hidekazu-konishi.com
Using Amazon Textract for OCR(Optical Character Recognition)
First Published:
Last Updated:
Using Amazon Bedrock for titling, commenting, and OCR (Optical Character Recognition) with Claude 3 Haiku
Using Amazon Bedrock for titling, commenting, and OCR (Optical Character Recognition) with Claude 3 Sonnet
Using Amazon Bedrock for titling, commenting, and OCR (Optical Character Recognition) with Claude 3 Opus
This time, I will try OCR processing with Amazon Textract, which has been used to read various types of documents and extract data such as text, handwritten characters, and tables as one of AWS's fully managed Machine Learning services.
Configuration Diagram
The configuration diagram to realize this theme is as follows.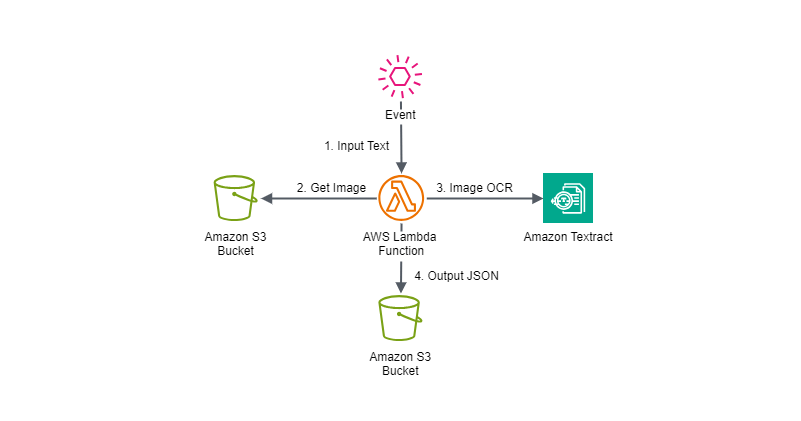
1. An AWS Lambda function is triggered by an event containing input text.
2. The AWS Lambda function that receives the event executes Amazon Textract's `detect_document_text` and retrieves images from the specified input Amazon S3 bucket.
3. Amazon Textract's `detect_document_text` processes the images from the specified input Amazon S3 bucket with OCR.
4. The extracted text is saved in JSON format in the specified output Amazon S3 bucket.
Implementation Example
This time, an AWS Lambda function has been implemented to execute `detect_document_text` of `textract` using AWS SDK for Python (Boto3).Additionally, I wanted to verify changes in output with respect to parameters, so the main parameters were made adjustable via Event.
For the specifications of methods to operate Amazon Textract using AWS SDK for Python (Boto3), please refer to Textract - Boto3 documentation.
import boto3
import json
import os
import sys
import datetime
region = os.environ.get('AWS_REGION')
s3_client = boto3.client('s3', region_name=region)
textract_client = boto3.client('textract', region_name=region)
def extract_text_from_image(bucket_name, document_key):
response = textract_client.detect_document_text(
Document={'S3Object': {'Bucket': bucket_name, 'Name': document_key}}
)
text_blocks = response['Blocks']
extracted_text = []
for block in text_blocks:
if block['BlockType'] == 'LINE':
extracted_text.append(block['Text'])
return "\n".join(extracted_text)
def lambda_handler(event, context):
result = {}
try:
input_s3_bucket_name = event['input_s3_bucket_name']
input_s3_object_key = event['input_s3_object_key']
output_s3_bucket_name = event['output_s3_bucket_name']
# Extract text from the image using Amazon Textract
image_ocr = extract_text_from_image(input_s3_bucket_name, input_s3_object_key)
response_json = {
"image_ocr": image_ocr
}
output_json = json.dumps(response_json).encode('utf-8')
output_s3_key = f'{input_s3_object_key.replace(".", "_")}_{datetime.datetime.now().strftime("%y%m%d_%H%M%S")}.json'
s3_client.put_object(Bucket=output_s3_bucket_name, Key=output_s3_key, Body=output_json)
result = {
"status": "SUCCESS",
"output_s3_bucket_url": f'https://s3.console.aws.amazon.com/s3/buckets/{output_s3_bucket_name}',
"output_s3_object_url": f'https://s3.console.aws.amazon.com/s3/object/{output_s3_bucket_name}?region={region}&bucketType=general&prefix={output_s3_key}'
}
except Exception as ex:
print(f'Exception: {ex}')
tb = sys.exc_info()[2]
err_message = f'Exception: {str(ex.with_traceback(tb))}'
print(err_message)
result = {
"status": "FAIL",
"error": err_message
}
return result
Execution Content
Parameter Settings
I verified changes in output by altering the image specified in the following format of Event parameters passed to the implemented AWS Lambda function.
{
"input_s3_bucket_name": "[Target Amazon S3 bucket to retrieve the image]",
"input_s3_object_key": "[Target Amazon S3 object key to retrieve the image]",
"output_s3_bucket_name": "[Amazon S3 bucket to output the result JSON]"
}
Input Data
As an example of input data, I used a screenshot image of the top page of my Personal Tech Blog, including the blog description and article titles.This example aims to assess the ability to accurately recognize standard document images with clear visibility.
Execution Results
Example: Titling, Commentary, and OCR for an English-Language Blog Article Image
* Input Data: Image
{
"image_ocr": "hidekazu-konishi.com\nHOME > Personal Tech Blog\nPersonal Tech Blog I hidekazu-konishi.com\nHere | plan to share my technical knowledge and experience, as well as my interests in the subject. Please note that this tech blog is a\nspace for sharing my personal views and ideas, and it does not represent the opinions of any company or organization I am affiliated with.\nThe main purpose of this blog is to deepen my own technical skills and knowledge, to create an archive where I can record and reflect on\nwhat | have learned and experienced, and to share information.\nMy interests are primarily in Amazon Web Services (AWS), but I may occasionally cover other technical topics as well.\nThe articles are based on my personal learning and practical experience. Of course, I am not perfect, so there may be errors or\ninadequacies in the articles. I hope you will enjoy this technical blog with that in mind. Thank you in advance.\nPrivacy Policy\nPersonal Tech Blog Entries\nFirst Published: 2022-04-30\nLast Updated: 2024-03-14\nSetting up DKIM, SPF, DMARC with Amazon SES and Amazon Route 53 - An Overview of DMARC Parameters and\nConfiguration Examples\nSummary of AWS Application Migration Service (AWS MGN) Architecture and Lifecycle Relationships, Usage Notes -\nIncluding Differences from AWS Server Migration Service (AWS SMS)\nBasic Information about Amazon Bedrock with API Examples - Model Features, Pricing, How to Use, Explanation of Tokens\nand Inference Parameters\nSummary of Differences and Commonalities in AWS Database Services using the Quorum Model - Comparison Charts of\nAmazon Aurora, Amazon DocumentDB, and Amazon Neptune\nAWS Amplify Features Focusing on Static Website Hosting - Relationship and Differences between AWS Amplify Hosting and\nAWS Amplify CLI\nHost a Static Website configured with Amazon S3 and Amazon CloudFront using AWS Amplify CLI\nHost a Static Website using AWS Amplify Hosting in the AWS Amplify Console\nReasons for Continually Obtaining All AWS Certifications, Study Methods, and Levels of Difficulty\nSummary of AWS CloudFormation StackSets Focusing on the Relationship between the Management Console and API,\nAccount Filter, and the Role of Parameters\nAWS History and Timeline regarding AWS Key Management Service - Overview, Functions, Features, Summary of Updates,\nand Introduction to KMS\nAWS History and Timeline regarding Amazon EventBridge - Overview, Functions, Features, Summary of Updates, and\nIntroduction\nAWS History and Timeline regarding Amazon Route 53 - Overview, Functions, Features, Summary of Updates, and\nIntroduction\nAWS History and Timeline regarding AWS Systems Manager - Overview, Functions, Features, Summary of Updates, and\nIntroduction to SSM\nAWS History and Timeline regarding Amazon S3 - Focusing on the evolution of features, roles, and prices beyond mere\nstorage\nHow to create a PWA(Progressive Web Apps) compatible website on AWS and use Lighthouse Report Viewer\nAWS History and Timeline - Almost All AWS Services List, Announcements, General Availability(GA)\nWritten by Hidekazu Konishi\nHOME > Personal Tech Blog\nCopyright \u00a9 Hidekazu Konishi ( hidekazu-konishi.com ) All Rights Reserved."
}
Verification of Execution Results
In the OCR process of the above execution example, I verified how accurately the text contained in the image was extracted by comparing the actual blog article's text with the text outputted to `image_ocr`.The upper half of the following image shows the actual text of the blog article, while the lower half displays the text outputted to `image_ocr`.

On the other hand, parts where `"|"` was mistaken for a character similar in shape to `"I"` are observed throughout.
In this trial, while Amazon Textract extracted all characters overall, the character recognition accuracy was lower than OCR using Anthropic Claude 3 Haiku on Amazon Bedrock, and it failed to recognize Unicode characters written in HTML code like `"\\u2022"` and `"\\u00a9"`.
Summary
This session explored OCR processing using Amazon Textract, a fully managed service by AWS.Through this trial, it was demonstrated that Amazon Textract allows very simple implementation and minimal parameter settings to utilize image recognition capabilities, and it can recognize text in a standard blog article with practical accuracy.
However, depending on the use case and required recognition accuracy, considering OCR processing using generative AI like Anthropic Claude 3 Haiku on Amazon Bedrock may increase in the future.
Moving forward, like in this session, I plan to continue monitoring Amazon Textract and other fully managed Machine Learning services regarding updates, implementation methods, and potential combinations with other services.
Written by Hidekazu Konishi
Copyright © Hidekazu Konishi ( hidekazu-konishi.com ) All Rights Reserved.