Evaluating OCR Accuracy of Claude on Amazon Bedrock and Amazon Textract Using Similarity Metrics
First Published:
Last Updated:
Using Amazon Bedrock for titling, commenting, and OCR (Optical Character Recognition) with Claude 3 Haiku
Using Amazon Bedrock for titling, commenting, and OCR (Optical Character Recognition) with Claude 3 Sonnet
Using Amazon Bedrock for titling, commenting, and OCR (Optical Character Recognition) with Claude 3 Opus
Using Amazon Bedrock for titling, commenting, and OCR (Optical Character Recognition) with Claude 3.5 Sonnet
Using Amazon Textract for OCR(Optical Character Recognition)
In this article, I will try a method to evaluate OCR accuracy using similarity based on the results output in the above articles.
* The source code published in this article and other articles by this author was developed as part of independent research and is provided 'as is' without any warranty of operability or fitness for a particular purpose. Please use it at your own risk. The code may be modified without prior notice.
Architecture Diagram
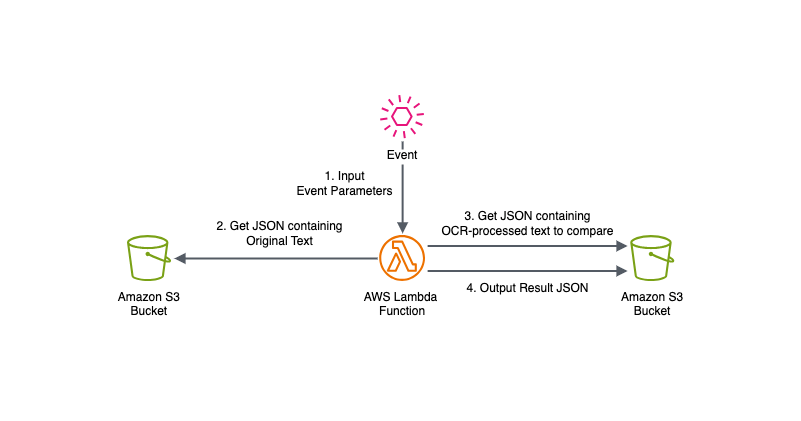
The architecture diagram illustrates the workflow of the OCR accuracy evaluation process:
- The process begins with an event that triggers the AWS Lambda function. This event contains parameters specifying the S3 bucket names and object keys for both the original text and the OCR-processed text.
- The Lambda function retrieves the JSON file containing the original text from the specified S3 bucket. This text serves as the baseline for comparison.
- Similarly, the function fetches the JSON file with the OCR-processed text from another S3 bucket (or the same bucket with a different key).
- The Lambda function performs the accuracy evaluation by comparing the original text with the OCR-processed text. It calculates various similarity metrics, including character-level accuracy, line-level accuracy, word-level accuracy, and segment accuracy. The comparison is done both with and without considering line breaks.
Finally, the function outputs a JSON file containing the detailed comparison results, including accuracy percentages and differences between the texts. This result file is stored in the S3 bucket specified for OCR results.
Implementation Example
For this implementation, we will use the AWS SDK for Python (Boto3) in an AWS Lambda function.Within the AWS Lambda function, we calculate the similarity between the original text and OCR results, considering patterns that ignore line breaks and patterns that consider line breaks.
The similarity is calculated using the
ratio() method of difflib.SequenceMatcher on a character-by-character basis.Another feature is that comparisons are also made at the line, word, and character levels.
Detailed specifications are described in the comments within the source code.
# OCR Accuracy Evaluation Lambda Function
#
# Overview:
# This Lambda function compares the original text with the text read by OCR processing,
# and evaluates the accuracy of OCR. The results are saved in JSON format to an S3 bucket.
#
# Main features:
# 1. Read original text and OCR text from S3
# 2. Perform text comparison and calculate the following accuracies:
# - Character-level accuracy
# - Line-level accuracy
# - Word-level accuracy
# - Accuracy considering line breaks and ignoring line breaks
# 3. Save comparison results to S3 bucket
#
# Input parameters:
# Event parameter format
# {
# "original_bucket": "[Amazon S3 bucket containing JSON with original text]",
# "original_key": "[Amazon S3 object key of JSON containing original text]",
# "ocr_bucket": "[Amazon S3 bucket containing JSON with OCR-processed text to compare]",
# "ocr_key": "[Amazon S3 object key of JSON containing OCR-processed text to compare]"
# }
#
# Input JSON format:
# Format of JSON containing original text
# {
# "original_text": "[Original text]",
# ...
# }
#
# Format of JSON containing OCR-processed text to compare
# {
# "image_ocr": "[Text read by OCR processing]",
# ...
# }
#
# Output:
# Results are saved as a JSON file in the S3 bucket.
# The output JSON includes the following information:
# - Details of the input event
# - Comparison results considering line breaks
# - Comparison results ignoring line breaks
# - Various accuracy metrics (character accuracy, line accuracy, word accuracy, etc.)
# - Text difference information
#
# Notes:
# - Verifies the validity of S3 bucket names and object keys.
# - Performs Unicode escape sequence decoding.
# - Logs errors and returns error responses when errors occur.
import json
import difflib
import boto3
from botocore.exceptions import ClientError, NoCredentialsError
import os
import logging
import re
# Log configuration
logger = logging.getLogger()
logger.setLevel(logging.INFO)
# Initialize S3 client as a global variable
try:
s3 = boto3.client('s3')
except NoCredentialsError:
logger.error("AWS credentials not found.")
raise
def read_json_from_s3(bucket, key):
"""Function to read JSON file from S3 bucket"""
try:
response = s3.get_object(Bucket=bucket, Key=key)
content = response['Body'].read().decode('utf-8')
return json.loads(content)
except ClientError as e:
logger.error(f"Error occurred while reading file from S3: {e}")
raise
except json.JSONDecodeError as e:
logger.error(f"Failed to decode JSON: {e}")
raise
def write_json_to_s3(bucket, key, data):
"""Function to write JSON data to S3 bucket"""
try:
s3.put_object(Bucket=bucket, Key=key, Body=json.dumps(data, ensure_ascii=False))
logger.info(f"Results written to S3: s3://{bucket}/{key}")
except ClientError as e:
logger.error(f"Error occurred while writing to S3: {e}")
raise
def decode_unicode_escapes(s):
"""Function to decode Unicode escape sequences"""
try:
# Avoid including quotation marks
return json.loads(json.dumps(s))
except json.JSONDecodeError:
logger.warning(f"Failed to decode Unicode escapes: {s}")
return s
def compare_strings(original, ocr_result):
"""Function to compare two strings and calculate accuracy"""
# Calculate overall similarity using SequenceMatcher
matcher = difflib.SequenceMatcher(None, original, ocr_result)
character_accuracy = round(matcher.ratio() * 100, 2)
# Line-by-line comparison
original_lines = original.splitlines()
ocr_lines = ocr_result.splitlines()
total_lines = max(len(original_lines), len(ocr_lines))
matching_lines = sum(1 for o, r in zip(original_lines, ocr_lines) if o == r)
line_accuracy = round((matching_lines / total_lines) * 100, 2) if total_lines > 0 else 0
# Word-by-word comparison
original_words = original.split()
ocr_words = ocr_result.split()
total_words = max(len(original_words), len(ocr_words))
matching_words = sum(1 for o, r in zip(original_words, ocr_words) if o == r)
word_accuracy = round((matching_words / total_words) * 100, 2) if total_words > 0 else 0
# Character-by-character comparison
total_chars = max(len(original), len(ocr_result))
matching_chars = sum(a == b for a, b in zip(original, ocr_result))
char_accuracy = round((matching_chars / total_chars) * 100, 2) if total_chars > 0 else 0
# Calculate differences
diff = list(difflib.unified_diff(original_lines, ocr_lines, lineterm=''))
return {
'character_accuracy': character_accuracy, # Overall similarity by SequenceMatcher (%)
'line_accuracy': line_accuracy, # Percentage of perfectly matching lines (%)
'word_accuracy': word_accuracy, # Percentage of perfectly matching words (%)
'char_accuracy': char_accuracy, # Percentage of perfectly matching characters (%)
'total_lines': total_lines, # Total number of lines
'matching_lines': matching_lines, # Number of perfectly matching lines
'total_words': total_words, # Total number of words
'matching_words': matching_words, # Number of perfectly matching words
'total_chars': total_chars, # Total number of characters
'matching_chars': matching_chars, # Number of perfectly matching characters
'diff': diff[:100] # Detailed differences (up to first 100 lines)
}
def compare_strings_ignore_newlines(original, ocr_result):
"""Function to compare two strings ignoring line breaks and calculate accuracy"""
# Replace newlines with spaces and merge consecutive spaces into one
original_no_newlines = ' '.join(original.replace('\n', ' ').replace('\r', ' ').split())
ocr_no_newlines = ' '.join(ocr_result.replace('\n', ' ').replace('\r', ' ').split())
# Calculate overall similarity using SequenceMatcher
matcher = difflib.SequenceMatcher(None, original_no_newlines, ocr_no_newlines)
character_accuracy = round(matcher.ratio() * 100, 2)
# Compare segments (pseudo-lines)
original_segments = original_no_newlines.split('. ')
ocr_segments = ocr_no_newlines.split('. ')
total_segments = max(len(original_segments), len(ocr_segments))
matching_segments = sum(1 for o, r in zip(original_segments, ocr_segments) if o == r)
segment_accuracy = round((matching_segments / total_segments) * 100, 2) if total_segments > 0 else 0
# Word-by-word comparison
original_words = original_no_newlines.split()
ocr_words = ocr_no_newlines.split()
total_words = max(len(original_words), len(ocr_words))
matching_words = sum(1 for o, r in zip(original_words, ocr_words) if o == r)
word_accuracy = round((matching_words / total_words) * 100, 2) if total_words > 0 else 0
# Character-by-character comparison
total_chars = max(len(original_no_newlines), len(ocr_no_newlines))
matching_chars = sum(a == b for a, b in zip(original_no_newlines, ocr_no_newlines))
char_accuracy = round((matching_chars / total_chars) * 100, 2) if total_chars > 0 else 0
# Calculate differences
diff = list(difflib.unified_diff(original_words, ocr_words, lineterm=''))
return {
'character_accuracy_no_newlines': character_accuracy, # Overall similarity ignoring line breaks (%)
'segment_accuracy': segment_accuracy, # Percentage of perfectly matching segments (pseudo-lines) (%)
'word_accuracy': word_accuracy, # Percentage of perfectly matching words (%)
'char_accuracy': char_accuracy, # Percentage of perfectly matching characters (%)
'total_segments': total_segments, # Total number of segments
'matching_segments': matching_segments, # Number of perfectly matching segments
'total_words': total_words, # Total number of words
'matching_words': matching_words, # Number of perfectly matching words
'total_chars': total_chars, # Total number of characters
'matching_chars': matching_chars, # Number of perfectly matching characters
'diff_no_newlines': diff[:100] # Detailed differences (up to first 100 lines)
}
def validate_s3_bucket_name(bucket_name):
"""Function to validate S3 bucket name"""
if not bucket_name:
raise ValueError("Bucket name is not specified.")
if len(bucket_name) < 3 or len(bucket_name) > 63:
raise ValueError("Bucket name must be between 3 and 63 characters.")
if not re.match(r'^[a-z0-9.-]+$', bucket_name):
raise ValueError("Bucket name contains invalid characters.")
if bucket_name.startswith('xn--') or bucket_name.endswith('-s3alias'):
raise ValueError("Bucket name contains invalid prefix or suffix.")
return True
def sanitize_filename(filename):
"""Function to sanitize filename"""
return re.sub(r'[^\w\-_\. ]', '_', filename)
def lambda_handler(event, context):
"""Main handler for Lambda function"""
try:
# Read settings from environment variables
original_bucket = event.get('original_bucket')
ocr_bucket = event.get('ocr_bucket')
if not original_bucket or not ocr_bucket:
raise ValueError("Required environment variables (original_bucket or ocr_bucket) are not set.")
# Validate S3 bucket names
validate_s3_bucket_name(original_bucket)
validate_s3_bucket_name(ocr_bucket)
# Get necessary information from the event
original_key = event.get('original_key')
ocr_key = event.get('ocr_key')
# Check if all required parameters are present
if not all([original_key, ocr_key]):
raise ValueError('Missing required parameters (original_key or ocr_key).')
# Read JSON files from S3
original_json = read_json_from_s3(original_bucket, original_key)
ocr_json = read_json_from_s3(ocr_bucket, ocr_key)
# Get necessary text from JSON
original_text = original_json.get('original_text', '')
ocr_text = ocr_json.get('image_ocr', '')
if not original_text or not ocr_text:
raise ValueError("Required text data not found.")
# Decode Unicode escape sequences in OCR text
ocr_text = decode_unicode_escapes(ocr_text)
# Perform comparison considering line breaks and ignoring line breaks
result_with_newlines = compare_strings(original_text, ocr_text)
result_without_newlines = compare_strings_ignore_newlines(original_text, ocr_text)
# Combine results into a single dictionary
combined_result = {
'without_newlines': result_without_newlines,
'with_newlines': result_with_newlines
}
# Prepare data for output to S3 with results and event
output_data = {
'event': event,
'result': combined_result
}
# Generate new S3 key (sanitize filename)
file_name = sanitize_filename(os.path.basename(ocr_key))
new_file_name = f"ocr-accuracy-{file_name}"
output_key = os.path.join(os.path.dirname(ocr_key), new_file_name)
# Write results to S3
write_json_to_s3(ocr_bucket, output_key, output_data)
# Return successful processing response
return {
'statusCode': 200,
'body': json.dumps({
'message': 'Results saved to S3',
'output_bucket': ocr_bucket,
'output_key': output_key
}, ensure_ascii=False)
}
except Exception as e:
logger.error(f"An error occurred: {str(e)}")
return {
'statusCode': 500,
'body': json.dumps({'error': str(e)})
}
Execution Details
Parameter Settings
The parameters passed when executing the AWS Lambda function are set in the following format:
{
"original_bucket": "[Amazon S3 bucket containing JSON with original text]",
"original_key": "[Amazon S3 object key of JSON containing original text]",
"ocr_bucket": "[Amazon S3 bucket containing JSON with OCR-processed text to compare]",
"ocr_key": "[Amazon S3 object key of JSON containing OCR-processed text to compare]"
}
original_bucket and original_key specify the S3 bucket name and object key of the JSON file containing the original text.The original text is the actual text written in the image that was subjected to OCR processing. This original text is saved in a JSON file in Amazon S3 with the key
original_text.ocr_bucket and ocr_key specify the S3 bucket name and object key of the JSON file containing the OCR processed text results.In this case, we will specify the OCR processing result JSON files for Claude 3 Haiku, Claude 3 Sonnet, Claude 3 Opus, Claude 3.5 Sonnet, and Amazon Textract that we tried in previous articles at runtime.
Input Data
The JSON file containing the original text of this trial, stored in an Amazon S3 bucket, is as follows:
{
"original_text": "hidekazu-konishi.com\nHOME > Personal Tech Blog\nPersonal Tech Blog | hidekazu-konishi.com\nHere I plan to share my technical knowledge and experience, as well as my interests in the subject. Please note that this tech blog is a space for sharing my personal views and ideas, and it does not represent the opinions of any company or organization I am affiliated with. The main purpose of this blog is to deepen my own technical skills and knowledge, to create an archive where I can record and reflect on what I have learned and experienced, and to share information.\nMy interests are primarily in Amazon Web Services (AWS), but I may occasionally cover other technical topics as well.\nThe articles are based on my personal learning and practical experience. Of course, I am not perfect, so there may be errors or inadequacies in the articles. I hope you will enjoy this technical blog with that in mind. Thank you in advance.\nPrivacy Policy\nPersonal Tech Blog Entries\nFirst Published: 2022-04-30\nLast Updated: 2024-03-14\n\u2022 Setting up DKIM, SPF, DMARC with Amazon SES and Amazon Route 53 - An Overview of DMARC Parameters and Configuration Examples\n\u2022 Summary of AWS Application Migration Service (AWS MGN) Architecture and Lifecycle Relationships, Usage Notes - Including Differences from AWS Server Migration Service (AWS SMS)\n\u2022 Basic Information about Amazon Bedrock with API Examples - Model Features, Pricing, How to Use, Explanation of Tokens and Inference Parameters\n\u2022 Summary of Differences and Commonalities in AWS Database Services using the Quorum Model - Comparison Charts of Amazon Aurora, Amazon DocumentDB, and Amazon Neptune\n\u2022 AWS Amplify Features Focusing on Static Website Hosting - Relationship and Differences between AWS Amplify Hosting and AWS Amplify CLI\n\u2022 Host a Static Website configured with Amazon S3 and Amazon CloudFront using AWS Amplify CLI\n\u2022 Host a Static Website using AWS Amplify Hosting in the AWS Amplify Console\n\u2022 Reasons for Continually Obtaining All AWS Certifications, Study Methods, and Levels of Difficulty\n\u2022 Summary of AWS CloudFormation StackSets Focusing on the Relationship between the Management Console and API, Account Filter, and the Role of Parameters\n\u2022 AWS History and Timeline regarding AWS Key Management Service - Overview, Functions, Features, Summary of Updates, and Introduction to KMS\n\u2022 AWS History and Timeline regarding Amazon EventBridge - Overview, Functions, Features, Summary of Updates, and Introduction\n\u2022 AWS History and Timeline regarding Amazon Route 53 - Overview, Functions, Features, Summary of Updates, and Introduction\n\u2022 AWS History and Timeline regarding AWS Systems Manager - Overview, Functions, Features, Summary of Updates, and Introduction to SSM\n\u2022 AWS History and Timeline regarding Amazon S3 - Focusing on the evolution of features, roles, and prices beyond mere storage\n\u2022 How to create a PWA(Progressive Web Apps) compatible website on AWS and use Lighthouse Report Viewer\n\u2022 AWS History and Timeline - Almost All AWS Services List, Announcements, General Availability(GA)\nWritten by Hidekazu Konishi\nHOME > Personal Tech Blog\nCopyright \u00a9 Hidekazu Konishi ( hidekazu-konishi.com ) All Rights Reserved."
}
On the other hand, the format of the JSON output from OCR processing by Claude 3 Haiku, Claude 3 Sonnet, Claude 3 Opus, Claude 3.5 Sonnet, and Amazon Textract stored in the Amazon S3 bucket should be as follows:
{
"image_ocr": "[Text read by OCR processing]",
--omitted--
}
Execution Results
By executing the AWS Lambda function code mentioned earlier, the following results are output, calculating the character-by-character similarity between the original text and the OCR processing results of Claude 3 Haiku, Claude 3 Sonnet, Claude 3 Opus, Claude 3.5 Sonnet, and Amazon Textract, as well as comparing at the line, word, and character levels:Example Execution Result for Claude 3 Haiku on Amazon Bedrock
{
"event": {
"original_bucket": "ho2k.com",
"original_key": "original/original_text.json",
"ocr_bucket": "ho2k.com",
"ocr_key": "ocr/amazon_bedrock_for_titling_commenting_ocr_with_claude3_haiku.json"
},
"result": {
"without_newlines": {
"character_accuracy_no_newlines": 99.67,
"segment_accuracy": 88.89,
"word_accuracy": 0.0,
"char_accuracy": 6.39,
"total_segments": 9,
"matching_segments": 8,
"total_words": 500,
"matching_words": 0,
"total_chars": 3179,
"matching_chars": 203,
"diff_no_newlines": [
--omitted--
]
},
"with_newlines": {
"character_accuracy": 99.64,
"line_accuracy": 86.21,
"word_accuracy": 0.0,
"char_accuracy": 6.07,
"total_lines": 29,
"matching_lines": 25,
"total_words": 500,
"matching_words": 0,
"total_chars": 3179,
"matching_chars": 193,
"diff": [
--omitted--
]
}
}
}
Example Execution Result for Claude 3 Sonnet on Amazon Bedrock
{
"event": {
"original_bucket": "ho2k.com",
"original_key": "original/original_text.json",
"ocr_bucket": "ho2k.com",
"ocr_key": "ocr/amazon_bedrock_for_titling_commenting_ocr_with_claude3_sonnet.json"
},
"result": {
"without_newlines": {
"character_accuracy_no_newlines": 99.94,
"segment_accuracy": 77.78,
"word_accuracy": 99.6,
"char_accuracy": 99.94,
"total_segments": 9,
"matching_segments": 7,
"total_words": 500,
"matching_words": 498,
"total_chars": 3179,
"matching_chars": 3177,
"diff_no_newlines": [
--omitted--
]
},
"with_newlines": {
"character_accuracy": 99.06,
"line_accuracy": 0.0,
"word_accuracy": 99.6,
"char_accuracy": 99.06,
"total_lines": 29,
"matching_lines": 0,
"total_words": 500,
"matching_words": 498,
"total_chars": 3179,
"matching_chars": 3149,
"diff": [
--omitted--
]
}
}
}
Example Execution Result for Claude 3 Opus on Amazon Bedrock
{
"event": {
"original_bucket": "ho2k.com",
"original_key": "original/original_text.json",
"ocr_bucket": "ho2k.com",
"ocr_key": "ocr/amazon_bedrock_for_titling_commenting_ocr_with_claude3_opus.json"
},
"result": {
"without_newlines": {
"character_accuracy_no_newlines": 99.64,
"segment_accuracy": 70.0,
"word_accuracy": 0.0,
"char_accuracy": 6.39,
"total_segments": 10,
"matching_segments": 7,
"total_words": 500,
"matching_words": 0,
"total_chars": 3179,
"matching_chars": 203,
"diff_no_newlines": [
--omitted--
]
},
"with_newlines": {
"character_accuracy": 98.71,
"line_accuracy": 1.82,
"word_accuracy": 0.0,
"char_accuracy": 4.78,
"total_lines": 55,
"matching_lines": 1,
"total_words": 500,
"matching_words": 0,
"total_chars": 3179,
"matching_chars": 152,
"diff": [
--omitted--
]
}
}
}
Example Execution Result for Claude 3.5 Sonnet on Amazon Bedrock
{
"event": {
"original_bucket": "ho2k.com",
"original_key": "original/original_text.json",
"ocr_bucket": "ho2k.com",
"ocr_key": "ocr/amazon_bedrock_for_titling_commenting_ocr_with_claude3-5_sonnet.json"
},
"result": {
"without_newlines": {
"character_accuracy_no_newlines": 100.0,
"segment_accuracy": 100.0,
"word_accuracy": 100.0,
"char_accuracy": 100.0,
"total_segments": 9,
"matching_segments": 9,
"total_words": 500,
"matching_words": 500,
"total_chars": 3179,
"matching_chars": 3179,
"diff_no_newlines": []
},
"with_newlines": {
"character_accuracy": 99.81,
"line_accuracy": 2.44,
"word_accuracy": 100.0,
"char_accuracy": 5.99,
"total_lines": 41,
"matching_lines": 1,
"total_words": 500,
"matching_words": 500,
"total_chars": 3191,
"matching_chars": 191,
"diff": [
--omitted--
]
}
}
}
Example Execution Result for Amazon Textract
{
"event": {
"original_bucket": "ho2k.com",
"original_key": "original/original_text.json",
"ocr_bucket": "ho2k.com",
"ocr_key": "ocr/amazon_textract_for_ocr.json"
},
"result": {
"without_newlines": {
"character_accuracy_no_newlines": 99.4,
"segment_accuracy": 66.67,
"word_accuracy": 33.8,
"char_accuracy": 35.04,
"total_segments": 9,
"matching_segments": 6,
"total_words": 500,
"matching_words": 169,
"total_chars": 3179,
"matching_chars": 1114,
"diff_no_newlines": [
--omitted--
]
},
"with_newlines": {
"character_accuracy": 89.66,
"line_accuracy": 4.55,
"word_accuracy": 33.8,
"char_accuracy": 34.76,
"total_lines": 44,
"matching_lines": 2,
"total_words": 500,
"matching_words": 169,
"total_chars": 3179,
"matching_chars": 1105,
"diff": [
--omitted--
]
}
}
}
References:
Tech Blog with curated related content
Using Amazon Bedrock for titling, commenting, and OCR (Optical Character Recognition) with Claude 3 Haiku
Using Amazon Bedrock for titling, commenting, and OCR (Optical Character Recognition) with Claude 3 Sonnet
Using Amazon Bedrock for titling, commenting, and OCR (Optical Character Recognition) with Claude 3 Opus
Using Amazon Bedrock for titling, commenting, and OCR (Optical Character Recognition) with Claude 3.5 Sonnet
Using Amazon Textract for OCR(Optical Character Recognition)
Summary
In this article, I explained a method for evaluating the accuracy of OCR processing using the Anthropic Claude model family on Amazon Bedrock and Amazon Textract.Using an AWS Lambda function, I calculated the similarity between the original text and OCR processing results, analyzing accuracy from various perspectives.
The main points of this accuracy evaluation using similarity include:
- Calculating similarity in patterns that consider line breaks and ignore line breaks
- Conducting accuracy evaluations at character, line, word, and segment levels
- Detailed difference analysis using
difflib.SequenceMatcher
Based on the results of this trial, the following points were confirmed:
- Claude 3.5 Sonnet showed 100% accuracy when ignoring line breaks, confirming its high performance.
- Claude 3 Sonnet and Claude 3 Opus also showed very high accuracy.
- Claude 3 Haiku tended to have slightly lower accuracy compared to other Claude models.
- In this trial, Amazon Textract showed lower accuracy compared to other models.
It is also possible to compare the performance of each model for different types of text and images.
I plan to continue following version upgrades of the Anthropic Claude models on Amazon Bedrock and updates to Amazon Textract, and verify the progress in accuracy improvement.
Written by Hidekazu Konishi