Using Claude 3.5 Sonnet Vision Capabilities on Amazon Bedrock to Verify, Regenerate, and Automate Image Generation with Amazon Titan Image Generator G1
First Published:
Last Updated:
Using Amazon Bedrock to repeatedly generate images with Stable Diffusion XL via Claude 3.5 Sonnet until requirements are met
In this article, I will introduce an example of using Amazon Bedrock to verify and regenerate images generated by Amazon Titan Image Generator G1 utilizing the image understanding and analysis capabilities of Anthropic Claude 3.5 Sonnet.
Similar to the previous article, this attempt also aims to reduce the amount of human visual inspection work by automatically determining whether generated images meet requirements.
* The source code published in this article and other articles by this author was developed as part of independent research and is provided 'as is' without any warranty of operability or fitness for a particular purpose. Please use it at your own risk. The code may be modified without prior notice.
* This article uses AWS services on an AWS account registered individually for writing.
* The Amazon Bedrock Models used for writing this article were executed on 2024-07-23 (JST) and are based on the following End user license agreement (EULA) at that time:
Anthropic Claude 3.5 Sonnet(anthropic.claude-3-5-sonnet-20240620-v1:0): Anthropic on Bedrock - Commercial Terms of Service(Effective: January 2, 2024)
Amazon Titan Image Generator G1(amazon.titan-image-generator-v1): End user license agreement (EULA) (AWS Customer Agreement and Service Terms)
Architecture Diagram and Process Flow
The architecture diagram to realize this theme is as follows: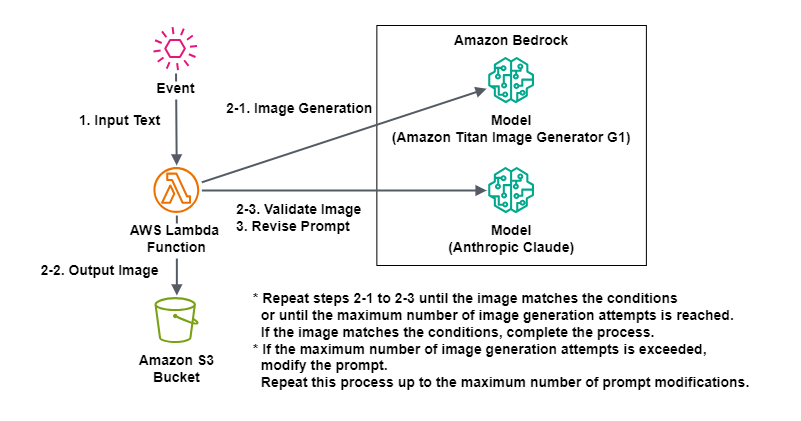
Here's a detailed explanation of this process flow:
1. Input an event containing prompts and parameters. 2-1. Execute the Titan Image Generator G1 model on Amazon Bedrock with the input prompt instructing image creation. 2-2. Save the generated image to Amazon S3. 2-3. Execute the Claude 3.5 Sonnet model on Amazon Bedrock for the image saved in Amazon S3 to verify if it meets the requirements of the prompt that instructed image creation. * If it's not deemed suitable for the requirements of the prompt that instructed image creation, repeat processesThe key point in this process flow is the modification of the prompt instructing image creation by the Claude 3.5 Sonnet model.2-1to2-3for the specified number of executions with the same prompt. * If it's deemed suitable for the requirements of the prompt that instructed image creation, output that image as the result. 3. If the number of modified prompt executions has not been exceeded and the number of times deemed unsuitable for the requirements of the prompt that instructed image creation exceeds the number of executions with the same prompt, execute the Claude 3.5 Sonnet model on Amazon Bedrock to modify the prompt instructing image creation to one that is more likely to meet the requirements. Restart the process from2-1with this new prompt instructing image creation. * If the number of modified prompt executions is exceeded, end the process as an error.
If the prompt instructing image creation is easily understandable to AI, there's a high possibility that an image meeting the requirements will be output after several executions.
However, if the prompt instructing image creation is difficult for AI to understand, it's possible that an image meeting the requirements may not be output.
Therefore, when the specified number of executions with the same prompt is exceeded, I included a process to execute the Claude 3.5 Sonnet model on Amazon Bedrock and modify the prompt instructing image creation to an optimized one.
Implementation Example
Format of the Input Event
{
"prompt": "[Initial prompt for image generation]",
"max_retry_attempts": [Maximum number of attempts to generate an image for each prompt],
"max_prompt_revisions": [Maximum number of times to revise the prompt],
"output_s3_bucket_name": "[Name of the S3 bucket to store generated images]",
"output_s3_key_prefix": "[Prefix for the S3 key of generated images]",
"claude_validate_temperature": [Temperature parameter for Claude model during image validation (0.0 to 1.0)],
"claude_validate_top_p": [Top-p parameter for Claude model during image validation (0.0 to 1.0)],
"claude_validate_top_k": [Top-k parameter for Claude model during image validation],
"claude_validate_max_tokens": [Maximum number of tokens generated by Claude model during image validation],
"claude_revise_temperature": [Temperature parameter for Claude model during prompt revision (0.0 to 1.0)],
"claude_revise_top_p": [Top-p parameter for Claude model during prompt revision (0.0 to 1.0)],
"claude_revise_top_k": [Top-k parameter for Claude model during prompt revision],
"claude_revise_max_tokens": [Maximum number of tokens generated by Claude model during prompt revision],
"titan_img_cfg_scale": [CFG scale for Titan Image Generator G1 model],
"titan_img_width": [Width of the image generated by Titan Image Generator G1 model (in pixels)],
"titan_img_height": [Height of the image generated by Titan Image Generator G1 model (in pixels)],
"titan_img_number_of_images": [Number of images to generate with Titan Image Generator G1 model],
"titan_img_seed": [Random seed used by Titan Image Generator G1 model (for reproducibility, random if not specified)]
}
Example of Input Event
{
"prompt": "A serene landscape with mountains and a lake",
"max_retry_attempts": 5,
"max_prompt_revisions": 3,
"output_s3_bucket_name": "your-output-bucket-name",
"output_s3_key_prefix": "generated-images-taitan",
"claude_validate_temperature": 1.0,
"claude_validate_top_p": 0.999,
"claude_validate_top_k": 250,
"claude_validate_max_tokens": 4096,
"claude_revise_temperature": 1.0,
"claude_revise_top_p": 0.999,
"claude_revise_top_k": 250,
"claude_revise_max_tokens": 4096,
"titan_img_cfg_scale": 10.0,
"titan_img_width": 1024,
"titan_img_height": 1024,
"titan_img_number_of_images": 1,
"titan_img_seed": 0
}
Source Code
The source code implemented this time is as follows:
# #Event Sample
# {
# "prompt": "A serene landscape with mountains and a lake",
# "max_retry_attempts": 5,
# "max_prompt_revisions": 3,
# "output_s3_bucket_name": "your-output-bucket-name",
# "output_s3_key_prefix": "generated-images-taitan",
# "claude_validate_temperature": 1.0,
# "claude_validate_top_p": 0.999,
# "claude_validate_top_k": 250,
# "claude_validate_max_tokens": 4096,
# "claude_revise_temperature": 1.0,
# "claude_revise_top_p": 0.999,
# "claude_revise_top_k": 250,
# "claude_revise_max_tokens": 4096,
# "titan_img_cfg_scale": 10.0,
# "titan_img_width": 1024,
# "titan_img_height": 1024,
# "titan_img_number_of_images": 1,
# "titan_img_seed": 0
# }
import boto3
import json
import base64
import os
import sys
from io import BytesIO
import datetime
import random
region = os.environ.get('AWS_REGION')
bedrock_runtime_client = boto3.client('bedrock-runtime', region_name=region)
s3_client = boto3.client('s3', region_name=region)
def claude3_5_invoke_model(input_prompt, image_media_type=None, image_data_base64=None, model_params={}):
messages = [
{
"role": "user",
"content": [
{
"type": "text",
"text": input_prompt
}
]
}
]
if image_media_type and image_data_base64:
messages[0]["content"].insert(0, {
"type": "image",
"source": {
"type": "base64",
"media_type": image_media_type,
"data": image_data_base64
}
})
body = {
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": model_params.get('max_tokens', 4096),
"messages": messages,
"temperature": model_params.get('temperature', 1.0),
"top_p": model_params.get('top_p', 0.999),
"top_k": model_params.get('top_k', 250),
"stop_sequences": ["\n\nHuman:"]
}
response = bedrock_runtime_client.invoke_model(
modelId='anthropic.claude-3-5-sonnet-20240620-v1:0',
contentType='application/json',
accept='application/json',
body=json.dumps(body)
)
response_body = json.loads(response.get('body').read())
response_text = response_body["content"][0]["text"]
return response_text
def titan_img_invoke_model(prompt, model_params={}):
seed = model_params.get('seed', 0)
if seed == 0:
seed = random.randint(0, 2147483646)
optimized_prompt = truncate_to_512(prompt)
body = {
"taskType": "TEXT_IMAGE",
"textToImageParams": {
"text": optimized_prompt
},
"imageGenerationConfig": {
"numberOfImages": model_params.get('img_number_of_images', 1),
"height": model_params.get('height', 1024),
"width": model_params.get('width', 1024),
"cfgScale": model_params.get('cfg_scale', 8),
"seed": seed
}
}
print(f"Titan Image Generator G1 model parameters: {body}")
response = bedrock_runtime_client.invoke_model(
body=json.dumps(body),
modelId="amazon.titan-image-generator-v1",
contentType="application/json",
accept="application/json"
)
response_body = json.loads(response['body'].read())
image_data = base64.b64decode(response_body.get("images")[0].encode('ascii'))
finish_reason = response_body.get("error")
if finish_reason is not None:
print(f"Image generation error. Error is {finish_reason}")
else:
print(f"Image generated successfully with seed: {seed}")
return image_data
def truncate_to_512(text):
if len(text) <= 512:
return text
truncated = text[:512]
last_period = truncated.rfind('.')
last_comma = truncated.rfind(',')
last_break = max(last_period, last_comma)
if last_break > 256: # Only if the last sentence or phrase is not too long
return truncated[:last_break + 1]
else:
return truncated
def save_image_to_s3(image_data, bucket, key):
s3_client.put_object(
Bucket=bucket,
Key=key,
Body=image_data
)
print(f"Image saved to S3: s3://{bucket}/{key}")
def validate_image(image_data, prompt, claude_validate_params):
image_base64 = base64.b64encode(image_data).decode('utf-8')
input_prompt = f"""Does this image match the following prompt? Prompt: {prompt}.
Please answer in the following JSON format:
{{"result":"", "reason":""}}
Ensure your response can be parsed as valid JSON. Do not include any explanations, comments, or additional text outside of the JSON structure."""
validation_result = claude3_5_invoke_model(input_prompt, "image/png", image_base64, claude_validate_params)
try:
print(f"validation Result: {validation_result}")
parsed_result = json.loads(validation_result)
is_valid = parsed_result['result'].upper() == 'YES'
print(f"Image validation result: {is_valid}")
print(f"Validation reason: {parsed_result['reason']}")
return is_valid
except json.JSONDecodeError:
print(f"Error parsing validation result: {validation_result}")
return False
def revise_prompt(original_prompt, claude_revise_params):
input_prompt = f"""Revise the following image generation prompt to optimize it for Titan Image Generator G1, incorporating best practices:
{original_prompt}
Please consider the following guidelines in your revision:
1. Start the prompt with "An image of..." and be specific and descriptive, using vivid adjectives and clear nouns.
2. Include detailed descriptions about composition, lighting, style, mood, color, and medium if relevant.
3. Mention specific artists or art styles if relevant, though this is not emphasized in Titan's guidelines.
4. Use descriptive keywords like "highly detailed" if appropriate. While "4k", "8k", or "photorealistic" can be used, they are not specifically emphasized for Titan.
5. Separate different concepts with commas, using them to structure the prompt logically.
6. Place more important elements, especially the main subject, at the beginning of the prompt.
7. Consider using negative prompts to specify what should NOT be included in the image.
8. If the original prompt is not in English, translate it to English.
9. Use double quotes instead of single quotes for any quoted text within the prompt.
10. Provide context or background details to help improve the realism and coherence of the generated image.
11. Ensure the final prompt is no longer than 500 characters. Prioritize the most important elements if you need to shorten the prompt.
Your goal is to create a clear, detailed prompt that will result in a high-quality image generation with Titan Image Generator G1, while staying within the 500-character limit.
Please provide your response in the following JSON format:
{{"revised_prompt":""}}
Ensure your response can be parsed as valid JSON. Do not include any explanations, comments, or additional text outside of the JSON structure."""
revised_prompt_json = claude3_5_invoke_model(input_prompt, model_params=claude_revise_params)
print(f"Original prompt: {original_prompt}")
print(f"Revised prompt JSON: {revised_prompt_json.strip()}")
try:
parsed_result = json.loads(revised_prompt_json)
revised_prompt = parsed_result['revised_prompt']
print(f"Parsed revised prompt: {revised_prompt}")
return revised_prompt
except json.JSONDecodeError:
print(f"Error parsing revised prompt result: {revised_prompt_json}")
return original_prompt
def lambda_handler(event, context):
try:
initial_prompt = event['prompt']
prompt = initial_prompt
max_retry_attempts = max(0, event.get('max_retry_attempts', 5) - 1)
max_prompt_revisions = max(0, event.get('max_prompt_revisions', 3) - 1)
output_s3_bucket_name = event['output_s3_bucket_name']
output_s3_key_prefix = event.get('output_s3_key_prefix', 'generated-images')
print(f"Initial prompt: {initial_prompt}")
print(f"Max retry attempts: {max_retry_attempts}")
print(f"Max prompt revisions: {max_prompt_revisions}")
# Model parameters
claude_validate_params = {
'temperature': event.get('claude_validate_temperature', 1.0),
'top_p': event.get('claude_validate_top_p', 0.999),
'top_k': event.get('claude_validate_top_k', 250),
'max_tokens': event.get('claude_validate_max_tokens', 4096)
}
claude_revise_params = {
'temperature': event.get('claude_revise_temperature', 1.0),
'top_p': event.get('claude_revise_top_p', 0.999),
'top_k': event.get('claude_revise_top_k', 250),
'max_tokens': event.get('claude_revise_max_tokens', 4096)
}
titan_img_params = {
'cfg_scale': event.get('titan_img_cfg_scale', 8),
"width": event.get('titan_img_width', 1024),
"height": event.get('titan_img_height', 1024),
'img_number_of_images': event.get('titan_img_number_of_images', 1),
"seed": event.get('titan_img_seed', 0)
}
print(f"Claude validate params: {claude_validate_params}")
print(f"Claude revise params: {claude_revise_params}")
print(f"Titan Image Generator G1 params: {titan_img_params}")
# Generate start timestamp and S3 key
start_timestamp = datetime.datetime.now().strftime("%Y%m%d%H%M%S")
for revision in range(max_prompt_revisions + 1):
print(f"Starting revision {revision}")
for attempt in range(max_retry_attempts + 1):
print(f"Attempt {attempt} for generating image")
# Generate image with Titan Image Generator G1
image_data = titan_img_invoke_model(prompt, titan_img_params)
image_key = f"{output_s3_key_prefix}-{start_timestamp}-{revision:03d}-{attempt:03d}.png"
# Save image to S3
save_image_to_s3(image_data, output_s3_bucket_name, image_key)
# Validate image with Claude
is_valid = validate_image(image_data, initial_prompt, claude_validate_params)
if is_valid:
print("Valid image generated successfully")
return {
'statusCode': 200,
'body': json.dumps({
'status': 'SUCCESS',
'message': 'Image generated successfully',
'output_s3_bucket_url': f'https://s3.console.aws.amazon.com/s3/buckets/{output_s3_bucket_name}',
'output_s3_object_url': f'https://s3.console.aws.amazon.com/s3/object/{output_s3_bucket_name}?region={region}&prefix={image_key}'
})
}
# If max retry attempts reached and not the last revision, revise prompt
if revision < max_prompt_revisions:
print("Revising prompt")
prompt = revise_prompt(initial_prompt, claude_revise_params)
print("Failed to generate a valid image after all attempts and revisions")
return {
'statusCode': 400,
'body': json.dumps({
'status': 'FAIL',
'error': 'Failed to generate a valid image after all attempts and revisions'
})
}
except Exception as ex:
print(f'Exception: {ex}')
tb = sys.exc_info()[2]
err_message = f'Exception: {str(ex.with_traceback(tb))}'
print(err_message)
return {
'statusCode': 500,
'body': json.dumps({
'status': 'FAIL',
'error': err_message
})
}
The points of ingenuity in this source code include the following:- Implemented a mechanism to automate the cycle of image generation and validation, repeating until requirements are met
- Used Claude 3.5 Sonnet for validating generated images and revising prompts
- Used Titan Image Generator G1 for high-quality image generation
- Included the recommendations listed in the Amazon Titan Image Generator Prompt Engineering Best Practices in the prompt revision instructions
- Made image generation parameters (cfgScale, width, height, seed) customizable
- Made Claude 3.5 Sonnet invocation parameters (temperature, top_p, top_k, max_tokens) adjustable
- Automatically saved generated images to S3 bucket and returned the result URL
- Implemented appropriate error handling and logging to facilitate troubleshooting
- Used JSON format to structure dialogues with Claude, making result parsing easier
- Made maximum retry attempts and maximum prompt revisions configurable to prevent infinite loops
Execution Details and Results
An Example of Execution: Input Parameters
{
"prompt": "自然の中から見た夜景で、空にはオーロラと月と流星群があり、地上には海が広がって流氷が流れ、地平線から太陽が出ている無人の写真。",
"max_retry_attempts": 5,
"max_prompt_revisions": 5,
"output_s3_bucket_name": "ho2k.com",
"output_s3_key_prefix": "generated-images-taitan",
"claude_validate_temperature": 1.0,
"claude_validate_top_p": 0.999,
"claude_validate_top_k": 250,
"claude_validate_max_tokens": 4096,
"claude_revise_temperature": 1.0,
"claude_revise_top_p": 0.999,
"claude_revise_top_k": 250,
"claude_revise_max_tokens": 4096,
"titan_img_cfg_scale": 10.0,
"titan_img_width": 1024,
"titan_img_height": 1024,
"titan_img_number_of_images": 1,
"titan_img_seed": 0
}
* The Japanese text set in the prompt above translates to the following meaning in English:"A night view from nature, with aurora, moon, and meteor shower in the sky, the sea spreading on the ground with drifting ice, and the sun rising from the horizon in an uninhabited photograph."
In this execution, I am attempting to optimize instructions given in Japanese sentences that are not optimized as prompts for Amazon Titan Image Generator G1 through prompt modification by Claude 3.5 Sonnet.
The input parameters for this execution example include the following considerations:
max_retry_attemptsis set to 5 to increase the success rate of image generation.max_prompt_revisionsis set to 5, providing more opportunities to improve the prompt if needed.- Parameters for Claude model for image validation and revision (temperature, top_p, top_k, max_tokens) are finely set.
titan_img_cfg_scaleis set to 10 to increase fidelity to the prompt.- The
seedused for image generation is set to be random, ensuring different images are generated each time.
An Example of Execution: Results
Generated Image
The final image that met the prompt requirements and passed verification in this trial is shown below.This image actually meets almost all the requirements of "自然の中から見た夜景で、空にはオーロラと月と流星群があり、地上には海が広がって流氷が流れ、地平線から太陽が出ている無人の写真。"(The meaning is "A night view from nature, with aurora, moon, and meteor shower in the sky, the sea spreading on the ground with drifting ice, and the sun rising from the horizon in an uninhabited photograph.")
(The visualization of the sun rising from the horizon is weak, but the contradictory scenery of the moon and the sun on the horizon, meteor shower, and drifting ice are clearly expressed).
Also, compared to other images generated earlier (see "List of Generated Images" below), I confirmed that the final image that passed verification satisfied more of the specified requirements.

Here is a list of images generated during this trial run.
Each row of images in this "List of Generated Images" was generated from different modified prompts.
While the image output from the initial Japanese text prompt is far from the requirements, the image output immediately after the first prompt modification meets almost all the requirements.

Changes in Modified Prompts
Each row of images in the "List of Generated Images" shown above was generated from different modified prompts.Specifically, the image in the first row of the "List of Generated Images" was generated from the "0th modification" prompt below, while the image in the last row was generated from the "1st modification" prompt below.
Let's look at the content of the modified image generation prompts for each number of prompt modifications.
0th modification
自然の中から見た夜景で、空にはオーロラと月と流星群があり、地上には海が広がって流氷が流れ、地平線から太陽が出ている無人の写真。* The meaning is "A night view from nature, with aurora, moon, and meteor shower in the sky, the sea spreading on the ground with drifting ice, and the sun rising from the horizon in an uninhabited photograph."
1st modification
An image of a breathtaking nighttime landscape viewed from nature, featuring a vibrant aurora borealis dancing across the sky, accompanied by a luminous full moon and a dazzling meteor shower. In the foreground, a vast, dark sea stretches to the horizon, dotted with floating ice floes. The sun is just beginning to rise at the horizon, casting a warm glow on the icy waters. The scene is devoid of human presence, highly detailed, with a serene and mystical atmosphere.Particularly when viewed in conjunction with the "List of Generated Images" mentioned above, it becomes apparent that the initial Japanese text prompt was not optimized for image generation, resulting in output images that deviate significantly from the requirements.
On the other hand, after the first modification where Claude 3.5 Sonnet optimized the prompt for image generation, an image that almost perfectly matches the requirements was output immediately after execution.
In this way, the images changed with each prompt modification and generation execution, and ultimately, an image that met the prompt requirements passed verification.
References:
Tech Blog with curated related content
AWS Documentation(Amazon Bedrock)
Amazon Titan Image Generator Prompt Engineering Best Practices
Summary
In this article, I introduced an example of using Amazon Bedrock to verify and regenerate images generated by Amazon Titan Image Generator G1 utilizing the image understanding and analysis capabilities of Anthropic Claude 3.5 Sonnet.Through this attempt, I confirmed that Claude 3.5 Sonnet's image recognition capabilities can recognize not only OCR but also the content and expression of images, and can be used to verify requirement fulfillment.
Furthermore, I found that Claude 3.5 Sonnet can be used for prompt optimization for Titan Image Generator G1, and it has a high ability to translate Japanese prompts into English and modify them into a format suitable for image generation.
And most importantly, by automating the cycle of image generation and verification, I was able to significantly reduce the amount of human visual inspection work.
A notable point is that, similar to the previous example using Stable Diffusion XL and this example using Amazon Titan Image Generator G1, by tailoring the prompt modification instructions to the best practices of each image generation AI, effective prompt optimization and image generation automation can be applied to various other image generation AIs.
In this way, Claude 3.5 Sonnet brings new possibilities to the control of image generation AI (such as Titan Image Generator G1 and Stable Diffusion XL) and processes that were previously difficult to automate.
I will continue to watch for the evolution of AI models provided by Amazon Bedrock and new implementation methods utilizing them, exploring further expansion of application areas.
Written by Hidekazu Konishi