Using Claude 3.7 Sonnet Vision Capabilities on Amazon Bedrock to Verify, Regenerate, and Automate Image Generation with Stable Diffusion 3.5 Large
First Published:
Last Updated:
Using Amazon Nova Pro Vision Capabilities on Amazon Bedrock to Verify, Regenerate, and Automate Image Generation with Amazon Nova Canvas
Using Claude 3.5 Sonnet Vision Capabilities on Amazon Bedrock to Verify, Regenerate, and Automate Image Generation with Amazon Titan Image Generator G1
Using Amazon Bedrock to repeatedly generate images with Stable Diffusion XL via Claude 3.5 Sonnet until requirements are met
In this article, I will introduce an example of using Amazon Bedrock to verify and regenerate images generated by Stability AI Stable Diffusion 3.5 Large (SD3.5 Large) utilizing the image understanding and analysis capabilities of Anthropic Claude 3.7 Sonnet.
Similar to the previous article, this attempt also aims to reduce the amount of human visual inspection work by automatically determining whether generated images meet requirements.
* The source code published in this article and other articles by this author was developed as part of independent research and is provided 'as is' without any warranty of operability or fitness for a particular purpose. Please use it at your own risk. The code may be modified without prior notice.
* This article uses AWS services on an AWS account registered individually for writing.
* The Amazon Bedrock Models used for writing this article were executed on 2025-03-01 (JST) and are based on the following End user license agreement (EULA) at that time:
Anthropic Claude 3.7 Sonnet (Model ID: anthropic.claude-3-7-sonnet-20250219-v1:0, Cross-region inference: us.anthropic.claude-3-7-sonnet-20250219-v1:0): Anthropic on Bedrock - Commercial Terms of Service (Effective: September 17, 2024)
Stability AI Stable Diffusion 3.5 Large(stability.sd3-5-large-v1:0): STABILITY AMAZON BEDROCK END USER LICENSE AGREEMENT(Last Updated: April 29, 2024)
Architecture Diagram and Process Flow
The architecture diagram to realize this theme is as follows: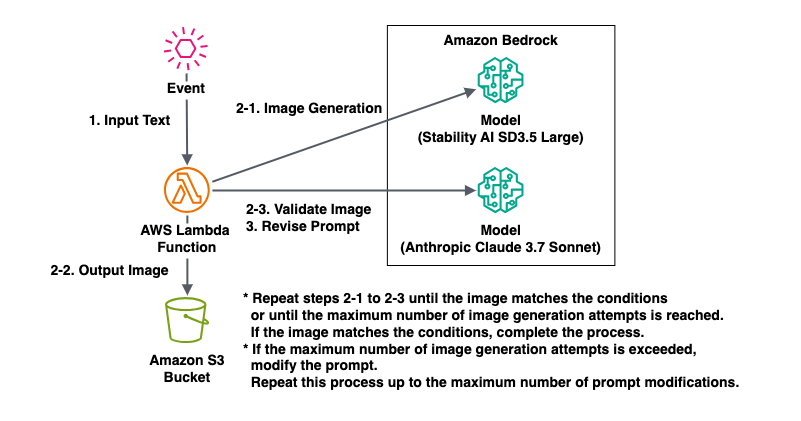
Here's a detailed explanation of this process flow:
1. Input an event containing prompts and parameters. 2-1. Execute the SD3.5 Large model on Amazon Bedrock with the input prompt instructing image creation. * Since SD3.5 Large does not support Japanese in prompts, execution with the initial Japanese prompt resulted in an error without generating images, and this process is skipped within the program. 2-2. Save the generated image to Amazon S3. 2-3. Execute the Claude 3.7 Sonnet model on Amazon Bedrock for the image saved in Amazon S3 to verify if it meets the requirements of the prompt that instructed image creation. * If it's not deemed suitable for the requirements of the prompt that instructed image creation, repeat processesThe key point in this process flow is the modification of the prompt instructing image creation by the Claude 3.7 Sonnet model.2-1to2-3for the specified number of executions with the same prompt. * If it's deemed suitable for the requirements of the prompt that instructed image creation, output that image as the result. 3. If the number of modified prompt executions has not been exceeded and the number of times deemed unsuitable for the requirements of the prompt that instructed image creation exceeds the number of executions with the same prompt, execute the Claude 3.7 Sonnet model on Amazon Bedrock to modify the prompt instructing image creation to one that is more likely to meet the requirements. Restart the process from2-1with this new prompt instructing image creation. * If the number of modified prompt executions is exceeded, end the process as an error.
If the prompt instructing image creation is easily understandable to AI, there's a high possibility that an image meeting the requirements will be output after several executions.
However, if the prompt instructing image creation is difficult for AI to understand, it's possible that an image meeting the requirements may not be output.
Therefore, when the specified number of executions with the same prompt is exceeded, I included a process to execute the Claude 3.7 Sonnet model on Amazon Bedrock and modify the prompt instructing image creation to an optimized one.
Implementation Example
Format of the Input Event
{
"prompt": "[Initial prompt for image generation]",
"max_retry_attempts": [Maximum number of attempts to generate an image for each prompt],
"max_prompt_revisions": [Maximum number of times to revise the prompt],
"output_s3_bucket_name": "[Name of the S3 bucket to store generated images]",
"output_s3_key_prefix": "[Prefix for the S3 key of generated images]",
"claude_validate_model_id": "[Model ID or Cross-region inference for Claude model during image validation]",
"claude_validate_temperature": [Temperature parameter for Claude model during image validation (0.0 to 1.0)],
"claude_validate_top_p": [Top-p parameter for Claude model during image validation (0.0 to 1.0)],
"claude_validate_top_k": [Top-k parameter for Claude model during image validation],
"claude_validate_max_tokens": [Maximum number of tokens generated by Claude model during image validation],
"claude_revise_model_id": "[Model ID or Cross-region inference for Claude model during prompt revision]",
"claude_revise_temperature": [Temperature parameter for Claude model during prompt revision (0.0 to 1.0)],
"claude_revise_top_p": [Top-p parameter for Claude model during prompt revision (0.0 to 1.0)],
"claude_revise_top_k": [Top-k parameter for Claude model during prompt revision],
"claude_revise_max_tokens": [Maximum number of tokens generated by Claude model during prompt revision],
"sd_model_id": "[Model ID for Stable Diffusion 3.5 Large model]",
"sd_aspect_ratio": [Controls the aspect ratio of the generated image for Stable Diffusion 3.5 Large model],
"sd_output_format": [Specifies the format of the output image for Stable Diffusion 3.5 Large model],
"sd_seed": [Random seed used by Stable Diffusion 3.5 Large model (for reproducibility, random if not specified)]
}
Example of Input Event
{
"prompt": "A serene landscape with mountains and a lake",
"max_retry_attempts": 5,
"max_prompt_revisions": 5,
"output_s3_bucket_name": "your-output-bucket-name",
"output_s3_key_prefix": "generated-images",
"claude_validate_model_id": "us.anthropic.claude-3-7-sonnet-20250219-v1:0",
"claude_validate_temperature": 1.0,
"claude_validate_top_p": 0.999,
"claude_validate_top_k": 250,
"claude_validate_max_tokens": 64000,
"claude_revise_model_id": "us.anthropic.claude-3-7-sonnet-20250219-v1:0",
"claude_revise_temperature": 1.0,
"claude_revise_top_p": 0.999,
"claude_revise_top_k": 250,
"claude_revise_max_tokens": 64000,
"sd_model_id": "stability.sd3-5-large-v1:0",
"sd_aspect_ratio": "1:1",
"sd_output_format": "png",
"sd_seed": 0
}
Source Code
The source code implemented this time is as follows:
# #Event Sample
# {
# "prompt": "A serene landscape with mountains and a lake",
# "max_retry_attempts": 5,
# "max_prompt_revisions": 5,
# "output_s3_bucket_name": "your-output-bucket-name",
# "output_s3_key_prefix": "generated-images",
# "claude_validate_model_id": "us.anthropic.claude-3-7-sonnet-20250219-v1:0",
# "claude_validate_temperature": 1.0,
# "claude_validate_top_p": 0.999,
# "claude_validate_top_k": 250,
# "claude_validate_max_tokens": 64000,
# "claude_revise_model_id": "us.anthropic.claude-3-7-sonnet-20250219-v1:0",
# "claude_revise_temperature": 1.0,
# "claude_revise_top_p": 0.999,
# "claude_revise_top_k": 250,
# "claude_revise_max_tokens": 64000,
# "sd_model_id": "stability.sd3-5-large-v1:0",
# "sd_aspect_ratio": "1:1",
# "sd_output_format": "png",
# "sd_seed": 0
# }
import boto3
import json
import base64
import os
import sys
import logging
from io import BytesIO
import datetime
import random
logger = logging.getLogger()
logger.setLevel(logging.INFO)
if not logger.handlers:
handler = logging.StreamHandler(sys.stdout)
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
handler.setFormatter(formatter)
logger.addHandler(handler)
region = os.environ.get('AWS_REGION')
bedrock_runtime_client = boto3.client('bedrock-runtime', region_name=region)
s3_client = boto3.client('s3', region_name=region)
def claude3_invoke_model(input_prompt, image_media_type=None, image_data_base64=None, model_params={}):
logger.info(f"Invoking Claude model: {model_params.get('model_id')}")
logger.debug(f"Prompt length: {len(input_prompt)} characters")
messages = [
{
"role": "user",
"content": [
{
"type": "text",
"text": input_prompt
}
]
}
]
if image_media_type and image_data_base64:
logger.debug(f"Including image in prompt with media type: {image_media_type}")
messages[0]["content"].insert(0, {
"type": "image",
"source": {
"type": "base64",
"media_type": image_media_type,
"data": image_data_base64
}
})
body = {
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": model_params.get('max_tokens', 64000),
"messages": messages,
"temperature": model_params.get('temperature', 1.0),
"top_p": model_params.get('top_p', 0.999),
"top_k": model_params.get('top_k', 250),
"stop_sequences": ["\n\nHuman:"]
}
try:
logger.debug(f"Claude request parameters: temperature={body['temperature']}, top_p={body['top_p']}, top_k={body['top_k']}")
response = bedrock_runtime_client.invoke_model(
modelId=model_params['model_id'],
contentType='application/json',
accept='application/json',
body=json.dumps(body)
)
response_body = json.loads(response.get('body').read())
response_text = response_body["content"][0]["text"]
logger.debug(f"Claude response length: {len(response_text)} characters")
logger.info("Claude model invocation successful")
return response_text
except Exception as e:
logger.error(f"Error invoking Claude model: {str(e)}")
raise
def sd_invoke_model(prompt, negative_prompt, model_params={}):
logger.info(f"Invoking Stable Diffusion model: {model_params.get('model_id')}")
logger.debug(f"Prompt: {prompt}")
if negative_prompt:
logger.debug(f"Negative prompt: {negative_prompt}")
seed = model_params.get('seed', 0)
if seed == 0:
seed = random.randint(0, 4294967295)
logger.info(f"Generated random seed: {seed}")
else:
logger.info(f"Using provided seed: {seed}")
body = {
"prompt": prompt,
"mode": 'text-to-image',
"aspect_ratio": model_params.get('aspect_ratio', '1:1'),
"output_format": model_params.get('output_format', 'png'),
"seed": seed
}
if negative_prompt:
body['negative_prompt'] = negative_prompt
logger.info(f"SD model parameters: {json.dumps(body)}")
try:
response = bedrock_runtime_client.invoke_model(
modelId=model_params['model_id'],
contentType="application/json",
accept="application/json",
body=json.dumps(body)
)
response_body = json.loads(response['body'].read())
logger.debug("SD model response received")
if 'images' in response_body and response_body['images']:
image_data = base64.b64decode(response_body['images'][0])
logger.info(f"Image generated successfully with seed: {seed}")
return image_data, None
else:
error_msg = "Image data was not found in the response."
logger.error(error_msg)
return None, Exception(error_msg)
except Exception as e:
logger.error(f"Exception during SD model invocation: {str(e)}")
return None, e
def save_image_to_s3(image_data, bucket, key):
logger.info(f"Saving image to S3: bucket={bucket}, key={key}")
try:
s3_client.put_object(
Bucket=bucket,
Key=key,
Body=image_data
)
logger.info(f"Image saved successfully to S3: s3://{bucket}/{key}")
except Exception as e:
logger.error(f"Error saving image to S3: {str(e)}")
raise
def validate_image(image_data, image_format, prompt, claude_validate_params):
logger.info("Validating generated image with Claude")
image_base64 = base64.b64encode(image_data).decode('utf-8')
input_prompt = f"""Does this image match the following prompt? Prompt: {prompt}.
Please answer in the following JSON format:
{{"result":"<YES or NO>", "reason":"<Reason for your decision>"}}
Ensure your response can be parsed as valid JSON. Do not include any explanations, comments, or additional text outside of the JSON structure."""
media_type = f"image/{image_format}"
logger.debug(f"Image validation media type: {media_type}")
validation_result = claude3_invoke_model(input_prompt, media_type, image_base64, claude_validate_params)
try:
logger.debug(f"Validation raw result: {validation_result}")
parsed_result = json.loads(validation_result)
if 'result' not in parsed_result:
logger.error("Missing 'result' field in validation response")
return False
is_valid = parsed_result['result'].upper() == 'YES'
logger.info(f"Image validation result: {is_valid}")
logger.info(f"Validation reason: {parsed_result.get('reason', 'No reason provided')}")
return is_valid
except json.JSONDecodeError:
logger.error(f"Error parsing validation result: {validation_result}")
return False
def revise_prompt(original_prompt, claude_revise_params):
logger.info("Revising prompt with Claude")
logger.debug(f"Original prompt: {original_prompt}")
input_prompt = f"""Revise the following image generation prompt to optimize it for Stable Diffusion 3.5 Large, incorporating best practices:
{original_prompt}
Please consider the following guidelines in your revision:
1. Use natural language descriptions - SD3.5 excels with conversational prompts.
2. Structure the prompt with key elements in this order if applicable:
- Style (illustration, painting medium, photography style)
- Subject and action (focus on subject first, then any actions)
- Composition and framing (close-up, wide-angle, etc.)
- Lighting and color (backlight, rim light, dynamic shadows, etc.)
- Technical parameters (bird's eye view, fish-eye lens, etc.)
3. For text in images, enclose desired text in "double quotes" and keep it short.
4. Consider including negative prompts to filter out unwanted elements.
5. Be specific with descriptive adjectives and clear nouns.
6. Mention specific artists or art styles if relevant for the desired aesthetic.
7. If the original prompt is not in English, translate it to English.
Your goal is to create a clear, natural language prompt that will result in a high-quality image with Stable Diffusion 3.5 Large.
Please provide your response in the following JSON format:
{{"revised_prompt":"<Revised Prompt>", "negative_prompt":"<Optional Negative Prompt>"}}
Ensure your response can be parsed as valid JSON. Do not include any explanations, comments, or additional text outside of the JSON structure."""
revised_prompt_json = claude3_invoke_model(input_prompt, model_params=claude_revise_params)
logger.debug(f"Revised prompt JSON response: {revised_prompt_json.strip()}")
try:
parsed_result = json.loads(revised_prompt_json)
revised_prompt = parsed_result['revised_prompt']
negative_prompt = parsed_result.get('negative_prompt', '')
logger.info(f"Prompt revised successfully")
logger.debug(f"Revised prompt: {revised_prompt}")
if negative_prompt:
logger.debug(f"Negative prompt: {negative_prompt}")
return revised_prompt, negative_prompt
except json.JSONDecodeError:
logger.error(f"Error parsing revised prompt result: {revised_prompt_json}")
return original_prompt, ""
def lambda_handler(event, context):
logger.info("Lambda function started")
logger.debug(f"Event: {json.dumps(event)}")
try:
initial_prompt = event['prompt']
prompt = initial_prompt
max_retry_attempts = max(0, event.get('max_retry_attempts', 5) - 1)
max_prompt_revisions = max(0, event.get('max_prompt_revisions', 3) - 1)
output_s3_bucket_name = event['output_s3_bucket_name']
output_s3_key_prefix = event.get('output_s3_key_prefix', 'generated-images')
logger.info(f"Initial prompt: {initial_prompt}")
logger.info(f"Max retry attempts: {max_retry_attempts}")
logger.info(f"Max prompt revisions: {max_prompt_revisions}")
logger.info(f"Output S3 bucket: {output_s3_bucket_name}")
logger.info(f"Output S3 key prefix: {output_s3_key_prefix}")
# Model parameters
claude_validate_params = {
"model_id": event.get('claude_validate_model_id', 'us.anthropic.claude-3-7-sonnet-20250219-v1:0'),
'temperature': event.get('claude_validate_temperature', 1.0),
'top_p': event.get('claude_validate_top_p', 0.999),
'top_k': event.get('claude_validate_top_k', 250),
'max_tokens': event.get('claude_validate_max_tokens', 64000)
}
claude_revise_params = {
"model_id": event.get('claude_revise_model_id', 'us.anthropic.claude-3-7-sonnet-20250219-v1:0'),
'temperature': event.get('claude_revise_temperature', 1.0),
'top_p': event.get('claude_revise_top_p', 0.999),
'top_k': event.get('claude_revise_top_k', 250),
'max_tokens': event.get('claude_revise_max_tokens', 64000)
}
sd_params = {
"model_id": event.get('sd_model_id', 'stability.sd3-5-large-v1:0'),
"aspect_ratio": event.get('sd_aspect_ratio', '1:1'),
"output_format": event.get('sd_output_format', 'png'),
"seed": event.get('sd_seed', 0)
}
logger.debug(f"Claude validate params: {json.dumps(claude_validate_params)}")
logger.debug(f"Claude revise params: {json.dumps(claude_revise_params)}")
logger.debug(f"SD params: {json.dumps(sd_params)}")
# Generate start timestamp and S3 key
start_timestamp = datetime.datetime.now().strftime("%Y%m%d%H%M%S")
negative_prompt = ""
for revision in range(max_prompt_revisions + 1):
logger.info(f"Starting revision {revision}/{max_prompt_revisions}")
for attempt in range(max_retry_attempts + 1):
logger.info(f"Starting attempt {attempt}/{max_retry_attempts} for generating image")
# Generate image with SD3.5 Large
image_data, error = sd_invoke_model(prompt, negative_prompt, sd_params)
# Skip image save and validation if there's an error
if error is not None:
logger.error(f"Error generating image: {str(error)}")
# If we've reached max attempts for this revision, break to try a revised prompt
if attempt == max_retry_attempts:
logger.info("Max attempts reached for this revision, moving to next revision")
break
else:
logger.info("Retrying image generation")
continue
image_format = sd_params["output_format"]
image_key = f"{output_s3_key_prefix}-{start_timestamp}-{revision:03d}-{attempt:03d}.{image_format}"
logger.debug(f"Generated image key: {image_key}")
# Save image to S3
save_image_to_s3(image_data, output_s3_bucket_name, image_key)
# Validate image with Claude
is_valid = validate_image(image_data, image_format, prompt, claude_validate_params)
if is_valid:
logger.info("Valid image generated successfully")
response = {
'statusCode': 200,
'body': json.dumps({
'status': 'SUCCESS',
'message': 'Image generated successfully',
'output_s3_bucket_url': f'https://s3.console.aws.amazon.com/s3/buckets/{output_s3_bucket_name}',
'output_s3_object_url': f'https://s3.console.aws.amazon.com/s3/object/{output_s3_bucket_name}?region={region}&prefix={image_key}'
})
}
logger.debug(f"Lambda response: {json.dumps(response)}")
return response
# If max retry attempts reached and not the last revision, revise prompt
if revision < max_prompt_revisions:
logger.info("Revising prompt for next revision")
prompt, negative_prompt = revise_prompt(initial_prompt, claude_revise_params)
logger.warning("Failed to generate a valid image after all attempts and revisions")
response = {
'statusCode': 400,
'body': json.dumps({
'status': 'FAIL',
'error': 'Failed to generate a valid image after all attempts and revisions'
})
}
logger.debug(f"Lambda response: {json.dumps(response)}")
return response
except Exception as ex:
logger.error(f'Exception in lambda_handler: {str(ex)}', exc_info=True)
tb = sys.exc_info()[2]
err_message = f'Exception: {str(ex.with_traceback(tb))}'
response = {
'statusCode': 500,
'body': json.dumps({
'status': 'FAIL',
'error': err_message
})
}
logger.debug(f"Lambda error response: {json.dumps(response)}")
return response
The points of ingenuity in this source code include the following:- Implemented a mechanism to automate the cycle of image generation and validation, repeating until requirements are met
- Used Claude 3.7 Sonnet for validating generated images and revising prompts
- Used Stable Diffusion 3.5 Large for high-quality image generation
- Included specific best practices for image generation in the prompt revision instructions
- Made image generation parameters (cfg_scale, steps, width, height, seed) customizable
- Made Claude 3.7 Sonnet invocation parameters (temperature, top_p, top_k, max_tokens) adjustable
- Automatically saved generated images to S3 bucket and returned the result URL
- Implemented appropriate error handling and logging to facilitate troubleshooting
- Used JSON format to structure dialogues with Claude, making result parsing easier
- Made maximum retry attempts and maximum prompt revisions configurable to prevent infinite loops
Execution Details and Results
An Example of Execution: Input Parameters
{
"prompt": "自然の中から見た夜景で、空にはオーロラと月と流星群があり、地上には海が広がって流氷が流れ、地平線から太陽が出ている無人の写真。",
"max_retry_attempts": 5,
"max_prompt_revisions": 5,
"output_s3_bucket_name": "ho2k.com",
"output_s3_key_prefix": "generated-images",
"claude_validate_model_id": "us.anthropic.claude-3-7-sonnet-20250219-v1:0",
"claude_validate_temperature": 1.0,
"claude_validate_top_p": 0.999,
"claude_validate_top_k": 250,
"claude_validate_max_tokens": 64000,
"claude_revise_model_id": "us.anthropic.claude-3-7-sonnet-20250219-v1:0",
"claude_revise_temperature": 1.0,
"claude_revise_top_p": 0.999,
"claude_revise_top_k": 250,
"claude_revise_max_tokens": 64000,
"sd_model_id": "stability.sd3-5-large-v1:0",
"sd_aspect_ratio": "1:1",
"sd_output_format": "png",
"sd_seed": 0
}
* The Japanese text set in the prompt above translates to the following meaning in English:"A night view from nature, with aurora, moon, and meteor shower in the sky, the sea spreading on the ground with drifting ice, and the sun rising from the horizon in an uninhabited photograph."
In this execution, I am attempting to optimize instructions given in Japanese sentences that are not optimized as prompts for Stable Diffusion 3.5 Large through prompt modification by Claude 3.7 Sonnet.
The input parameters for this execution example include the following considerations:
max_retry_attemptsis set to 5 to increase the success rate of image generation.max_prompt_revisionsis set to 5, providing more opportunities to improve the prompt if needed.- Parameters for Claude model for image validation and revision (temperature, top_p, top_k, max_tokens) are finely set.
- The
sd_seedused for image generation is set to be random, ensuring different images are generated each time.
An Example of Execution: Results
Generated Image
The final image that met the prompt requirements and passed verification in this trial is shown below.This image actually meets almost all the requirements of "自然の中から見た夜景で、空にはオーロラと月と流星群があり、地上には海が広がって流氷が流れ、地平線から太陽が出ている無人の写真。"(The meaning is "A night view from nature, with aurora, moon, and meteor shower in the sky, the sea spreading on the ground with drifting ice, and the sun rising from the horizon in an uninhabited photograph.")
(While there are meteors but not enough to be called a meteor shower, and the moon is depicted rather small, the drifting ice and aurora are clearly expressed, and the contradictory scene of both the moon and the sun rising from the horizon is distinctly represented.)
Also, compared to other images generated earlier (see "List of Generated Images" below), I confirmed that the final image that passed verification satisfied more of the specified requirements.

[Image Validation Result and Reason]
Result: Passed
Reason:
The image perfectly matches the prompt, showing an Arctic night landscape with floating ice floes on water, a vibrant aurora borealis with purple and green waves in the sky, visible shooting stars, and what appears to be a low sun/light on the horizon. The scene is captured in high detail with natural lighting, showing a pristine wilderness with no human structures. The starry night sky, dramatic auroras, and frozen seascape create exactly the breathtaking nature photograph described in the prompt.Here is a list of images generated during this trial run.
Each row of images in this "List of Generated Images" was generated from different modified prompts.
Since SD3.5 Large does not support Japanese in prompts, execution with the initial Japanese prompt resulted in an error without generating images, and actual image generation starts from the first prompt modification onwards.
The output images from the first prompt modification onwards are closer to the requirements.

Changes in Modified Prompts
Each row of images in the "List of Generated Images" was generated from different modified prompts.Specifically, since SD3.5 Large does not support Japanese in prompts, the initial execution with Japanese prompts resulted in an error and no image was generated. The actual image generation began from the first prompt modification onward.
Therefore, the images in the first row of the "List of Generated Images" were generated from the "1st modification" prompt, while the images in the last row were generated from the "3rd modification" prompt.
This time, I am generating negative prompts simultaneously with the modification of the initial prompts, and passing them to SD3.5 Large.
Let's examine the changes in both the modified image generation prompts and negative prompts for each number of prompt modifications.
0th modification
{
"prompt": "自然の中から見た夜景で、空にはオーロラと月と流星群があり、地上には海が広がって流氷が流れ、地平線から太陽が出ている無人の写真。"
}
* The meaning is "A night view from nature, with aurora, moon, and meteor shower in the sky, the sea spreading on the ground with drifting ice, and the sun rising from the horizon in an uninhabited photograph."* Since SD3.5 Large does not support Japanese in prompts, execution with the initial Japanese prompt resulted in an error without generating images, and this process is skipped within the program.
1st modification
{
"prompt": "Create a breathtaking nature landscape photograph showing the magnificent northern lights (aurora borealis) dancing across the night sky, accompanied by a crescent moon and a meteor shower. Below, an arctic sea stretches to the horizon with floating ice floes gently drifting on the water. In the distance, the sun is just beginning to rise over the horizon, creating a dramatic contrast between night and day. Wide-angle composition capturing both the expansive sky and reflective ocean surface. Cinematic lighting with the auroras casting ethereal green and purple reflections on the water and ice.",
"negative_prompt": "people, humans, text, watermark, signature, blurry, distorted, low resolution, oversaturated, unrealistic lighting, cartoon style"
}
2nd modification
{
"prompt": "A breathtaking natural landscape photograph at night captured from a shoreline perspective. In the sky, vibrant aurora borealis waves dance alongside a bright crescent moon and a spectacular meteor shower with multiple shooting stars. Below, a vast ocean stretches to the horizon with floating ice floes scattered across the dark water. At the horizon line, the first rays of sunrise emerge, creating a beautiful contrast between night and dawn. The scene is completely devoid of people or man-made structures, showcasing pure wilderness.",
"negative_prompt": "people, buildings, structures, text, watermark, blurry, distorted, low quality, grainy, oversaturated"
}
3rd modification
{
"prompt": "A breathtaking nature photograph capturing the Arctic night landscape. A wide-angle composition showing the horizon where a low sun is just beginning to rise, casting golden light across a vast frozen sea filled with floating ice floes. In the dramatic night sky above, a vibrant aurora borealis dances in waves of green and purple, while a bright crescent moon illuminates the scene. Several shooting stars streak across the starry sky. The perspective is from a high vantage point overlooking the pristine wilderness, with no human presence or structures visible. Ultra-detailed 8K photography with crisp focus and natural lighting.",
"negative_prompt": "people, buildings, structures, ships, boats, text, watermarks, blurry, noisy, low quality, artifacts, oversaturation, unnatural colors, lens flare"
}
Upon examining the 'List of Generated Images' along with the corrected prompts, I can see that Claude 3.7 Sonnet optimized the prompts for image generation, and after the first prompt correction, images closer to the requirements were output.In this way, the images changed with each prompt modification and generation execution, and eventually an image that met the prompt requirements passed verification.
References:
Tech Blog with curated related content
AWS Documentation(Amazon Bedrock)
Stable Diffusion 3.5 Prompt Guide
Summary
In this article, I introduced an example using Anthropic Claude 3.7 Sonnet's image recognition capabilities on Amazon Bedrock to verify images generated by Stability AI Stable Diffusion 3.5 Large (SD3.5 Large) and regenerate them until they meet requirements.The results of this experiment showed that Claude 3.7 Sonnet's image recognition capabilities can not only perform OCR but also recognize what is depicted in images and what they express, and can be used to verify whether images meet requirements. I also confirmed that Claude 3.7 Sonnet can modify and optimize the content of prompts themselves. Additionally, Claude 3.7 Sonnet's image recognition capabilities and prompt modification functions execute faster than Claude 3.5 Sonnet (v2).
Most importantly, by automatically determining whether generated images meet requirements using these capabilities, I was able to significantly reduce the need for manual visual inspection by humans. Claude 3.7 Sonnet's image recognition capabilities and advanced text editing abilities have increased the potential for applications in processes that were previously difficult to automate, including controlling other image generation AI models as demonstrated in this example.
I will continue to monitor updates to AI models supported by Amazon Bedrock, including Anthropic Claude models, their implementation methods, and combinations with other services.
Written by Hidekazu Konishi