Using Amazon Bedrock for titling, commenting, and OCR (Optical Character Recognition) with Claude 3.5 Sonnet
First Published:
Last Updated:
Basic Information about Amazon Bedrock with API Examples - Model Features, Pricing, How to Use, Explanation of Tokens and Inference Parameters
This time, I will introduce examples of using Amazon Bedrock for image titling, commentary, and OCR (Optical Character Recognition) with Anthropic Claude 3.5 Sonnet.
* The source code published in this article and other articles by this author was developed as part of independent research and is provided 'as is' without any warranty of operability or fitness for a particular purpose. Please use it at your own risk. The code may be modified without prior notice.
* This article was written using AWS services on a personally registered AWS account.
* The Amazon Bedrock models used in the writing of this article were executed on 2024-07-18 (JST) and are based on the following End user license agreement (EULA) at that time.
Anthropic Claude 3.5 Sonnet (anthropic.claude-3-5-sonnet-20240620-v1:0): Anthropic on Bedrock - Commercial Terms of Service (Effective: January 2, 2024)
Overview of Anthropic Claude
Anthropic is a US startup company in the field of generative AI technology, founded by former engineers of OpenAI, with investments from Google and Amazon.Claude is a chat-type AI model developed by Anthropic, known for having fewer hallucinations (information not based on facts) and supporting natural conversations close to human interactions in multiple languages including Japanese.
In particular, Claude 3.5 Sonnet, among the models available on Amazon Bedrock at the time of writing this article, is known for its strengths in image recognition. Hence, I tried titling, commentary, and OCR.
Overview of Parameters Specified for Claude 3.5 Sonnet
Using an example of executinginvoke_model of bedrock-runtime with AWS SDK for Python (Boto3), the following outlines the parameters specified for Claude 3.5 Sonnet.
import boto3
import json
import os
import sys
import re
import base64
import datetime
region = os.environ.get('AWS_REGION')
bedrock_runtime_client = boto3.client('bedrock-runtime', region_name=region)
def claude3_invoke_model(input_prompt, image_media_type, image_data_base64, model_params):
prompt = f'\n\nHuman:{input_prompt}\n\nAssistant:'
response = bedrock_runtime_client.invoke_model(
modelId=model_params['model_id'], # Identifier to specify the model to use.
contentType='application/json', # MIME type of the request input data.
accept='application/json', # MIME type of the inference Body in the response. (Default: application/json)
body=json.dumps({
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": model_params['max_tokens'], # Specifies the value of maxTokens, the maximum number of tokens. (Default: 2000, Minimum: 0, Maximum: 4,096)
"messages": [
{
"role": "user",
"content": [
{
"type": "image",
"source": {
"type": "base64",
"media_type": image_media_type, # Specify the Media Type of the image, such as "image/jpeg", "image/png".
"data": image_data_base64 # Input image data in the format specified by "type" (base64).
}
},
{
"type": "text",
"text": prompt # Input the prompt entered by the user.
}
]
}
],
"system": "", #(Optional) Used to specify the AI's role, goals, or provide additional context and instructions.
"temperature": model_params['temperature'], #(Optional) Specify the value of temperature. (Default: 1.0, Minimum: 0, Maximum: 1.0)
"top_p": model_params['top_p'], #(Optional) Specify the value of topP. (Default: 0.999, Minimum: 0, Maximum: 1.0)
"top_k": model_params['top_k'], #(Optional) Specify the value of topK. (Default: Disabled, Minimum: 0, Maximum: 500)
"stop_sequences": ["\n\nHuman:"] #(Optional) Specifies strings or sequences that, when detected, will cause the model to stop generating text at that point.
})
)
print('Claude3 Response Start-----')
print(response)
print('Claude3 Response End-----')
print('Claude3 Response Body Start-----')
response_body = json.loads(response.get('body').read())
print(response_body)
print('Claude3 Response Body End-----')
print('Claude3 Response Text Start-----')
response_text = response_body["content"][0]["text"]
print(response_text)
print('Claude3 Response Text End-----')
return response_text
For general inference parameters for models dealing with text, such as temperature, top_p(topP), top_k(topK), and max_tokens_to_sample(maxTokens), please see the following article for explanations.Basic Information about Amazon Bedrock with API Examples - Model Features, Pricing, How to Use, Explanation of Tokens and Inference Parameters
For more details on the parameters used with the Anthropic Claude model, please refer to the following AWS Document.
Reference: Anthropic Claude Messages API - Amazon Bedrock
Ownership and Copyright of Content Generated by the Claude 3.5 Sonnet Model
Based on the license of Claude 3.5 Sonnet, this document clarifies the ownership and copyright of content output by the model.According to the End User License Agreement (EULA) found on the Amazon Bedrock console page for the Anthropic Claude 3.5 Sonnet model, the provider, Anthropic, does not claim ownership of the prompts or outputs (Users should verify the exact terms of the license).
Anthropic does not anticipate obtaining any rights in or access to Customer Content under these Terms. As between the Parties and to the extent permitted by applicable law, Anthropic agrees that Customer owns all Outputs, and disclaims any rights it receives to the Customer Content under these Terms. Subject to Customer’s compliance with these Terms, Anthropic hereby assigns to Customer its right, title, and interest (if any) in and to Outputs. Anthropic may not train models on Customer Content from Services.Thus, as long as the content of the license is adhered to, the outputs generated by the model can be freely used by the user.
Architecture Diagram
For this trial, due to the aim of observing the output variations through input/output adjustments and parameter tuning when invoking the Anthropic Claude 3.5 Sonnet model from an AWS Lambda function, the setup was kept simple.The AWS services that could be used to input events into the AWS Lambda function include Amazon API Gateway, Amazon EventBridge, among others, with event parameters being adapted according to the AWS resources used through mapping or transformers, or modifying the format on the AWS Lambda side.
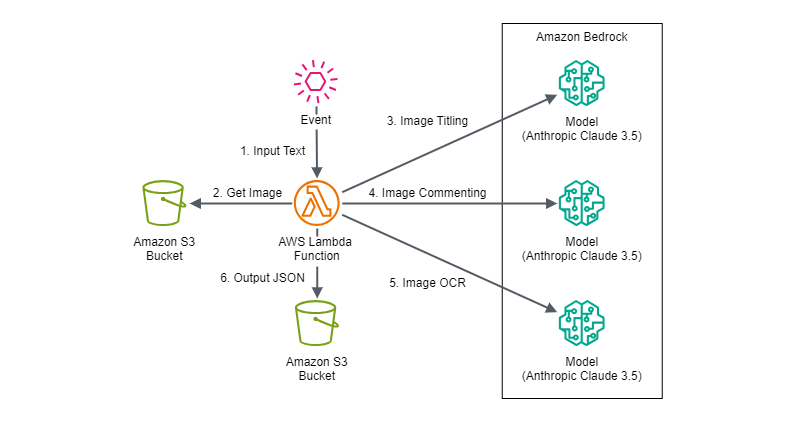
This is because attempting to direct all three tasks in a single request was observed to diminish the output accuracy for each task.
Implementation Example
This time, an AWS Lambda function was implemented to executeinvoke_model of bedrock-runtime using AWS SDK for Python (Boto3).Additionally, to observe the variations in outputs for each model parameter, the main parameters for each model were made adjustable via events.
import boto3
import json
import os
import sys
import re
import base64
import datetime
region = os.environ.get('AWS_REGION')
bedrock_runtime_client = boto3.client('bedrock-runtime', region_name=region)
s3_client = boto3.client('s3', region_name=region)
def claude3_invoke_model(input_prompt, image_media_type, image_data_base64, model_params):
prompt = f'\n\nHuman:{input_prompt}\n\nAssistant:'
response = bedrock_runtime_client.invoke_model(
modelId=model_params['model_id'], # Identifier to specify the model to use.
contentType='application/json', # MIME type of the request input data.
accept='application/json', # MIME type of the inference Body in the response. (Default: application/json)
body=json.dumps({
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": model_params['max_tokens'], # Specifies the value of maxTokens, the maximum number of tokens. (Default: 2000, Minimum: 0, Maximum: 4,096)
"messages": [
{
"role": "user",
"content": [
{
"type": "image",
"source": {
"type": "base64",
"media_type": image_media_type, # Specify the Media Type of the image, such as "image/jpeg", "image/png".
"data": image_data_base64 # Input image data in the format specified by "type" (base64).
}
},
{
"type": "text",
"text": prompt # Input the prompt entered by the user.
}
]
}
],
"system": "", #(Optional) Used to specify the AI's role, goals, or provide additional context and instructions.
"temperature": model_params['temperature'], #(Optional) Specify the value of temperature. (Default: 1.0, Minimum: 0, Maximum: 1.0)
"top_p": model_params['top_p'], #(Optional) Specify the value of topP. (Default: 0.999, Minimum: 0, Maximum: 1.0)
"top_k": model_params['top_k'], #(Optional) Specify the value of topK. (Default: Disabled, Minimum: 0, Maximum: 500)
"stop_sequences": ["\n\nHuman:"] #(Optional) Specifies strings or sequences that, when detected, will cause the model to stop generating text at that point.
})
)
print('Claude3 Response Start-----')
print(response)
print('Claude3 Response End-----')
print('Claude3 Response Body Start-----')
response_body = json.loads(response.get('body').read())
print(response_body)
print('Claude3 Response Body End-----')
print('Claude3 Response Text Start-----')
response_text = response_body["content"][0]["text"]
print(response_text)
print('Claude3 Response Text End-----')
return response_text
def lambda_handler(event, context):
# Format of the input event
#{
# "input_s3_bucket_name": "[Target Amazon S3 bucket to retrieve the image]",
# "input_s3_object_key": "[Target Amazon S3 object key to retrieve the image]",
# "output_s3_bucket_name": "[Amazon S3 bucket to output the result JSON]",
# "output_s3_object_key_prefix": "[Amazon S3 object key to output the result JSON]",
# "claude_model_id": "[Model ID for Claude]",
# "claude_temperature": 1.0,
# "claude_top_p": 0.999,
# "claude_top_k": 250,
# "claude_max_tokens": 4096,
# "image_title_prompt": "[Custom prompt for image_title]",
# "image_description_prompt": "[Custom prompt for image_description]",
# "image_ocr_prompt": "[Custom prompt for image_ocr]"
#}
result = {}
try:
input_s3_bucket_name = event['input_s3_bucket_name']
input_s3_object_key = event['input_s3_object_key']
output_s3_bucket_name = event['output_s3_bucket_name']
output_s3_object_key_prefix = event.get('output_s3_object_key_prefix', input_s3_object_key)
model_params = {
'model_id': event.get('claude_model_id', 'anthropic.claude-3-sonnet-20240229-v1:0'),
'temperature': event.get('claude_temperature', 1.0),
'top_p': event.get('claude_top_p', 0.999),
'top_k': event.get('claude_top_k', 250),
'max_tokens': event.get('claude_max_tokens', 4096)
}
image_title_prompt = event.get('image_title_prompt', 'Please provide a title for this image.')
image_description_prompt = event.get('image_description_prompt', 'Please provide a brief description of the title for this image.')
image_ocr_prompt = event.get('image_ocr_prompt', 'Please extract all text contained in this image.')
s3_object = s3_client.get_object(Bucket=input_s3_bucket_name, Key=input_s3_object_key)
image_media_type = s3_object['ContentType']
image_data = s3_object['Body'].read()
image_data_base64 = base64.b64encode(image_data).decode('utf-8')
# Invoke Model for image_title
image_title_prompt = event.get('image_title_prompt', 'Please provide a title for this image.')
input_prompt = f'{image_title_prompt} However, do not include your own commentary in the output; present the results in the following format:\nimage_title: <result>'
image_title = claude3_invoke_model(input_prompt, image_media_type, image_data_base64, model_params).removeprefix('image_title:').removeprefix(' ')
# Invoke Model for image_description
image_description_prompt = event.get('image_description_prompt', 'Please provide a brief description of the title for this image.')
input_prompt = f'{image_description_prompt} However, do not include your own commentary in the output; present the results in the following format:\nimage_description: <result>'
image_description = claude3_invoke_model(input_prompt, image_media_type, image_data_base64, model_params).removeprefix('image_description:').removeprefix(' ')
# Invoke Model for image_ocr
image_ocr_prompt = event.get('image_ocr_prompt', 'Please extract all text contained in this image.')
input_prompt = f'{image_ocr_prompt} However, do not include your own commentary in the output; present the results in the following format:\nimage_ocr: <result>'
image_ocr = claude3_invoke_model(input_prompt, image_media_type, image_data_base64, model_params).removeprefix('image_ocr:').removeprefix(' ')
response_json = {
"image_title": image_title,
"image_description": image_description,
"image_ocr": image_ocr
}
output_json = json.dumps(response_json).encode('utf-8')
output_s3_object_key = f'{output_s3_object_key_prefix.replace(".", "_")}_{datetime.datetime.now().strftime("%y%m%d_%H%M%S")}.json'
s3_client.put_object(Bucket=output_s3_bucket_name, Key=output_s3_object_key, Body=output_json)
result = {
"status": "SUCCESS",
"output_s3_bucket_url": f'https://s3.console.aws.amazon.com/s3/buckets/{output_s3_bucket_name}',
"output_s3_object_url": f'https://s3.console.aws.amazon.com/s3/object/{output_s3_bucket_name}?region={region}&bucketType=general&prefix={output_s3_object_key}'
}
except Exception as ex:
print(f'Exception: {ex}')
tb = sys.exc_info()[2]
err_message = f'Exception: {str(ex.with_traceback(tb))}'
print(err_message)
result = {
"status": "FAIL",
"error": err_message
}
return result
Execution Details
Parameter Settings
I observed the changes in output by altering the following format of Event parameters passed to the implemented AWS Lambda function to various values.
{
"input_s3_bucket_name": "[Target Amazon S3 bucket to retrieve the image]",
"input_s3_object_key": "[Target Amazon S3 object key to retrieve the image]",
"output_s3_bucket_name": "[Amazon S3 bucket to output the result JSON]",
"output_s3_object_key_prefix": "[Amazon S3 object key prefix to output the result JSON]",
"claude_model_id": "anthropic.claude-3-5-sonnet-20240620-v1:0",
"claude_temperature": 1,
"claude_top_p": 0.999,
"claude_top_k": 250,
"claude_max_tokens": 4096,
"image_title_prompt": "Please provide a title for this image.",
"image_description_prompt": "Please provide a brief description of the title for this image.",
"image_ocr_prompt": "Please extract all text contained in this image."
}
Below, I introduce the titling, commentary, and OCR output for images, specifically using the Anthropic Claude 3.5 Sonnet with max_tokens set to the maximum of 4096, while other parameters were set to default settings.Input Data
As an example of input data, I used a screenshot image of the top page of my Personal Tech Blog, including the blog description and article titles.This example aims to assess the ability to accurately recognize standard document images with clear visibility.
Execution Results
Example: Titling, Commentary, and OCR for an English-Language Blog Article Image
* Input Data: Image
{
"image_title": "Personal Tech Blog | hidekazu-konishi.com",
"image_description": "Personal Tech Blog | hidekazu-konishi.com",
"image_ocr": "hidekazu-konishi.com\n\nHOME > Personal Tech Blog\n\nPersonal Tech Blog | hidekazu-konishi.com\n\nHere I plan to share my technical knowledge and experience, as well as my interests in the subject. Please note that this tech blog is a space for sharing my personal views and ideas, and it does not represent the opinions of any company or organization I am affiliated with. The main purpose of this blog is to deepen my own technical skills and knowledge, to create an archive where I can record and reflect on what I have learned and experienced, and to share information.\n\nMy interests are primarily in Amazon Web Services (AWS), but I may occasionally cover other technical topics as well.\n\nThe articles are based on my personal learning and practical experience. Of course, I am not perfect, so there may be errors or inadequacies in the articles. I hope you will enjoy this technical blog with that in mind. Thank you in advance.\n\nPrivacy Policy\n\nPersonal Tech Blog Entries\n\nFirst Published: 2022-04-30\nLast Updated: 2024-03-14\n\n\u2022 Setting up DKIM, SPF, DMARC with Amazon SES and Amazon Route 53 - An Overview of DMARC Parameters and Configuration Examples\n\u2022 Summary of AWS Application Migration Service (AWS MGN) Architecture and Lifecycle Relationships, Usage Notes - Including Differences from AWS Server Migration Service (AWS SMS)\n\u2022 Basic Information about Amazon Bedrock with API Examples - Model Features, Pricing, How to Use, Explanation of Tokens and Inference Parameters\n\u2022 Summary of Differences and Commonalities in AWS Database Services using the Quorum Model - Comparison Charts of Amazon Aurora, Amazon DocumentDB, and Amazon Neptune\n\u2022 AWS Amplify Features Focusing on Static Website Hosting - Relationship and Differences between AWS Amplify Hosting and AWS Amplify CLI\n\u2022 Host a Static Website configured with Amazon S3 and Amazon CloudFront using AWS Amplify CLI\n\u2022 Host a Static Website using AWS Amplify Hosting in the AWS Amplify Console\n\u2022 Reasons for Continually Obtaining All AWS Certifications, Study Methods, and Levels of Difficulty\n\u2022 Summary of AWS CloudFormation StackSets Focusing on the Relationship between the Management Console and API, Account Filter, and the Role of Parameters\n\u2022 AWS History and Timeline regarding AWS Key Management Service - Overview, Functions, Features, Summary of Updates, and Introduction to KMS\n\u2022 AWS History and Timeline regarding Amazon EventBridge - Overview, Functions, Features, Summary of Updates, and Introduction\n\u2022 AWS History and Timeline regarding Amazon Route 53 - Overview, Functions, Features, Summary of Updates, and Introduction\n\u2022 AWS History and Timeline regarding AWS Systems Manager - Overview, Functions, Features, Summary of Updates, and Introduction to SSM\n\u2022 AWS History and Timeline regarding Amazon S3 - Focusing on the evolution of features, roles, and prices beyond mere storage\n\u2022 How to create a PWA(Progressive Web Apps) compatible website on AWS and use Lighthouse Report Viewer\n\u2022 AWS History and Timeline - Almost All AWS Services List, Announcements, General Availability(GA)\n\nWritten by Hidekazu Konishi\n\nHOME > Personal Tech Blog\n\nCopyright \u00a9 Hidekazu Konishi ( hidekazu-konishi.com ) All Rights Reserved."
}
Verification of Execution Results
For the OCR process in the above execution example, I verified how accurately the text contained in the image was extracted by comparing the actual blog article's text with the text outputted toimage_ocr.The upper half of the following image shows the actual text of the blog article, while the lower half displays the text outputted to
image_ocr.
"\u2022" or "\u00a9" are also recognized from the image and output.It also recognizes parts where text strings are broken into new lines within the image and outputs them with the line break character
"\n".Furthermore, the leading
"hidekazu-konishi.com " is also output, and there were no particularly noticeable errors.This demonstrates that Anthropic Claude 3.5 Sonnet can extract text contained in images with higher accuracy than Anthropic Claude 3 family's Haiku, Sonnet, and Opus, which were previously tested in similar verifications.
References:
Tech Blog with curated related content
Summary
In this session, I introduced how to use Amazon Bedrock's Anthropic Claude 3.5 Sonnet for image titling, commentary, and OCR.Through this trial, it was demonstrated that the image recognition capabilities of Anthropic Claude 3.5 Sonnet can recognize text in a standard blog article with higher accuracy than the Anthropic Claude 3 family, presenting a viable use case for practical application.
I plan to continue monitoring Amazon Bedrock for updates, implementation methods, and potential combinations with other services, as demonstrated in this article.
Written by Hidekazu Konishi