed / TimedOut / Stopped | Execution outcome counts - alarm on Failed and TimedOut |
DurableExecutionDuration | Wall-clock time per execution in the RUNNING state |
ApproximateRunningDurableExecutions | Currently running executions |
ApproximateRunningDurableExecutionsUtilization | Percentage of your account's running-executions quota in use - alarm at 80% |
DurableExecutionOperations | Operations consumed per execution (limit: 3,000) |
DurableExecutionStorageWrittenBytes | Durable state written per execution (limit: 100 MB) |
Two reading rules: standard
Invocations and Duration count every replay invocation, so a single execution produces many data points — use DurableExecutionDuration for end-to-end timing and DurableExecutionFailed for outcome alarms, not Errors. And treat the two budget metrics (DurableExecutionOperations, DurableExecutionStorageWrittenBytes) as leading indicators: a workflow whose operation count grows with input size will eventually hit the ceiling in production, and the metric trend tells you before it does.8.3 EventBridge Status Events
Lambda publishes durable execution status changes to Amazon EventBridge (sourceaws.lambda, detail-type Durable Execution Status Change) for RUNNING and every terminal state, with the execution ARN, execution name, function version ARN, and timestamps in the detail. This is the integration point for completion handling of asynchronous executions — notify, archive, trigger downstream — especially since durable functions do not support Lambda destinations:{
"source": ["aws.lambda"],
"detail-type": ["Durable Execution Status Change"],
"detail": {
"status": ["FAILED", "TIMED_OUT"]
}
}AWS X-Ray active tracing is supported as for any Lambda function, with the trace header propagated through the durable execution, which helps map where time goes across resumed invocations.
8.4 Testing Durable Functions
The Durable Execution SDK ships testing SDKs that run executions locally and in the cloud and let tests inspect the result structurally: execution status, individual operation results, operation ordering, and operation counts — not just the final return value. Cloud-side,sam remote invoke and the cloud test runner exercise the deployed function; the calling principal needs lambda:InvokeFunction, lambda:GetDurableExecution, and lambda:GetDurableExecutionHistory. AWS SAM CLI also supports completing callbacks during local and remote test runs (sam local callback succeed / sam remote callback succeed), so human-in-the-loop paths are testable without a human.What should the tests assert? The official debugging guidance points at the replay-specific failure modes: non-deterministic code that produces different results on replay, shared state through global variables that breaks during replay, and missing operations from conditional logic errors. A test suite that asserts on operation sequence — this input produces exactly these steps, in this order, with these names — is effectively a determinism regression test: a contributor who introduces a non-deterministic branch changes the sequence, and the test catches what code review missed. Complement it with unit tests of step bodies (plain functions — test them as such) and an integration test through the cloud runner for IAM, configuration, and version wiring.
9. Common Pitfalls
A consolidated checklist of the failure modes covered throughout this guide, plus a few operational traps:- Bare non-determinism in the handler.
Date.now(), UUID generation,Math.random(), environment/flag reads, or any I/O outside a step. Symptom: replay divergence errors, or silently inconsistent data after a resume. Fix: wrap in steps (Sections 4.1, 4.3). - Mutating outer state from inside loops with steps. First run correct, replayed run wrong — the silent one. Route all accumulation through step return values (Section 4.2).
- Dynamic step names from non-deterministic values. Names containing timestamps or random components break checkpoint matching on replay. Names derived from handler input are fine; names derived from the wall clock are not.
- Running production on
$LATEST. Resumed executions replay changed code against the old checkpoint log. Always invoke production durable functions through numbered versions or aliases, keep old versions alive while executions may resume on them, and bundle and pin the SDK (Section 4.5). - Callbacks without timeouts. A callback with no timeout waits until the execution timeout — potentially a year — if the external system never answers. Set a timeout always, and a heartbeat timeout when the external worker can crash mid-task (Section 3.5).
- Wrong step granularity. One step per trivial computation exhausts the 3,000-operation budget and bloats checkpoint storage; one giant step around your whole handler gives at-least-once semantics to everything inside it and surrenders retry isolation. One step per side effect / per retryable unit (Sections 3.3, 5.2).
- Large payloads in checkpoint state. Step return values are durable state, budgeted at 100 MB per execution. Checkpoint references (S3 keys, record IDs), not blobs (Section 5.2).
- Nesting steps inside steps. Not supported — compose with child contexts for concurrency and sub-structure (Sections 3.3, 3.6).
- Assuming exactly-once step bodies. Steps are at-least-once; the checkpoint dedupes completed steps, not interrupted ones. Side effects inside steps need idempotency keys (Sections 3.3, 5.4).
- Expecting idempotent starts from event source mappings. ESM deliveries cannot carry execution names at launch; retried deliveries start duplicate executions unless you dedupe in code or via a dispatcher function (Section 5.4).
- Synchronous invocation of long-waiting workflows. The synchronous caller is bounded by the 15-minute invocation limit even though the execution can run for a year. Invoke long workflows asynchronously and observe completion via EventBridge or the execution APIs (Sections 5.1, 8.3).
- Treating durable functions as a Distributed Map substitute. Wide fan-out over large datasets hits the operation budget by design. Use Step Functions Distributed Map for the fan-out stage, durable functions for the surrounding logic (Sections 6.2, 7.1).
One adjacent note: because waits release the execution environment, a workflow that suspends frequently will also re-enter through cold starts more often than a hot, steadily invoked function. The resume latency is usually irrelevant against multi-minute waits, but if the milliseconds matter for the post-resume work, standard cold-start techniques apply — see AWS Lambda Cold Start Mitigation Guide - Provisioned Concurrency, SnapStart, and Code-Level Techniques.
10. Frequently Asked Questions
Q. Do Lambda durable functions replace AWS Step Functions?No — and this is AWS's own position, not just this article's reading. Durable functions are optimized for application development within Lambda (workflow tightly coupled to code, one language, fast iteration); Step Functions is built for orchestration across AWS services (native integrations, visual graph, zero-maintenance infrastructure). The realistic outcomes are: code-centric workflows that previously forced an awkward state machine move to durable functions; service-coordination workflows stay in Step Functions; and large systems use both, with Step Functions as the outer graph and durable functions as code-centric segments (Sections 6 and 7).
Q. What happens if my code is non-deterministic during replay?
The SDK validates each replay against the checkpoint log by operation sequence, name, and type. Structural divergence — a different branch leading to different operations — is detected and surfaced as an error rather than silently continuing. However, non-determinism that does not change the operation structure (for example, a fresh timestamp flowing into a step's input, or state mutated outside steps) can produce silently wrong data. The contract: all non-deterministic values must be produced inside steps; all state must flow through step return values (Section 4).
Q. Can a durable execution survive a deployment?
Yes — by design, via version pinning. Each execution is pinned to the function version that started it; resumes always invoke that version regardless of later deployments. Deploy a new version (or repoint an alias) and new executions pick it up while in-flight executions finish on their original code. The discipline this requires: invoke through versions or aliases (never
$LATEST in production) and keep old versions around while executions may still resume on them (Section 4.5).Q. How long can a durable function wait, and what does waiting cost?
A wait can last up to the execution timeout — configurable up to one year. While suspended, the function consumes no compute and the execution environment is released; you pay for compute only when the function is actively running. Note that durable functions do add billable dimensions beyond standard Lambda charges (durable operations and state); see the official AWS Lambda pricing page for specifics — this article intentionally omits pricing figures.
Q. Can I convert an existing Lambda function into a durable function?
Durable execution is configured at function creation (
DurableConfig), so treat it as a new function: create the durable function, move the handler code over, wrap it with the SDK, and restructure side effects into steps. The restructuring is the real work — existing code written without the determinism contract usually needs its time/UUID/I/O calls pulled into steps before it is replay-safe (Sections 3.1 and 4).Q. Which runtimes and Regions can I use?
Node.js 22/24, Python 3.13/3.14, and Java 17/21/25 as managed runtimes, plus OCI container images for other versions. After the December 2025 launch and the December 2025 and April 2026 Region expansions, durable functions are available in roughly 31 commercial Regions including Tokyo and Osaka; check the official documentation for the current list (Section 2.3).
11. Summary
Lambda durable functions extend Lambda with a checkpoint/replay execution model: steps checkpoint business logic and retry it automatically, waits and callbacks suspend execution for up to a year without compute charges, and replay reconstructs in-flight state by re-running your code against the checkpoint log. The price of admission is the determinism contract — code outside durable operations must be a pure function of inputs and completed-operation results — which in practice means wrapping time, randomness, identity, and I/O in steps, passing state through step return values, keeping branches stable, and pinning code versions with qualified ARNs.The capability arrived with unusual completeness: idempotent starts via execution names, callbacks with heartbeats for human-in-the-loop, per-execution metrics with explicit budgets (3,000 operations, 100 MB state), EventBridge lifecycle events, a structural testing SDK, and a near-global Region footprint within five months of launch.
On the question that frames this guide — durable functions or Step Functions — the answer is a boundary, not a winner: durable functions for workflow logic that lives naturally in code, Step Functions for orchestration that lives naturally as a graph across services, hybrids where a system needs both, and no migration pressure on Step Functions workflows that already work. If you internalize one section, make it Section 4: teams that respect the determinism contract get workflow-grade reliability in plain code; teams that do not will meet the only genuinely sharp edge this feature has.
I hope this guide helps you decide where durable functions belong in your serverless architecture — and helps your first durable execution replay cleanly on the first try.
12. References
AWS Official Documentation - Lambda Developer Guide- Lambda durable functions - AWS Lambda Developer Guide
- Basic concepts - Lambda durable functions
- Creating Lambda durable functions
- Supported runtimes for durable functions
- Invoking durable Lambda functions
- Idempotency - Lambda durable functions
- Durable functions or Step Functions
- Monitoring durable functions
- Testing Lambda durable functions
- Best practices for Lambda durable functions
AWS Official Documentation - Durable Execution SDK Developer Guide
AWS What's New / AWS Blogs
- Build multi-step applications and AI workflows with AWS Lambda durable functions (AWS News Blog)
- Building fault-tolerant applications with AWS Lambda durable functions (AWS Compute Blog)
- AWS Lambda durable functions are now available in 14 additional AWS Regions
- AWS Lambda durable functions are now available in 16 additional AWS Regions
- AWS Lambda durable functions (product page)
- AWS Lambda pricing
Related Articles in This Site
- AWS Lambda Master Index - A Hub for Lambda Articles
- AWS History and Timeline regarding AWS Lambda - Overview, Functions, Features, Summary of Updates, and Introduction
- AWS Step Functions Distributed Map - Practical Patterns and Pitfalls for Large-Scale Parallel Workloads
- How to Add an Approval Flow to AWS Step Functions Workflow (AWS Systems Manager Automation and Amazon EventBridge Edition)
- AWS Lambda Cold Start Mitigation Guide - Provisioned Concurrency, SnapStart, and Code-Level Techniques
References:
Tech Blog with curated related content
Written by Hidekazu Konishi